1. 多字节分隔符
1.1 应用场景
1.1.1 Hive中的分隔符
Hive中默认使用单字节分隔符来加载文本数据,例如逗号、制表符、空格等等,默认的分隔符为\001。根据不同文件的不同分隔符,我们可以通过在创建表时使用 row format delimited fields terminated by ‘单字节分隔符’ 来指定文件中的分割符,确保正确将表中的每一列与文件中的每一列实现一一对应的关系。
1.1.2 特殊数据
在实际工作中,我们遇到的数据往往不是非常规范化的数据,例如我们会遇到以下的两种情况
- 情况一:每一行数据的分隔符是多字节分隔符,例如:”||”、“—”等;
- 情况二:数据的字段中包含了分隔符(会导致字段错位)。
Hive分隔符限制:
-
1.2 问题与需求
基于上面两种情况的测试发现,当数据中出现了多字节分隔符或者数据中的某个字段包含了分隔符,就会导致数据加载错位的问题。
1.3 解决方案一:替换分隔符
面对情况一,如果数据中的分隔符是多字节分隔符,可以使用程序提前将数据中的多字节分隔符替换为单字节分隔符,然后使用Hive加载。
1.4 解决方案二:RegexSerDe正则加载
面对情况一和情况二的问题,Hive中提供了一种特殊的方式来解决,Hive提供了一种特殊的Serde来加载特殊数据的问题,使用正则匹配来加载数据,匹配每一列的数据。
1.4.1 什么是SerDe?
Hive的SerDe提供了序列化和反序列化两个功能,SerDe是英文Serialize和Deserilize的组合缩写,用于实现将Hive中的对象进行序列化和将数据进行反序列化。
Serialize就是序列化,用于将Hive中使用的java object转换成能写入hdfs的字节序列,或者其他系统能识别的流文件。Hive中的insert语句用于将数据写入HDFS,所以就会调用序列化实现。Hive中的调用过程如下:
Deserilize就是反序列化,用于将字符串或者二进制数据流转换成Hive能识别的java object对象。所有Hive中的Select语句在查询数据时,需要将HDFS中的数据解析为Hive中对象,就需要进行反序列化。Hive中的调用过程如下:
1.4.2 Hive中包含的SerDe

Hive中默认提供了多种SerDe用于解析和加载不同类型的数据文件,常用的有ORCSerde 、RegexSerde、JsonSerDe等。1.4.3 RegexSerDe的功能
RegexSerde是Hive中专门为了满足复杂数据场景所提供的正则加载和解析数据的接口,使用RegexSerde可以指定正则表达式加载数据,根据正则表达式匹配每一列数据。上述过程中遇到的情况一和情况二的问题,都可以通过RegexSerDe使用正则表达式来加载实现。
1.4.4 RegexSerDe解决多字节分隔符
原始数据格式 | 01||周杰伦||中国||台湾||男||七里香 | | —- |
正则表达式定义每一列 | ([0-9])\\|\\|(.)\\|\\|(.)\\|\\|(.)\\|\\|(.)\\|\\|(.) | | —- |
基于正则表达式,使用RegexSerde建表 ```sql —如果表已存在就删除表 drop table if exists singer; —创建表 create table singer( id string,—歌手id name string,—歌手名称 country string,—国家 province string,—省份 gender string,—性别 works string—作品 ) —指定使用RegexSerde加载数据 ROW FORMAT SERDE ‘org.apache.hadoop.hive.serde2.RegexSerDe’ —指定正则表达式 WITH SERDEPROPERTIES ( “input.regex” = “([0-9])\|\|([^}])\|\|([^}])\|\|([^}])\|\|([^}])\|\|([^}])” );
load data local inpath ‘/export/data/test01.txt’ into table singer;
<a name="eZksl"></a>#### 1.4.5 RegexSerDe解决数据中包含分割符- 原始数据格式| 192.168.88.100 [08/Nov/2020:10:44:33 +0800] "GET /hpsk_sdk/index.html HTTP/1.1" 200 328 || --- |- 正则表达式定义每一列| ([^ ]*) ([^}]*) ([^ ]*) ([^ ]*) ([^ ]*) ([0-9]*) ([^ ]*) || --- |- 基于正则表达式,使用RegexSerde建表```sql--如果表存在,就删除表drop table if exists apachelog;--创建表create table apachelog(ip string, --IP地址stime string, --时间mothed string, --请求方式url string, --请求地址policy string, --请求协议stat string, --请求状态body string --字节大小)--指定使用RegexSerde加载数据ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.RegexSerDe'--指定正则表达式WITH SERDEPROPERTIES ("input.regex" = "([^ ]*) ([^}]*) ([^ ]*) ([^ ]*) ([^ ]*) ([0-9]*) ([^ ]*)");load data local inpath '/export/data/apache_web_access.log' into table apachelog;
RegexSerde使用简单,对于各种复杂的数据场景,都可以通过正则定义匹配每行中的每个字段,基本上可以满足大多数场景的需求,工作中推荐使用该方式来实现对于复杂数据的加载。
1.5 解决方案三:自定义InputFormat
Hive中也允许使用自定义InputFormat来解决以上问题,通过在自定义InputFormat,来自定义解析逻辑实现读取每一行的数据。
1.5.1 自定义InputFormat
- 自定义InputFormat继承自TextInputFormat,读取数据时将每条数据中的”||”全部替换成“|” ```java import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapred.*;
import java.io.IOException;
/**
