下述安装操作是在Windows 11的Ubuntu Linux子系统上进行。
Ubuntu版本:18.04
1. Java安装
1.1 Java下载
官方下载太慢,在华为镜像上下载,地址:https://repo.huaweicloud.com/java/jdk/
根据自己系统选择合适的包下载即可,本次安装使用:jdk-8u191-linux-x64.tar.gz
1.2 安装
# 将安装包上传至服务器上,并解压> tar -zxvf jdk-8u191-linux-x64.tar.gz# 添加环境变量> vim /etc/profile# 添加如下内容export JAVA_HOME=/home/soft/jdk1.8.0_191export PATH=$JAVA_HOME/bin:$PATHexport CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar# 让配置立即生效> source /etc/profile# 验证是否安装成功> java -versionjava version "1.8.0_191"Java(TM) SE Runtime Environment (build 1.8.0_191-b12)Java HotSpot(TM) 64-Bit Server VM (build 25.191-b12, mixed mode)
2. Hadoop安装
2.1 下载
国内下载镜像地址:https://mirrors.cnnic.cn/apache/
下载hadoop-3.2.3.tar.gz安装包。
2.2 安装
配置hadoop环境变量
vim /etc/profile
添加如下内容
export HADOOP_HOME=/home/soft/hadoop-3.2.2 PATH=$PATH:$HOME/bin:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
使配置生效
source /etc/profile ```
配置hadoop依赖的java,修改hadoop-env.sh,添加如下内容,保存并退出
export JAVA_HOME=/home/soft/jdk1.8.0_191
修改core-site.xml配置文件
> cd /home/soft/hadoop-3.2.2/etc/hadoop> vim core-site.xml
在
标签下添加如下内容,保存并退出: <!-- NameNode的地址 --><property><name>fs.defaultFS</name><value>hdfs://localhost:9000</value></property><!-- 指定hadoop运行时产生临时文件的存储目录 --><property><name>hadoop.tmp.dir</name><value>/home/hadoop/tmp</value></property><!