1. Hive参数配置
1.1 Hive CLI
$HIVE_HOME/bin/hive是一个shellUtil,通常称之为hive的第一代客户端或者旧客户端,主要功能有两个:
- 用于以交互式或批处理模式运行Hive查询,注意,此时作为客户端,需要并且能够访问的是Hive metastore服务,而不是hiveserver2服务。
- 用于hive相关服务的启动,比如metastore服务。
可以通过运行”hive -H” 或者 “hive —help”来查看命令行选项。
| -e -f -H,—help 打印帮助信息 —hiveconf -S,—silent 静默模式 -v,—verbose 详细模式,将执行sql回显到console —service service_name 启动hive的相关服务 |
|---|
1.1.1 Batch Mode 批处理模式
当使用-e或-f选项运行$ HIVE_HOME/bin/hive时,它将以批处理模式执行SQL命令。所谓的批处理可以理解为一次性执行,执行完毕退出。
#-e$HIVE_HOME/bin/hive -e 'show databases'#-fcd ~#编辑一个sql文件 里面写上合法正确的sql语句vim hive.sqlshow databases;#执行 从客户端所在机器的本地磁盘加载文件$HIVE_HOME/bin/hive -f /root/hive.sql#也可以从其他文件系统加载sql文件执行$HIVE_HOME/bin/hive -f hdfs://<namenode>:<port>/hive-script.sql$HIVE_HOME/bin/hive -f s3://mys3bucket/s3-script.sql#使用静默模式将数据从查询中转储到文件中$HIVE_HOME/bin/hive -S -e 'select * from itheima.student' > a.txt
1.1.2 Interactive Shell 交互式模式
所谓交互式模式可以理解为客户端和hive服务一直保持连接,除非手动退出客户端。
1.1.3 启动服务、修改配置
远程模式部署方式下,hive metastore服务需要单独配置手动启动,此时就可以使用Hive CLI来进行相关服务的启动,hiveserver2服务类似。
#--service$HIVE_HOME/bin/hive --service metastore$HIVE_HOME/bin/hive --service hiveserver2#--hiveconf$HIVE_HOME/bin/hive --hiveconf hive.root.logger=DEBUG,console
1.1.4 Beeline CLI
$HIVE_HOME/bin/beeline被称之为第二代客户端或者新客户端,是一个JDBC客户端,是官方强烈推荐使用的Hive命令行工具,和第一代客户端相比,性能加强安全性提高。Beeline在嵌入式模式和远程模式下均可工作。
在嵌入式模式下,它运行嵌入式Hive(类似于Hive CLI);
远程模式下beeline通过Thrift连接到单独的HiveServer2服务上,这也是官方推荐在生产环境中使用的模式。
常见的使用方式如下所示,在启动hiveserver2服务的前提下使用beeline远程连接:
[root@node3 ~]# /export/server/hive/bin/beelineBeeline version 3.1.2 by Apache Hivebeeline> ! connect jdbc:hive2://node1:10000Connecting to jdbc:hive2://node1:10000Enter username for jdbc:hive2://node1:10000: rootEnter password for jdbc:hive2://node1:10000:Connected to: Apache Hive (version 3.1.2)Driver: Hive JDBC (version 3.1.2)Transaction isolation: TRANSACTION_REPEATABLE_READ0: jdbc:hive2://node1:10000>
1.2 Configuration Properties配置属性
1.2.1 修改配置属性方式
1.2.1.1 方式1:hive-site.xml配置文件
在$HIVE_HOME/conf路径下,可以添加一个hive-site.xml文件,把需要定义修改的配置属性添加进去,这个配置文件会影响到这个Hive安装包的任何一种服务启动、客户端使用方式,可以理解为是Hive的全局配置。
1.2.1.2 方式2:hiveconf命令行参数
hiveconf是一个命令行的参数,用于在使用Hive CLI或者Beeline CLI的时候指定配置参数。这种方式的配置在整个的会话session中有效,会话结束,失效。
1.2.1.3 方式3:set命令
在Hive CLI或Beeline中使用set命令为set命令之后的所有SQL语句设置配置参数,这个也是会话级别的。
1.2.1.4 方式4:服务器特定的配置文件
您可以设置特定metastore的配置值hivemetastore-site.xml中,并在HiveServer2特定的配置值hiveserver2-site.xml中。
Hive Metastore服务器读取$ HIVE_CONF_DIR或类路径中可用的hive-site.xml以及hivemetastore-site.xml配置文件。
HiveServer2读取$ HIVE_CONF_DIR或类路径中可用的hive-site.xml以及hiveserver2-site.xml。
如果HiveServer2以嵌入式模式使用元存储,则还将加载hivemetastore-site.xml。
1.2.1.5 概况总结
配置文件的优先顺序如下,后面的优先级越高:hive-site.xml-> hivemetastore-site.xml-> hiveserver2-site.xml->’ -hiveconf’命令行参数
2. Hive内置运算符
| —显示所有的函数和运算符 show functions; —查看运算符或者函数的使用说明 describe function +; —使用extended 可以查看更加详细的使用说明 describe function extended +; |
|---|
2.1 关系运算符
关系运算符是二元运算符,执行的是两个操作数的比较运算。每个关系运算符都返回boolean类型结果(TRUE或FALSE)。
| •等值比较: = 、== •不等值比较: <> 、!= •小于比较: < •小于等于比较: <= •大于比较: > •大于等于比较: >= •空值判断: IS NULL •非空判断: IS NOT NULL •LIKE比较: LIKE •JAVA的LIKE操作: RLIKE •REGEXP操作: REGEXP |
|---|
2.2 算术运算符
算术运算符操作数必须是数值类型。 分为一元运算符和二元运算符;一元运算符,只有一个操作数;二元运算符有两个操作数,运算符在两个操作数之间。
| •加法操作: + •减法操作: - •乘法操作: * •除法操作: / •取整操作: div •取余操作: % •位与操作: & •位或操作: | •位异或操作: ^ •位取反操作: ~ |
|---|
2.3 逻辑运算符
| •与操作: A AND B •或操作: A OR B •非操作: NOT A 、!A •在:A IN (val1, val2, …) •不在:A NOT IN (val1, val2, …) •逻辑是否存在: [NOT] EXISTS (subquery) |
|---|
3. Hive函数入门
show functions 查看当下版本支持的函数;
describe function extended funcname 来查看函数的使用方式和方法。
3.1 函数分类
Hive的函数很多,除了自己内置所支持的函数之外,还支持用户自己定义开发函数。
针对内置的函数,可以根据函数的应用类型进行归纳分类,比如:数值类型函数、日期类型函数、字符串类型函数、集合函数、条件函数等;