- @ClassName UserInputFormat
- @Description TODO 用于实现自定义InputFormat,读取每行数据
- @Create By nkong */
public class UserInputFormat extends TextInputFormat {
@Override
public RecordReader
```java
import org.apache.commons.logging.Log;
import org.apache.commons.logging.LogFactory;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FSDataInputStream;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.fs.Seekable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.io.compress.*;
import org.apache.hadoop.mapred.FileSplit;
import org.apache.hadoop.mapred.LineRecordReader;
import org.apache.hadoop.mapred.RecordReader;
import java.io.IOException;
import java.io.InputStream;
/**
* @ClassName UserRecordReader
* @Description TODO 用于自定义读取器,在自定义InputFormat中使用,将读取到的每行数据中的||替换为|
* @Create By nkong
*/
public class UserRecordReader implements RecordReader<LongWritable, Text> {
private static final Log LOG = LogFactory.getLog(LineRecordReader.class.getName());
int maxLineLength;
private CompressionCodecFactory compressionCodecs = null;
private long start;
private long pos;
private long end;
private LineReader in;
private Seekable filePosition;
private CompressionCodec codec;
private Decompressor decompressor;
public UserRecordReader(Configuration job, FileSplit split) throws IOException {
this.maxLineLength = job.getInt("mapred.linerecordreader.maxlength", Integer.MAX_VALUE);
start = split.getStart();
end = start + split.getLength();
final Path file = split.getPath();
compressionCodecs = new CompressionCodecFactory(job);
codec = compressionCodecs.getCodec(file);
FileSystem fs = file.getFileSystem(job);
FSDataInputStream fileIn = fs.open(split.getPath());
if (isCompressedInput()) {
decompressor = CodecPool.getDecompressor(codec);
if (codec instanceof SplittableCompressionCodec) {
final SplitCompressionInputStream cIn = ((SplittableCompressionCodec) codec)
.createInputStream(fileIn, decompressor, start, end,
SplittableCompressionCodec.READ_MODE.BYBLOCK);
in = new LineReader(cIn, job);
start = cIn.getAdjustedStart();
end = cIn.getAdjustedEnd();
filePosition = cIn; // take pos from compressed stream
} else {
in = new LineReader(codec.createInputStream(fileIn, decompressor), job);
filePosition = fileIn;
}
} else {
fileIn.seek(start);
in = new LineReader(fileIn, job);
filePosition = fileIn;
}
if (start != 0) {
start += in.readLine(new Text(), 0, maxBytesToConsume(start));
}
this.pos = start;
}
private boolean isCompressedInput() {
return (codec != null);
}
private int maxBytesToConsume(long pos) {
return isCompressedInput() ? Integer.MAX_VALUE : (int) Math.min(Integer.MAX_VALUE, end - pos);
}
private long getFilePosition() throws IOException {
long retVal;
if (isCompressedInput() && null != filePosition) {
retVal = filePosition.getPos();
} else {
retVal = pos;
}
return retVal;
}
public LongWritable createKey() {
return new LongWritable();
}
public Text createValue() {
return new Text();
}
/**
* Read a line.
