1. 冒泡排序
1.1 介绍
很多人接触的第一个算法就是冒泡排序,因此这个想必大家都很熟悉了。
冒泡排序的思想是:只比较相邻的两个数据,若满足条件,将相邻数据替换。(符合条件的数据像冒泡泡一样冒出来,因此叫做冒泡算法)
下面我们以 4,5,6,3,2,1(升序)这一组数据为例,下面是其第一次冒泡排序的过程: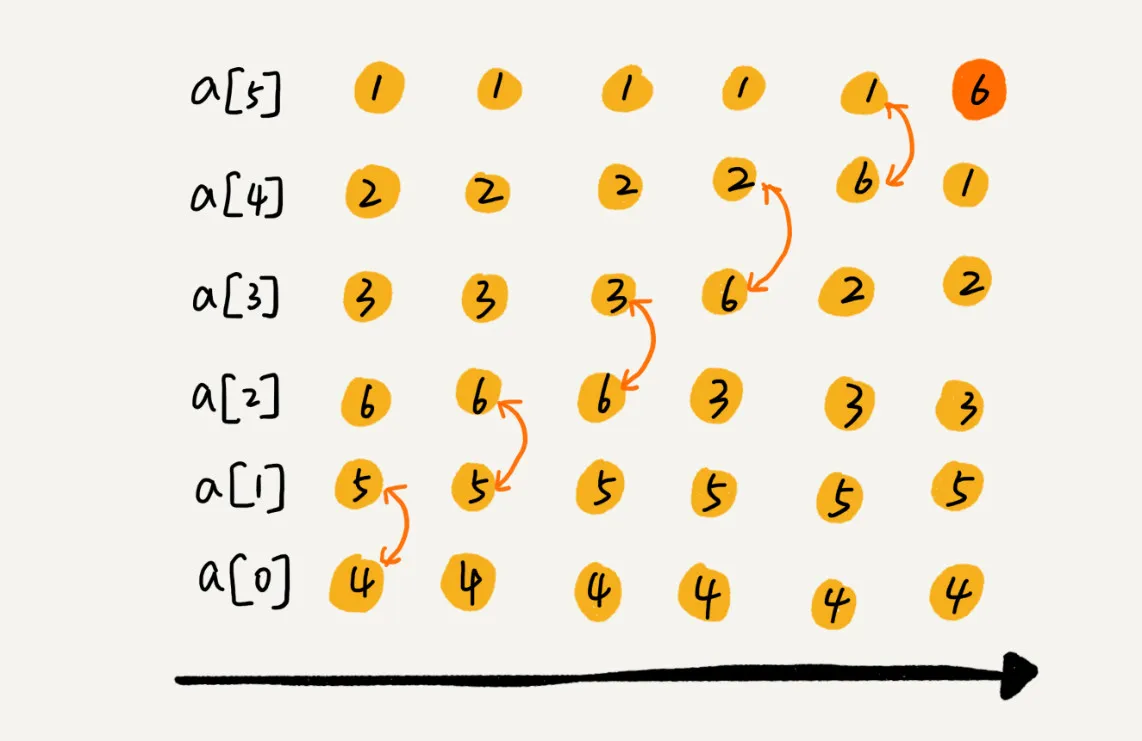
从上图可以看出,冒泡排序只会操作相邻的两个数据 ,若是前一个数据大于后一个数据,则进行交换,这样,在第一次冒泡中,就可以将最大的数据筛选出来并放置到合适的位置上,以后的五次冒泡均是如此:
下面是具体代码:
void bubble_sort(int *arr, const int &count){if (1 >= count){std::cout << "数组中元素无需排序" << std::endl;return;}// 升序int ntemp = 0;for (int i = 0; i < count; ++i){for (int j = 0; j < count - i- 1; ++j){if (arr[j] > arr[j + 1]){ntemp = arr[j];arr[j] = arr[j + 1];arr[j + 1] = ntemp;}}}}
事实上,上述代码还有优化空间。试想一下:若是某次冒泡排序过程中没有发生数据交换,说明参与冒泡排序的数据都是有序且符合排序条件的,加上在之前的冒泡排序中已经排序好的数据,此时整个数据都是有序的。这种情况下就无需进行后续冒泡,直接返回即可。
看下面这个例子: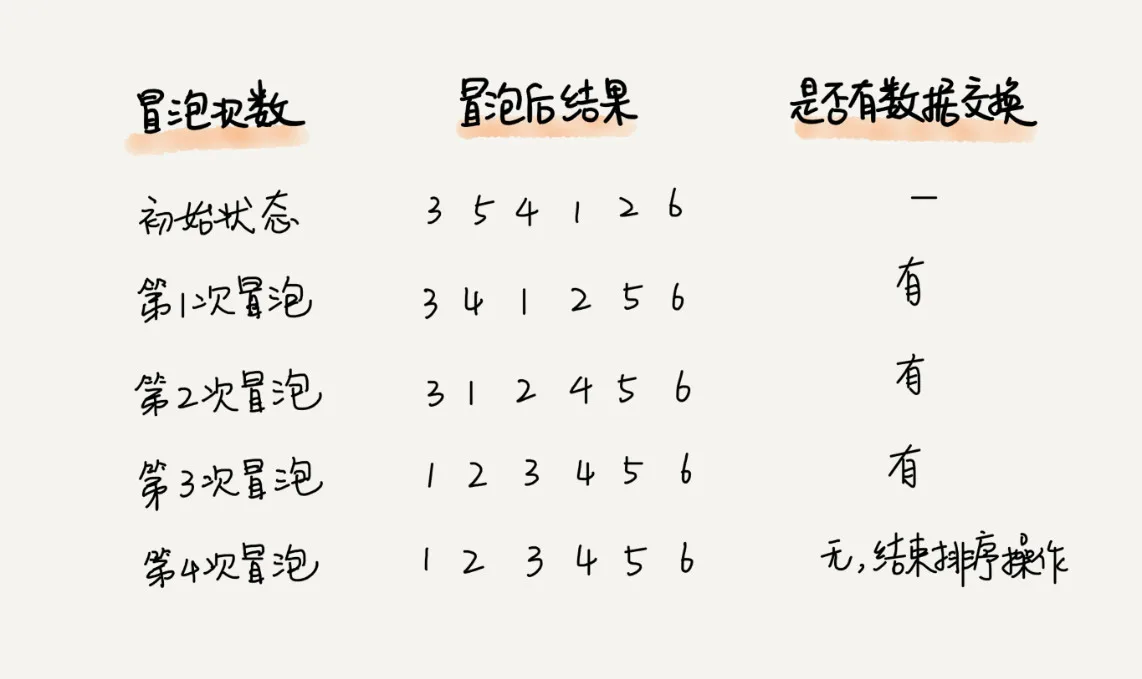
优化后的代码如下:
