1. Hive数据类型详解
Hive中的数据类型指的是Hive表中的列字段类型。Hive数据类型整体分为两个类别:原生数据类型(primitive data type)和复杂数据类型(complex data type)。
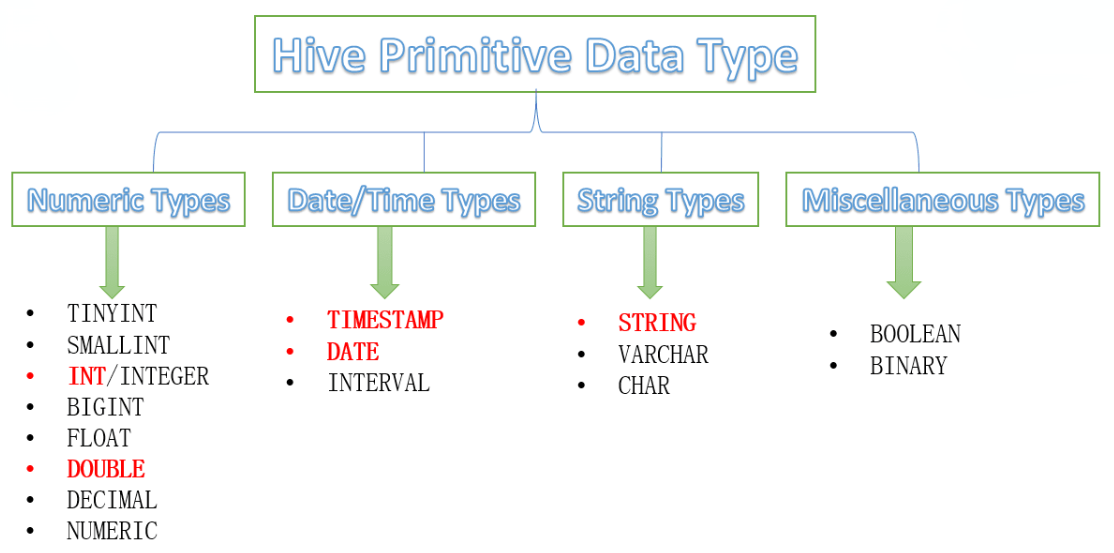
原生数据类型包括:数值类型、时间类型、字符串类型、杂项数据类型;
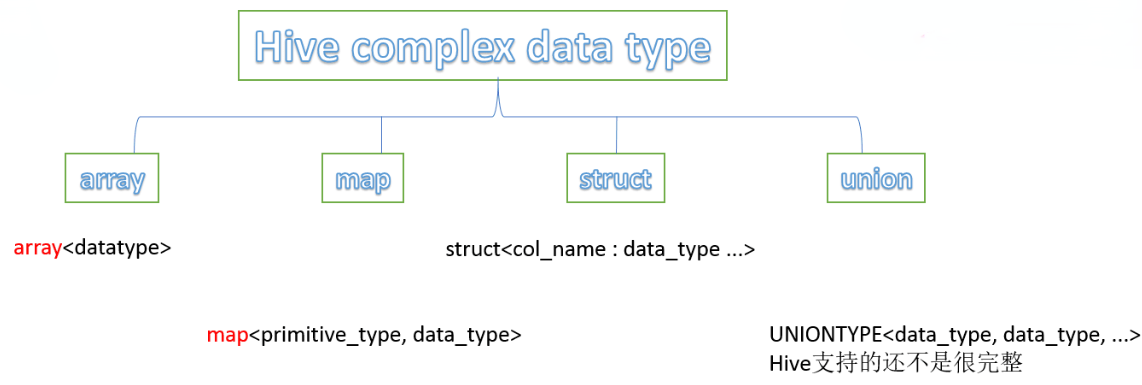
复杂数据类型包括:array数组、map映射、struct结构、union联合体。
关于Hive的数据类型,需要注意:
- 英文字母大小写不敏感;
- 除SQL数据类型外,还支持Java数据类型,比如:string;
- int和string是使用最多的,大多数函数都支持;
- 复杂数据类型的使用通常需要和分隔符指定语法配合使用。
如果定义的数据类型和文件不一致,hive会尝试隐式转换,但是不保证成功。
1.1 原生数据类型
1.2 复杂数据类型
1.3 隐式、显示类型转换
隐式类型转换
各类型之间允许的隐式转换: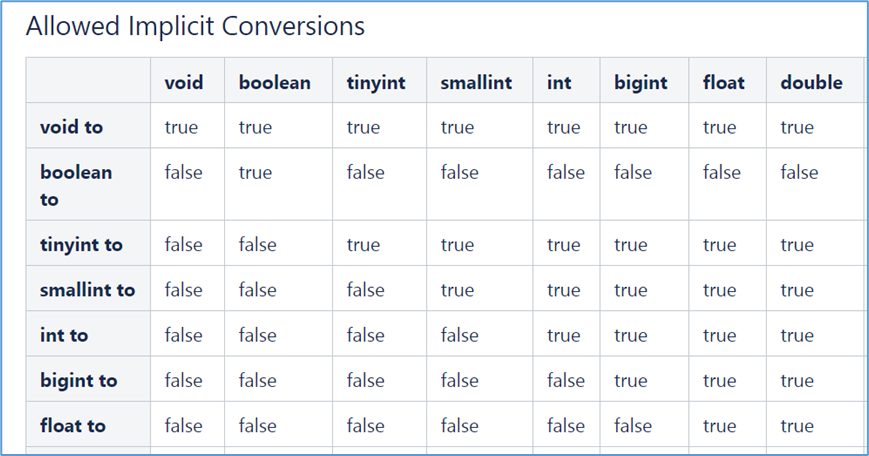
- 显示类型转换
显式类型转换使用CAST函数。
例如,CAST(’100’ as INT)会将100字符串转换为100整数值。 如果强制转换失败,例如,CAST(’INT’as INT),该函数返回NULL。
2. Hive读写文件机制
2.1 SerDe是什么
SerDe是Serializer、Deserializer的简称,目的是用于序列化和反序列化。序列化是对象转化为字节码的过程;而反序列化是字节码转换为对象的过程。
Hive使用SerDe(和FileFormat)读取和写入行对象。
可以通过desc formatted tablename查看表的相关SerDe信息。默认如下:
2.2 Hive读写文件流程
Hive读取文件机制:首先调用InputFormat(默认TextInputFormat),返回一条一条kv键值对记录(默认是一行对应一条记录)。然后调用SerDe(默认LazySimpleSerDe)的Deserializer,将一条记录中的value根据分隔符切分为各个字段。