*/
public synchronized boolean next(LongWritable key, Text value) throws IOException {
while (getFilePosition() <= end) {
key.set(pos);
int newSize = in.readLine(value, maxLineLength, Math.max(maxBytesToConsume(pos), maxLineLength));
String str = value.toString().replaceAll("\\|\\|", "\\|");
value.set(str);
pos += newSize;
if (newSize == 0) {
return false;
}
if (newSize < maxLineLength) {
return true;
}
LOG.info("Skipped line of size " + newSize + " at pos " + (pos - newSize));
}
return false;
}
public float getProgress() throws IOException {
if (start == end) {
return 0.0f;
} else {
return Math.min(1.0f, (getFilePosition() - start) / (float) (end - start));
}
}
public synchronized long getPos() throws IOException {
return pos;
}
public synchronized void close() throws IOException {
try {
if (in != null) {
in.close();
}
} finally {
if (decompressor != null) {
CodecPool.returnDecompressor(decompressor);
}
}
}
public static class LineReader extends org.apache.hadoop.util.LineReader {
LineReader(InputStream in) {
super(in);
}
LineReader(InputStream in, int bufferSize) {
super(in, bufferSize);
}
public LineReader(InputStream in, Configuration conf) throws IOException {
super(in, conf);
}
}
}
1.5.2 基于自定义Input创建表
- 将开发好的InputFormat打成jar包,放入Hive的lib目录中;
- 在Hive中,将jar包添加到环境变量中。 | add jar /export/server/hive-3.1.2-bin/lib/HiveUserInputFormat.jar; | | —- |
该方法可以实现临时添加,如果希望永久生效,重启Hive即可。
--如果表已存在就删除表
drop table if exists singer;
--创建表
create table singer(
id string,--歌手id
name string,--歌手名称
country string,--国家
province string,--省份
gender string,--性别
works string--作品
)
--指定使用分隔符为|
row format delimited fields terminated by '|'
stored as
--指定使用自定义的类实现解析
inputformat 'com.hive.mr.UserInputFormat'
outputformat 'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat';
-- 加载数据
load data local inpath '/export/data/test01.txt' into table singer;
2. URL解析函数
2.1 URL的基本组成
在对URL进行解析时,我们要先了解URL的基本组成部分,再根据实际的需求从URL中获取对应的部分,例如一条URL由以下几个部分组成: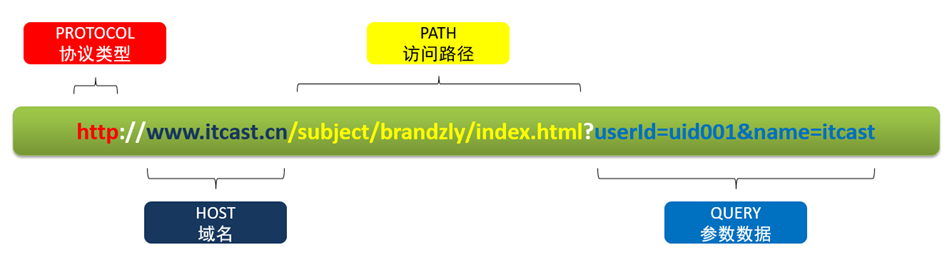
2.2 Hive中的URL解析函数
Hive中为了实现对URL的解析,专门提供了解析URL的函数parse_url和parse_url_tuple。
2.2.1 parse_url
parse_url函数是Hive中提供的最基本的url解析函数,可以根据指定的参数,从URL解析出对应的参数值进行返回,函数为普通的一对一函数类型。
- 语法
| parse_url(url, partToExtract[, key]) - extracts a part from a URL
Parts: HOST, PATH, QUERY, REF, PROTOCOL, AUTHORITY, FILE, USERINFO key | | —- |
parse_url在使用时需要指定两个参数
第一个参数:url:指定要解析的URL
第二个参数:key:指定要解析的内容
示例:
SELECT parse_url('http://facebook.com/path/p1.php?query=1', 'HOST') FROM src LIMIT 1;
-- 'facebook.com'
SELECT parse_url('http://facebook.com/path/p1.php?query=1', 'QUERY') FROM src LIMIT 1;
-- 'query=1'
SELECT parse_url('http://facebook.com/path/p1.php?query=1', 'QUERY', 'query') FROM src LIMIT 1;
-- '1'
2.2.2 parse_url_tuple
parse_url_tuple函数是Hive中提供的基于parse_url的url解析函数,可以通过一次指定多个参数,从URL解析出多个参数的值进行返回多列,函数为特殊的一对多函数类型,即通常所说的UDTF函数类型。
- 语法
| parse_url_tuple(url, partname1, partname2, …, partnameN) - extracts N (N>=1) parts from a URL.
