已上传GitHub:https://github.com/pantom2077/aljcscan
python3实现检查网页中的暗链
原理:通过爬虫获取网页中的URL链接,后进行访问对返回的数据包进行关键字匹配,如果匹配到了就会保存相关的网址匹配到的关键字。
更新
1 selenium请求
同事反馈说有的没有检测到
- 第一个考虑指纹没匹配上,后来发现不存在这样的问题。
- 第二个考虑是爬虫没有爬到
- 然后主动发包测试发现返回的是404,应该是网站做了防护,之前使用的是requests 数据包,如果其他网站校验了其他请求包那么就会很难搞。
- 于是用了selenium 模拟浏览器请求,但是速度要慢,消耗的资源要多-后面在优化吧。
测试效果
以前: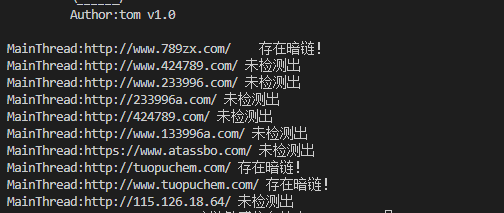
更新后: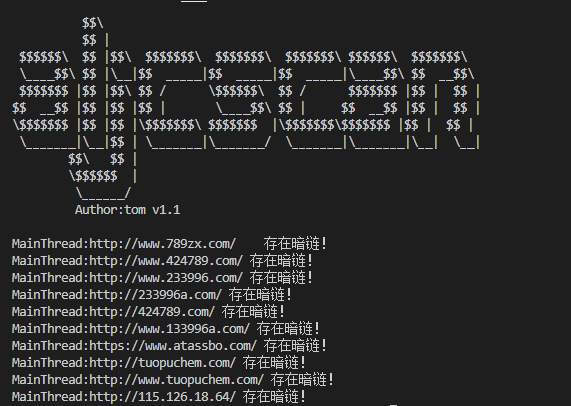
2.报告输出
如果是外链查出来还要去找对应扫描的目标网站,稍微优化了一下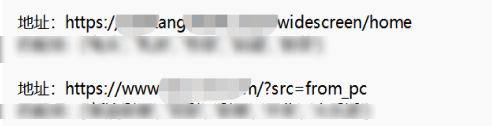
以往内容
关键字
自己可以根据想要检查的内容在根目录的rules.txt里面添加
前置条件
需要安装chrome浏览器脚本使用
参数: ``` python39.exe .\aljcscan.py -h usage: aljcscan.py [-h] [—targets TARGETS] [—files FILES] [—outname OUTNAME] [—Thread THREAD] [—aljc ALJC][--aljcall ALJCALL]
Process some integers.
