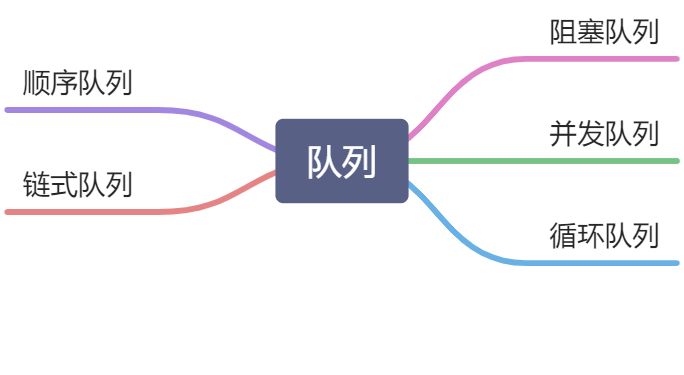
1. 队列的定义
队列,顾名思义,就是一种类似于日常生活中排队的数据结构。假设我们到银行柜台排队办理业务,柜台的服务人员必定先处理队头人员的业务,当有新人排队时,一般都排在队尾。
类似于排队,遵循先进先出,后进后出的数据结构,我们成为队列。
2. 队列的实现
队列可以用链表、数组实现。使用数组实现的队列称为顺序队列,使用链表实现的队列称为链式队列。下面我们一一介绍。
2.1 顺序队列
当我们使用数组实现队列时,首先要考虑的问题是:数组的哪一端作为队头,哪一端作为队尾?
显而易见,应该使用数组头部作为队头,使用数组尾部作为队尾,为什么呢?
若我们采用数组头部作为队尾,那么每次入队时,就必须要进行数据搬移工作,效率非常低下。
虽然将数组头部作为队头也会进行数据搬移工作,但我们可以通过一系列的优化手段,降低其时间复杂度。
- 我们准备两个指针,表明队头、队尾的位置;
- 当入队时,队尾指针后移,当出队时,队头指针后移,这样就实现了时间复杂度为
 的入队、出队操作。
的入队、出队操作。
那么有同学会问了,这样的话不就会造成一部分内存浪费了吗?事实确实如此,因此我们需要继续优化:
- 当队尾指针指向数组尾部时,此时若是数组中仍有空闲位置,则将head~tail间的元素搬运到0~(tail-head)位置来,这样就可以继续插入了。
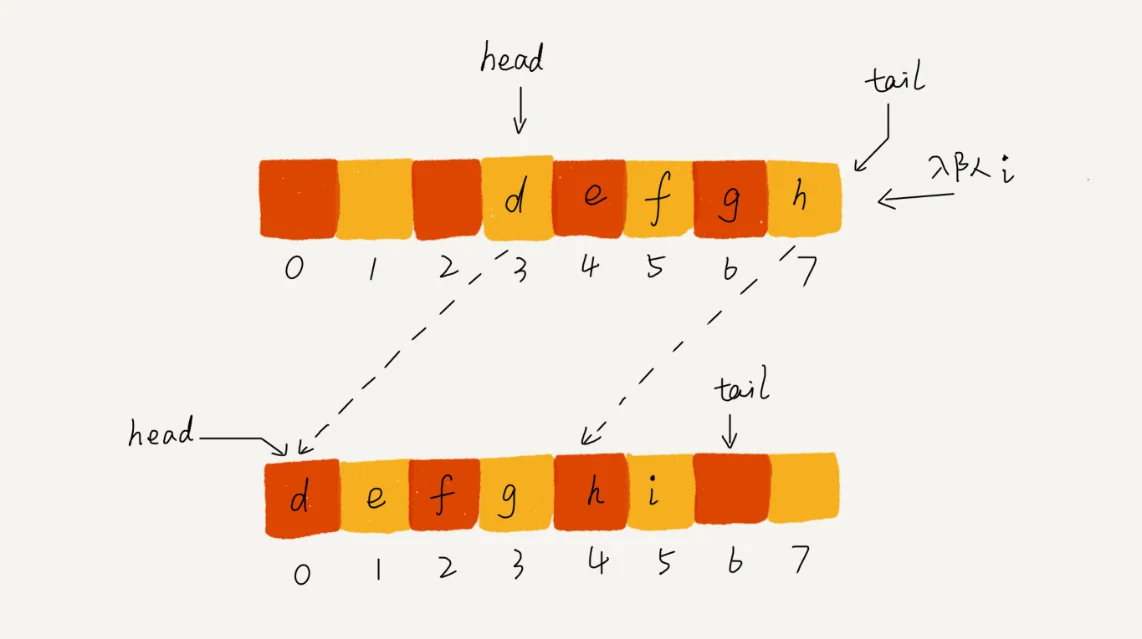
接下来我们分析一下时间复杂度:
- 出队操作因不会触发数据搬移,因此其时间复杂度为
- 入队时,若不涉及数据搬运,则时间复杂度为<最好时间复杂度>
- 入队时,若不涉及数据搬运,则时间复杂度为
 <最坏时间复杂度>
<最坏时间复杂度>
那么平均时间复杂度呢?