void bubble_sort_pro(int *arr, const int &count){if (1 >= count){std::cout << "数组中元素无需排序" << std::endl;return;}// 升序int ntemp = 0;bool bSwap = true;for (int i = 0; i < count; ++i){bSwap = false;for (int j = 0; j < count - i- 1; ++j){if (arr[j] > arr[j + 1]){ntemp = arr[j];arr[j] = arr[j + 1];arr[j + 1] = ntemp;bSwap = true;}}if (!bSwap){break;}}}
1.2 算法效率分析
- 是否是原地排序算法:是。即无需其他内存空间即可完成排序
- 是否稳定性排序算法:是。即数据相同时不发生交换
- 最好时间复杂度:
 。即所有数据有序且满足排序条件
。即所有数据有序且满足排序条件 - 最坏时间复杂度:
 。即所有数据逆序。
。即所有数据逆序。 - 平均时间复杂度:
计算平均时间复杂度之前,我们先介绍有序度、逆序度两个概念。
有序度:一组数据中符合条件的一对数据的个数
逆序度:一组数据中不符合条件的一对数据的个数
满有序度: 完全符合条件的有序的一组数据的有序度(n个数据,其满有序度为 )。
)。
显然,一组数据的上述三者之间存在下面关系:满有序度=有序度+逆序度。
那么如何计算有序度呢?看下面例子:
我们分析上述例子的冒泡排序过程可知,其需要交换四次,即交换逆序度次。也就是说最好情况下,交换0次,最差情况下交换 次,取中间值即为
次,取中间值即为  。所以其平均时间复杂度仍为 。
。所以其平均时间复杂度仍为 。
1.3 有序度分析
冒泡排序执行过程中,不外乎比较、交换两种操作。通过第二节,我们已经知道,一组数据的满有序度是固定的,数据每进行一次交换,则有序度增加1,因此数据交换的次数其实为原始数据的逆序度,下面我们通过一个例子感受一下:
我们以第一次冒泡进行说明:此次冒泡过程中,6先后与3、2、1进行交换,有序度增加3。
2. 插入排序
2.1 介绍
在介绍插入排序算法之前,我们先思考一个问题:向有序数组插入一个数字,如何保证插入完成之后数组仍是有序的?
