1. 链表的由来
上一章我们已经学习了数组,知道了数组的实现依赖于连续的内存,但当内存中没有那么大的连续内存时,数组就会因盛情不到内存而无法使用,这种情况下,我们就需要一种不那么依赖于连续内存的数据结构,链表由此诞生。
2. 链表概述
不同于数组,链表内部由一个个节点组成,这些节点都记录着下一个节点的位置,这样便可以将各个节点串起来,形成链表。
上述描述中,这种只知道自己后置节点的链表,称为单链表,内存结构如下: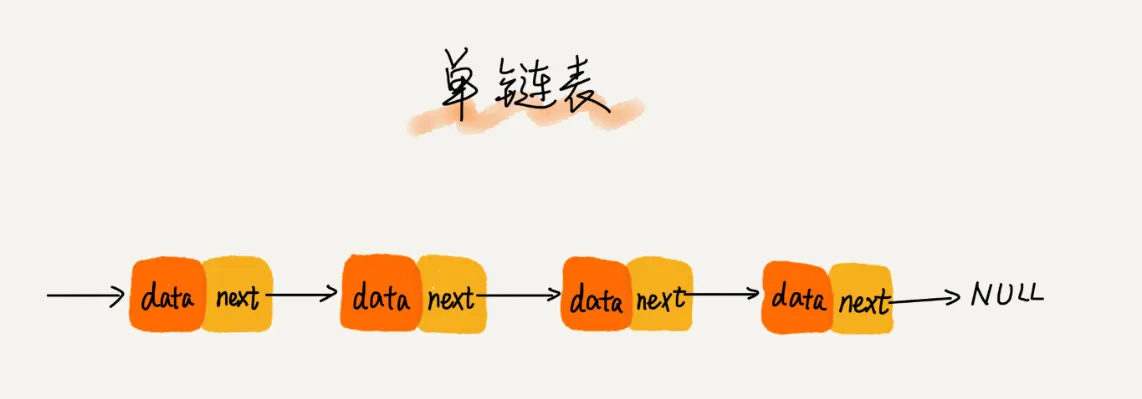
链表中各节点不是连续的,仅仅通过next与将各个节点连接在一起。节点的C++定义如下:
struct SNode{datatype m_data;SNode *m_next;}
3. 单链表操作
链表与数组的特性完全相反:
- 数组可以通过下标以
 的时间复杂度访问元素,而链表访问特定元素的时间复杂度为
的时间复杂度访问元素,而链表访问特定元素的时间复杂度为 。
。 - 数组在插入删除时需要进行数据搬移工作,时间复杂度为,而链表仅需要改变节点中next的指向即可完成插入、删除,时间复杂度为
 <需要知道提前知道前置节点>。
<需要知道提前知道前置节点>。 - 当然,链表也因为增加了后置指针域,增加了一部分内存开销。
3.1 查找
因单链表只知道其后置元素,因此查找指定的节点时,需要从头开始遍历整个链表,时间复杂度为。
3.2 插入
在已知前置节点的前提下,单链表的插入操作仅需要将前置节点的next域指向待插入节点,将待插入节点的next域指向原后置节点即可,时间复杂度为。
3.3 删除
在已知前置节点的前提下,单链表的删除操作仅需要将前置节点的next域指向待删除节点的后置节点即可,时间复杂度为。<要记得释放待删除节点哦>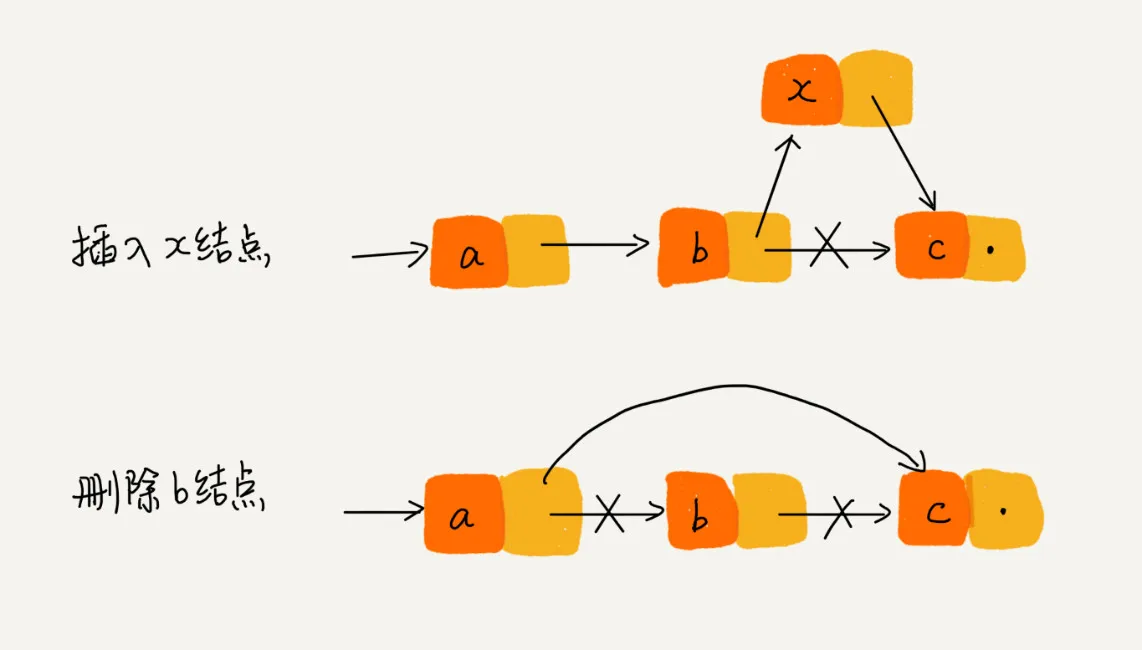
具体代码如下:
List Insert(const int &nData, const int &nPos, List list){if (1 == nPos){List node = new SNode;if (nullptr == node){std::cout << "malloc memory failed" << std::endl;return list;}node->m_nData = nData;node->m_pNext = list;return