数据结构是现实世界和抽象数学世界之间的一座桥梁。
我们虽然没接触过队列,但一定见过排队。
- 吃饭排队,排在前面的先交钱,排在后面的等着交钱。
- 当队伍太长,于是做了个小优化:分两个队伍,一个交钱,一个取餐。
再比如我们看参考书,首先去目录查页码,再翻到对应页看内容。
页码和内容“成双成对”。
再比如我们安排出行,如果是拼车,就有下车先后,先去哪再去哪,怎样可以最省时间?怎样可以最省路程?
这也是一类经典现实问题,对应数学的图论,地方是点,路线是边,求最短路径等优化类问题。
Python也提供了非常丰富的数据结构,应用在不同的情况。
本文重点介绍4个常用数据结构:
- 列表list:无序的一组数据,比如一串数字
- 元组tuple:有序的列表,你可以想象成坐标
- 集合set:与数学意义一致,里面元素无重复
- 词典dict:里面元素“成双成对”
这些数据结构很常用,学完后我们就以收入统计作为应用案例来练习。
1、列表 list
在之前的章节里,相信你已经熟悉字符串操作。
其实,字符串是一种特殊的列表,只不过它是Python的基础数据类型,而非数据结构。
因为字符串太常用了,如果还需要每个人自己去操作一个个字符,效率太低。
但,我们也可以用列表的方式来处理字符串的每个字符。
1.1 增加元素:append()
还是那个问题,把字符串反转:
s = 'hello python'l = [] # 准备一个空列表for c in s:l.append(c) # 在列表后面加一个字符s_result = ''for i in range(len(l)-1, -1, -1):s_result += l[i]print(s_result)
是不是感觉有点麻烦?
好,我们看看list有什么特性可以帮我们优化。
1.2 插入元素:insert()
找到一个insert方法,可以在指定下标位置插入元素。
s = 'hello python'l = [] # 准备一个空列表for c in s:l.insert(0, c)s_result = ''.join(l) # 字符串的join函数把列表里的字符连起来print(s_result)
每次都往头上加字符,就是反转。这么一来看起来简单多了。
1.3 反转列表:reverse()
再找找,发现list自带反转功能,它有个reverse()方法。如果字符串能转为list,就容易了。
事实上,所有序列都可以转为list。
s = 'hello python'l = list(s) # 字符串转成字符列表l.reverse() # 列表反转print(''.join(l)) # 字符合并
嗯,更简单了。
根据上面的案例,我们已经掌握了list的大部分操作:
- list(x),把x转为列表
- len(x),获取列表长度
- x.append(a),把元素a加入列表
- x.insert(i, a),在下标为i处插入a
- x.reverse(),列表反转
对于一个数据集,我们最普遍的操作就是“增删查改”(其实这也是大部分程序员的日常工作)。
刚才介绍了增加的两种方式:append()和insert(),接下来介绍剩下的。
先介绍一种Python的生成器写法,它可以快速帮助我们生成一个列表。
1.4 列表生成器
l = [ i for i in range(10) ]
上面生成了一个从0到10(不含)的数字列表。
它等价于下面的代码:
l = []for i in range(10):l.append(i)
Python的生成器,是它区别于其他语言的一大特征,可以让代码更简洁。
比如,我们想生成从0到10的数字平方,或者更复杂点的情况:
l1 = [ i**2 for i in range(10) ]l2 = [ i**2 for i in range(10) if i**2 < 40 ]# [0, 1, 4, 9, 16, 25, 36]
是不是很容易?