针对用户自定义函数,可以根据函数的输入输出行数进行分类,比如:UDF、UDAF、UDTF。
3.1.1 内置函数分类
3.1.1.1 字符串函数
| •字符串长度函数:length •字符串反转函数:reverse •字符串连接函数:concat •带分隔符字符串连接函数:concat_ws •字符串截取函数:substr,substring •字符串转大写函数:upper,ucase •字符串转小写函数:lower,lcase •去空格函数:trim •左边去空格函数:ltrim •右边去空格函数:rtrim •正则表达式替换函数:regexp_replace •正则表达式解析函数:regexp_extract •URL解析函数:parse_url •json解析函数:get_json_object •空格字符串函数:space •重复字符串函数:repeat •首字符ascii函数:ascii •左补足函数:lpad •右补足函数:rpad •分割字符串函数: split •集合查找函数: find_in_set |
|---|
------------String Functions 字符串函数------------describe function extended find_in_set;--字符串长度函数:length(str | binary)select length("angelababy");--字符串反转函数:reverseselect reverse("angelababy");--字符串连接函数:concat(str1, str2, ... strN)select concat("angela","baby");--带分隔符字符串连接函数:concat_ws(separator, [string | array(string)]+)select concat_ws('.', 'www', array('itcast', 'cn'));--字符串截取函数:substr(str, pos[, len]) 或者 substring(str, pos[, len])select substr("angelababy",-2); --pos是从1开始的索引,如果为负数则倒着数select substr("angelababy",2,2);--字符串转大写函数:upper,ucaseselect upper("angelababy");select ucase("angelababy");--字符串转小写函数:lower,lcaseselect lower("ANGELABABY");select lcase("ANGELABABY");--去空格函数:trim 去除左右两边的空格select trim(" angelababy ");--左边去空格函数:ltrimselect ltrim(" angelababy ");--右边去空格函数:rtrimselect rtrim(" angelababy ");--正则表达式替换函数:regexp_replace(str, regexp, rep)select regexp_replace('100-200', '(\\d+)', 'num');--正则表达式解析函数:regexp_extract(str, regexp[, idx]) 提取正则匹配到的指定组内容select regexp_extract('100-200', '(\\d+)-(\\d+)', 2);--URL解析函数:parse_url 注意要想一次解析出多个 可以使用parse_url_tuple这个UDTF函数select parse_url('http://www.itcast.cn/path/p1.php?query=1', 'HOST');--json解析函数:get_json_object--空格字符串函数:space(n) 返回指定个数空格select space(4);--重复字符串函数:repeat(str, n) 重复str字符串n次select repeat("angela",2);--首字符ascii函数:asciiselect ascii("angela"); --a对应ASCII 97--左补足函数:lpadselect lpad('hi', 5, '??'); --???hiselect lpad('hi', 1, '??'); --h--右补足函数:rpadselect rpad('hi', 5, '??');--分割字符串函数: split(str, regex)select split('apache hive', '\\s+');--集合查找函数: find_in_set(str,str_array)select find_in_set('a','abc,b,ab,c,def');
3.1.1.2 日期函数
| •获取当前日期:current_date •获取当前时间戳:current_timestamp •UNIX时间戳转日期函数: from_unixtime •获取当前UNIX时间戳函数: unix_timestamp •日期转UNIX时间戳函数: unix_timestamp •指定格式日期转UNIX时间戳函数: unix_timestamp •抽取日期函数: to_date •日期转年函数: year •日期转月函数: month •日期转天函数: day •日期转小时函数: hour •日期转分钟函数: minute •日期转秒函数: second •日期转周函数: weekofyear •日期比较函数: datediff •日期增加函数: date_add •日期减少函数: date_sub |
|---|
--获取当前日期: current_dateselect current_date();--获取当前时间戳: current_timestamp--同一查询中对current_timestamp的所有调用均返回相同的值。select current_timestamp();--获取当前UNIX时间戳函数: unix_timestampselect unix_timestamp();--UNIX时间戳转日期函数: from_unixtimeselect from_unixtime(1618238391);select from_unixtime(0, 'yyyy-MM-dd HH:mm:ss');--日期转UNIX时间戳函数: unix_timestampselect unix_timestamp("2011-12-07 13:01:03");--指定格式日期转UNIX时间戳函数: unix_timestampselect unix_timestamp('20111207 13:01:03','yyyyMMdd HH:mm:ss');--抽取日期函数: to_dateselect to_date('2009-07-30 04:17:52');--日期转年函数: yearselect year('2009-07-30 04:17:52');--日期转月函数: monthselect month('2009-07-30 04:17:52');--日期转天函数: dayselect day('2009-07-30 04:17:52');--日期转小时函数: hourselect hour('2009-07-30 04:17:52');--日期转分钟函数: minuteselect minute('2009-07-30 04:17:52');--日期转秒函数: secondselect second('2009-07-30 04:17:52');--日期转周函数: weekofyear 返回指定日期所示年份第几周select weekofyear('2009-07-30 04:17:52');--日期比较函数: datediff 日期格式要求'yyyy-MM-dd HH:mm:ss' or 'yyyy-MM-dd'select datediff('2012-12-08','2012-05-09');--日期增加函数: date_addselect date_add('2012-02-28',10);--日期减少函数: date_subselect date_sub('2012-01-1',10);
3.1.1.3 数学函数