分析整个入队过程,假设数组容量为n,那么在n-1次的时间复杂度为入队操作后,第n次时间复杂度会提升到,此后会一直循环这个过程,直到队满,那么将时间复杂度为的这一次操作均摊到其他n-1次操作后,我们可以得出平均时间复杂度为,也就是最好时间复杂度。
具体代码实现如下:
class CArrayQueue{public:CArrayQueue(const int &ncount = 10) : m_ncount(ncount){if (nullptr != m_strData){delete m_strData;m_strData = nullptr;}m_strData = new std::string[ncount];if (nullptr == m_strData){return;}}~CArrayQueue(){if (nullptr != m_strData){delete[] m_strData;m_strData = nullptr;}}int size(){return m_ntail - m_nhead;}bool empty(){return m_nhead == m_ntail;}bool full(){return size() == m_ncount;}bool enqueue(const std::string &strElem){if (full()){return false;}if (m_ntail == m_ncount){int ntemp = 0;// 执行一次数据搬移操作for (int i = m_nhead; i < m_ntail; ++i){m_strData[ntemp++] = m_strData[i];}m_ntail = m_ntail - m_nhead;m_nhead = 0;}m_strData[m_ntail++] = strElem;return true;}bool dequeue(std::string &strElem){if (empty()){return false;}strElem = m_strData[m_nhead++];return true;}void print(){for(int i = m_nhead; i < m_ntail; ++i){std::cout << "队列元素_" << i << "内容:" << m_strData[i] << std::endl;}}private:std::string *m_strData = nullptr; // 队列内容int m_ncount = 0; // 队列容量int m_nhead = 0; // 队首指针int m_ntail = 0; // 队尾指针};
2.2 链式队列
链式队列采用链表实现,我们使用head、tail两个指针分别记录队头,队尾,当入队时,tail->next=new_node,tail=new_node即可,当出队时,new_node->next=head->next,head=new_node。
下面时整个流程示意图: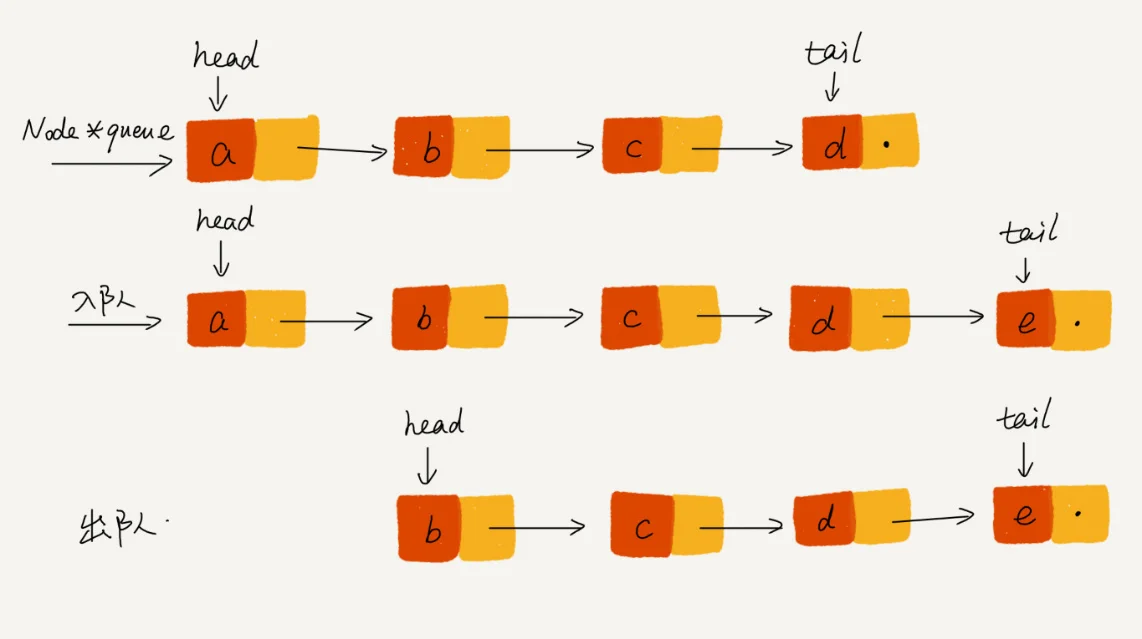
代码如下:
struct SNode{std::string m_strData;SNode *m_next;};class CListQueue{public:CListQueue(){m_head = new SNode;if (nullptr == m_head){return;}m_head->m_next = nullptr;m_first = m_last = nullptr;}~CListQueue(){SNode *node = nullptr;while (nullptr != m_head->m_next){node = m_head;m_head = m_head->m_next;delete node;node = nullptr;}}int size(){SNode *temp = m_first;int nb = 0;while (nullptr != temp){nb++;temp = temp->m_next;}return nb;}bool empty(){return 0 == size();}bool enqueue(const std::string &strElem){SNode *node = new SNode;if (nullptr == node){return false;}node->m_strData = strElem;node->m_next = nullptr;if (0 == size()){m_first = m_last = node;m_head->m_next = node;return true;}m_last->m_next = node;m_last = m_last->m_next;return true;}bool dequeue(std::string &strElem){if (empty()){return false;}strElem = m_first->m_strData;SNode *temp = m_first;m_first = m_first->m_next;m_head->m_next = m_first;if (nullptr != temp){delete temp;temp = nullptr;}}void print(){SNode *temp = m_first;int nb = 0;while (nullptr != temp){std::cout << "队列内容:" << temp->m_strData << std::endl;temp = temp->m_next;}}private:SNode *m_head; // 头节点SNode *m_first; // 第一个节点SNode *m_last; // 最后一个节点};
3. 循环队列
上述的顺序队列虽然经过优化之后,效率已经可以了,但是在某些情况下时间复杂度还是退化为。那么我们如何继续优化呢?
我们注意到,时间复杂度退化为的时候,恰好是搬运数据的时候,那么我们如何避免数据搬运呢?
答案就是我们将数组头部与尾部连接起来,这样就可以省去数据搬运的过程。
具体结构如下图所示: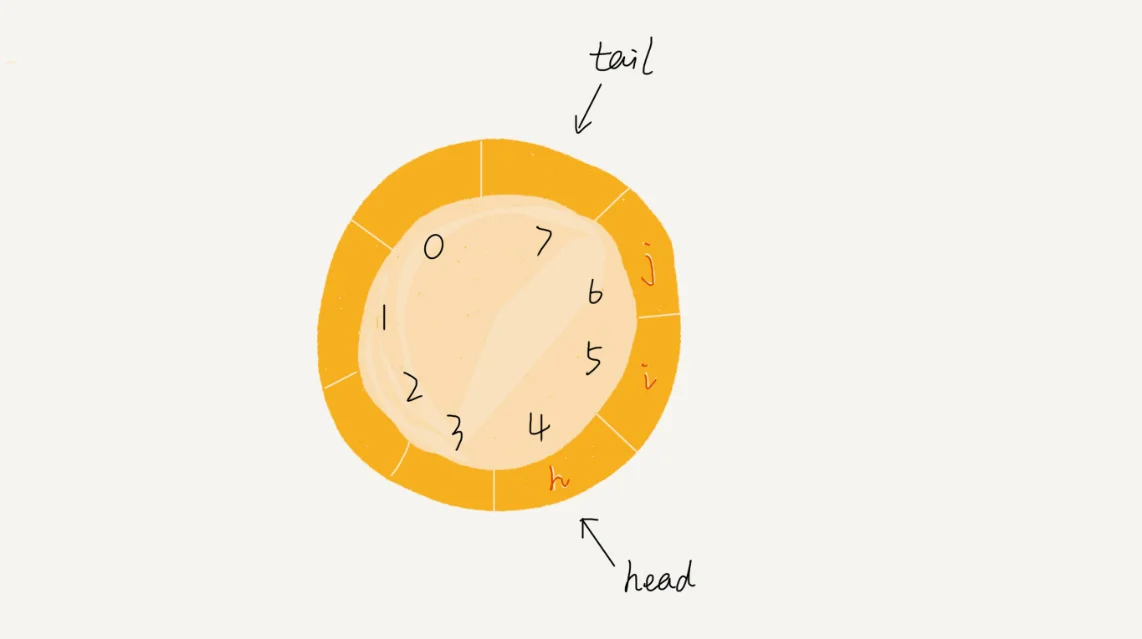
看上图可知,当队尾指针达到数组末尾时,并不会增长到8,而是会变为0,这样数据就可以继续入队,我们也通过这一方法成功的避免了数据搬移工作。
循环队列的原理看起来很简单,但是其代码实现很复杂,首先我们需要明确,如何判断队满还是队空?还是依赖于head=tail这一条件判断吗?显示不是!!因为我们发现当队满或队空是都会满足这一条件。因此需要做一些取舍:
