之前的章节中,我们已经掌握了Python所有基础内容,但距离实践仍有距离。
就像我们掌握完所有英语语法,却并不能直接用来对话。
我们还需要实践,在实践中积累更多案例,体会在不同情况下应用。
也可以从实践中,获得别人的宝贵经验,提前获知前人测试下来的最佳实践。
比如:
- 遵守
PEP8代码风格规范,让代码更易读更易维护; - 通过日志打印来监测代码运行状况;
- 典型项目工程的目录结构布局,以及默认配置规则。
怎样获得更多的最佳实践呢?参考优秀代码。
尤其是那些经典的开源项目,都会给人启发,比如flask和requests。
虽然,刚入门时我们未必需要去读懂所有源代码,但了解一些经典、常见的用法,会让我们在使用三方模块时不那么吃力。尤其是Python支持多种编程形式(过程、对象、函数),不同的人会有不同的编程风格。
本文内容:
- 代码风格:常用规范和辅助工具
- 程序调试:单步调试和日志打印
- 设计模式:常见模式及其用法
1、代码风格
之前在各个章节中零散介绍过一些常见的代码风格规范,比如命名规范、注释和文档规范等,这里做个小结,同时介绍下编写代码时的辅助工具。
最常见的两套风格规范:《Google开源项目风格指南》、《PEP8规范》。
虽然我们不必像程序员那样100%靠拢规范,但至少遵守一些基本规范,有助于我们有一个高质量的起点。
1.1 基本代码结构
- 用4个空格代表缩进
- 单行最长尽量不超过80
- 顶层类或函数间隔2个空行,类/实例方法间隔单空行
- 头部导入模块,一行一个模块(可以是同个模块中多个元素)
- 每个文件头部声明编码:
# coding=utf-8 - 平时用单双引号字符串,保持内外优先级,三引号用于文档注释
1.2 基本命名规范
- 包名、模块名、函数、方法和变量名都用小写,多词用下划线
_分割 - 常量名用大写,多词用下划线
_分割 - 类名用驼峰形式,如
CircleShape - 命名优先使用缩写形式,如
number->num - 类方法的第一个参数名用
cls - 实例方法的第一个参数名用
self - 不使用Python内置函数名
- 不对外公开的属性用
__开头,但不要同时以其结尾(Python内部属性)
1.3 其他常见写法
- 优先用
with语句读写文件 - 拼接字符串时,优先用
join()而非+ - 在需要迭代元素时优先用
for-in循环 - 需要生成元素列表时,优先用列表生成形式
- 多个变量,优先在单行按序赋值
- 基本判断,用
x if a else y形式 - 区间判断,用