| •取整函数: round •指定精度取整函数: round •向下取整函数: floor •向上取整函数: ceil •取随机数函数: rand •二进制函数: bin •进制转换函数: conv •绝对值函数: abs |
|---|
--取整函数: round 返回double类型的整数值部分 (遵循四舍五入)select round(3.1415926);--指定精度取整函数: round(double a, int d) 返回指定精度d的double类型select round(3.1415926,4);--向下取整函数: floorselect floor(3.1415926);select floor(-3.1415926);--向上取整函数: ceilselect ceil(3.1415926);select ceil(-3.1415926);--取随机数函数: rand 每次执行都不一样 返回一个0到1范围内的随机数select rand();--指定种子取随机数函数: rand(int seed) 得到一个稳定的随机数序列select rand(2);--二进制函数: bin(BIGINT a)select bin(18);--进制转换函数: conv(BIGINT num, int from_base, int to_base)select conv(17,10,16);--绝对值函数: absselect abs(-3.9);
3.1.1.4 集合函数
| •集合元素size函数:size(Map •取map集合keys函数:map_keys(Map •取map集合values函数:map_values(Map •判断数组是否包含指定元素:array_contains(Array •数组排序函数:sort_array(Array |
|---|
--集合元素size函数: size(Map<K.V>) size(Array<T>)select size(`array`(11,22,33));select size(`map`("id",10086,"name","zhangsan","age",18));--取map集合keys函数: map_keys(Map<K.V>)select map_keys(`map`("id",10086,"name","zhangsan","age",18));--取map集合values函数: map_values(Map<K.V>)select map_values(`map`("id",10086,"name","zhangsan","age",18));--判断数组是否包含指定元素: array_contains(Array<T>, value)select array_contains(`array`(11,22,33),11);select array_contains(`array`(11,22,33),66);--数组排序函数:sort_array(Array<T>)select sort_array(`array`(12,2,32));
3.1.1.5 条件函数
| •if条件判断:if(boolean testCondition, T valueTrue, T valueFalseOrNull) •空判断函数:isnull( a ) •非空判断函数:isnotnull ( a ) •空值转换函数:nvl(T value, T default_value) •非空查找函数:COALESCE(T v1, T v2, …) •条件转换函数:CASE a WHEN b THEN c [WHEN d THEN e]* [ELSE f] END •nullif( a, b ):如果a = b,则返回NULL;否则返回NULL。否则返回一个 •assert_true:如果’condition’不为真,则引发异常,否则返回null |
|---|
--使用之前课程创建好的student表数据select * from student limit 3;--if条件判断: if(boolean testCondition, T valueTrue, T valueFalseOrNull)select if(1=2,100,200);select if(sex ='男','M','W') from student limit 3;--空判断函数: isnull( a )select isnull("allen");select isnull(null);--非空判断函数: isnotnull ( a )select isnotnull("allen");select isnotnull(null);--空值转换函数: nvl(T value, T default_value)select nvl("allen","itcast");select nvl(null,"itcast");--非空查找函数: COALESCE(T v1, T v2, ...)--返回参数中的第一个非空值;如果所有值都为NULL,那么返回NULLselect COALESCE(null,11,22,33);select COALESCE(null,null,null,33);select COALESCE(null,null,null);--条件转换函数: CASE a WHEN b THEN c [WHEN d THEN e]* [ELSE f] ENDselect case 100 when 50 then 'tom' when 100 then 'mary' else 'tim' end;select case sex when '男' then 'man' else 'women' end from student limit 3;--nullif( a, b ):-- 果a = b,则返回NULL;否则返回NULL。否则返回一个select nullif(11,11);select nullif(11,12);--assert_true(condition)--如果'condition'不为真,则引发异常,否则返回nullSELECT assert_true(11 >= 0);SELECT assert_true(-1 >= 0);
3.1.1.6 类型转换函数
| •任意数据类型之间转换:cast —任意数据类型之间转换:cast select cast(12.14 as bigint); select cast(12.14 as string); |
|---|
3.1.1.7 数据脱敏函数
| •mask •mask_first_n(string str[, int n] •mask_last_n(string str[, int n]) •mask_show_first_n(string str[, int n]) •mask_show_last_n(string str[, int n]) •mask_hash(string|char|varchar str) |
|---|
--mask--将查询回的数据,大写字母转换为X,小写字母转换为x,数字转换为n。select mask("abc123DEF");select mask("abc123DEF",'-','.','^'); --自定义替换的字母--mask_first_n(string str[, int n]--对前n个进行脱敏替换select mask_first_n("abc123DEF",4);--mask_last_n(string str[, int n])select mask_last_n("abc123DEF",4);--mask_show_first_n(string str[, int n])--除了前n个字符,其余进行掩码处理select mask_show_first_n("abc123DEF",4);--mask_show_last_n(string str[, int n])select mask_show_last_n("abc123DEF",4);--mask_hash(string|char|varchar str)--返回字符串的hash编码。select mask_hash("abc123DEF");
3.1.1.8 其他杂项函数