其中,第二行代码等价于下面:
l = []for i in range(10):if i**2 < 40:l.append(i**2)print(l)
1.5 列表删查改操作
好,接下来我们先把列表的“删查改”介绍完。
a = [ i for i in range(10) ]# [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]a1 = a.pop(3) # 3,如果不加参数默认是最后一个# [0, 1, 2, 4, 5, 6, 7, 8, 9]a.remove(2) # 找到第一个2再删除它,没有返回值# [0, 1, 4, 5, 6, 7, 8, 9]# a.remove(3) # ValueError,因为找不到3i = a.index(4) # 2,表示下标# i = a.index(2) # ValueError,因为找不到2a.insert(0, 8) # 头部插入新元素# [10, 0, 1, 4, 5, 6, 7, 8, 9]a.sort() # 列表排序# [0, 1, 4, 5, 6, 7, 8, 8, 9]c = a.count(8) # 2,表示8出现2次amin = min(a) # min内置函数,找列表最小值,0amax = max(a) # max内置函数,找列表最大值,9a.extend([10,11,12]) # 一次添加多个值# [0, 1, 4, 5, 6, 7, 8, 8, 9, 10, 11, 12]del a[0] # 用内置函数del按下标删除元素# [1, 4, 5, 6, 7, 8, 8, 9, 10, 11, 12]
注意点:
- remove和pop都是删除操作,但remove不返回,pop返回删除的元素
- index根据值找到第一个符合元素,remove根据值找到第一待删除元素,如果找不到,就会报ValueError
- 用del删除元素时,如果下标超出范围,会报IndexError错误
2、元组 tuple
list用方括号表示,tuple用小括号表示。
tuple其实是一个数学向量。
比如一个坐标(x, y),反过来写就不一定是同一个地儿了。
其实我们已经用过tuple,只不过没有察觉。
x, y = 1, 2t = (3, 4)x, y = t # x=3, y=4
2.1 只读属性
tuple自带的操作方法比较少,只有index()和count(),用法同列表。
那“增删改”怎么办呢?
- tuple是不支持删除和修改的,只能重新生成一个,这就和字符串特性一样:不可变。
- 和字符串一样,tuple、list都支持切片器操作,都用方括号指定区间。
- tuple可以通过”加号”来添加元素,其实列表也可以,但一定要确保是同数据类型相加。
t = (1,2)t += (3, ) # 注意这里,不能少小括号和英文逗号# (1, 2, 3)l = [1,2,3] + [3,4,5]# [1, 2, 3, 3, 4, 5]l[2:5]print(l[2:5])# [3, 3, 4]# tuple是不可变的# 不能删不能改,只能重新生成一个,比如用切片器t = t[1:]# (2, 3)t = (10, ) + t[1:]
2.2 转换类型到列表
如果想要反转怎么办呢?参考字符串,转成list中间态,操作完再转回来。
t = (3, 4, 5, 2, 3)l = list(t)l.count(3) # 2l.sort()t = tuple(l)# (2, 3, 3, 4, 5)
tuple相比list约束更多,所以在性能上会更高。
此外,tuple的向量表达方式,让Python比其他语言在使用时灵活不少。
3、集合 set
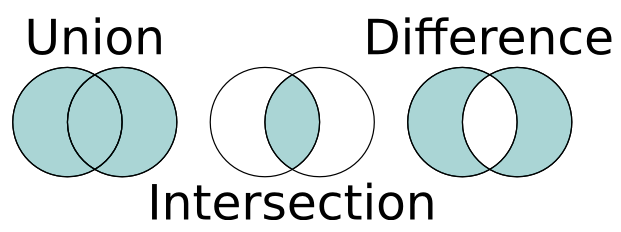
3.1 常用方法
set与数学集合意义一致,有并集、交集、差等运算。
st1 = { 1, 2, 3 }# st = {} # 这种形式用于定义空词典st1.add(2) # 重复# st1: {1, 2, 3}st1.add(4) # 添加不重复# st1: {1, 2, 3, 4}a = st1.pop()# st1: {2, 3, 4}# 删除元素,找不到会报KeyErrorst1.remove(4)# st1: {2, 3}# 删除元素,找不到不报错st1.discard(5)# st1: {2, 3}# 把一个list转成setst2 = set([i for i in range(3,7)])# st2: {3, 4, 5, 6}st = st1.union(st2) # 两个集合的并集# st: {2, 3, 4, 5, 6}st = st1.intersection(st2)# st: {3}st = st1.difference(st2) # s1-s2差集# st: {2}st2.difference_update(st1) # 从s2中删除st1和st2的并集# st2: {4, 5, 6}# 判断两个set是否有交集b = st1.isdisjoint(st2) # Truest1.update({1, 4, 5, 6})# st1: {1, 2, 3, 4, 5, 6}# st2: {4, 5, 6}# 判断st2是否st1的子集st2.issubset(st1) # True# 判断st1是否st2的超集st1.issuperset(st2) # True
set的注意点:
- 不能用{}来定义空set,它表示空的词典
- set和数学意义的集合一致,无重复集合
- discard()和remove()都是删除某个元素,但找不到的情况下,前者不报错,后者报错
- add()添加的是具体的某一个元素,update()是把一个序列里的元素都加入进来并去重
3.2 常见错误
第4点不少人会犯错,尤其是在用字符串的时候要小心。
s = 'hello'st = set(s)# st: {'l', 'e', 'h', 'o'}st.add('python')# st: {'l', 'e', 'h', 'o', 'python'}# update参数是一个序列,world会被当成字符序列st.update('world')# st: {'l', 'd', 'e', 'r', 'h', 'o', 'w', 'python'}
set在实战应用中,经常用来生成一个无重复元素的集合。
如,把一个字符串中每个字符出现的次数统计出来。
s = 'hello world and hello python.'st = set(s)for i in st:print('{}: {}'.format(i, s.count(i)))
4、词典 dict
词典是一种映射,它的元素是键值对key: value,其中key不重复。
上面说的一对空大括号,就表示创建一个空的词典。
为什么要有词典?或者说词典有什么用呢?
