1.概述
二分搜索我们都知道,这是一种很高效的搜索算法,但二分搜索算法也有很大的局限性:要求基础数据必须是有序的且存储结构连续,这样才可以实现随机访问,因此我们常见到的二分搜索都是基于数组实现的,那么如果基础数据是链表形式的呢,我们有办法实现类似二分搜索这样高效的搜索算法吗?自然是有的,那就是我们今天要学的跳表。
2.详解
2.1 基础概念
跳表:就是带有多层索引的链表。<br /> 对于一个单链表来说,即使单链表中存储的数据是有序的,我们要查询一个数据也需要从头开始遍历整个链表,时间复杂度为,效率很低。<br /> 那么如何提高单链表的查找效率呢?如果我们像图中一样,对单链表建立一级索引,查找起来是不是会更快一点?每两个节点提取一个节点到上一层,这样索引所在的这一层被称为**索引层,**图中down表示down指针,指向下一级节点。<br />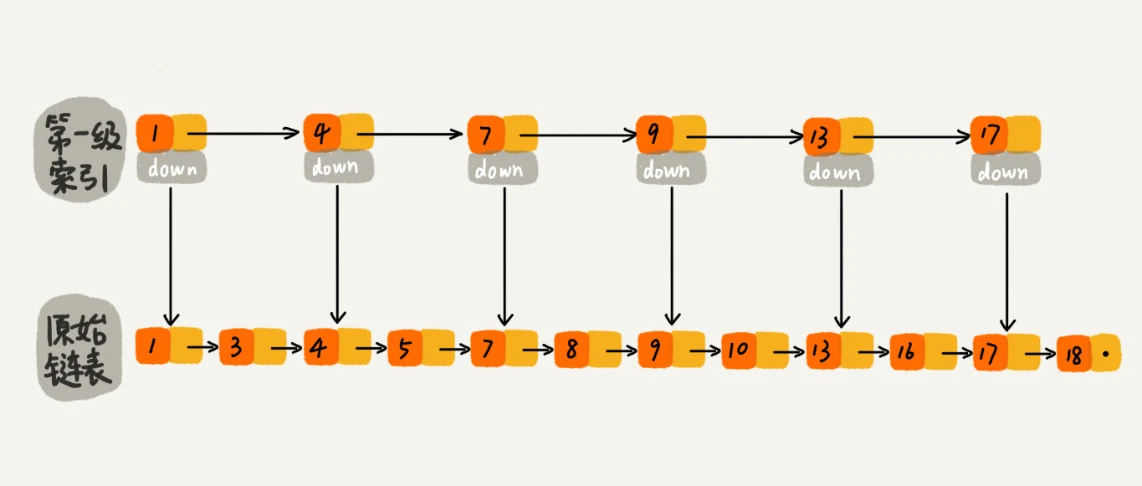<br /> 我们会发现,若是查找16节点,单链表时需要遍历10次,而建立一级索引之后只需要7次,效率提高不少。<br /> 那么如果我们再对第一级索引建立二级索引,效率会不会进一步提升呢?从下图可以看出,这次我们仅需要遍历6个节点。若是数据量非常大,可以达到1000、10000等,效率的提升无疑是非常巨大的。<br />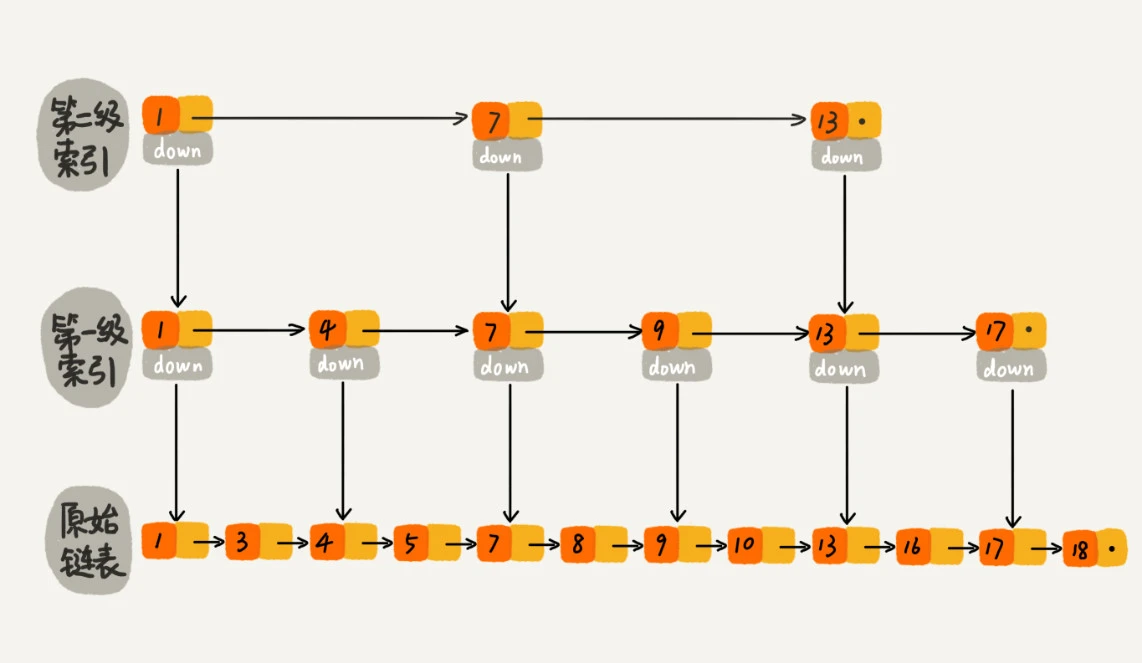
2.2 效率分析
时间复杂度:
 。
。从2.1节分析可以看出,若是我们每两个节点提取出来一个到上一级索引,假设链表长度为,最高级索引有两个结点,那么第一级索引的长度为,第二级索引的长度为,以此类推,第级索引的长度为。所以索引层的高度为,加上原始链表,则高度为。假设每一层索引的查找次数为m,那么整体的时间复杂度为。<br /> m取值到底是多少呢?先说结论:每一层m都不会超过3。原因是:高层索引是由底层索引每两个筛选出来的,因此其到下层索引查找时,查找的范围也只是在上层的两个索引加上低层中间的索引。因此时间复杂度为。
空间复杂度:
 。
。从时间复杂度的分析可以看出:索引层的数量为一个等比数列,因此结果为
 ,因此空间复杂度为。
,因此空间复杂度为。
2.3 插入和删除
跳表可以实现很高效的插入、删除,复杂度均为
。跳表插入
回顾单链表插入,我们需要通过查找来确定要插入的位置,跳表插入也是如此。<br /> 与单链表不同的是,跳表插入需要考虑索引层的问题,否则两个索引节点间可能会存入大量的数据,极端情况下跳表会退化单链表。<br /> 那么如何控制新插入的节点要插入哪几层索引呢?通常我们会采用随机数的方式确定该数据插入的索引层数。代码如下:
```cpp void CSkipList::Insert(const DATA_TYPE &value) { CNode *pNewNode = new CNode; if (nullptr == pNewNode) {
return;
}
int level = RandomLevel(); pNewNode->SetData(value); pNewNode->SetLevel(level);
std::vector