学过前面的知识,我们马上就可以回答出:将待插入数据与原数组元素进行比较,找到待插入位置,移动相关元素后,将待插入元素插入即可。事实上,上述方法就是插入排序的核心思想。
插入排序的核心思想:将一个数组看做两部分,前一部分是有序的,后一部分是无序的(初始情况下仅认为第一个数据是有序的),将无序部分的数据拿出来插入到有序部分上,直到最后一个无序数据插入完成,至此数组元素的排序也完成了。
下面看一个例子: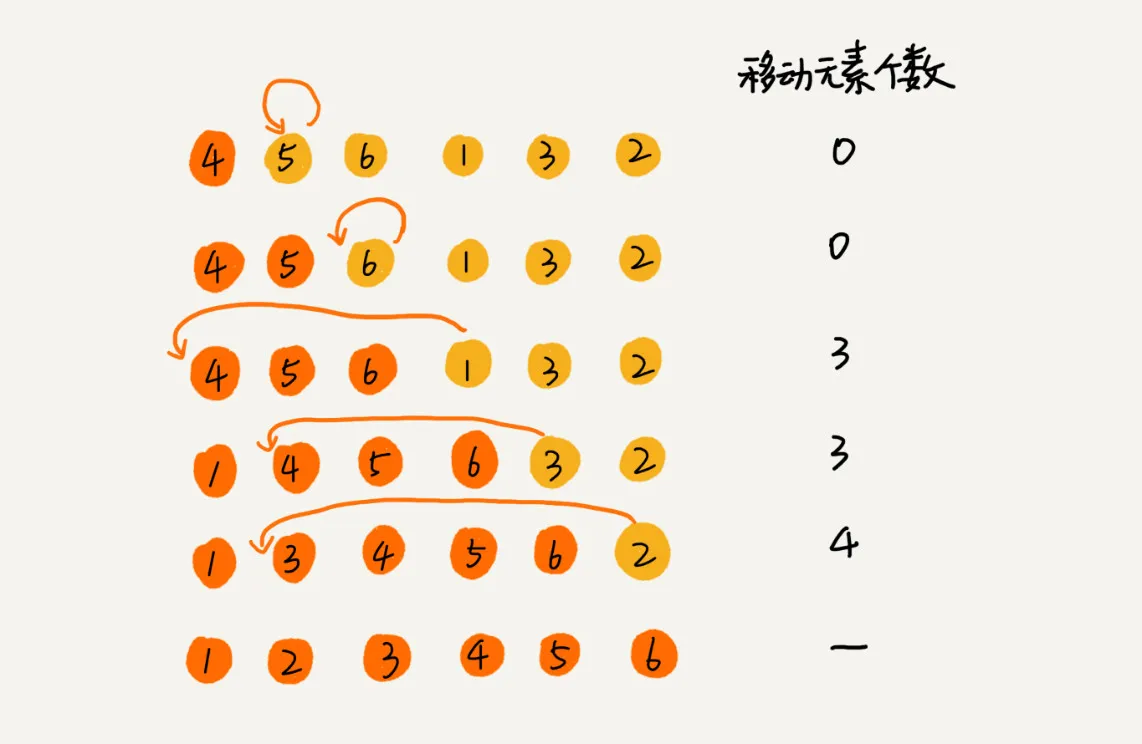
具体代码如下:
void insert_sort(int *arr, const int &count){if (1 >= count){std::cout << "数组中元素无需排序" << std::endl;return;}// 升序// 自己写的第一版,缺点:必须比较完全部有序部分才行/*int ntemp = 0;for (int i = 1; i < count; ++i){for (int j = 0; j < i; ++j){if (arr[i] >= arr[j]){continue;}else{// 插入,搬运ntemp = arr[i];arr[i] = arr[j];arr[j] = ntemp;}}}*/// 借鉴他人的:无需比较全部有序内容for (int i = 1; i < count; ++i){int value = arr[i];int j = i - 1;for (; j >= 0; --j){if (arr[j] > value){// 数据搬移arr[j + 1] = arr[j];}else{break;}}arr[j + 1] = value;}}