-- 表示设置 hadoop 的代理用户--><property><!--表示代理用户的组所属--><name>hadoop.proxyuser.root.groups</name><value>*</value></property><property><!--表示任意节点使用 hadoop 集群的代理用户 hadoop 都能访问 hdfs 集群--><name>hadoop.proxyuser.root.hosts</name><value>*</value></property>
修改hdfs-site.xml文件
> vim hdfs-site.xml
添加如下内容,保存并退出:
<property><name>dfs.replication</name><value>1</value><description>数据块的备份数量,不能大于DataNode的数量</description></property><property><name>dfs.namenode.name.dir</name><value>/home/hadoop/namenode</value><description>NameNode 需要存储数据的文件目录</description></property><property><name>dfs.datanode.data.dir</name><value>/home/hadoop/datanode</value><description>DataNode 需要存放数据的文件目录</description></property>
修改yarn-site.xml配置文件
> vim yarn-site.xml
添加如下内容,保存并退出:
<!-- ResourceManager的地址 --><property><name>yarn.resourcemanager.hostname</name><value>localhost</value></property><!-- reducer获取数据的方式 --><property><name>yarn.nodemanager.aux-services</name><value>mapreduce_shuffle</value></property>
修改mapred-site.xml配置文件
> vim mapred-site.xml
添加如下内容,保存并退出:
<!-- 指定mr运行在yarn上 --><property><name>mapreduce.framework.name</name><value>yarn</value></property>
修改start-dfs.sh和stop-dfs.sh配置
> cd /home/soft/hadoop-3.2.2/sbin> vim start-dfs.sh> vim stop-dfs.sh
在最上边添加如下内容,保存并退出:
HDFS_DATANODE_USER=rootHADOOP_SECURE_DN_USER=hdfsHDFS_NAMENODE_USER=rootHDFS_SECONDARYNAMENODE_USER=root
修改start-yarn.sh和stop-yarn.sh配置
> vim start-yarn.sh> vim stop-yarn.sh
在最上边添加如下内容,保存并退出:
YARN_RESOURCEMANAGER_USER=rootHADOOP_SECURE_DN_USER=yarnYARN_NODEMANAGER_USER=root
2.3 启动验证
第一次启动需要先格式化集群,执行如下命令:
## 格式化 HDFS 集群的 namenodehdfs namenode -format
启动hadoop
> cd /home/soft/hadoop-3.2.2/sbin> ./start-all.sh
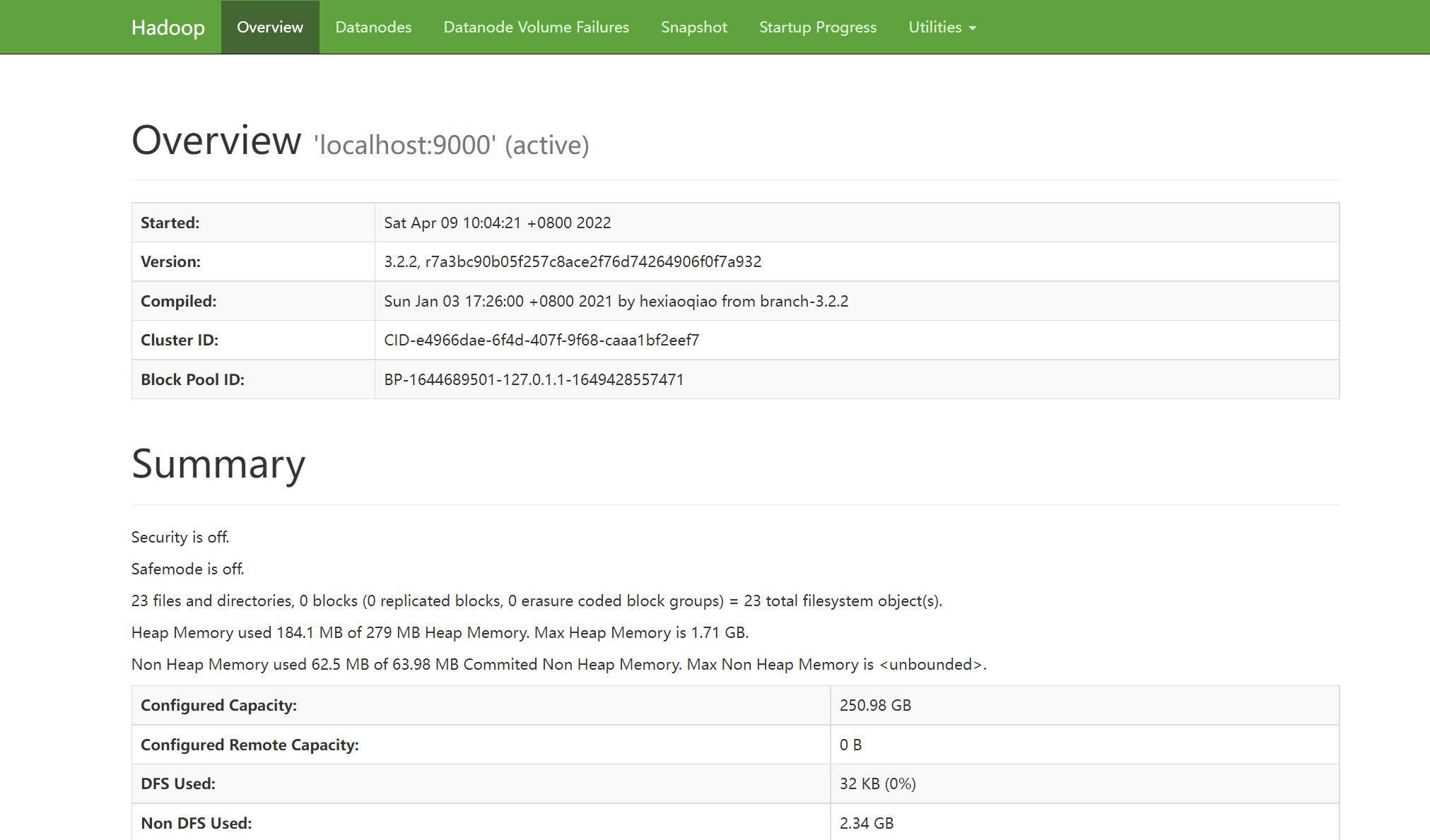
访问hadoop集群的web地址:http://localhost:9870(Hadoop3中HDFS的默认端口改为9870,Hadoop2的默认端口为50070)
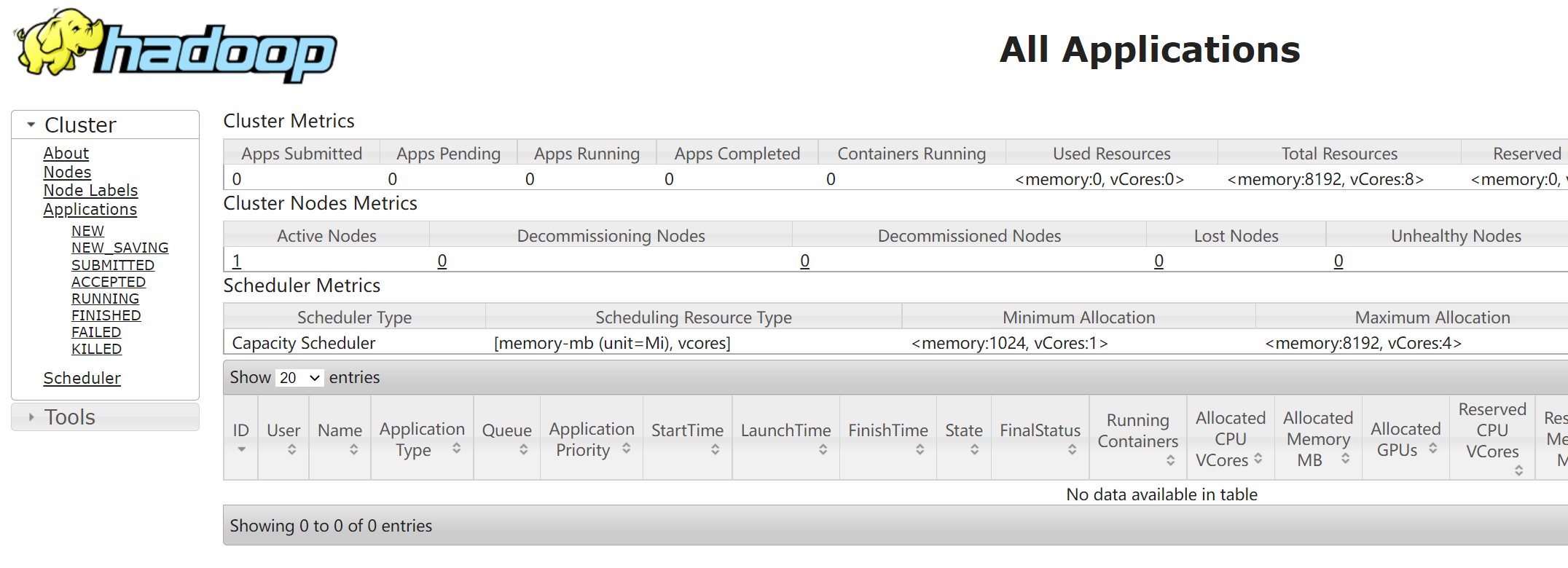
- 访问Yarn的web地址:http://localhost:8088/cluster
2.4 问题解决
2.4.1 SSH问题
在启动hadoop时,可能出现此问题:
| localhost: ssh: connect to host localhost port 22: Connection refused localhost: ssh: connect to host localhost port 22: Connection refused … |
|---|
验证是否存在ssh服务
ps -ef | grep ssh
大概率不存在。。。
安装ssh
下载地址:https://launchpad.net/ubuntu/+source/openssh/1:7.2p2-4/+build/9584683
下载client和server:openssh-client_7.2p2-4_amd64.deb和openssh-sftp-server_7.2p2-4_amd64.deb
# 上传到服务器,安装> dpkg -i openssh-client_7.2p2-4_amd64.deb> dpkg -i openssh-sftp-server_7.2p2-4_amd64.deb# 启动> /etc/init.d/ssh start# 测试是否成功> ssh localhost# 设置免密登录> cd ~> cd .ssh/> ssh -keygen -t rsa> cat ./id_rsa.pub >> ./authorized_keys> chmod 0600 ./authorized_keys
至此,此问题完美解决!