vecNode(level, m_pHead); CNode *pNode = m_pHead; for (int i = level - 1; i >= 0; —i) { while (nullptr != pNode->GetIdxList()[i] && pNode->GetIdxList()[i]->GetData() < value){// 找到每一级索引的最后一个小于value的节点pNode = pNode->GetIdxList()[i];}// 将该节点放入列表,等待插入vecNode[i] = pNode;
}
for (int i = 0; i < level; i++) {
pNewNode->GetIdxList()[i] = vecNode[i]->GetIdxList()[i];vecNode[i]->GetIdxList()[i] = pNewNode;
}
if (m_nLevel < level) {
m_nLevel = level;
} }
int GetRandom()
{
static int _count = 1;
std::default_random_engine generator(time(0) + _count);
std::uniform_int_distribution
int CSkipList::RandomLevel() { int level = 1; for (int i = 1; i < SKIPLIST_HEIGHT; ++i) { if (1 == (GetRandom() % 3)) { level++; } } return level; }
- 跳表删除跳表删除基本是插入的反操作,需要特别注意的是,需要同步删除索引层的相关节点。代码如下:```cppbool CSkipList::Remove(const DATA_TYPE &value){std::vector<CNode *> vecNode(m_nLevel, nullptr);CNode *pNode = m_pHead;for (int i = m_nLevel - 1; i >= 0; --i){while (nullptr != pNode->GetIdxList()[i] && pNode->GetIdxList()[i]->GetData() < value){// 找到每一级索引的最后一个小于value的节点pNode = pNode->GetIdxList()[i];}vecNode[i] = pNode;}if (nullptr != pNode->GetIdxList()[0] && pNode->GetIdxList()[0]->GetData() == value){// 找到要删除的节点CNode *pDelNode = pNode->GetIdxList()[0];for (int i = m_nLevel - 1; i >= 0; --i){if (nullptr == vecNode[i]){continue;}if (nullptr != vecNode[i]->GetIdxList()[i] && vecNode[i]->GetIdxList()[i]->GetData() == value){vecNode[i]->GetIdxList()[i] = pDelNode->GetIdxList()[i];}}if (nullptr != pDelNode){delete pDelNode;pDelNode = nullptr;}}return true;}

若有收获,就点个赞吧
0 人点赞