Hive写文件机制:将Row写入文件时,首先调用SerDe(默认LazySimpleSerDe)的Serializer将对象转换成字节序列,然后调用OutputFormat将数据写入HDFS文件中。
2.3 SerDe相关语法
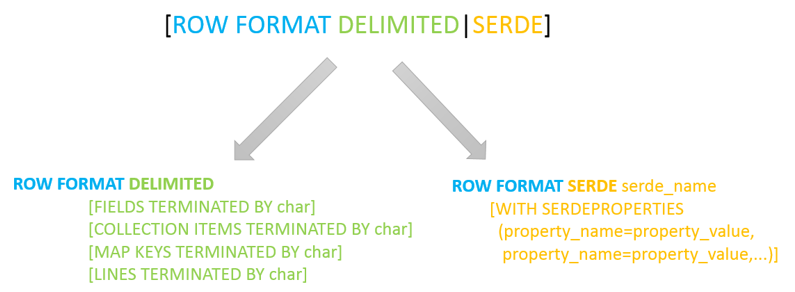
其中ROW FORMAT是语法关键字,DELIMITED和SERDE二选其一。
如果使用delimited表示使用默认的LazySimpleSerDe类来处理数据。如果数据文件格式比较特殊可以使用ROW FORMAT SERDE serde_name指定其他的Serde类来处理数据,甚至支持用户自定义SerDe类。
2.4 LazySimpleSerDe 分隔符指定
LazySimpleSerDe是Hive默认的序列化类,包含4种子语法,分别用于指定字段之间、集合元素之间、map映射 kv之间、换行的分隔符号。在建表的时候可以根据数据的特点灵活搭配使用。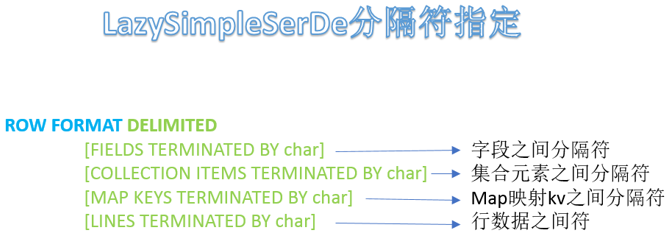
注意:hive建表时如果没有row format语法。此时字段之间默认的分割符是’\001’,是一种特殊的字符。
3. Hive数据存储路径
3.1 默认存储路径
Hive表默认存储路径是由${HIVE_HOME}/conf/hive-site.xml配置文件的hive.metastore.warehouse.dir属性指定。默认值是:/user/hive/warehouse。
3.2 指定存储路径
在Hive建表的时候,可以通过location语法来更改数据在HDFS上的存储路径,使得建表加载数据更加灵活方便。
语法:LOCATION ‘
对于已经生成好的数据文件,使用location指定路径将会很方便。
4. Hive DDL介绍
4.1 Hive内、外部表
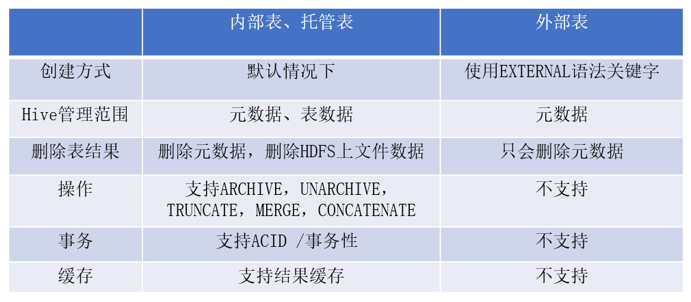