3. Hive安装
本地模式安装hive,需要依赖hadoop和mysql。hadoop安装步骤如上,mysql安装了windows版本,傻瓜操作,步骤略。
3.1 下载
国内下载镜像地址:https://mirrors.cnnic.cn/apache/
下载apache-hive-3.1.2-bin.tar.gz安装包。
3.2 安装
# 上传解压安装包> cd /home/soft> tar -zxvf apache-hive-3.1.2-bin.tar.gz> mv apache-hive-3.1.2-bin hive-3.1.2# 解决hadoop、hive之间guava版本差异> cd /home/soft/hive-3.1.2> rm -f ./lib/guava-19.0.jar> cp /home/soft/hadoop-3.2.2/share/hadoop/common/lib/guava-27.0-jre.jar ./lib/# 添加mysql jdbc驱动到hive安装包lib/文件下mysql-connector-java-5.1.47.jar# 配置hive环境变量> vim /etc/profile# 添加如下内容export HIVE_HOME=/home/soft/hive-3.1.2export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$HIVE_HOME/bin# 修改hive环境变量 添加Hadoop_HOME> cd /home/soft/hive-3.1.2/conf/> vim hive-env.sh# 添加如下内容HADOOP_HOME=/home/soft/hadoop-3.2.2export HIVE_CONF_DIR=/home/soft/hive-3.1.2/confexport HIVE_AUX_JARS_PATH=/home/soft/hive-3.1.2/lib# 新增hive-site.xml 配置mysql等相关信息> vim hive-site.xml# 内容如下# 初始化metadata> cd /home/soft/hive-3.1.2> ./bin/schematool -dbType mysql -initSchema# 初始化成功会在mysql中创建74张表
hive客户端使用
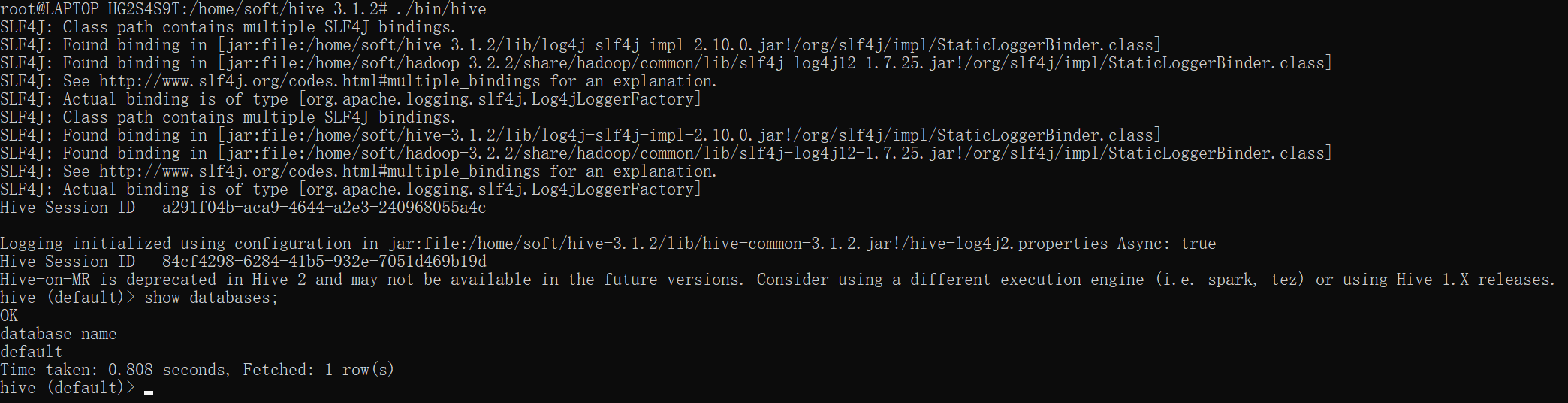
# 启动hive服务> cd /home/soft/hive-3.1.2> bin/hive
启动成功:
beeline客户端使用(推荐) ```shell
启动hiveserver2服务
cd /home/soft/hive-3.1.2 nohup ./bin/hiveserver2 & >/dev/null 2>&1
启动beeline
./bin/beeline -u jdbc:hive2://localhost:10000 -n root
10000为hiveserver默认端口
启动成功:<br />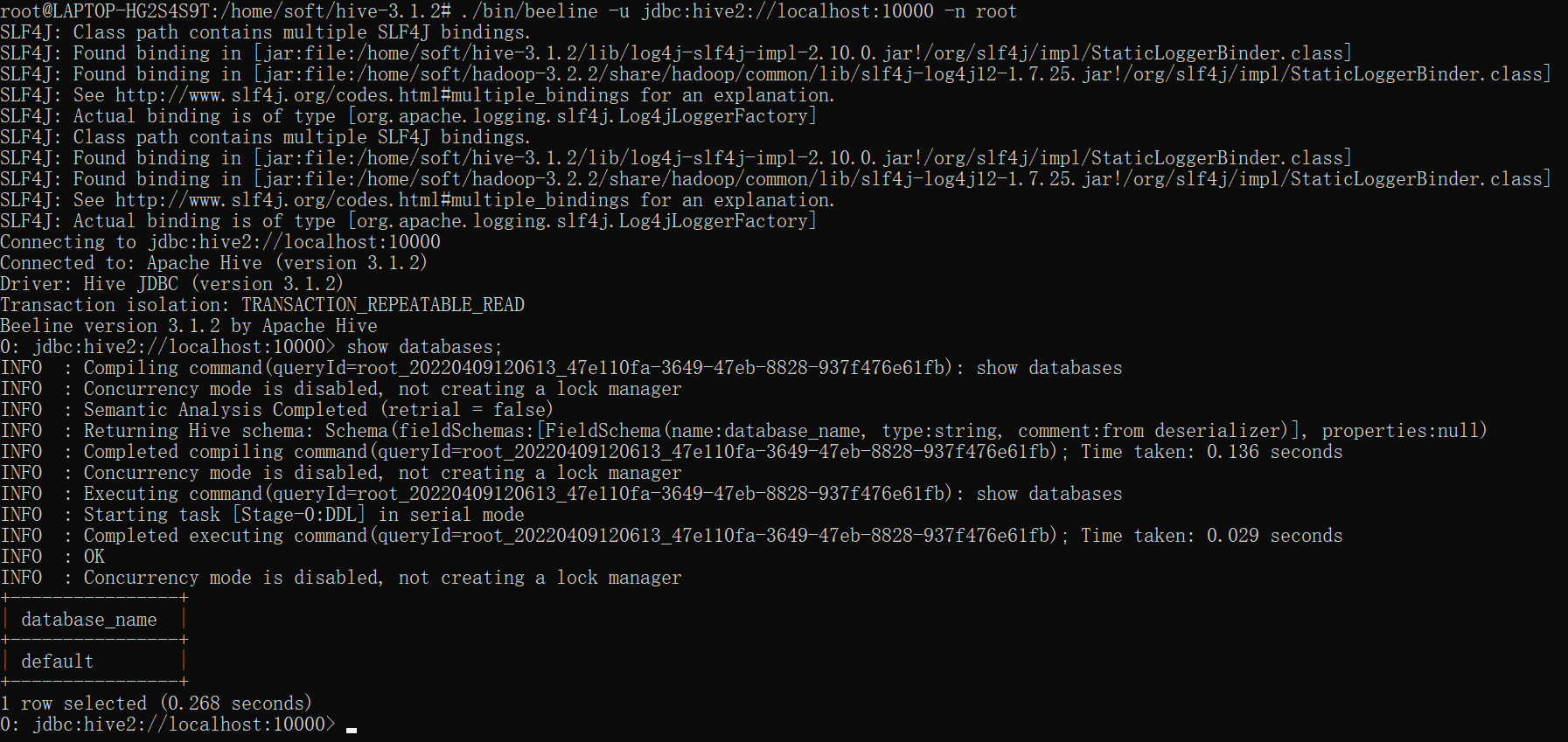<br />**hive-site.xml内容**:```xml<?xml version="1.0" encoding="UTF-8" standalone="no"?><?xml-stylesheet type="text/xsl" href="configuration.xsl"?><configuration><!