你想想看为什么书要有目录,是一个道理。
它主要帮你提高了查找的速度,不然每次你都得一页页翻,直到看见想要的。
回忆下,目前为止,不管是list、tuple、set,还是数据类型str,我们想找其中的元素,都是挨个找,也就是遍历整个序列。哪怕我们用了它们自带的方法,如find(),它本质上也是通过挨个对比来找。
但如果我们本身已经知道了某个数字对应的内容,就像目录的页码对应着某一页的内容,那我们就不必一页页翻查,只要翻到对应页码即可,效率更高。这就是dict的价值所在。
4.1 创建词典
生成dict的方式,主要有这几种:
d1 = {} # 空词典d1 = { 'a':1, 'b':2, 'c':3 } # 直接赋值# {'a': 1, 'b': 2, 'c': 3}d1 = dict(a=1, b=2, c=3) # 参数构造# {'a': 1, 'b': 2, 'c': 3}d1 = { i:i**2 for i in range(5) } # 生成器# {0: 0, 1: 1, 2: 4, 3: 9, 4: 16}d1 = dict.fromkeys(range(5), 'x') # 把一个序列作为key,默认值为x# {0: 'x', 1: 'x', 2: 'x', 3: 'x', 4: 'x'}l1 = ['a', 'b', 'c']l2 = [1, 2, 3]z = zip(l1, l2) # 用zip打包两个序列# list(z): [('a', 1), ('b', 2), ('c', 3)]d1 = dict(z)# d1: {'a': 1, 'b': 2, 'c': 3}
4.2 序列打包和解包
其中,zip()是Python的内置函数,把多个序列打包起来,比如我们可以用它生成一个二维矩阵:
ll = []for i in range(1, 5):ll.append([j**i for j in range(1, 5)])print(list(zip(*ll)))# [(1, 1, 1, 1), (2, 4, 8, 16), (3, 9, 27, 81), (4, 16, 64, 256)]
我们先生成了4个列表,每个列表的值是1,2,3,4的一次方、二次方、三次方、四次方。
然后,我们用zip()打包,打包的意思是把每个列表中第N个元素拿出来组成tuple,最后形成tuple的新列表。
其中*操作符类似解压,把一个列表展开。
l = [ i for i in range(5) ]print(l)# [0, 1, 2, 3, 4]print(*l)# 0 1 2 3 4
4.3 词典应用:工资条
下面,我们就用工资条来演示下dict的使用。
# 从二维序列构造dictnames = [ '张三', '李四', '王五', '赵六' ]salaries = [ 10000, 8000, 20000, 9000]d = dict(zip(names, salaries)) # 把两个序列打包# {'张三': 10000, '李四': 8000, '王五': 20000, '赵六': 9000}# 查王五的工资d['王五'] # 20000# 查 '小明' 在不在工资清单里'小明' in d # False# 找出所有人员l = d.keys()print(list(l))# l: ['张三', '李四', '王五', '赵六']# 找到所有的工资数额v = d.values()print(list(v))# v: [10000, 8000, 20000, 9000]# 想一个个打印对账单for k, v in d.items():print('{} 的工资是:{}'.format(k, v))#李四离职,删除其工资信息del d['李四']print(d)# d: {'张三': 10000, '王五': 20000, '赵六': 9000}
dict的用途非常广泛,比如在restful网站开发中,它经常被用于处理客户端提交和返回的数据。