node;}List temp = FindByIndex(nPos - 1, list);if (nullptr == temp){return list;}List node = new SNode;if (nullptr == node){std::cout << "malloc memory failed" << std::endl;return list;}node->m_nData = nData;node->m_pNext = temp->m_pNext;temp->m_pNext = node;return list;}List Remove(const int &nPos, List list){if (1 == nPos){if (nullptr == list){return list;}else{List node = list;list = list->m_pNext;if (nullptr != node){delete node;node = nullptr;}}return list;}List temp = FindByIndex(nPos - 1, list);if (nullptr == temp){return list;}List node = temp->m_pNext;if (nullptr == node){return list;}temp->m_pNext = node->m_pNext;if (nullptr != node){delete node;node = nullptr;}return list;}
4. 循环链表
由第三小节可知,单链表有两个特殊的节点:头结点和尾结点。头结点是链表的起始节点,尾结点是链表的终止节点,其next域指向NULL,单链表中我们也经常通过尾结点的这一特性判断链表是否结束。
若是链表的尾结点指向头结点,那么链表就形成了一个环,这样的链表称为循环链表。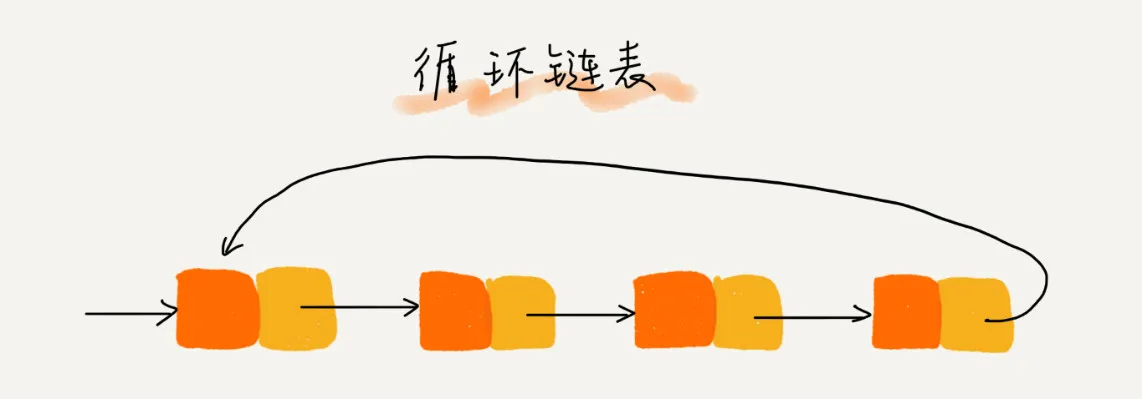
与单链表相比,循环链表能更简单的访问到头结点,用来处理带环的问题再合适不过了,例如著名的约瑟夫问题。
5. 双向链表
单链表仅知道后置元素,这就导致每次插入、删除节点时,均需要经过遍历找到待操作节点,才可以进行删除、插入操作。这就导致虽然插入、删除的操作时间复杂度为,但因需要遍历,整个的时间复杂度就变为了。
为了解决上述问题,引入了双向链表。