4.1.1 内部表
内部表(Internal table)也称为被Hive拥有和管理的托管表(Managed table)。默认情况下创建的表就是内部表,Hive拥有该表的结构和文件。换句话说,Hive完全管理表(元数据和数据)的生命周期,类似于RDBMS中的表。
删除内部表时,它会删除数据以及表的元数据。
create table student(num int,name string,sex string,age int,dept string)row format delimitedfields terminated by ',';create table customers(id int,name string)ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.OpenCSVSerde'-- org.apache.hadoop.hive.serde2.OpenCSVSerde 翻译文件的序列化与反序列化,-- 翻译成上边对应的表结构,序列化与反序列化的过程中还可以进行下边的操作。WITH SERDEPROPERTIES("separatorChar" = ",", -- 以,分割"quoteChar" = "\"" -- 去除分割后的")STORED AS TEXTFILE;
4.1.2 外部表
外部表(External table)中的数据不是Hive拥有或管理的,只管理表元数据的生命周期。要创建一个外部表,需要使用EXTERNAL语法关键字。
删除外部表只会删除元数据,而不会删除实际数据。在Hive外部仍然可以访问实际数据。
而且外部表更为方便的是可以搭配location语法指定数据的路径。
create external table student_ext(num int,name string,sex string,age int,dept string)row format delimited fields terminated by ','location '/xxx/xxx';
- 内部表和外部表区别?
