1. 栈的定义
关于栈这种数据结构,我们有一个生动形象的比喻。
我们把栈空间比作一摞盘子,每次放盘子的时候只能在盘顶放,取得时候也只能在盘顶取,不能从中间任意抽取。
事实上,满足这种只在一端进行操作,后进先出,先进后出的数据结构,就称为栈。
我们再仔细想一想,若想满足上述情况,我们用链表/数组也可以实现,为什么还要发明栈这种数据结构?
确实!数组和链表都可以满足上述条件,但是除了满足上述条件,其暴露了更多的操作接口,这样就使得用户可以随意更改我们的结构,也就违反了我们设计的初衷。因此 ,当实际应用场景满足先进后出,后进先出的条件时,我们优先选用栈这种数据结构。
2. 栈的分类
在第一小节中,我们提到数组和链表都可以实现栈,那么想对应的,就会有两种形式的栈。
使用数组实现的栈称为顺序栈,使用链表实现的栈称为链式栈。
2.1 顺序栈
当我们选用数组实现栈时,我们需要考虑,数组的哪一端作为栈顶呢?答案显而易见,要使用数组尾部作为栈顶,这样就可以避免大量的数据搬移工作。
下面我们看一下代码实现:
using data_type = int;class CStack{public:CStack(int ncount):m_ncount(ncount){if (nullptr != m_data){delete m_data;m_data = nullptr;}m_data = new data_type[n];if (nullptr == m_data){return;}}bool push(const data_type &elem){if (m_ncount == m_nindex){return false;}m_data[m_nindex] = elem;++m_nindex;}bool pop(data_type &elem){if (0 == m_nindex){return false;}elem = m_data[m_nindex - 1];--m_nindex;}private:data_type *m_data = nullptr; // 栈元素int m_ncount = 0; // 栈容量int m_nindex = 0; // 栈顶指针(指向当前栈顶的下一个)}