- 采用
head=tail这一条件作为循环队列为空的判定条件 - 牺牲一个存储单元,当满足
(tail + 1) % count = head时,判定循环队列满。
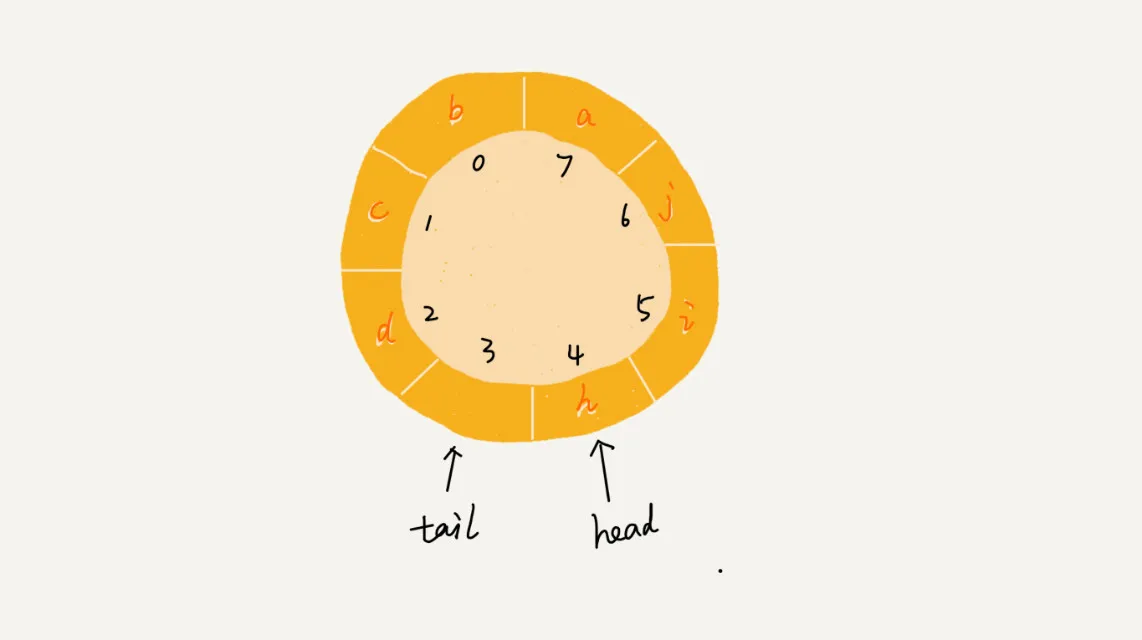
经过上述分析可知,队尾、队头指针可能会由8变为0,那么如何实现这一过程呢?我们仅需要对自增后的指针取模即可,即tail=(tail+1)%ncount head=(head+1)%ncount,同理,计算循环队列元素个数的公式为:size=(tail - head + ncount) % ncount。
代码如下:
class CLoopQueue{public:CLoopQueue(const int &ncount = 10) : m_ncount(ncount){if (nullptr != m_strData){delete m_strData;m_strData = nullptr;}m_strData = new std::string[ncount];if (nullptr == m_strData){return;}}~CLoopQueue(){if (nullptr != m_strData){delete[] m_strData;m_strData = nullptr;}}int size(){return (m_ntail - m_nhead + m_ncount) % m_ncount;}bool empty(){return m_nhead == m_ntail;}bool full(){return (m_ntail + 1) % m_ncount == m_nhead;}bool enqueue(const std::string &strElem){if (full()){return false;}m_strData[m_ntail] = strElem;m_ntail = (m_ntail + 1) % m_ncount;return true;}bool dequeue(std::string &strElem){if (empty()){return false;}strElem = m_strData[m_nhead];m_nhead = (m_nhead + 1) % m_ncount;return true;}void print(){if (m_nhead < m_ntail){for(int i = m_nhead; i < m_ntail; ++i){std::cout << "队列元素_" << i << "内容:" << m_strData[i] << std::endl;}}else{for(int i = m_nhead; i < m_nhead + m_ncount; ++i){std::cout << "队列元素_" << i % m_ncount << "内容:" << m_strData[i % m_ncount] << std::endl;}}}private:std::string *m_strData = nullptr; // 队列内容int m_ncount = 0; // 队列容量int m_nhead = 0; // 队首指针int m_ntail = 0; // 队尾指针};

若有收获,就点个赞吧
0 人点赞