4.2 分区表
当Hive表对应的数据量大、文件多时,为了避免查询时全表扫描数据,Hive支持根据用户指定的字段进行分区,分区的字段可以是日期、地域、种类等具有标识意义的字段。比如把一整年的数据根据月份划分12个月(12个分区),后续就可以查询指定月份分区的数据,尽可能避免了全表扫描查询。
create table t_all_hero_part(id int,name string,hp_max int,mp_max int,attack_max int,defense_max int,attack_range string,role_main string,role_assist string)partitioned by (role string)row format delimitedfields terminated by "\t";
注意:分区字段不能是表中已经存在的字段,因为分区字段最终也会以虚拟字段的形式显示在表结构上。
4.2.1 静态分区
静态分区指的是分区的字段值是由用户在加载数据的时候手动指定的。
4.2.2 动态分区
动态分区指的是分区的字段值是基于查询结果自动推断出来的。
启用hive动态分区,需要在hive会话中设置两个参数:set hive.exec.dynamic.partition=true;set hive.exec.dynamic.partition.mode=nonstrict;
第一个参数表示开启动态分区功能;
第二个参数指定动态分区的模式:分为nonstick非严格模式和strict严格模式。strict严格模式要求至少有一个分区为静态分区。
4.2.3 分区表注意事项
- 分区表不是建表的必要语法规则,是一种优化手段表,可选;
- 分区字段不能是表中已有的字段,不能重复;
- 分区字段是虚拟字段,其数据并不存储在底层的文件中;
- 分区字段值的确定来自于用户价值数据手动指定(静态分区)或者根据查询结果位置自动推断(动态分区)
- Hive支持多重分区,也就是说在分区的基础上继续分区,划分更加细粒度。
4.3 分桶表
4.3.1 概念
分桶表也叫做桶表,源自建表语法中bucket单词。是一种用于优化查询而设计的表类型。该功能可以让数据分解为若干个部分易于管理。
在分桶时,我们要指定根据哪个字段将数据分为几桶(几个部分)。默认规则是:Bucket number = hash_function(bucketing_column) mod num_buckets。
桶编号相同的数据会被分到同一个桶当中。hash_function取决于分桶字段bucketing_column的类型:
如果是int类型,hash_function(int) == int;
如果是其他类型,比如bigint,string或者复杂数据类型,hash_function比较棘手,将是从该类型派生的某个数字,比如hashcode值。
注意:分桶的字段必须是表中已经存在的字段。4.3.2 语法
示例: ```sql —根据state字段分为5桶,每个桶内根据cases字段倒序排序 CREATE TABLE itcast.covid19_bucket_sort(-- 分桶表建表语句CREATE [EXTERNAL] TABLE [db_name.]table_name[(col_name data_type, ...)]CLUSTERED BY (col_name)INTO N BUCKETS;
CLUSTERED BY(state) sorted by (cases desc) INTO 5 BUCKETS;count_date string,county string,state string,fips int,cases int,deaths int)
—开启分桶的功能 从Hive2.0开始不再需要设置 set hive.enforce.bucketing=true;
<a name="kz0Kr"></a>#### 4.3.3 分桶表的好处1. 基于分桶字段查询时,减少全表扫描1. JOIN时可以提高MR程序效率,减少笛卡尔积数量对于JOIN操作两个表有一个相同的列,如果对这两个表都进行了分桶操作。那么将保存相同列值的桶进行JOIN操作就可以,可以大大较少JOIN的数据量。3. 分桶表数据进行抽样<a name="DqCHk"></a>### 4.4 事务表Hive本身从设计之初时,就是不支持事务的,因为**Hive的核心目标是将已经存在的结构化数据文件映射成为表,然后提供基于表的SQL分析处理**,是一款**面向分析**的工具。<br />从**Hive0.14**版本开始,具有ACID语义的事务已添加到Hive中。<br />使用示例:```sql--Hive中事务表的创建使用--1、开启事务配置(可以使用set设置当前session生效 也可以配置在hive-site.xml中)set hive.support.concurrency = true; --Hive是否支持并发set hive.enforce.bucketing = true; --从Hive2.0开始不再需要 是否开启分桶功能set hive.exec.dynamic.partition.mode = nonstrict; --动态分区模式 非严格set hive.txn.manager = org.apache.hadoop.hive.ql.lockmgr.DbTxnManager; --set hive.compactor.initiator.on = true; --是否在Metastore实例上运行启动线程和清理线程set hive.compactor.worker.threads = 1; --在此metastore实例上运行多少个压缩程序工作线程。--2、创建Hive事务表create table trans_student(id int,name String,age int)clustered by (id) into 2 buckets stored as orcTBLPROPERTIES('transactional'='true');
4.4.1 事务表局限性