| •hive调用java方法: java_method(class, method[, arg1[, arg2..]]) •反射函数: reflect(class, method[, arg1[, arg2..]]) •取哈希值函数:hash •current_user()、logged_in_user()、current_database()、version() •SHA-1加密: sha1(string/binary) •SHA-2家族算法加密:sha2(string/binary, int) (SHA-224, SHA-256, SHA-384, SHA-512) •crc32加密: •MD5加密: md5(string/binary) |
|---|
--hive调用java方法: java_method(class, method[, arg1[, arg2..]])select java_method("java.lang.Math","max",11,22);--反射函数: reflect(class, method[, arg1[, arg2..]])select reflect("java.lang.Math","max",11,22);--取哈希值函数:hashselect hash("allen");--current_user()、logged_in_user()、current_database()、version()--SHA-1加密: sha1(string/binary)select sha1("allen");--SHA-2家族算法加密:sha2(string/binary, int) (SHA-224, SHA-256, SHA-384, SHA-512)select sha2("allen",224);select sha2("allen",512);--crc32加密:select crc32("allen");--MD5加密: md5(string/binary)select md5("allen");
3.1.2 用户自定义函数分类
- UDF(User-Defined-Function)普通函数,一进一出
- UDAF(User-Defined Aggregation Function)聚合函数,多进一出
- UDTF(User-Defined Table-Generating Functions)表生成函数,一进多出
3.1.2.1 UDF 普通函数
UDF函数通常把它叫做普通函数,最大的特点是一进一出,也就是输入一行输出一行。3.1.2.2 UDAF 聚合函数
UDAF函数通常把它叫做聚合函数,A所代表的单词就是Aggregation聚合的意思。最大的特点是多进一出,也就是输入多行输出一行。
| •count:统计检索到的总行数。 •sum:求和 •avg:求平均 •min:最小值 •max:最大值 •数据收集函数(去重): collect_set(col) •数据收集函数(不去重): collect_list(col) |
|---|
3.1.2.3 UDTF 表生成函数
UDTF函数通常把它叫做表生成函数,T所代表的单词是Table-Generating表生成的意思。最大的特点是一进多出,也就是输入一行输出多行。比如explode函数。
3.2 用户自定义UDF
3.2.1 实现步骤
| 1、写一个java类,继承UDF,并重载evaluate方法; 2、程序打成jar包,上传服务器添加到hive的classpath; hive>add JAR /home/hadoop/udf.jar; 3、注册成为临时函数(给UDF命名); create temporary function 函数名 as ‘UDF类全路径’; 4、使用函数 |
|---|
手机号脱敏代码示例:
package com.nkong.hive.udf;import org.apache.commons.lang.StringUtils;import org.apache.hadoop.hive.ql.exec.UDF;import java.util.regex.Matcher;import java.util.regex.Pattern;/*** @description: hive自定义函数UDF 实现对手机号中间4位进行****加密* @author: Itcast*/public class EncryptPhoneNumber extends UDF {/*** 重载evaluate方法 实现函数的业务逻辑* @param phoNum 入参:未加密手机号* @return 返回:加密后的手机号字符串*/public String evaluate(String phoNum){String encryptPhoNum = null;//手机号不为空 并且为11位if (StringUtils.isNotEmpty(phoNum) && phoNum.trim().length() == 11 ) {//判断数据是否满足中国大陆手机号码规范String regex = "^(1[3-9]\\d{9}$)";Pattern p = Pattern.compile(regex);Matcher m = p.matcher(phoNum);if (m.matches()) {//进入这里都是符合手机号规则的//使用正则替换 返回加密后数据encryptPhoNum = phoNum.trim().replaceAll("()\\d{4}(\\d{4})","$1****$2");}else{//不符合手机号规则 数据直接原封不动返回encryptPhoNum = phoNum;}}else{//不符合11位 数据直接原封不动返回encryptPhoNum = phoNum;}return encryptPhoNum;}}
4. Hive函数高阶
4.1 UDTF之explode函数
4.1.1 explode语法功能
explode函数,中文戏称之为“爆炸函数”,可以炸开数据。
explode函数接收map或者array类型的数据作为参数,然后把参数中的每个元素炸开变成一行数据。一个元素一行。这样的效果正好满足于输入一行输出多行。
一般情况下,explode函数可以直接使用即可,也可以根据需要结合lateral view侧视图使用。
4.1.2 explode函数的使用
select explode(`array`(11,22,33)) as item;
select explode(`map`("id",10086,"name","zhangsan","age",18));
4.1.3 使用示例
- 业务需求
有一份数据《The_NBA_Championship.txt》,关于部分年份的NBA总冠军球队名单: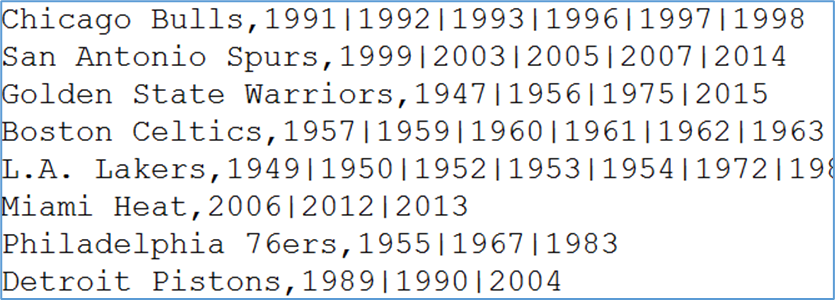
第一个字段表示的是球队名称,第二个字段是获取总冠军的年份,字段之间以“,”分割;
获取总冠军年份之间以“|”进行分割。
需求:使用Hive建表映射成功数据,对数据拆分,要求拆分之后数据如下所示:
并且最好根据年份的倒序进行排序。
- 代码实现
```sql
—step1:建表
create table the_nba_championship(
team_name string,
champion_year array
) row format delimited fields terminated by ‘,’ collection items terminated by ‘|’;
—step2:加载数据文件到表中 load data local inpath ‘/root/hivedata/The_NBA_Championship.txt’ into table the_nba_championship;
—step3:验证 select * from the_nba_championship;
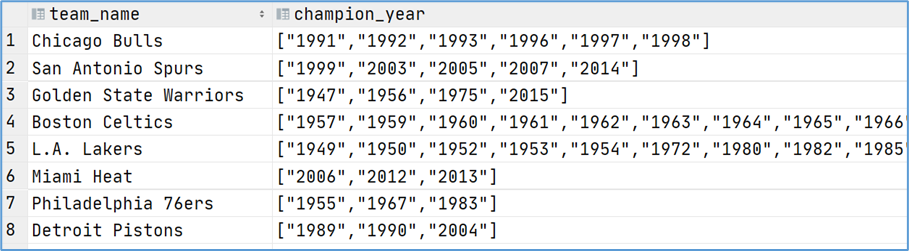<br />使用explode函数:
```sql
--step4:使用explode函数对champion_year进行拆分 俗称炸开
select explode(champion_year) from the_nba_championship;
-- 报错?
