1. 什么是Hive
- Hive是一款建立在Hadoop之上的开源数据仓库系统,可以将存储在Hadoop文件中的结构化、半结构化数据文件映射为一张数据库表,基于表提供了一种类似SQL的查询模型,称为Hice查询语言(HQL),用于访问和分析存储在Hadoop文件中的大型数据集。
- Hive核心是将HQL转换为MapReduce程序,然后将程序提交给Hadoop集群执行。
- Hive由Facebook实现并开源。
- Hive和Hadoop关系?
- Hive利用HDFS存储数据,利用MapReduce查询分析数据。
- 用户专注于编写HQL,Hive帮用户转换为MapReduce程序并完成对数据的分析。
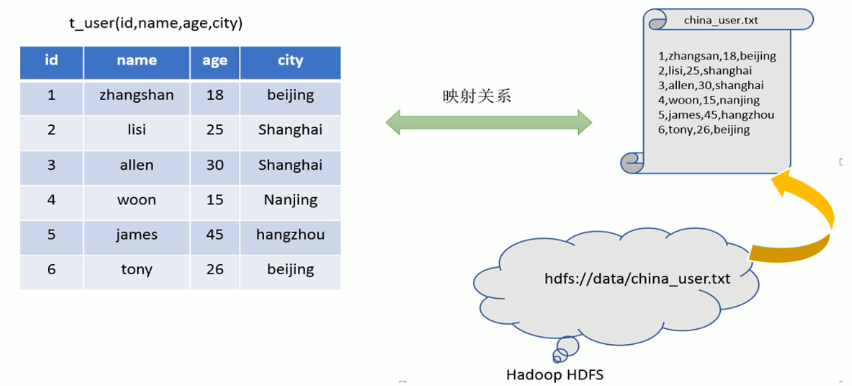
- 映射信息记录
- 在Hive中能够写sql处理的前提是针对表,而不是针对文件,因此需要将文件和表之间的对应关系描述记录清楚。映射信息专业的叫法称之为元数据信息。
- 具体来看,要记录的元数据信息包括:表对应哪个文件(位置信息)、表的列对应着文件哪一个字段(顺序信息)、文件字段之间的分隔符是什么。
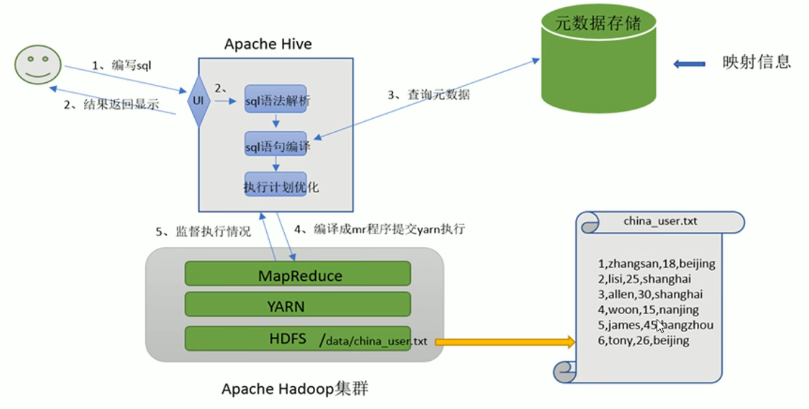
- 用户编写完sql之后,hive需要针对sql进行语法校验,并且根据记录的元数据信息解读sql的含义,制定执行计划。并且把执行计划转换为MapReduce程序来执行,把执行的结果封装返回给用户。
- 执行流程
2. Hive架构
Hive架构图: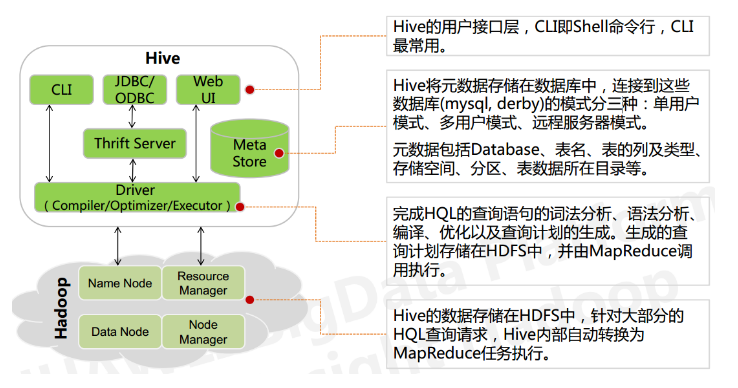
- 用户接口层
包括CLI、JDBC、WebGUI。其中,CLI为shell命令行;Hive中的Thrift服务器允许外部客户端通过网络与Hive进行交互,类似于JDBC或ODBC协议。WebGUI是通过浏览器访问Hive。
- 元数据存储
通常是存储在关系型数据库中。Hive中的元数据包括表名、字段和分区属性,表的属性,表数据所在目录等。
- Driver驱动程序,包括语法解析、计划编译器、优化器、执行器
完成HQL查询语句从词法分析、语法分析、编译、优化以及查询计划的生成。生成的查询计划存储在HDFS中,并由执行引擎调用执行。
- 执行引擎
Hive本身并不直接处理数据文件。而是通过执行引擎处理。当下Hive支持MapReduce、Tez、Spark三种执行引擎。
2.1 Hive数据模型
2.1.1 Data Model
- 数据模型:用来描述数据、组织数据和对数据进行操作,是对现实世界数据特征的描述。
- Hive的数据模型类似于RDBMS库表结构,此外还有自己特有模型。
- Hive中的数据可以在粒度级别上分为:表、分区、分桶。
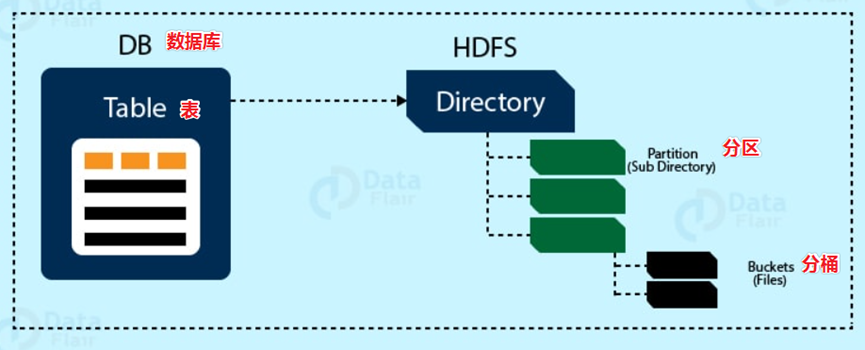
2.1.2 Databases 数据库
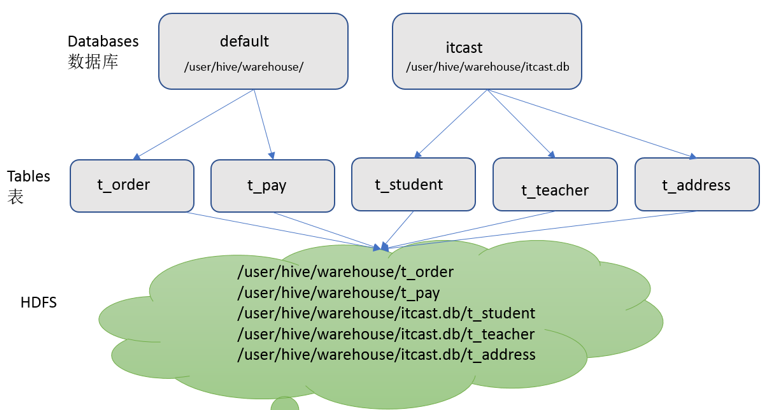
- Hive作为一个数据仓库,在结构上和RDBMS类似,也分数据库,每个数据库下面有各自的表组成。默认数据库default。
Hive的数据是存储在HDFS上的,默认有一个根目录,在hive-site.xml中,由参数hive.metastore.warehouse.dir指定。默认值为/user/hive/warehouse。
2.2.3 Tables 表
Hive表与RDBMS中的表相同。Hive中的表所对应的数据通常是存储在HDFS中,而表相关的元数据是存储在RDBMS中。
- Hive中的表数据在HDFS上存储的路径为:${hive.metastore.warehouse.dir}/db/table。
2.2.4 Partitions 分区
- Partition分区是Hive的一种优化表手段。分区是指根据分区列的值将表划分为不同分区。这样可以更快地对指定分区数据进行查询。
- 分区在存储层面上的表现是,table表目录下以子文件夹的形式存在。
- 一个文件夹表示一份分区。子文件命名标准:分区列=分区值。
-
2.2.5 Buckets 分桶
Bucket分桶表是hive中的一种优化表手段。分桶是指根据表中字段的值,经过hash计算规则将数据文件划分成指定的若干个小文件。
- 分桶规则:hashfunc(字段)/桶个数。余数相同的分到同一个文件。
- 分桶的好处是可以优化join查询和方便抽样查询。
- Bucket分桶表在HDFS中表现为同一个表目录下数据根据hash散列之后变成多个文件。