c < a < b形式
1.4 辅助工具
- flake8:静态检查代码规范
- autopep8:按PEP8规范自动格式化代码
安装好VSCode和Python插件后,当你打开某个.py文件,然后右键选择“格式化文档”时(快捷键是ALT+SHIFT+F),VSCode会帮你自动格式化文档。当你没有安装上面两个工具时,它会在右下角弹出安装提示,点击就即可安装。
2、程序调试
Python程序调试有两种方法:
- 断点跟踪
- 日志打印
2.1 断点跟踪
第一种方式,可以结合VSCode方便地观察执行过程。
打开一个.py文件,点击“运行”->“启动调试”,或按F5键,就会弹出一个选项框:
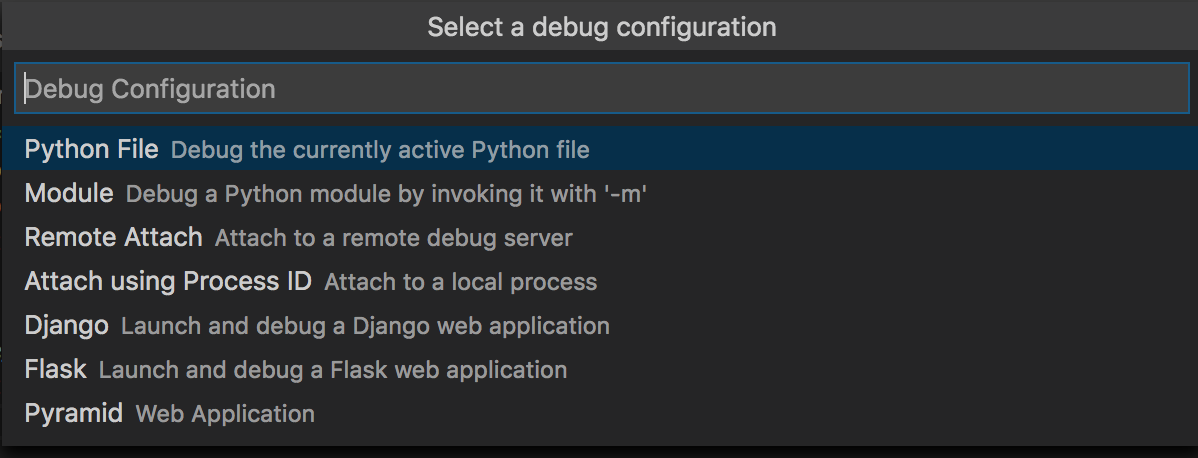
你可以自定义调试配置文件,比如第一项就是调试当前打开的.py文件,其他比如远程调试或者跨进程调试等。
选择调试本地文件后,VSCode就会切换到调试视图。我们可以在代码中设置一个断点(让程序执行到那时停下)。添加方法是在代码行数前面点一下,会出现一个小红点。
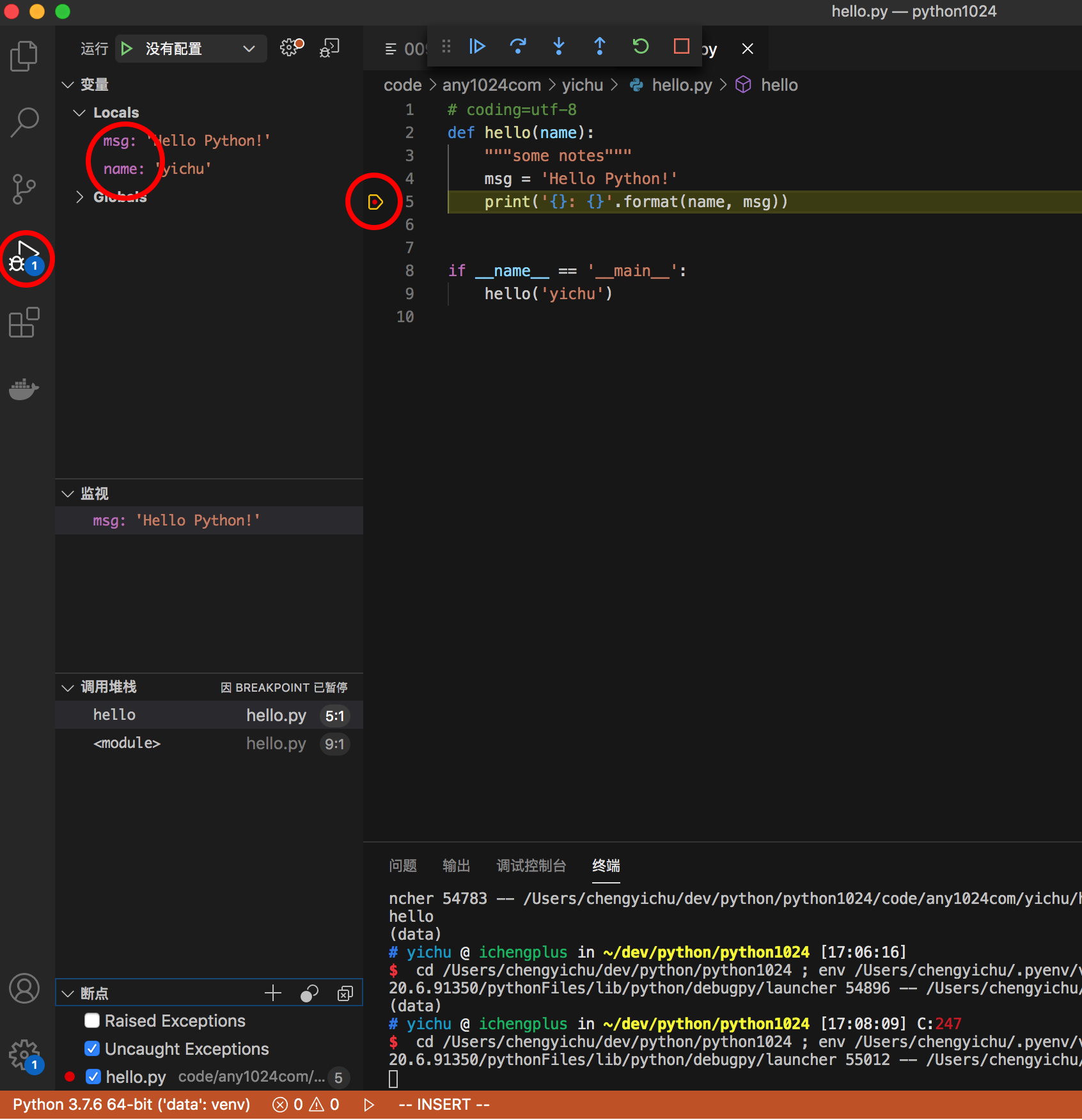
我们可以从最左边看到VSCode的调试视图,然后在左边可以观察到变量值,在代码中,小红点所在的那一行被高亮凸显出来,表示当前卡在这一行(还没执行)。这样我们就可以方便地观察当前执行的状况了。
当我们需要快速调试一个模块中的功能时,可以像上面在模块中添加__name__判断,仅当这个模块所在文件被单独执行时,__name__才会被设置为"__main__"。
2.2 日志打印
另外一种调试方法,是通过日志打印。
最简单是通过print()函数,但当调试完毕后,为了不影响主要功能,还得一个个删除print()语句,而且print()主要是打印到终端屏幕,内容超过了缓冲区,就会丢失,查找也不方便。
更通用方式是日志,用它打印内容到文件,方便查看也不用移除。后续程序执行时,还能通过开关控制打印不同级别的日志信息。比如在正式使用时,只打印错误信息;在调试阶段打印更详细信息等。
Python提供了日志标准模块: logging,引入后简单配置即可使用。
import logginglogging.basicConfig(level=logging.INFO)logging.debug("This is a debug log.")logging.info("This is a info log.")logging.warning("This is a warning log.")logging.error("This is a error log.")logging.critical("This is a critical log.")