-- mysql地址 --><property><name>javax.jdo.option.ConnectionURL</name><value>jdbc:mysql://xxx.xxx.xxx.xxx:3306/hive?createDatabaseIfNotExist=true&useUnicode=true&characterEncoding=UTF-8&useSSL=false</value></property><!-- 驱动 --><property><name>javax.jdo.option.ConnectionDriverName</name><value>com.mysql.jdbc.Driver</value></property><!-- 账号 --><property><name>javax.jdo.option.ConnectionUserName</name><value>root</value></property><!-- 密码 --><property><name>javax.jdo.option.ConnectionPassword</name><value>root</value></property><property><name>datanucleus.readOnlyDatastore</name><value>false</value></property><property><name>datanucleus.fixedDatastore</name><value>false</value></property><property><name>datanucleus.autoCreateSchema</name><value>true</value></property><property><name>datanucleus.schema.autoCreateAll</name><value>true</value></property><property><name>datanucleus.autoCreateTables</name><value>true</value></property><property><name>datanucleus.autoCreateColumns</name><value>true</value></property><property><name>hive.metastore.local</name><value>true</value></property><!-- 显示表的列名 --><property><name>hive.cli.print.header</name><value>true</value></property><!-- 显示数据库名称 --><property><name>hive.cli.print.current.db</name><value>true</value></property></configuration>3.3 问题解决
3.3.1 Windows的3306端口不通
需要开放windows3306端口,步骤如下:
- 打开【高级安全Windows Defender防火墙】配置
- 新建入站规则
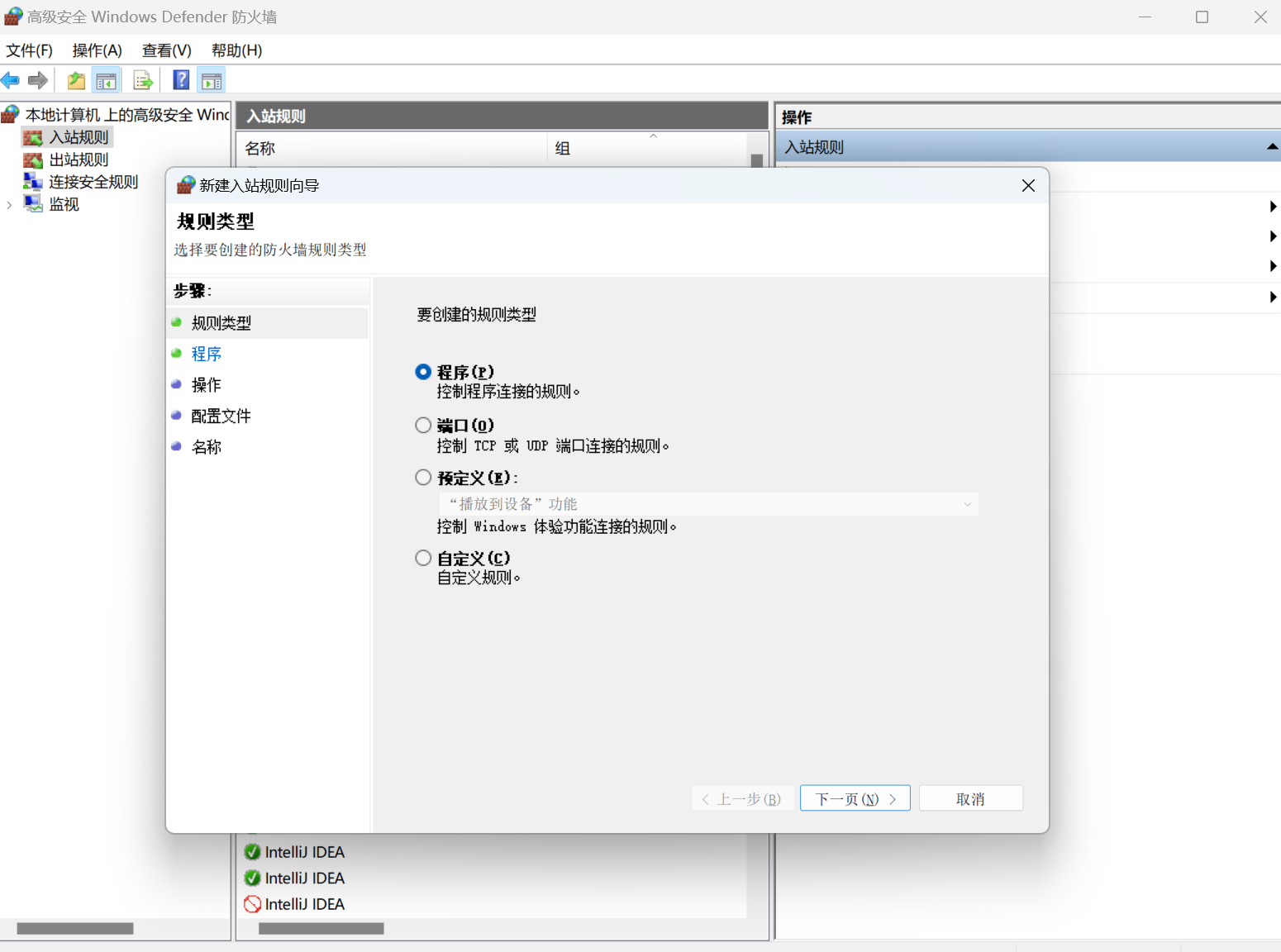
- 选择端口,点击下一步,选择TCP、特定本地端口:3306,点击下一步
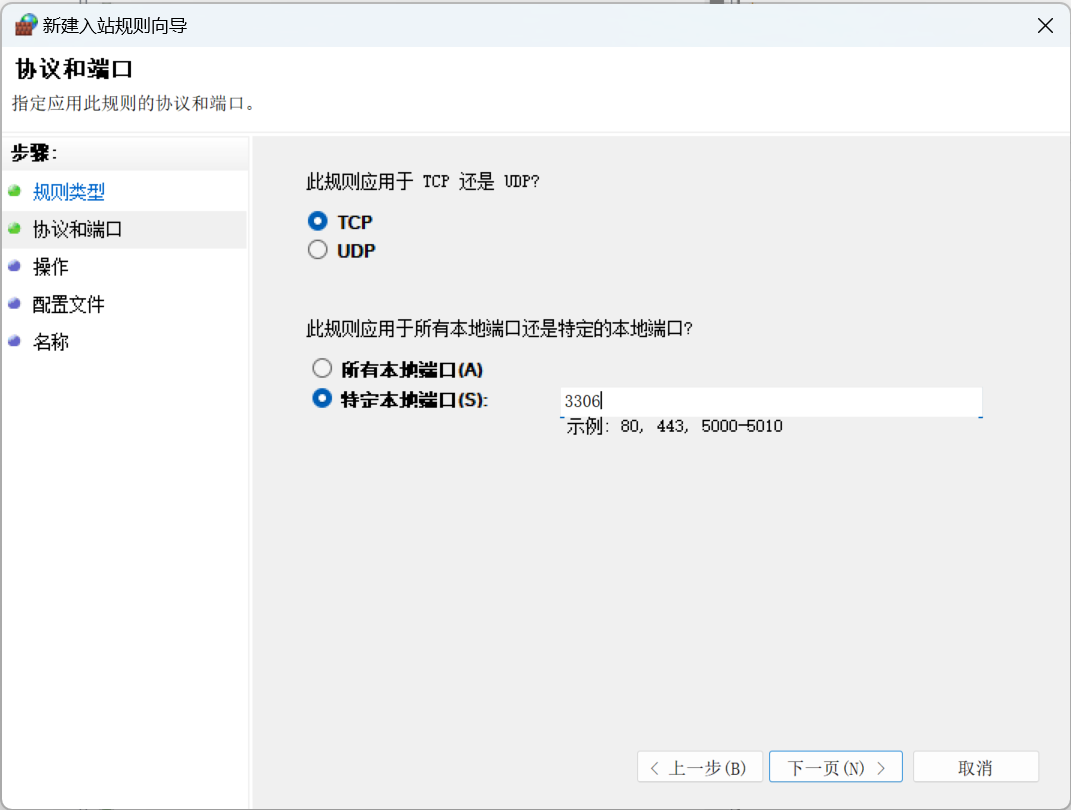
- 选择允许连接,然后一直点击下一步到结束,至此3306端口就开放了。