2.2 元数据
描述数据的数据,主要是描述数据属性的信息,用来支持如指示存储位置、历史数据、资源查找、文件记录等功能。2.2.1 Metadata
Metadata即元数据。元数据包含用Hive创建的database、table、表的位置、类型、属性,字段顺序类型等元信息。元数据存储在关系型数据库中。如hive内置的Derby、或者第三方如MySQL等。2.2.2 MetaStore
Metastore即元数据服务。Metastore服务的作用是管理metadata元数据,对外暴露服务地址,让各种客户端通过连接metastore服务,由metastore再去连接MySQL数据库来存取元数据。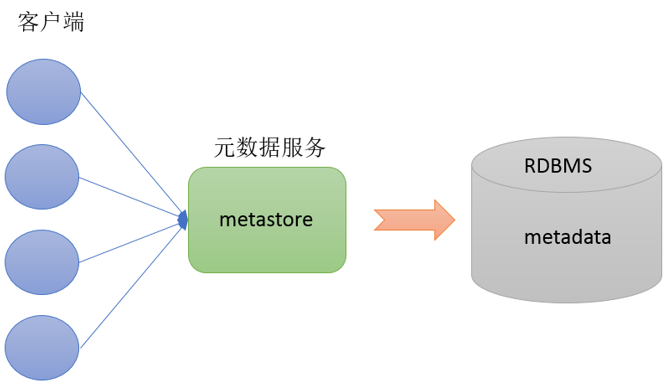
2.2.3 MetaStore三种配置方式
metastore服务配置有3种模式:内嵌模式、本地模式、远程模式。
2.2.3.1 内嵌模式
内嵌模式(Embedded Metastore)是metastore默认部署模式。此种模式下,元数据存储在内置的Derby数据库,并且Derby数据库和metastore服务都嵌入在主HiveServer进程中,当启动HiveServer进程时,Derby和metastore都会启动。不需要额外起Metastore服务。
但是一次只能支持一个活动用户,适用于测试体验,不适用于生产环境。2.2.3.2 本地模式
本地模式(Local Metastore)下,Hive Metastore服务与主HiveServer进程在同一进程中运行,但是存储元数据的数据库在单独的进程中运行,并且可以在单独的主机上。metastore服务将通过JDBC与metastore数据库进行通信。
本地模式采用外部数据库来存储元数据,推荐使用MySQL。hive根据hive.metastore.uris参数值来判断,如果为空,则为本地模式。
缺点是:每启动一次hive服务,都内置启动了一个metastore。2.2.3.3 远程模式
远程模式(Remote Metastore)下,Metastore服务在其自己的单独JVM上运行,而不在HiveServer的JVM中运行。如果其他进程希望与Metastore服务器通信,则可以使用Thrift Network API进行通信。
在生产环境中,建议用远程模式来配置Hive Metastore。在这种情况下,其他依赖hive的软件都可以通过Metastore访问hive。由于还可以完全屏蔽数据库层,因此这也带来了更好的可管理性/安全性。
远程模式下,需要配置hive.metastore.uris参数来指定metastore服务运行的机器ip和端口,并且需要单独手动启动metastore服务。3. Hive安装部署
Hive是一款基于Hadoop的数仓软件,在安装hive前,需要先安装Hadoop;如果元数据要存储在外部数据库MySQL中,还需要安装好MySQL。3.1 内嵌模式安装
```shell上传解压安装包
cd /export/server/ tar zxvf apache-hive-3.1.2-bin.tar.gz mv apache-hive-3.1.2-bin hive
解决hadoop、hive之间guava版本差异
cd /export/server/hive rm -rf lib/guava-19.0.jar cp /export/server/hadoop-3.1.4/share/hadoop/common/lib/guava-27.0-jre.jar ./lib/
修改hive环境变量文件 添加Hadoop_HOME
cd /export/server/hive/conf/ mv hive-env.sh.template hive-env.sh vim hive-env.sh export HADOOP_HOME=/export/server/hadoop-3.1.4 export HIVE_CONF_DIR=/export/server/hive/conf export HIVE_AUX_JARS_PATH=/export/server/hive/lib
初始化metadata
cd /export/server/hive bin/schematool -dbType derby -initSchema
启动hive服务
bin/hive