通过上述代码,我们很简单就可以判断出时间复杂度为 ,空间复杂度为。
,空间复杂度为。
上述代码中,栈的大小是固定不变的,当栈满以后,就会出现入栈失败的情况,那么如何解决这种问题呢?
很简单,我们会想到使用动态数组,当栈空间不够时,申请一块新的内存,将旧数据搬运进去即可。过程示意图如下: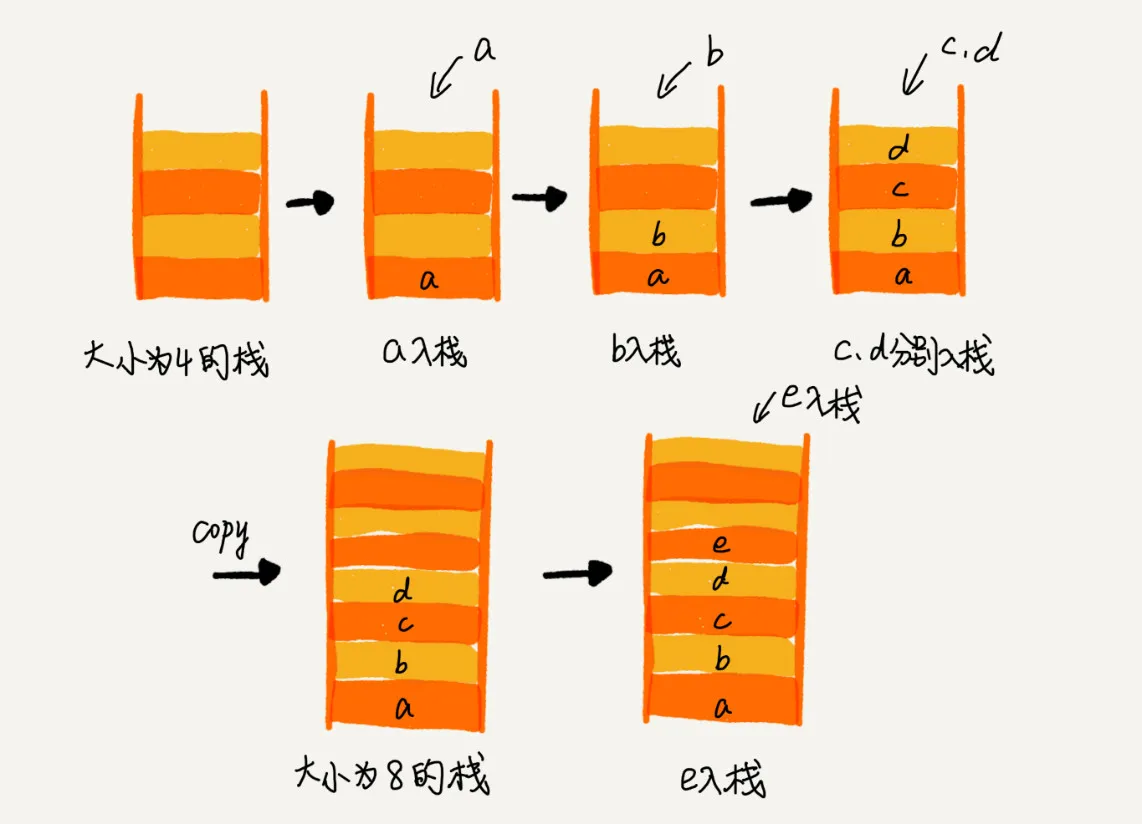
具体代码实现如下:
class CStackArray{public:CStackArray(const int &nCount = STATCK_DEFAULT_COUNT){if (nullptr == m_data){m_data = new std::string[nCount];if (nullptr == m_data){std::cout << "malloc data failed!" << std::endl;return;}m_count = nCount;m_index = 0;}}~CStackArray(){if (nullptr != m_data){delete[] m_data;m_data = nullptr;}}bool empty(){return 0 == m_index;}bool full(){return m_count == m_index;}int size(){return m_index;}bool push(const std::string &str){if (full()){// 需要扩容std::string *temp = new std::string[2 * m_count];if (nullptr == temp){std::cout << "fail to