select team_name,explode(champion_year) from the_nba_championship;
explode使用限制: 如果只有explode函数表达式,程序执行是没有任何问题的;但是如果在select条件中,包含explode和其他字段,就会报错。(不能在只查询源表的时候,既想返回源表字段又想返回explode生成的虚拟表字段)
Hive专门提供了语法lateral View侧视图,专门用于搭配explode这样的UDTF函数,以满足上述需要。
4.2 Lateral View 侧视图
4.2.1 概念
Lateral View是一种特殊的语法,主要用于搭配UDTF类型功能的函数一起使用,用于解决UDTF函数的一些查询限制的问题。
侧视图的原理是将UDTF的结果构建成一个类似于视图的表,然后将原表中的每一行和UDTF函数输出的每一行进行连接,生成一张新的虚拟表。这样就避免了UDTF的使用限制问题。使用lateral view时也可以对UDTF产生的记录设置字段名称,产生的字段可以用于group by、order by 、limit等语句中,不需要再单独嵌套一层子查询。
4.2.2 UDTF配合侧视图使用
针对上述NBA冠军球队年份排名案例,使用explode函数+lateral view侧视图,可以完美解决:
--lateral view侧视图基本语法如下
select …… from tabelA lateral view UDTF(xxx) 别名 as col1,col2,col3……;
select a.team_name ,b.year
from the_nba_championship a lateral view explode(champion_year) b as year
--根据年份倒序排序
select a.team_name ,b.year
from the_nba_championship a lateral view explode(champion_year) b as year
order by b.year desc;
4.3 Aggregation 聚合函数
4.3.1 基础聚合
HQL提供了几种内置的UDAF聚合函数,例如max(…),min(…)和avg(…)。这些我们把它称之为基础的聚合函数。
通常情况下,聚合函数会与GROUP BY子句一起使用。 如果未指定GROUP BY子句,默认情况下,它会汇总所有行数据。
4.3.2 增强聚合
4.3.2.1 概述
增强聚合的grouping_sets、cube、rollup这几个函数主要适用于OLAP多维数据分析模式中,多维分析中的维指的分析问题时看待问题的维度、角度。
数据准备,字段:月份、天、用户cookieid。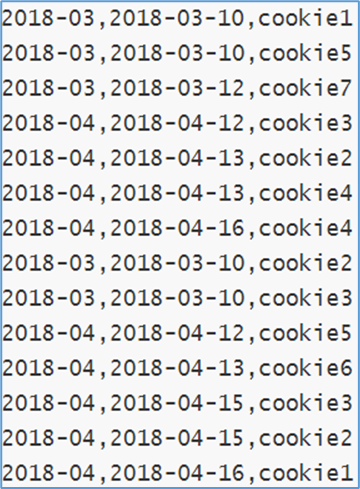
--表创建并且加载数据
CREATE TABLE cookie_info(
month STRING,
day STRING,
cookieid STRING
) ROW FORMAT DELIMITED
FIELDS TERMINATED BY ',';
load data local inpath '/root/hivedata/cookie_info.txt' into table cookie_info;
4.3.2.2 Grouping sets
grouping sets是一种将多个group by逻辑写在一个sql语句中的便利写法。等价于将不同维度的GROUP BY结果集进行UNION ALL。GROUPING__ID表示结果属于哪一个分组集合。
---group sets---------
SELECT
month,
day,
COUNT(DISTINCT cookieid) AS nums,
GROUPING__ID
FROM cookie_info
GROUP BY month,day
GROUPING SETS (month,day)
ORDER BY GROUPING__ID;
--grouping_id表示这一组结果属于哪个分组集合,
--根据grouping sets中的分组条件month,day,1是代表month,2是代表day
--等价于
SELECT month,NULL,COUNT(DISTINCT cookieid) AS nums,1 AS GROUPING__ID FROM cookie_info GROUP BY month
UNION ALL
SELECT NULL as month,day,COUNT(DISTINCT cookieid) AS nums,2 AS GROUPING__ID FROM cookie_info GROUP BY day;
--再比如
SELECT
month,
day,
COUNT(DISTINCT cookieid) AS nums,
GROUPING__ID
FROM cookie_info
GROUP BY month,day
GROUPING SETS (month,day,(month,day))
ORDER BY GROUPING__ID;
--等价于
SELECT month,NULL,COUNT(DISTINCT cookieid) AS nums,1 AS GROUPING__ID FROM cookie_info GROUP BY month
UNION ALL
SELECT NULL,day,COUNT(DISTINCT cookieid) AS nums,2 AS GROUPING__ID FROM cookie_info GROUP BY day
UNION ALL
SELECT month,day,COUNT(DISTINCT cookieid) AS nums,3 AS GROUPING__ID FROM cookie_info GROUP BY month,day;
4.3.2.3 Cube
cube的语法功能指的是:根据GROUP BY的维度的所有组合进行聚合。
对于cube,如果有n个维度,则所有组合的总个数是:2^n。比如Cube有a,b,c3个维度,则所有组合情况是:((a,b,c),(a,b),(b,c),(a,c),(a),(b),(c),())。
------cube---------------
SELECT
month,
day,
COUNT(DISTINCT cookieid) AS nums,