何为双向链表?就是在单链表的基础上,新增前置节点指针域,这样节点就既知道其前置节点,也知道其后置节点,这样的链表被称为双向链表。
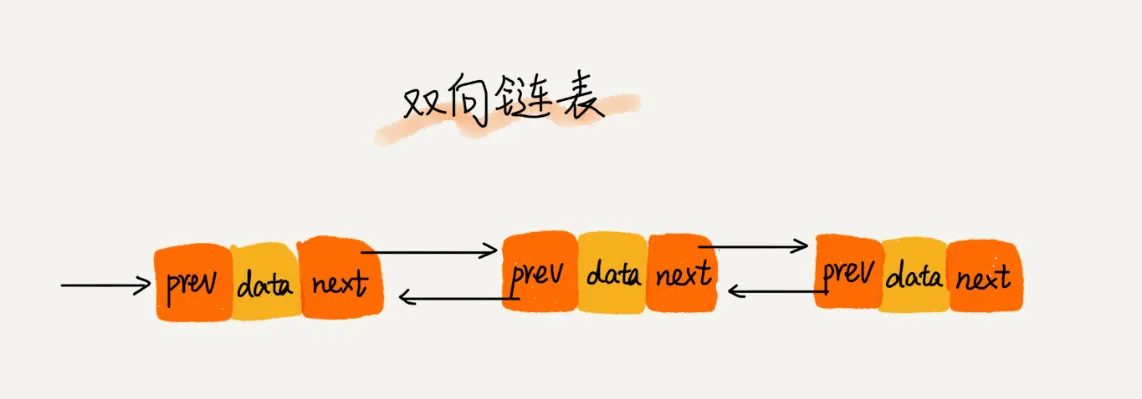
下面我们举例说明双向链表的优秀之处:
以节点删除为例,此项操作不外乎两种情况:
- 删除“值等于给定值”的节点
- 删除给定指针指向的节点
在第一种情况下,单链表与双链表均需要进行遍历,确定待删除节点,然后执行删除操作。
在第二种情况下,单链表因不知道其前置节点,因此仍需要遍历来确定其前置节点,而双向链表因知道前置节点,便可以的时间复杂度执行删除操作。
当然,面对在给定节点前插入节点时,双向链表的优势也大于单链表。
6. 双向循环链表
将双向链表与循环链表整合到一起,便形成了双向循环链表。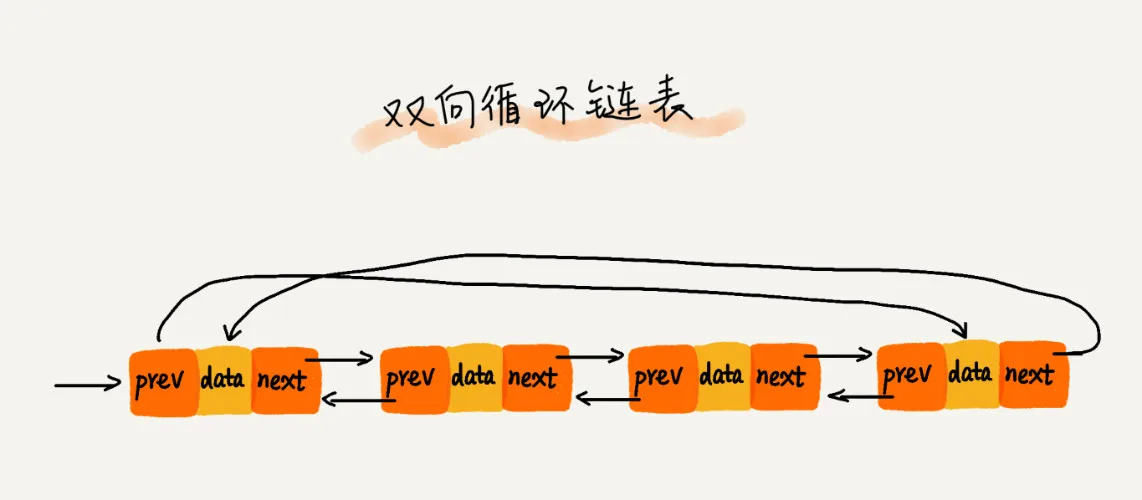
7. 如何实现LRU缓存淘汰算法?(思考题)
在现代操作系统中,为避免频繁与内存发生交互引起效率降低,cpu通常会将内存中的一块数据读到缓冲区中,应用程序在访问某个数据时,cpu会首先访问缓存,缓存找不到时才会去内存中寻找。
当缓存满了之后,如何删除缓存呢?目前有三种:先进先出原则,最少使用原则,最近最少使用原则(LRU)。
假定我们规定越靠近链表尾部,使用越少,那么我们试着思考一下LRU缓存淘汰算法的思路:
来了新数据之后,分为两种情况:
- 此数据已经在缓冲区中,那么我们将原有数据删除,并将该数据插入链表头部。
- 若数据不在缓冲区中,又分为两种情况:
- (1)缓冲区已满,此时删除尾部节点,并将新数据插入链表头部。
- (2)缓冲区未满,则直接将新数据插入链表头部。
那么我们来分析一下缓存的访问时间复杂度,不管缓存有没有满,我们都需要经过遍历才能访问到想要的数据,对应的时间复杂度为。
8. 小结
数组和链表是两种最基础的数据结构,但他两的特性完全不同。
数组适用于数据访问频繁,但插入、删除操作较少的场景,链表则适用于数据插入、删除频繁,访问较少的场景。
在实际开发过程中,我们要根据实际应用场景选择合理的数据结构。
除此之外,数组与链表的区别之处还在于:数组更有利于缓存机制,链表则没有优势。
原因:cpu读取缓存时,会读取一段连续的内存,而数组也是一段连续的内存,因此在程序执行过程中,使用数组能够更好的命中cpu缓存,从而提高执行效率。链表因内存并不连续,无此项优势。

若有收获,就点个赞吧
0 人点赞