虽然Hive支持了具有ACID语义的事务,但是在使用起来,并没有像在MySQL中使用那样方便,有很多局限性。原因很简单,毕竟Hive的设计目标不是为了支持事务操作,而是支持分析操作,且最终基于HDFS的底层存储机制使得文件的增加删除修改操作需要动一些小心思。具体限制如下:
- 尚不支持BEGIN,COMMIT和ROLLBACK。所有语言操作都是自动提交的。
- 仅支持ORC文件格式(STORED AS ORC)。
- 默认情况下事务配置为关闭。需要配置参数开启使用。
- 表必须是分桶表(Bucketed)才可以使用事务功能。
- 表参数transactional必须为true。
外部表不能成为ACID表,不允许从非ACID会话读取/写入ACID表。
4.5 视图
Hive中的视图(view)是一种虚拟表,只保存定义,不实际存储数据。
4.5.1 视图的好处
将真实表中特定的列数据提供给用户,保护数据隐式。
-
4.6 物化视图
物化视图(Materialized View)是一个包括查询结果的数据库对像,可以用于预先计算并保存表连接或聚集等耗时较多的操作的结果。这样,在执行查询时,就可以避免进行这些耗时的操作,而从快速的得到结果。使用物化视图的目的就是通过预计算,提高查询性能,当然需要占用一定的存储空间。
Hive3.0开始尝试引入物化视图,并提供对于物化视图的查询自动重写(基于Apache Calcite实现)。3.0中提供了物化视图存储选择机制,可以本地存储在hive,同时可以通过用户自定义storage handlers存储在其他系统(如Druid)。
Hive引入物化视图的目的就是为了优化数据查询访问的效率,相当于从数据预处理的角度优化数据访问。Hive从3.0丢弃了index索引的语法支持,推荐使用物化视图和列式存储文件格式来加快查询的速度。4.6.1 物化视图和普通视图的区别
视图是虚拟的,逻辑存在的,只有定义没有存储数据。
- 物化视图是真实的,物理存在的,里面存储着预计算的数据。
- 不同于视图,物化视图能够缓存数据,在创建物化视图的时候就把数据缓存起来了,hive把物化视图当成一张“表”,将数据缓存。而视图只是创建一个虚表,只有表结构,没有数据,实际查询的时候再去改写SQL去访问实际的数据表。
- 视图的目的是简化降低查询的复杂度,而物化视图的目的是提高查询性能。
4.6.2 语法
示例: ```sql CREATE MATERIALIZED VIEW druid_wiki_mv STORED AS ‘org.apache.hadoop.hive.druid.DruidStorageHandler’ AS SELECT __time, page, user, c_added, c_removed FROM src;-- 物化视图的创建语法CREATE MATERIALIZED VIEW [IF NOT EXISTS] [db_name.]materialized_view_name[DISABLE REWRITE][COMMENT materialized_view_comment][PARTITIONED ON (col_name, ...)][CLUSTERED ON (col_name, ...) | DISTRIBUTED ON (col_name, ...) SORTED ON (col_name, ...)][[ROW FORMAT row_format][STORED AS file_format]| STORED BY 'storage.handler.class.name' [WITH SERDEPROPERTIES (...)]][LOCATION hdfs_path][TBLPROPERTIES (property_name=property_value, ...)]AS SELECT ...;
— Drops a materialized view DROP MATERIALIZED VIEW [db_name.]materialized_view_name; — Shows materialized views (with optional filters) SHOW MATERIALIZED VIEWS [IN database_name]; — Shows information about a specific materialized view DESCRIBE [EXTENDED | FORMATTED] [db_name.]materialized_view_name;
— 当数据源变更,物化视图需要手动触发变更 ALTER MATERIALIZED VIEW [db_name.]materialized_view_name REBUILD;
使用:```sql--1、新建一张事务表 student_transset hive.support.concurrency = true; --Hive是否支持并发set hive.enforce.bucketing = true; --从Hive2.0开始不再需要 是否开启分桶功能set hive.exec.dynamic.partition.mode = nonstrict; --动态分区模式 非严格set hive.txn.manager = org.apache.hadoop.hive.ql.lockmgr.DbTxnManager; --set hive.compactor.initiator.on = true; --是否在Metastore实例上运行启动线程和清理线程set hive.compactor.worker.threads = 1; --在此metastore实例上运行多少个压缩程序工作线程。