GROUPING__ID
FROM cookie_info
GROUP BY month,day
WITH CUBE
ORDER BY GROUPING__ID;
--等价于
SELECT NULL,NULL,COUNT(DISTINCT cookieid) AS nums,0 AS GROUPING__ID FROM cookie_info
UNION ALL
SELECT month,NULL,COUNT(DISTINCT cookieid) AS nums,1 AS GROUPING__ID FROM cookie_info GROUP BY month
UNION ALL
SELECT NULL,day,COUNT(DISTINCT cookieid) AS nums,2 AS GROUPING__ID FROM cookie_info GROUP BY day
UNION ALL
SELECT month,day,COUNT(DISTINCT cookieid) AS nums,3 AS GROUPING__ID FROM cookie_info GROUP BY month,day;
4.3.2.4 Rollup
rollup是Cube的子集,以最左侧的维度为主,从该维度进行层级聚合。比如ROLLUP有a,b,c3个维度,则所有组合情况是:((a,b,c),(a,b),(a),())。
--rollup-------------
--比如,以month维度进行层级聚合:
SELECT
month,
day,
COUNT(DISTINCT cookieid) AS nums,
GROUPING__ID
FROM cookie_info
GROUP BY month,day
WITH ROLLUP
ORDER BY GROUPING__ID;
--把month和day调换顺序,则以day维度进行层级聚合:
SELECT
day,
month,
COUNT(DISTINCT cookieid) AS uv,
GROUPING__ID
FROM cookie_info
GROUP BY day,month
WITH ROLLUP
ORDER BY GROUPING__ID;
4.4 Window functions 窗口函数
4.4.1 窗口函数概述
窗口函数(Window functions)是一种SQL函数,非常适合于数据分析,因此也叫做OLAP函数,其最大特点是:输入值是从SELECT语句的结果集中的一行或多行的“窗口”中获取的。你也可以理解为窗口有大有小(行有多有少)。
通过OVER子句,窗口函数与其他SQL函数有所区别。如果函数具有OVER子句,则它是窗口函数。如果它缺少OVER子句,则它是一个普通的聚合函数。
窗口函数可以简单地解释为类似于聚合函数的计算函数,但是通过GROUP BY子句组合的常规聚合会隐藏正在聚合的各个行,最终输出一行,窗口函数聚合后还可以访问当中的各个行,并且可以将这些行中的某些属性添加到结果集中。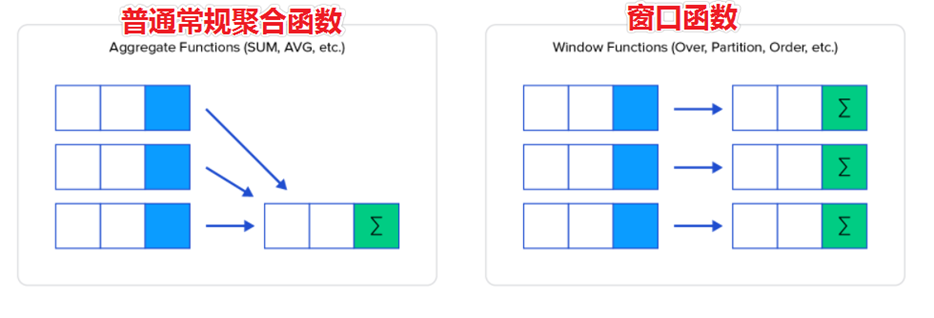
4.4.2 窗口函数语法
| Function(arg1,…, argn) OVER ([PARTITION BY <…>] [ORDER BY <….>] [
—其中Function(arg1,…, argn) 可以是下面分类中的任意一个
—聚合函数:比如sum max avg等
—排序函数:比如rank row_number等
—分析函数:比如lead lag first_value等
—OVER [PARTITION BY <…>] 类似于group by 用于指定分组 每个分组你可以把它叫做窗口
—如果没有PARTITION BY 那么整张表的所有行就是一组
—[ORDER BY <….>] 用于指定每个分组内的数据排序规则 支持ASC、DESC
—[
4.4.3 使用案例
- 需求:网站用户页面浏览次数分析
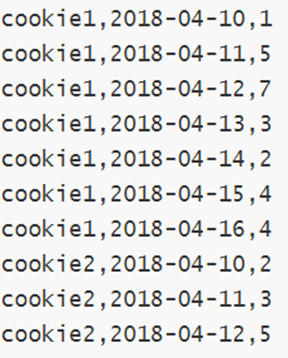
字段含义:cookieid 、访问时间、pv数(页面浏览数)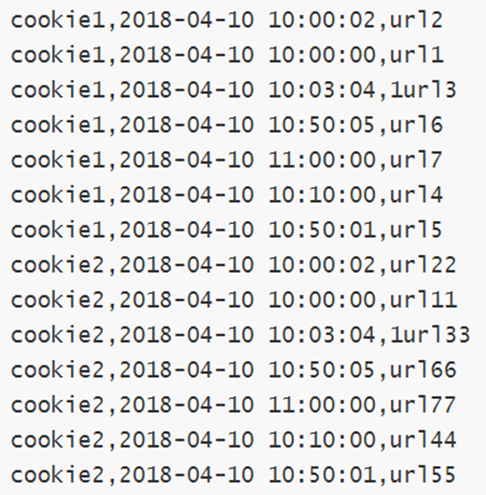
字段含义:cookieid、访问时间、访问页面url
---建表并且加载数据
create table website_pv_info(
cookieid string,
createtime string, --day
pv int
) row format delimited
fields terminated by ',';
create table website_url_info (
cookieid string,
createtime string, --访问时间
url string --访问页面
) row format delimited
fields terminated by ',';
load data local inpath '/root/hivedata/website_pv_info.txt' into table website_pv_info;
load data local inpath '/root/hivedata/website_url_info.txt' into table website_url_info;
4.4.3.1 窗口聚合函数
-----窗口聚合函数的使用-----------
--1、求出每个用户总pv数 sum+group by普通常规聚合操作
select cookieid,sum(pv) as total_pv from website_pv_info group by cookieid;
--2、sum+窗口函数 总共有四种用法 注意是整体聚合 还是累积聚合
--sum(...) over( )对表所有行求和
--sum(...) over( order by ... ) 连续累积求和
--sum(...) over( partition by... ) 同组内所有行求和
--sum(...) over( partition by... order by ... ) 在每个分组内,连续累积求和
--需求:求出网站总的pv数 所有用户所有访问加起来
--sum(...) over( )对表所有行求和
select cookieid,createtime,pv,