5、实战案例:收入统计
我们用一个综合案例来加强下今天的学习内容。
5.1 应用背景:运营绩效
运营组有3个员工,昵称分别为:小王、小林、小明。
他们平时的任务是拉新用户,每个月拉新多少用户,直接决定考评绩效,规则:
- 当月拉新至少100人算合格,绩效为C;否则认定为不合格,绩效为D。
- 当月拉新超过300人(含),绩效为B;
- 当月拉新超过500人(含),绩效为A。
个人工资和年终奖,计算如下:
- 单月绩效折算为百分制P=A(100)or B(80)or C(60)or D(0);
- 个人单月工资S=3000+3000*P/100;
- 个人年终奖F,等于月绩效分数加权平均值X,乘以奖金基数T=10万,月份权重W说明如下。
其中,月份权重从1月到12月,其中6月、10月、12月、1月的权重为1.2,7月和8月为0.8,其余为1。
(嗯,618、双11、双12、春节)



假设三人每个月拉新结果如下表,请计算三人每年的收入。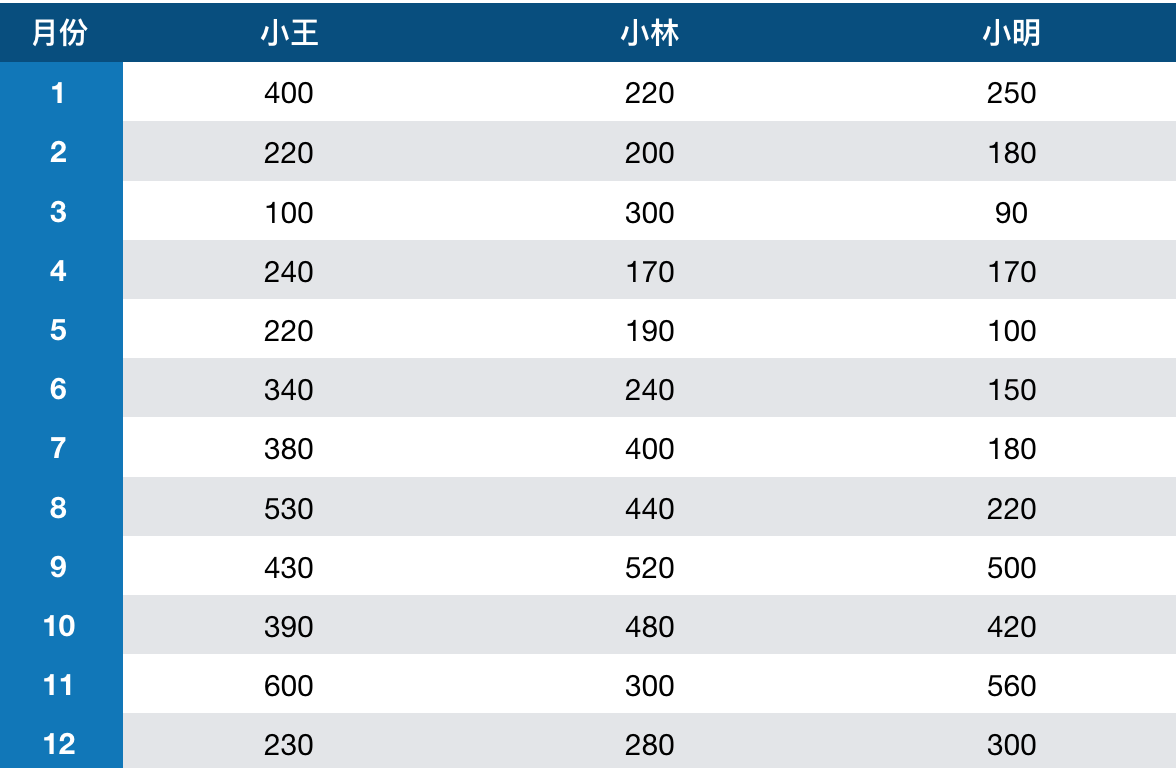
这个综合应用题源于某实际互联网项目团队,代表了一批公司采用的激励政策,相关信息已脱敏。
5.2 问题思路分析
参考思路分析:
- 数据初始化:把拉新数据、月份权重记录到不同list
- 计算每人每月绩效,以及对应的百分制得分
- 计算每人每月工资收入
- 根据权重,计算每人每年奖金收入
- 得出每人每年总收入
5.3 参考代码
参考代码,仅作为参考,不是唯一标准。
这里用Python生成器和内置函数压缩了代码量以节省版面。
如果你还没有熟悉生成器和内置函数,也可以用for-in来实现。
代码没有好坏,只要能解决问题,都是有用的。
# 录入每个人拉新数据names = ['wang', 'lin', 'ming']wang = [400, 220, 100, 240, 220, 340, 380, 530, 430, 390, 600, 230]lin = [220, 200, 300, 170, 190, 240, 400, 440, 520, 480, 300, 280]ming = [250, 180, 90, 170, 100, 150, 180, 220, 500, 420, 560, 300]# 按wang、lin、ming顺序打包,打包后数据以(wang, lin, ming)序形成12个元素growth_zip = zip(wang, lin, ming)# 录入1月~12月年终占比权重,注意下标从0开始weight = (1.2, 1, 1, 1, 1, 1.2, 0.8, 0.8, 1, 1.2, 1, 1.2)# 开始计算每个人每个月的得分,值是list,其中元素记录方式如:('A', 100)score = {'wang':[], 'lin':[], 'ming':[]}for m in growth_zip:for u in range(3):# u=0是wang,u=1是lin,u=2是mingif m[u] < 100:score[names[u]].append(('D', 0))elif m[u] < 300:score[names[u]].append(('C', 60))elif m[u] < 500:score[names[u]].append(('B', 80))else:score[names[u]].append(('A', 