**注意**:Hive3版本需要用户手动进行元数据初始化动作。内嵌模式下,判断是否初始化成功的依据是执行命令之后输出信息和执行命令的当前路径下是否有文件产生。<a name="ZlVJW"></a>### 3.2 本地模式安装本地模式和内嵌模式最大的区别就是:本地模式使用mysql来存储元数据。<br />**MySQL安装**:```shell#卸载Centos7自带mariadbrpm -qa|grep mariadbmariadb-libs-5.5.64-1.el7.x86_64rpm -e mariadb-libs-5.5.64-1.el7.x86_64 --nodeps#创建mysql安装包存放点mkdir /export/software/mysql#上传mysql-5.7.29安装包到上述文件夹下、解压tar xvf mysql-5.7.29-1.el7.x86_64.rpm-bundle.tar#执行安装yum -y install libaiorpm -ivh mysql-community-common-5.7.29-1.el7.x86_64.rpm mysql-community-libs-5.7.29-1.el7.x86_64.rpm mysql-community-client-5.7.29-1.el7.x86_64.rpm mysql-community-server-5.7.29-1.el7.x86_64.rpm#初始化mysqlmysqld --initialize#更改所属组chown mysql:mysql /var/lib/mysql -R#启动mysqlsystemctl start mysqld.service#查看生成的临时root密码cat /var/log/mysqld.log#这行日志的最后就是随机生成的临时密码[Note] A temporary password is generated for root@localhost: o+TU+KDOm004#修改mysql root密码、授权远程访问mysql -u root -pEnter password: #这里输入在日志中生成的临时密码#更新root密码 设置为hadoopmysql> alter user user() identified by "hadoop";Query OK, 0 rows affected (0.00 sec)#授权mysql> use mysql;mysql> GRANT ALL PRIVILEGES ON *.* TO 'root'@'%' IDENTIFIED BY 'hadoop' WITH GRANT OPTION;mysql> FLUSH PRIVILEGES;#mysql的启动和关闭 状态查看systemctl stop mysqldsystemctl status mysqldsystemctl start mysqld#建议设置为开机自启动服务systemctl enable mysqld#查看是否已经设置自启动成功systemctl list-unit-files | grep mysqld
Hive安装:
# 上传解压安装包cd /export/server/tar zxvf apache-hive-3.1.2-bin.tar.gzmv apache-hive-3.1.2-bin hive#解决hadoop、hive之间guava版本差异cd /export/server/hiverm -rf lib/guava-19.0.jarcp /export/server/hadoop-3.1.4/share/hadoop/common/lib/guava-27.0-jre.jar ./lib/#添加mysql jdbc驱动到hive安装包lib/文件下mysql-connector-java-5.1.32.jar#修改hive环境变量文件 添加Hadoop_HOMEcd /export/server/hive/conf/mv hive-env.sh.template hive-env.shvim hive-env.shexport HADOOP_HOME=/export/server/hadoop-3.1.4export HIVE_CONF_DIR=/export/server/hive/confexport HIVE_AUX_JARS_PATH=/export/server/hive/lib#新增hive-site.xml 配置mysql等相关信息vim hive-site.xml#初始化metadatacd /export/server/hivebin/schematool -initSchema -dbType mysql -verbos#初始化成功会在mysql中创建74张表#启动hive服务bin/hive
hive-site.xml配置:
<configuration><!-- 存储元数据mysql相关配置 --><property><name>javax.jdo.option.ConnectionURL</name><value> jdbc:mysql://node1:3306/hive?createDatabaseIfNotExist=true&useSSL=false&useUnicode=true&characterEncoding=UTF-8</value></property><property><name>javax.jdo.option.ConnectionDriverName</name><value>com.mysql.jdbc.Driver</value></property><property><name>javax.jdo.option.ConnectionUserName</name><value>root</value></property><property><name>javax.jdo.option.ConnectionPassword</name><value>hadoop</value></property><!-- 关闭元数据存储授权 --><property><name>hive.metastore.event.db.notification.api.auth</name><value>false</value></property><!-- 关闭元数据存储版本的验证 --><property><name>hive.metastore.schema.verification</name><value>false</value></property></configuration>
3.3 远程模式安装
MySQL安装同上。
Hive安装同上。
hive-site.xml配置:
<configuration>
<!-- 存储元数据mysql相关配置 -->
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value> jdbc:mysql://node1:3306/hive?createDatabaseIfNotExist=true&useSSL=false&useUnicode=true&characterEncoding=UTF-8</value>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>hadoop</value>
</property>
<!-- H2S运行绑定host -->
<property>
<name>hive.server2.thrift.bind.host</name>
<value>node1</value>
</property>
<!-- 远程模式部署metastore 服务地址 -->
<property>
<name>hive.metastore.uris</name>
<value>thrift://node1:9083</value>
</property>
<!-- 关闭元数据存储授权 -->
<property>
<name>hive.metastore.event.db.notification.api.auth</name>
<value>false</value>
</property>
<!-- 关闭元数据存储版本的验证 -->
<property>
<name>hive.metastore.schema.verification</name>
<value>false</value>
</property>
</configuration>
远程模式Metastore服务手动启动:
#前台启动 关闭ctrl+c
/export/server/hive/bin/hive --service metastore
#后台启动 进程挂起 关闭使用jps + kill
#输入命令回车执行 再次回车 进程将挂起后台
nohup /export/server/hive/bin/hive --service metastore &
#前台启动开启debug日志