logging让你可以指定不同打印级别:DEBUG、INFO、WARNING、ERROR、CRITICAL等,设置的级别会影响输出信息多少。
比如,当设置level=logging.INFO时,logging.debug()的信息就不会包含在输出。如果指定level=logging.ERROR时,只有logging.error()及以上级别的信息才会被输出。
这样,我们就可以用一个开关,控制输出信息的级别了。
此外,logging可以通过简单配置,把信息输出到不同的媒介,比如文件、终端甚至某个网络服务。
我们来配置它同时输出到终端和文件。
import logginglogger = logging.getLogger('hello.test')logger.setLevel(logging.DEBUG)log_fmt = logging.Formatter('%(asctime)s : %(name)s : %(levelname)s : %(message)s',datefmt='%Y-%m-%d %H:%M:%S')# 用FileHandler输出到文件f_handler = logging.FileHandler('hello.log')f_handler.setLevel(logging.ERROR)f_handler.setFormatter(log_fmt)# 用StreamHandler输出到Consolec_handler = logging.StreamHandler()c_handler.setLevel(logging.DEBUG)c_handler.setFormatter(log_fmt)# 添加两个Handlerlogger.addHandler(f_handler)logger.addHandler(c_handler)logger.debug("This is a debug log.")logger.info("This is a info log.")logger.warning("This is a warning log.")logger.error("This is a error log.")logger.critical("This is a critical log.")