100))# 初始化每个人的总收入,以(工资, 年终奖)形式记录income = {'wang':(), 'lin':(), 'ming':()}# 开始计算收入for u, s in score.items():# 根据score计算每个月收入salary = sum([ 3000 + 3000 * p / 100 for (g, p) in s ])# 根据score和weight计算年终奖,累加到incomex = sum([ a * b for a, b in zip([ p for (g, p) in s ], weight) ]) / 12.0bonus = x * 1000income[u] = (salary, bonus)# 输出打印工资条for u, i in income.items():print('员工 {} 年度总收入 {:.2f} 元,其中:工资 {:.2f},年终奖 {:.2f}' \.format(u, i[0] + i[1], i[0], i[1]))
参考答案输出:
5.4 参考代码注释
其中,用到了一个新的内置函数sum(),它用于统计一个整数序列所有元素的总和。
所以,还记得之前“从1加到100,计算总和”这个问题么?在Python中一句话就搞定了:
sum([ i for i in range(1, 101) ]) # 5050
另外温习下Python生成器:
x = sum([ a * b for a, b in zip([ p for (g, p) in s ], weight) ]) / 12.0
这行代码,先生成了一个每月绩效成绩列表,然后把它和weight权重列表打包,这时候数据组成如下:
[(80, 1.2), (60, 1), (60, 1), (80, 1)......(90, 1.2)]
然后用tuple来迭代,并生成两个元素乘积的列表,也就是:把两个列表每个元素相乘后,生成新列表。
这行代码,也等价于下面:
# 生成绩效列表ps = [ p for (g, p) in s ]total = 0for i in range(12):total += ps[i]*weight[i]# 有可能不是整数,一个整数和一个浮点数相除# 得出的数据类型是浮点数x = total / 12.0
一点Python学习窍门:
Python的生成器非常强大,写出来的代码可以非常简洁,但开始时不一定能驾轻就熟,也可以用非常普通的循环来代替,久而久之,当你对循环、累加等模式熟悉后,你就会去想怎样可以更简洁方便,于是就会去更多练习生成器,也就慢慢掌握了。
总结
本节内容主要介绍了4类常见的Python基本数据结构:list、tuple、set、dict。
他们都是某种数据的元素集合,也可以按某种形式互相转化,但他们各自有特性。
- list是无序的序列,支持最多操作
- tuple是有序向量,和字符串一样不可变
- set是无重复元素集合,可以支持数学集合运算,如交、并、差
- dict是成对数据集合,可以快速查找key对应的value,注意key必须是不可变数据,list不能成为key
他们的特性让它们适用于不同的场景,牢固掌握这几个数据结构,有助于实践应用效率。
当然,数据结构还有很多种类型,比如二叉树、Trie树、堆、图……
它们在特性场景下,添加了更多约束,产生了更多特性,适用于某一类问题。
它们和上面4种基本数据结构一样,都是数学抽象的计算机表达方式,都可以通过组合基本数据类型和数据结构实现。
还是“够用”原则:先把4种基本的掌握牢固,它们已经够你应对90%以上常见情况。
作者:程一初
更新时间:2020年8月

若有收获,就点个赞吧
0 人点赞