malloc!" << std::endl;return false;}for (int i = 0; i < size(); ++i){temp[i] = m_data[i];}if (nullptr != m_data){delete[] m_data;m_data = nullptr;}m_data = temp;}// 简单入栈m_data[m_index++] = str;return true;}bool pop(std::string &str){if (empty()){std::cout << "stack is empty!" << std::endl;return false;}str = m_data[--m_index];return true;}private:std::string *m_data = nullptr; // 数据内容int m_count = 0; // 栈的容量int m_index = 0; // 入栈指针};
我们分析上述代码,发现出栈的时间复杂度依然为 ,但入栈的时间复杂度却发生了变化:
,但入栈的时间复杂度却发生了变化:
- 当栈有空闲空间时,入栈的时间复杂度为。<最好时间复杂度>
- 当栈没有空闲空间时,入栈的时间复杂度为
 。<最坏时间复杂度>
。<最坏时间复杂度>
上述我们分析了最好、最坏时间复杂度,那么平均时间复杂度是怎么样的呢?
假设栈容量为n个,当进行了n次简单入栈操作(时间复杂度为)之后,此时栈满需要扩容,时间复杂度变为,后续入栈都会重复这一过程,我们用一张图描述这一过程: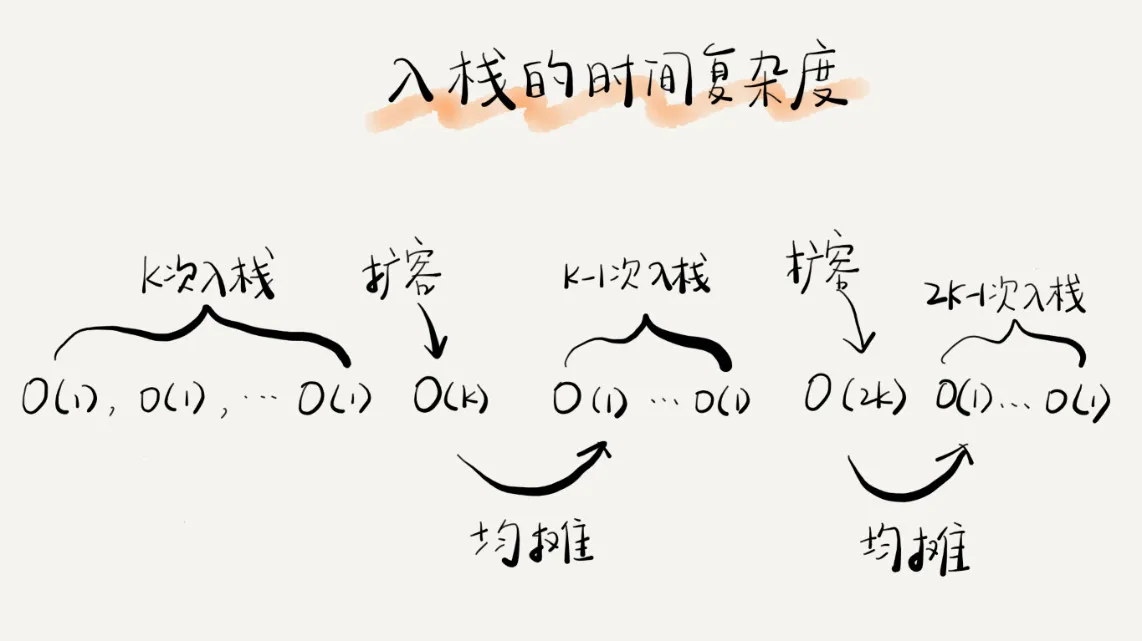
通过上述分析可知,时间复杂度仅仅会在第k次退化为,其他时间均为,将第k次的时间复杂度均摊到其他入栈操作上,就可以得出平均时间复杂度为。
3.栈的应用
3.1 函数调用
在函数调用过程,每个函数都会分配一个栈帧,函数执行过程中会将临时变量入栈,执行结束后,会将临时变量出栈,清空相应栈帧。