这里我们定义了一个logger 对象,然后定义了两个Handler 对象,其中一个用来输出到文件,另一个输出到终端,输出格式用Formatter定义,包含时间、日志名称、日志等级,以及输出的信息。
从案例中可以看到,我们把FileHandler定义为ERROR级别,把StreamHandler定义为DEBUG级别。当我们输出各级别信息时,logger对象关联的所有Handler都会按级别输出信息。
结果中,终端打印了所有5条信息,而打开同文件夹的hello.log文件,会看到只有ERROR和CRITICAL级别的两条信息。
3、设计模式
第一次使用logging打印日志时,你也许会觉得麻烦,感觉需要配置很多信息。
但是在实际使用过程中,你会发现它非常灵活,比如有些项目需要统一收集信息,那就自己写一个Handler,把信息传递给指定的服务器。使用时只需要多关联一个Hander即可。
在大规模的运维项目中,比如统一管理上千台服务器,我们会把日志通过网络统一收集处理。
这种灵活的特性,来自于它的精巧设计。
软件工程实践中,人们提炼出了一批经典设计,统称为“设计模式”。
比如,上面logging模块中,至少应用到了3种设计模式:
- 工厂方法模式(Factory Method)
- 单例模式(Singleton)
- 责任链模式(Chain of Responsibility)
这3个也是很多三方模块会使用的设计模式,我们就以logging为例来理解下它们的形式,方便以后遇到新模块时掌握更快。
你可以在VSCode中,选择这个方法,然后按F12就可以打开logging 的源代码,并在VSCode左边的大纲视图里方便浏览。logging源代码并不复杂,共3个文件,加起来不到5K行代码。
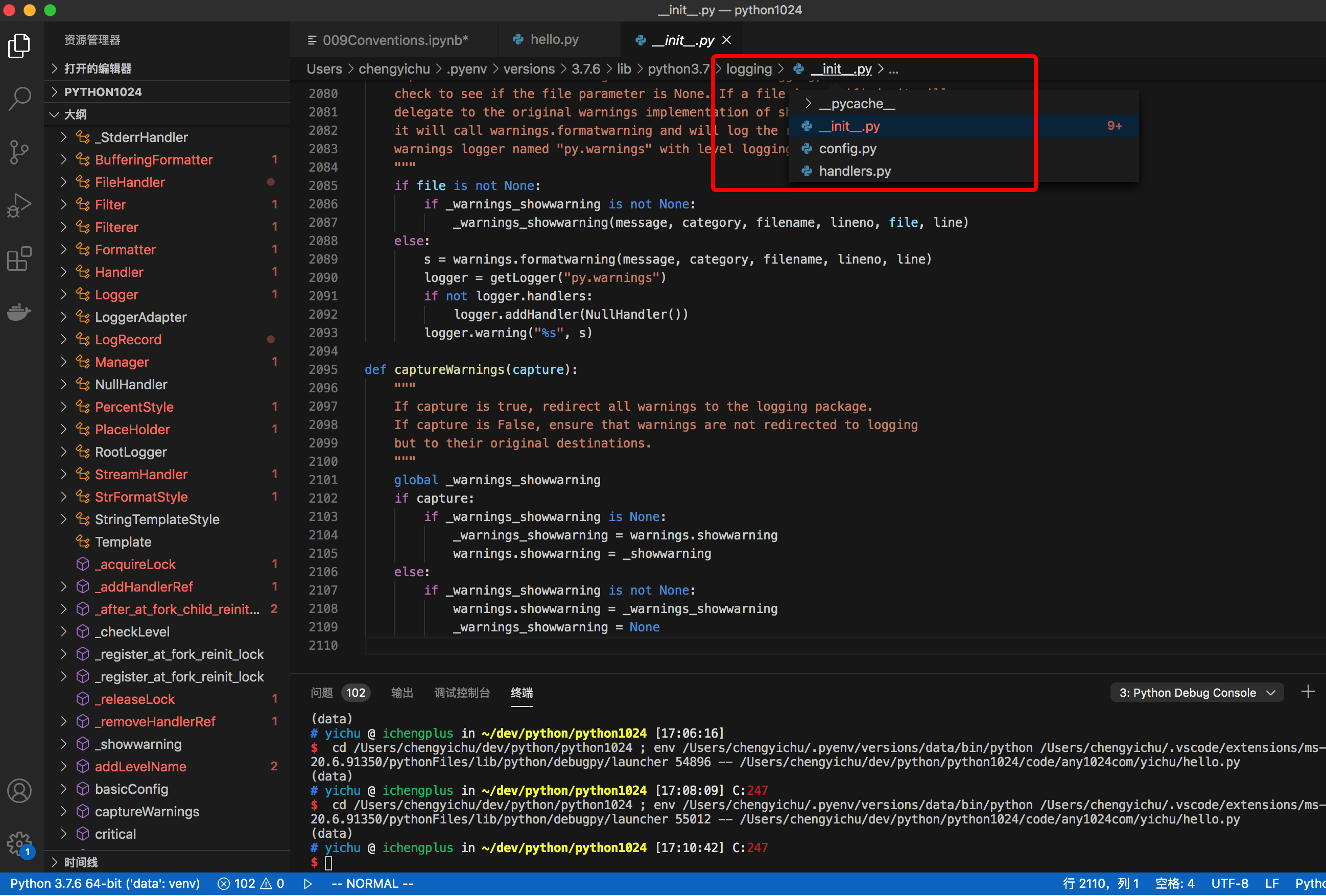
但是想要读懂它,至少得了解刚才说的3类设计模式。
当然,这里不会直接教你读源代码,而是把上面3类设计模式抽取出来,用例子来说明。
3.1 工厂方法和单例模式
我们在打印日志时,用的是logger 实例,在面向对象章节中,我们知道要获得一个类的实例,可以用下面的方式:
class Logger(object):"""some notes"""def __init__(self, name):self.name = namelogger = Logger('hello.test')
但,logging中并非这样获得实例,而是通过模块的一个顶级函数logging.getLogger()来获得。
这是一种工厂方式,也就是由一个外部的对象,来负责某个类的实例化。
class Logger(object):def log(self, msg):print(msg)class Manager(object):__logger = None@classmethoddef getLogger(cls):if cls.__logger is None:cls.__logger = Logger()return cls.__loggerlogger = Manager.getLogger()logger.log('Hello Python!')