sum(pv) over() as total_pv
from website_pv_info;
--需求:求出每个用户总pv数
--sum(...) over( partition by... ),同组内所行求和
select cookieid,createtime,pv,
sum(pv) over(partition by cookieid) as total_pv
from website_pv_info;
--需求:求出每个用户截止到当天,累积的总pv数
--sum(...) over( partition by... order by ... ),在每个分组内,连续累积求和
select cookieid,createtime,pv,
sum(pv) over(partition by cookieid order by createtime) as current_total_pv
from website_pv_info;
4.4.3.2 窗口表达式
在sum(…) over( partition by… order by … )语法完整的情况下,进行的累积聚合操作,默认累积聚合行为是:从第一行聚合到当前行。
Window expression窗口表达式给我们提供了一种控制行范围的能力,比如向前2行,向后3行。
语法如下:
| 关键字是rows between,包括下面这几个选项 - preceding:往前 - following:往后 - current row:当前行 - unbounded:边界 - unbounded preceding 表示从前面的起点 - unbounded following:表示到后面的终点 |
|---|
---窗口表达式
--第一行到当前行
select cookieid,createtime,pv,
sum(pv) over(partition by cookieid order by createtime rows between unbounded preceding and current row) as pv2
from website_pv_info;
--向前3行至当前行
select cookieid,createtime,pv,
sum(pv) over(partition by cookieid order by createtime rows between 3 preceding and current row) as pv4
from website_pv_info;
--向前3行 向后1行
select cookieid,createtime,pv,
sum(pv) over(partition by cookieid order by createtime rows between 3 preceding and 1 following) as pv5
from website_pv_info;
--当前行至最后一行
select cookieid,createtime,pv,
sum(pv) over(partition by cookieid order by createtime rows between current row and unbounded following) as pv6
from website_pv_info;
--第一行到最后一行 也就是分组内的所有行
select cookieid,createtime,pv,
sum(pv) over(partition by cookieid order by createtime rows between unbounded preceding and unbounded following) as pv6
from website_pv_info;
4.4.3.3 窗口排序函数
窗口排序函数用于给每个分组内的数据打上排序的标号。注意窗口排序函数不支持窗口表达式。
- row_number(排序):在每个分组中,为每行分配一个从1开始的唯一序列号,递增,不考虑重复;
- rank(跳跃排名): 在每个分组中,为每行分配一个从1开始的序列号,考虑重复,挤占后续位置;
- dense_rank(连续排名): 在每个分组中,为每行分配一个从1开始的序列号,考虑重复,不挤占后续位置;
| ——-窗口排序函数
SELECT
cookieid,
createtime,
pv,
RANK() OVER(PARTITION BY cookieid ORDER BY pv desc) AS rn1,
DENSE_RANK() OVER(PARTITION BY cookieid ORDER BY pv desc) AS rn2,
ROW_NUMBER() OVER(PARTITION BY cookieid ORDER BY pv DESC) AS rn3
FROM website_pv_info
WHERE cookieid = ‘cookie1’; | | —- |
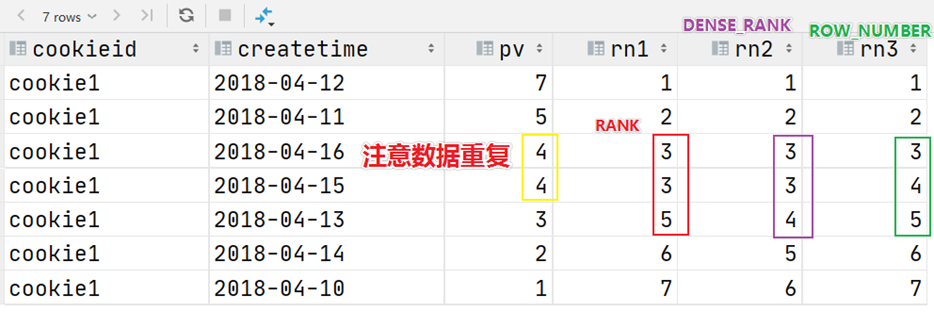
上述这三个函数用于分组TopN的场景非常适合。
--需求:找出每个用户访问pv最多的Top3 重复并列的不考虑
SELECT * from
(SELECT
cookieid,
createtime,
pv,
ROW_NUMBER() OVER(PARTITION BY cookieid ORDER BY pv DESC) AS seq
FROM website_pv_info) tmp where tmp.seq <4;
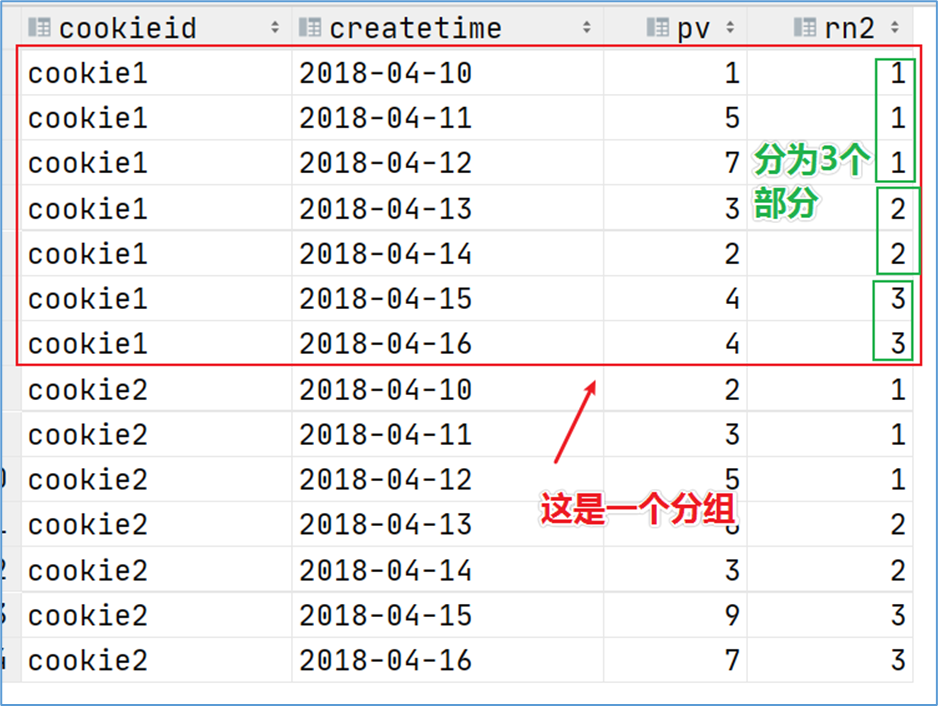
- ntile,其功能为:将每个分组内的数据分为指定的若干个桶里(分为若干个部分),并且为每一个桶分配一个桶编号。如果不能平均分配,则优先分配较小编号的桶,并且各个桶中能放的行数最多相差1。
有时会有这样的需求:如果数据排序后分为三部分,业务人员只关心其中的一部分,如何将这中间的三分之一数据拿出来呢?NTILE函数即可以满足。
--把每个分组内的数据分为3桶
SELECT
cookieid,
createtime,
pv,
NTILE(3) OVER(PARTITION BY cookieid ORDER BY createtime) AS rn2
FROM website_pv_info
ORDER BY cookieid,createtime;