optional arguments: -h, —help show this help message and exit —targets TARGETS information gathering for SubDomain —files FILES Save subDomain info to Files —outname OUTNAME Save outname —Thread THREAD Thread —aljc ALJC Scan for all sensitive words —aljcall ALJCALL Scan for sensitive words ```
—targets
—Thread
—aljc
—aljcall
使用示例
检查当前的网页(不爬虫)
python39.exe .\aljcscan.py —targets .\targets.txt —aljc True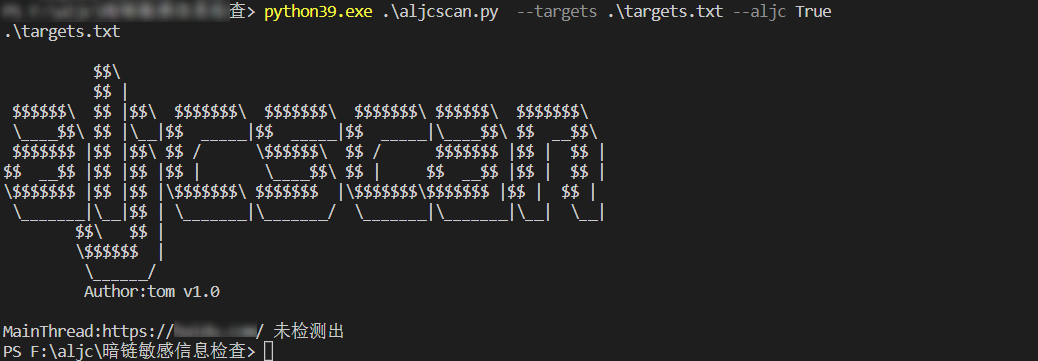
爬虫各个URL后进行检查
python39.exe .\aljcscan.py —targets .\targets.txt —aljcall True —Thread 20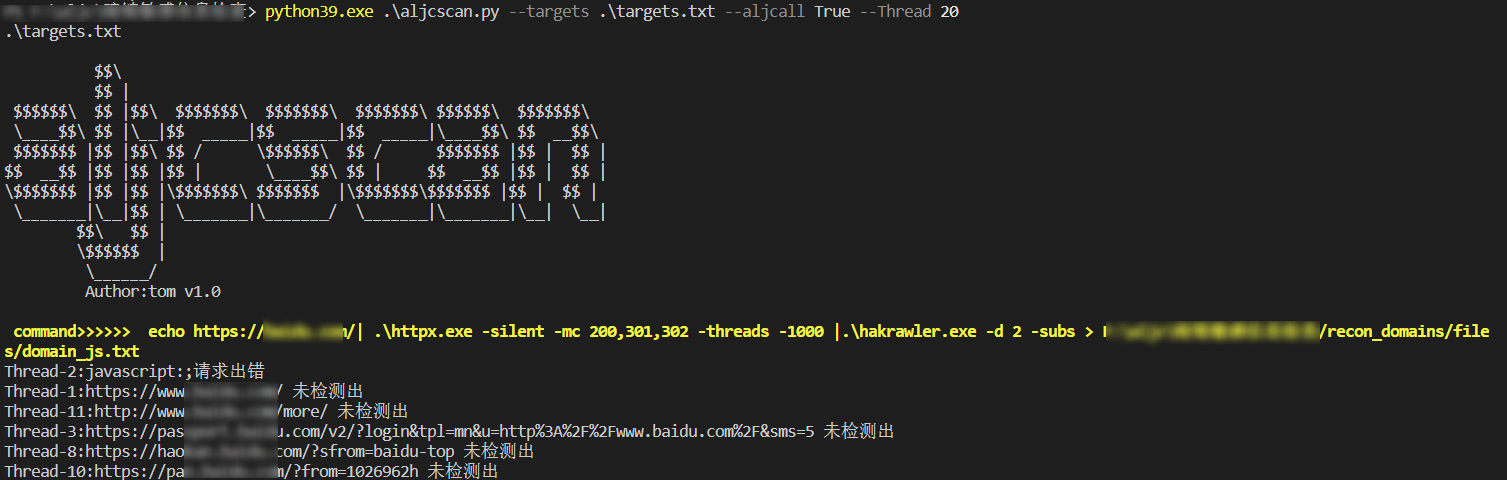
输出
输入到当前目录 result.txt
有一些相关的网站会误报需要自己识别一下。比如下面百度健康,匹配到一些敏感关键字,彩票网站会匹配到一些博彩相关。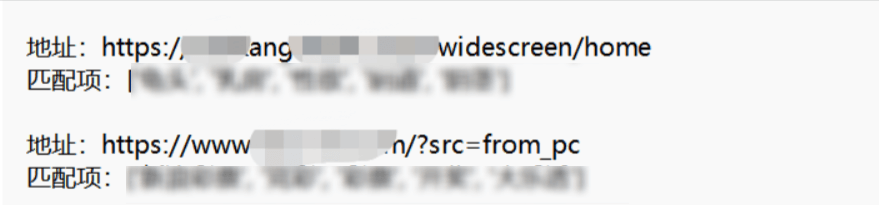
参考
https://github.com/projectdiscovery/katana
https://github.com/hakluke/hakrawler
https://github.com/projectdiscovery/httpx
DC_find 链接找不到了

若有收获,就点个赞吧
0 人点赞