CREATE TABLE student_trans (sno int,sname string,sdept string)clustered by (sno) into 2 buckets stored as orcTBLPROPERTIES('transactional'='true');--2、导入数据到student_trans中insert overwrite table student_transselect sno,sname,sdeptfrom student;select * from student_trans;--3、对student_trans建立聚合物化视图CREATE MATERIALIZED VIEW student_trans_aggAS SELECT sdept, count(*) as sdept_cnt from student_trans group by sdept;--注意 这里当执行CREATE MATERIALIZED VIEW,会启动一个MR对物化视图进行构建--可以发现当下的数据库中有了一个物化视图show tables;show materialized views;--4、对原始表student_trans查询--由于会命中物化视图,重写query查询物化视图,查询速度会加快(没有启动MR,只是普通的table scan)SELECT sdept, count(*) as sdept_cnt from student_trans group by sdept;--5、查询执行计划可以发现 查询被自动重写为TableScan alias: itcast.student_trans_agg--转换成了对物化视图的查询 提高了查询效率explain SELECT sdept, count(*) as sdept_cnt from student_trans group by sdept;
5. Hive DDL其他用法
5.1 数据库DDL
- 创建数据库
CREATE (DATABASE|SCHEMA) [IF NOT EXISTS] database_name[COMMENT database_comment][LOCATION hdfs_path][WITH DBPROPERTIES (property_name=property_value, ...)];
- COMMENT:数据库的注释说明语句
- LOCATION:指定数据库在HDFS存储位置,默认/user/hive/warehouse
- WITH DBPROPERTIES:用于指定一些数据库的属性配置。
- 查看库属性
DESCRIBE DATABASE/SCHEMA [EXTENDED] db_name;
- EXTENDED:用于显示更多信息。
- 删除数据库
DROP (DATABASE|SCHEMA) [IF EXISTS] database_name [RESTRICT|CASCADE];
- 默认行为是RESTRICT,仅在数据库为空时才删除它。要删除带有表的数据库,我们可以使用CASCADE。
- 元数据操作 ```sql —更改数据库属性 ALTER (DATABASE|SCHEMA) database_name SET DBPROPERTIES (property_name=property_value, …);
—更改数据库所有者 ALTER (DATABASE|SCHEMA) database_name SET OWNER [USER|ROLE] user_or_role;
—更改数据库位置 ALTER (DATABASE|SCHEMA) database_name SET LOCATION hdfs_path;
<a name="OFCv4"></a>### 5.2 表DDL1. 查看表属性```sqldescribe formatted [db_name.]table_name;describe extended [db_name.]table_name;
如果指定了EXTENDED关键字,则它将以Thrift序列化形式显示表的所有元数据。如果指定了FORMATTED关键字,则它将以表格格式显示元数据。
删除表
DROP TABLE [IF EXISTS] table_name [PURGE];
DROP TABLE删除该表的元数据和数据。
如果已配置垃圾桶(且未指定PURGE),则该表对应的数据实际上将移动到.Trash/Current目录,而元数据完全丢失。删除EXTERNAL表时,该表中的数据不会从文件系统中删除,只删除元数据。
如果指定了PURGE,则表数据不会进入.Trash/Current目录,跳过垃圾桶直接被删除。清空表
TRUNCATE [TABLE] table_name;
从表中删除所有行。可以简单理解为清空表的所有数据但是保留表的元数据结构。如果HDFS启用了垃圾桶,数据将被丢进垃圾桶,否则将被删除。
Alter table操作 ```sql —1、更改表名 ALTER TABLE table_name RENAME TO new_table_name; —2、更改表属性 ALTER TABLE table_name SET TBLPROPERTIES (property_name = property_value, … ); —更改表注释 ALTER TABLE student SET TBLPROPERTIES (‘comment’ = “new comment for student table”); —3、更改SerDe属性 ALTER TABLE table_name SET SERDE serde_class_name [WITH SERDEPROPERTIES (property_name = property_value, … )]; ALTER TABLE table_name [PARTITION partition_spec] SET SERDEPROPERTIES serde_properties; ALTER TABLE table_name SET SERDEPROPERTIES (‘field.delim’ = ‘,’); —移除SerDe属性 ALTER TABLE table_name [PARTITION partition_spec] UNSET SERDEPROPERTIES (property_name, … );
—4、更改表的文件存储格式 该操作仅更改表元数据。现有数据的任何转换都必须在Hive之外进行。 ALTER TABLE table_name SET FILEFORMAT file_format; —5、更改表的存储位置路径 ALTER TABLE table_name SET LOCATION “new location”;