--需求:统计每个用户pv数最多的前3分之1天。
--理解:将数据根据cookieid分 根据pv倒序排序 排序之后分为3个部分 取第一部分
SELECT * from
(SELECT
cookieid,
createtime,
pv,
NTILE(3) OVER(PARTITION BY cookieid ORDER BY pv DESC) AS rn
FROM website_pv_info) tmp where rn =1;
4.4.3.4 窗口分析函数
- LAG(col,n,DEFAULT):用于统计窗口内往上第n行值。
第一个参数为列名,第二个参数为往上第n行(可选,默认为1),第三个参数为默认值(当往上第n行为NULL时候,取默认值,如不指定,则为NULL);
- LEAD(col,n,DEFAULT):用于统计窗口内往下第n行值
第一个参数为列名,第二个参数为往下第n行(可选,默认为1),第三个参数为默认值(当往下第n行为NULL时候,取默认值,如不指定,则为NULL);
- FIRST_VALUE():取分组内排序后,截止到当前行,第一个值;
- LAST_VALUE():取分组内排序后,截止到当前行,最后一个值;
```sql
—————-窗口分析函数—————
—LAG
SELECT cookieid,
FROM website_url_info;createtime, url, ROW_NUMBER() OVER(PARTITION BY cookieid ORDER BY createtime) AS rn, LAG(createtime,1,'1970-01-01 00:00:00') OVER(PARTITION BY cookieid ORDER BY createtime) AS last_1_time, LAG(createtime,2) OVER(PARTITION BY cookieid ORDER BY createtime) AS last_2_time
—LEAD SELECT cookieid, createtime, url, ROW_NUMBER() OVER(PARTITION BY cookieid ORDER BY createtime) AS rn, LEAD(createtime,1,’1970-01-01 00:00:00’) OVER(PARTITION BY cookieid ORDER BY createtime) AS next_1_time, LEAD(createtime,2) OVER(PARTITION BY cookieid ORDER BY createtime) AS next_2_time FROM website_url_info;
—FIRST_VALUE SELECT cookieid, createtime, url, ROW_NUMBER() OVER(PARTITION BY cookieid ORDER BY createtime) AS rn, FIRST_VALUE(url) OVER(PARTITION BY cookieid ORDER BY createtime) AS first1 FROM website_url_info;
—LAST_VALUE SELECT cookieid, createtime, url, ROW_NUMBER() OVER(PARTITION BY cookieid ORDER BY createtime) AS rn, LAST_VALUE(url) OVER(PARTITION BY cookieid ORDER BY createtime) AS last1 FROM website_url_info;
<a name="tYz1w"></a>
### 4.5 Sampling 抽样函数
当数据量过大时,我们可能需要查找数据子集以加快数据处理速度分析。 这就是抽样、采样,一种用于识别和分析数据中的子集的技术,以发现整个数据集中的模式和趋势。 <br />在HQL中,可以通过三种方式采样数据:**随机采样,存储桶表采样和块采样**。
<a name="fAu9W"></a>
#### 4.5.1 Random随机抽样
随机抽样使用**rand()函数和LIMIT关键字**来获取数据。 使用了DISTRIBUTE和SORT关键字,可以确保数据也随机分布在mapper和reducer之间,使得底层执行有效率。 <br />ORDER BY 和rand()语句也可以达到相同的目的,但是表现不好。因为ORDER BY是全局排序,只会启动运行一个Reducer。
```sql
--数据表
select * from student;
--需求:随机抽取2个学生的情况进行查看
SELECT * FROM student DISTRIBUTE BY rand() SORT BY rand() LIMIT 2;
--使用order by+rand也可以实现同样的效果 但是效率不高
SELECT * FROM student ORDER BY rand() LIMIT 2;
4.5.2 Block块抽样
Block块采样允许select随机获取n行数据,即数据大小或n个字节的数据。采样粒度是HDFS块大小。
---block抽样
--根据行数抽样
SELECT * FROM student TABLESAMPLE(1 ROWS);
--根据数据大小百分比抽样
SELECT * FROM student TABLESAMPLE(50 PERCENT);
--根据数据大小抽样
--支持数据单位 b/B, k/K, m/M, g/G
SELECT * FROM student TABLESAMPLE(1k);
4.5.3 Bucket table分桶表抽样
这是一种特殊的采样方法,针对分桶表进行了优化。
---bucket table抽样
--根据整行数据进行抽样
SELECT * FROM t_usa_covid19_bucket TABLESAMPLE(BUCKET 1 OUT OF 2 ON rand());
--根据分桶字段进行抽样 效率更高
describe formatted t_usa_covid19_bucket;
SELECT * FROM t_usa_covid19_bucket TABLESAMPLE(BUCKET 1 OUT OF 2 ON state);

若有收获,就点个赞吧
0 人点赞