2.2 算法分析:
- 是否是原地排序算法:是。即无需其他内存空间即可完成排序
- 是否稳定性排序算法:是。即数据相同时不发生交换
- 最好时间复杂度:
 。即所有数据有序且满足排序条件
。即所有数据有序且满足排序条件 - 最坏时间复杂度: 。即所有数据逆序。
- 平均时间复杂度:。其内存循环本质上是数组的插入操作,通过前面的知识我们知道,数组插入操作的平均时间复杂度为,再加上外层循环,因此其平均时间复杂度为。
2.3 有序度分析
插入排序算法的操作主要为比较和数据搬运。数据搬运n次,说明一个元素与n个元素的逆序被矫正了,即有序度增加n,也就是说:插入排序算法的数据搬运次数等于原始数据集合的逆序度。
下面看一个例子: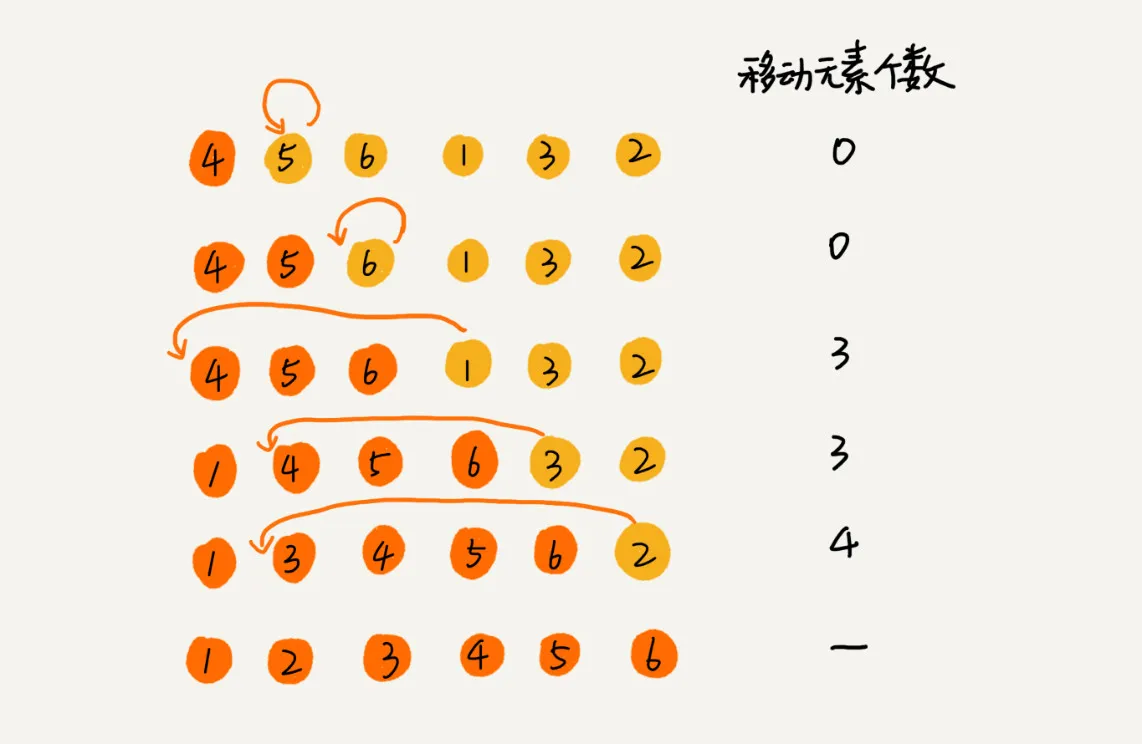
3. 选择排序
3.1 介绍
选择排序的思想和插入排序的思想大同小异,都会数组数据区分为有序部分和无序部分,不同的是,选择排序每次会在未排序部分查找最小值,然后将其插入到有序部分的末尾。
下面看一个例子:
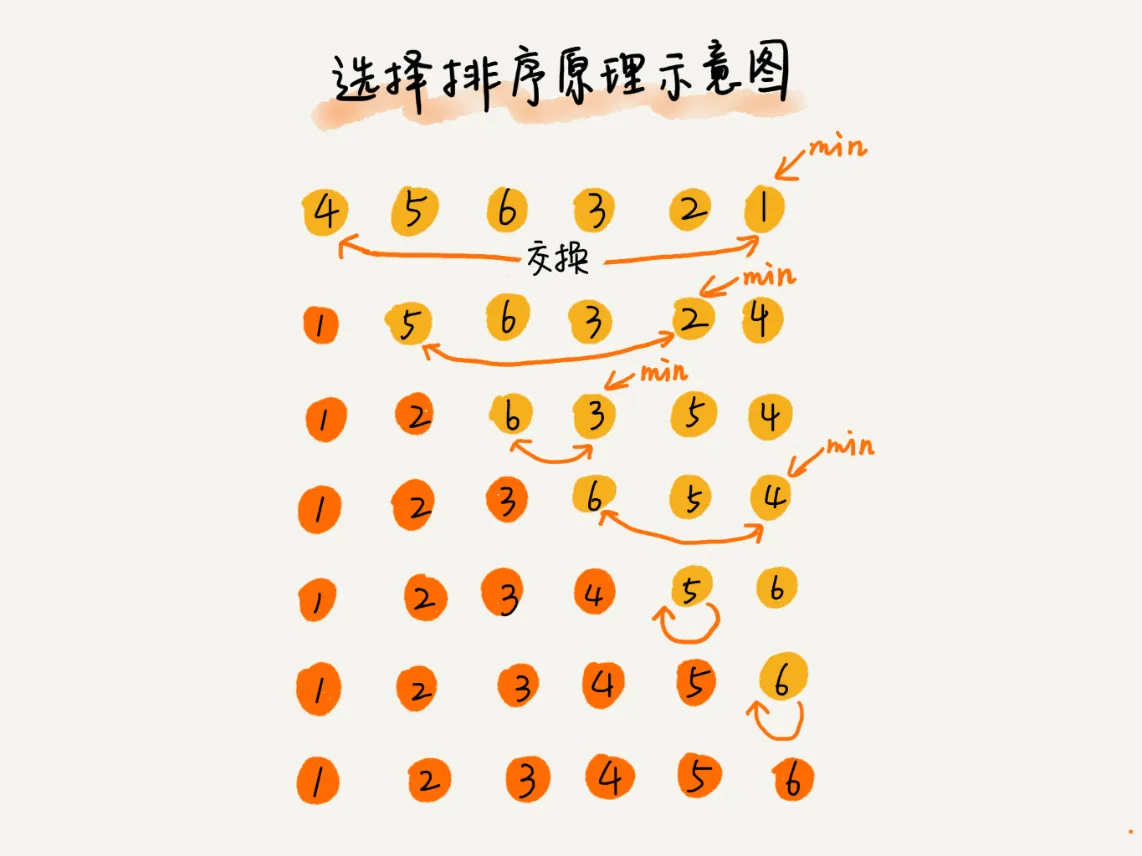
代码示例如下:
void selcet_sort(int *arr, const int &count){if (1 >= count){std::cout << "数组中元素无需排序" << std::endl;return;}for (int i = 0; i < count - 1; ++i){int minpos = i;for (int j = i; j < count; ++j){if (arr[j] < arr[minpos]){minpos = j;}}int ntemp = arr[minpos];arr[minpos] = arr[i];arr[i] = ntemp;}}
3.2 算法分析
- 是否是原地排序算法:是。即无需其他内存空间即可完成排序
- 是否稳定性排序算法:否。当数据中存在相同元素时,因为是元素交换,无法保证其一定不移动顺序。
- 最好时间复杂度:。
- 最坏时间复杂度:
- 平均时间复杂度:。
4. (思考题)实际代码开发中,为什么更愿意使用插入排序而不是冒泡排序?
前面讲到,冒泡排序、插入排序比较次数基本一致,但交换和搬运的次数都等于原始数据的逆序度。下面我们看一下两个算法交换、搬运的部分的代码: ```cpp // 冒泡排序 交换 if (arr[j] > arr[j + 1]) { ntemp = arr[j]; arr[j] = arr[j + 1]; arr[j + 1] = ntemp; }
// 插入排序 搬运 if (arr[j] > value) { // 数据搬移 arr[j + 1] = arr[j]; } ``` 假设每行代码执行的时间一样,很明显插入排序要比冒泡排序花费的时间更少,效率更高。

若有收获,就点个赞吧
0 人点赞