—6、更改列名称/类型/位置/注释 CREATE TABLE test_change (a int, b int, c int); — First change column a’s name to a1. ALTER TABLE test_change CHANGE a a1 INT; — Next change column a1’s name to a2, its data type to string, and put it after column b. ALTER TABLE test_change CHANGE a1 a2 STRING AFTER b; — The new table’s structure is: b int, a2 string, c int. — Then change column c’s name to c1, and put it as the first column. ALTER TABLE test_change CHANGE c c1 INT FIRST; — The new table’s structure is: c1 int, b int, a2 string. — Add a comment to column a1 ALTER TABLE test_change CHANGE a1 a1 INT COMMENT ‘this is column a1’;
—7、添加/替换列 —使用ADD COLUMNS,您可以将新列添加到现有列的末尾但在分区列之前。 —REPLACE COLUMNS 将删除所有现有列,并添加新的列集。 ALTER TABLE table_name ADD|REPLACE COLUMNS (col_name data_type,…);
<a name="KnyvC"></a>### 5.3 分区DDL1. 添加分区```sqlALTER TABLE table_name ADDPARTITION (dt='2008-08-08', country='us') location '/path/to/us/part080808'PARTITION (dt='2008-08-09', country='us') location '/path/to/us/part080809';
重命名分区
ALTER TABLE table_name PARTITION (dt='2008-08-09') RENAME TO PARTITION (dt='20080809');
删除分区
-- 删除分区ALTER TABLE table_name DROP [IF EXISTS] PARTITION (dt='2008-08-08', country='us');ALTER TABLE table_name DROP [IF EXISTS] PARTITION (dt='2008-08-08', country='us') PURGE; --直接删除数据 不进垃圾桶
修复分区
-- 修复分区MSCK [REPAIR] TABLE table_name [ADD/DROP/SYNC PARTITIONS];
MSC命令的默认选项是“添加分区”。使用此选项,它将把HDFS上存在但元存储中不存在的所有分区添加到元存储中。DROP PARTITIONS选项将从已经从HDFS中删除的metastore中删除分区信息。SYNC PARTITIONS选项等效于调用ADD和DROP PARTITIONS。
Alter partition
--更改分区文件存储格式ALTER TABLE table_name PARTITION (dt='2008-08-09') SET FILEFORMAT file_format;--更改分区位置ALTER TABLE table_name PARTITION (dt='2008-08-09') SET LOCATION "new location";
6. Hive Show 语法使用
```sql —1、显示所有数据库 SCHEMAS和DATABASES的用法 功能一样 show databases; show schemas;
—2、显示当前数据库所有表/视图/物化视图/分区/索引 show tables; SHOW TABLES [IN database_name]; —指定某个数据库
—3、显示当前数据库下所有视图 Show Views; SHOW VIEWS ‘test*’; — show all views that start with “test“ SHOW VIEWS FROM test1; — show views from database test1 SHOW VIEWS [IN/FROM database_name];
—4、显示当前数据库下所有物化视图 SHOW MATERIALIZED VIEWS [IN/FROM database_name];
—5、显示表分区信息,分区按字母顺序列出,不是分区表执行该语句会报错 show partitions table_name;
—6、显示表/分区的扩展信息 SHOW TABLE EXTENDED [IN|FROM database_name] LIKE table_name; show table extended like student;
—7、显示表的属性信息 SHOW TBLPROPERTIES table_name; show tblproperties student;
—8、显示表、视图的创建语句 SHOW CREATE TABLE ([db_name.]table_name|view_name); show create table student;
—9、显示表中的所有列,包括分区列。 SHOW COLUMNS (FROM|IN) table_name [(FROM|IN) db_name]; show columns in student;
—10、显示当前支持的所有自定义和内置的函数 show functions;
—11、Describe desc —查看表信息 desc extended table_name; —查看表信息(格式化美观) desc formatted table_name; —查看数据库相关信息 describe database database_name; ```

若有收获,就点个赞吧
0 人点赞