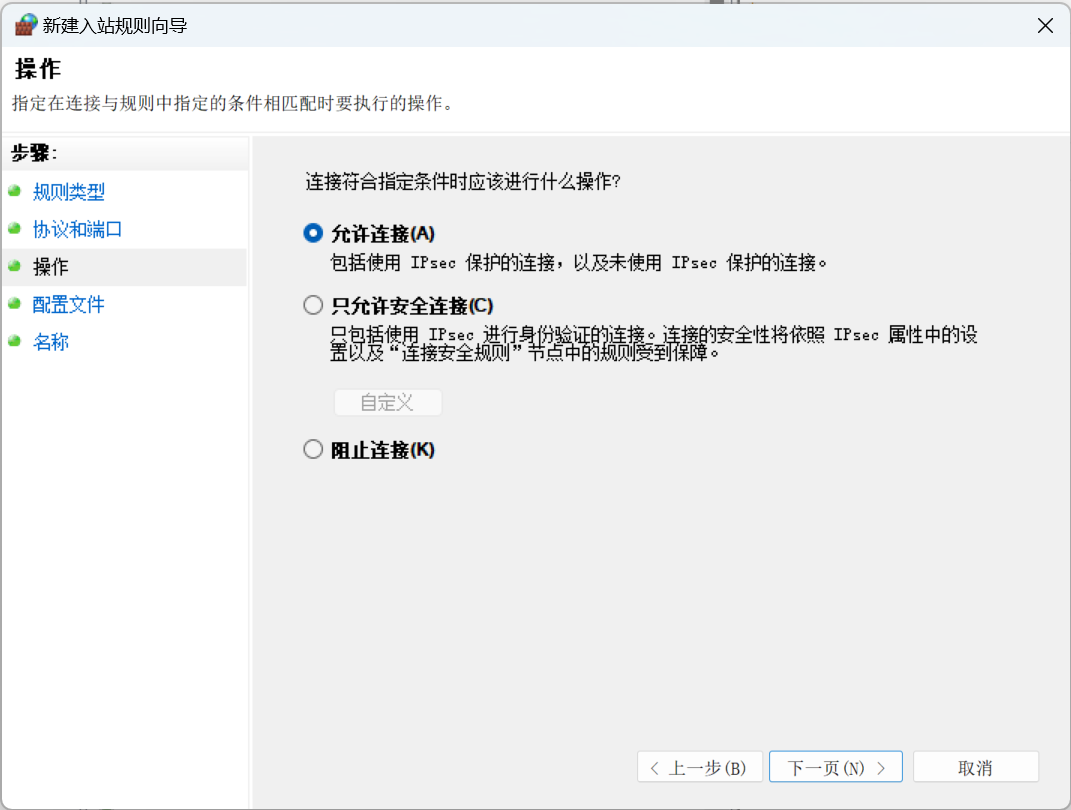
3.3.2 metastore数据库初始化失败
初始化metastore时,报错连不上数据库。
排查发现:Windows可以ping通Linux的ip,但是反过来ping不通,应该是出于安全考虑吧,win11默认在防火墙里禁用了。解决步骤:
- 同上打开防火墙配置,并新建入站规则
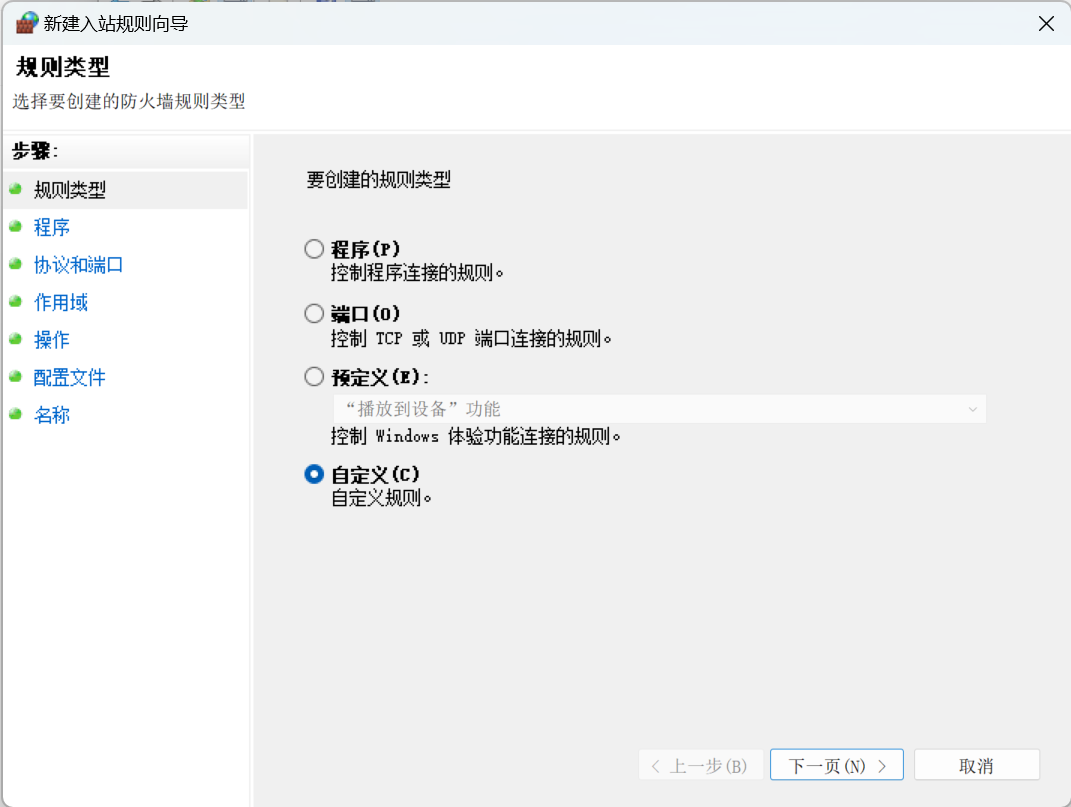
- 选择自定义,点击下一页,协议和端口配置:协议类型ICMPv4

- 点击下一页到结束即可。
3.3.3 beeline连接权限问题
连接报错:User: root is not allowed to impersonate root。
此问题需修改hadoop配置,修改core-site.xml文件,添加如下内容即可解决。<!-- 表示设置 hadoop 的代理用户--><property><!--表示代理用户的组所属--><name>hadoop.proxyuser.root.groups</name><value>*</value></property><property><!--表示任意节点使用 hadoop 集群的代理用户 hadoop 都能访问 hdfs 集群--><name>hadoop.proxyuser.root.hosts</name><value>*</value></property>
3.3.4 insert into执行慢
修改yarn-site.xml配置,添加如下内容: ```xmlyarn.scheduler.minimum-allocation-mb 2048 default value is 1024

若有收获,就点个赞吧
0 人点赞