/export/server/hive/bin/hive --service metastore --hiveconf hive.root.logger=DEBUG,console
**注意**:在远程模式下,必须首先启动Hive metastore服务才可以使用hive。因为metastore服务和hive server是两个单独的进程。
4. Hive客户端使用
Hive发展至今,总共历经了两代客户端工具。
- 第一代客户端(deprecated不推荐使用):$HIVE_HOME/bin/hive, 是一个 shellUtil。主要功能:一是可用于以交互或批处理模式运行Hive查询;二是用于Hive相关服务的启动,比如metastore服务。
- 第二代客户端(recommended 推荐使用):$HIVE_HOME/bin/beeline,是一个JDBC客户端,是官方强烈推荐使用的Hive命令行工具,和第一代客户端相比,性能加强安全性提高。
Beeline Shell在嵌入式模式和远程模式下均可工作。在嵌入式模式下,它运行嵌入式 Hive(类似于Hive Client),而远程模式下beeline通过 Thrift 连接到单独的 HiveServer2 服务上,这也是官方推荐在生产环境中使用的模式。
那么问题来了,
- HiveServer2是什么?HiveServer1哪里去了?
HiveServer、HiveServer2都是Hive自带的两种服务,允许客户端在不启动CLI的情况下对Hive中的数据进行操作,且两个都允许远程客户端使用多种编程语言如java,python等向hive提交请求,取回结果。
但是,HiveServer不能处理多于一个客户端的并发请求。因此在Hive-0.11.0版本中重写了HiveServer代码得到了HiveServer2,进而解决了该问题。HiveServer已经被废弃。
HiveServer2支持多客户端的并发和身份认证,旨在为开放API客户端如JDBC、ODBC提供更好的支持。
4.1 Hive服务和客户端的关系
HiveServer2通过Metastore服务读写元数据。所以在远程模式下,启动HiveServer2之前必须先首先启动metastore服务。
特别注意:远程模式下,Beeline客户端只能通过HiveServer2服务访问Hive。而Hive Client是通过Metastore服务访问的。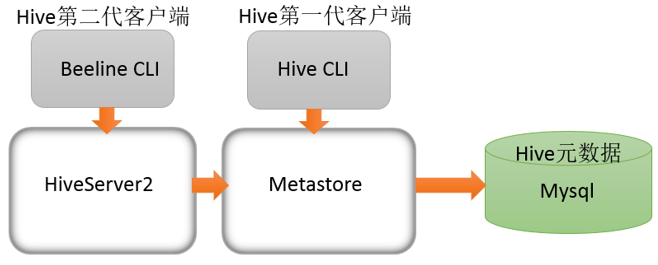
4.2 Beeline客户端
官方推荐使用Beeline客户端。示例:
% bin/beeline
Hive version 0.11.0-SNAPSHOT by Apache
beeline> !connect jdbc:hive2://localhost:10000 scott tiger
!connect jdbc:hive2://localhost:10000 scott tiger
Connecting to jdbc:hive2://localhost:10000
Connected to: Hive (version 0.10.0)
Driver: Hive (version 0.10.0-SNAPSHOT)
Transaction isolation: TRANSACTION_REPEATABLE_READ
0: jdbc:hive2://localhost:10000> show tables;
show tables;
+-------------------+
| tab_name |
+-------------------+
| primitives |
| src |
| src1 |
| src_json |
| src_sequencefile |
| src_thrift |
| srcbucket |
| srcbucket2 |
| srcpart |
+-------------------+
9 rows selected (1.079 seconds)
也可以在命令行上指定参数:
% beeline -u jdbc:hive2://localhost:10000/default -n scott -w password_file
Hive version 0.11.0-SNAPSHOT by Apache
Connecting to jdbc:hive2://localhost:10000/default
**官网详细使用:**

若有收获,就点个赞吧
0 人点赞