下面我们看一个例子:
int main() {int a = 1;int ret = 0;int res = 0;ret = add(3, 5);res = a + ret;printf("%d", res);reuturn 0;}int add(int x, int y) {int sum = 0;sum = x + y;return sum;}
上述代码中,main函数执行过程中,会将临时变量a,ret,res分别压入栈中,调用add函数时,将y,x先后压入栈中。为方便理解,我画了一张示意图: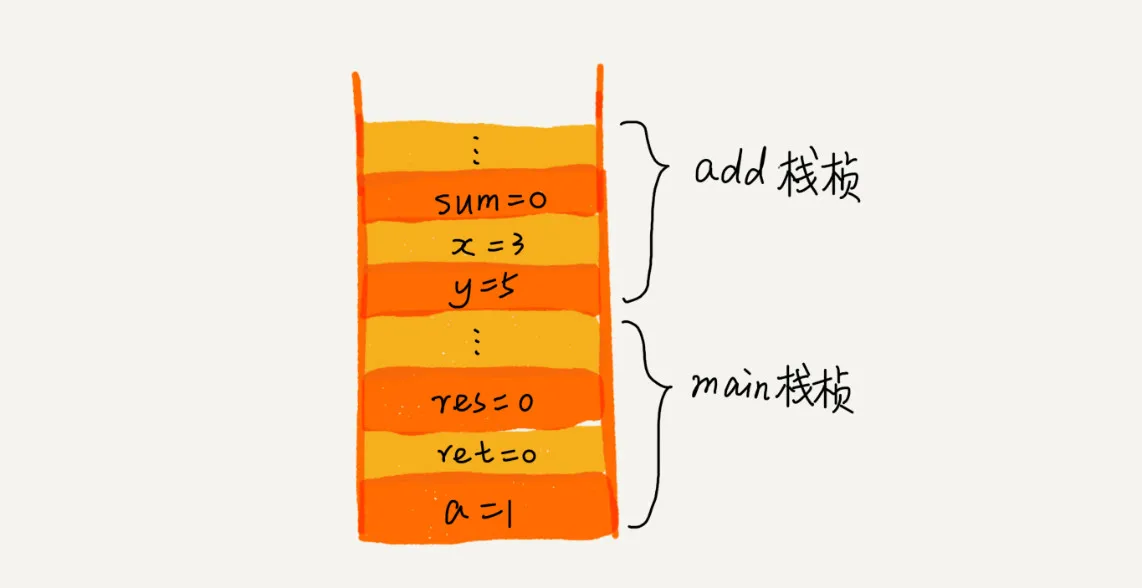
3.2 四则运算表达式计算
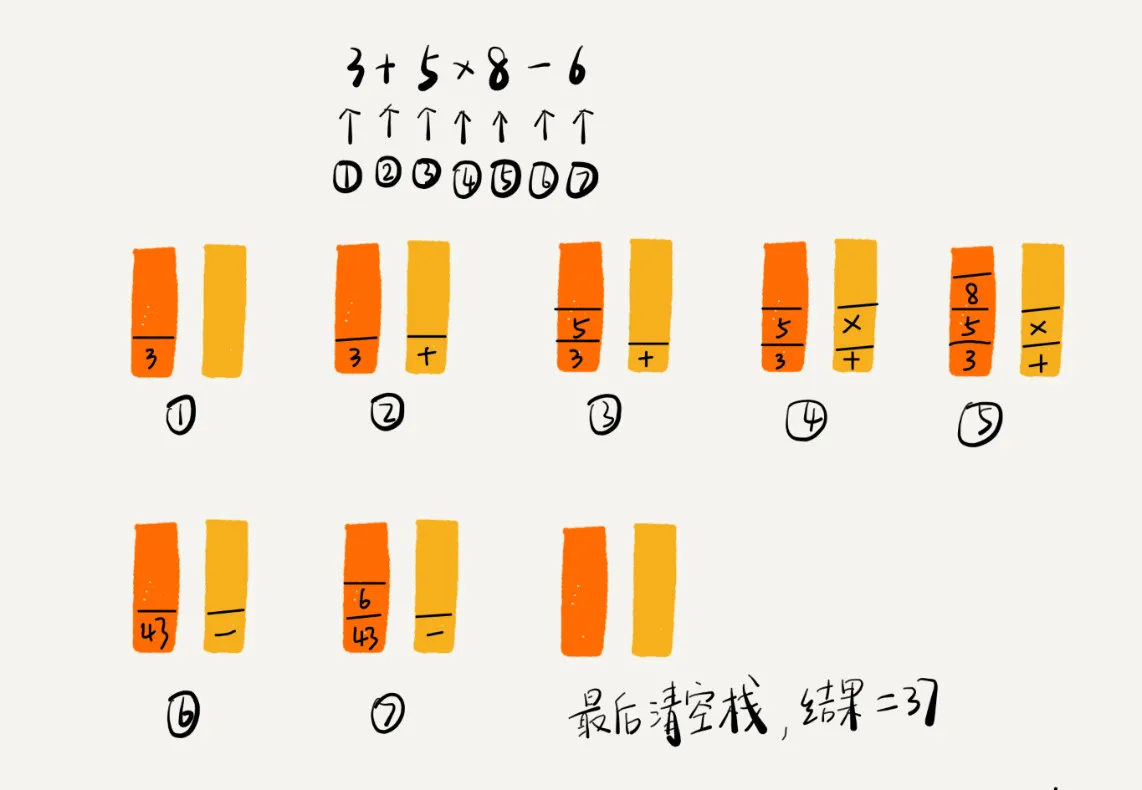
例如:3+5*8-6表达式计算,我们可以快速的口算出来,那么计算机是如何进行计算的呢?
计算机会准备两个栈,一个用来存储操作数,一个用来存储运算符,当从左到右遍历运算表达式时,若遇到数字,则将其入栈到操作数栈,当遇到运算符时,若当前运算符优先级高于运算符栈栈顶元素,则直接入栈,否则,取出操作数栈栈顶两元素与运算符栈栈顶元素进行运算,将结果压入操作数栈,将待入栈操作符与操作符栈顶元素比较,继续执行上述过程。
4. 思考题:为什么函数调用要使用栈这一数据结构,用其他的数据结构可以吗?
当然是可以的,只是栈先进后出、后进先出这一特性完美契合函数调用过程,顺理成章函数调用就使用了这一数据结构。
函数调用,本质上作用域的切换。需要满足调用函数后,作用域切换到被调用函数,调用结束后,作用域切换到调用函数。
所谓作用域,本质上是临时变量存在的地方。当调用函数时,被调用函数的临时变量被压入栈中,此时栈顶指针指向被调用函数,完成了作用域的切换;当函数调用结束后,被调用函数的变量释放、出栈,此时栈顶指针指向调用函数的变量,作用域重新回到调用函数。怎么样?是不是很完美!!!!

若有收获,就点个赞吧
0 人点赞