可以看到,我们可以用Manager的类方法getLogger()获取Logger的实例。
而且,这个实例不管在哪里用,都是同一个实例。
这就是第二种设计模式:单例模式。
单例模式让我们可以在全局使用同一个实例,比如我们只需要在开始配置一次,后面就能随时使用同一个logger对象了。
3.2 责任链模式
我们在logging配置时,可以添加很多个Handler的子类,比如FileHander、StreamHandler,分别对应文件和通用流,实际上底层数据传送都是StreamHandler完成的。
当我们通过调用debug()、info()、warning()方法输出信息时,logging会遍历所有关联的Handler对象,如果它们设置的信息级别“够”,就会“站出来”处理信息,处理完后会继续往后传递,直到所有Handler都“经手”过。
class Logger(object):def __init__(self):self._handlers=[]def debug(self, msg):for h in self._handlers:if self._level <= h.get_level():h.handle(msg)def set_level(self, level):self._level = leveldef add_handler(self, handler):self._handlers.append(handler)class Manager(object):__logger = None@classmethoddef getLogger(cls, level):if cls.__logger is None:cls.__logger = Logger()cls.__logger.set_level(level)return cls.__loggerclass AbstractHandler(object):"""抽象类"""def __init__(self, level):self._level = leveldef get_level(self):return self._leveldef handle(self, msg):raise NotImplementedError('Use Handler Subclasses')class FileHandler(AbstractHandler):def handle(self, msg):print('File handler: {}'.format(msg))class ConsoleHandler(AbstractHandler):def handle(self, msg):print('Console handler: {}'.format(msg))logger = Manager.getLogger(2)logger.add_handler(FileHandler(1))logger.add_handler(ConsoleHandler(2))logger.debug('Hello Python!')
示例中,我们定义了一个抽象类AbstractHandler,Python中并没有内置抽象类,但我们可以通过添加一个没有实现的方法来实现。比如我们增加了一个handler()方法,但不能直接被调用,一旦调用就会发出NotImplementedError的错误信息。
我们通过继承这个抽象类,定义了FileHandler和ConsoleHandler两个实际“干活”的类,并定义了它们对应的等级(用一个整数代表)。然后我们把它们的实例“关联”到logger实例,其实就是放入其内部的一个列表。同时,我们也为Logger实例增加了level信息。
在调用debug()方法时,我们遍历那些添加到logger实例内部列表的Handler,观察它们的level与 logger设置的level对比,满足条件的才处理日志信息。
这样,我们未来就可以通过继承增加更多Handler子类,只需要加入logger实例的列表,就能同时满足日志输出需求了。
设计模式还有很多种,它们并不局限于某一种编程语言,而是更高维度的抽象。
如果对设计模式感兴趣,推荐一本不错的书:《Head First设计模式》,其中讲解了更多设计模式。
总结
本文主要介绍了一些开发中常见的规约,它们是人们在实践中总结出的经验。
虽然违反它们并不会让你的程序无法运行,但它们可以帮我们避免常见错误,提升代码质量。
这个Python入门系列到这里就结束了,想要融汇贯通,更多在于实践。
后面我还会陆续更新一些应用类的文章,比如自动化办公、数据分析、Web开发等,可以结合起来实践学习。
好啦,下期再会!
作者:程一初
更新时间:2020年8月

若有收获,就点个赞吧
0 人点赞