It takes a URL and one or multiple partnames, and returns a tuple. All the input parameters and output column types are string.
Partname: HOST, PATH, QUERY, REF, PROTOCOL, AUTHORITY, FILE, USERINFO, QUERY:| | —- |
parse_url在使用时可以指定多个参数
第一个参数:url:指定要解析的URL
第二个参数:key1:指定要解析的内容1
……
第N个参数:keyN:指定要解析的内容N
示例:
SELECT b.* FROM src LATERAL VIEW parse_url_tuple(fullurl, 'HOST', 'PATH', 'QUERY', 'QUERY:id') b as host, path, query, query_id LIMIT 1;
SELECT parse_url_tuple(a.fullurl, 'HOST', 'PATH', 'QUERY', 'REF', 'PROTOCOL', 'FILE', 'AUTHORITY', 'USERINFO', 'QUERY:k1') as (ho, pa, qu, re, pr, fi, au, us, qk1) from src a;
3. 行列转换应用与实现
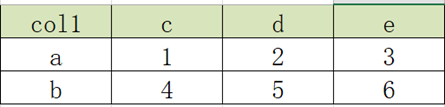
3.1 行转列:多行转多列
- 原始数据表
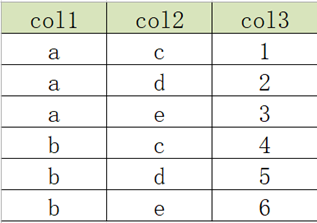
- 目标结果表
case when语法:
| CASE WHEN 条件1 THEN VALUE1 WHEN 条件2 THEN VALUE2 …… WHEN 条件N THEN VALUEN ELSE 默认值 END |
|---|
或
| CASE 列 WHEN V1 THEN VALUE1 WHEN V2 THEN VALUE2 …… WHEN VN THEN VALUEN ELSE 默认值 END |
|---|
实现:
select
col1 as col1,
max(case col2 when 'c' then col3 else 0 end) as c,
max(case col2 when 'd' then col3 else 0 end) as d,
max(case col2 when 'e' then col3 else 0 end) as e
from
row2col1
group by
col1;
3.2 行转列:多行转单列
- 原始数据表
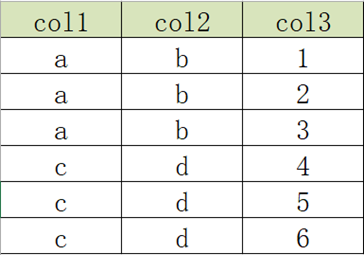
- 目标数据表
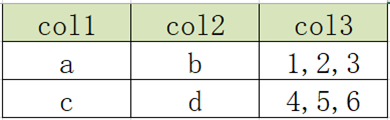
concat_ws语法:用于实现字符串拼接,可以指定分隔符
| concat_ws(SplitChar,element1,element2……) |
|---|
collect_list语法:用于将一列中的多行合并为一行,不进行去重
| collect_list(colName) |
|---|
select collect_list(col1) from row2col1;
+----------------------------+
| ["a","a","a","b","b","b"] |
+----------------------------+
concat_set语法:用于将一列中的多行合并为一行,并进行去重
| collect_set(colName) |
|---|
select collect_set(col1) from row2col1;
+------------+
| ["b","a"] |
+------------+
实现:
select
col1,
col2,
concat_ws(',', collect_list(cast(col3 as string))) as col3
from
row2col2
group by
col1, col2;
3.3 列转行:多列转多行
- 原始数据表
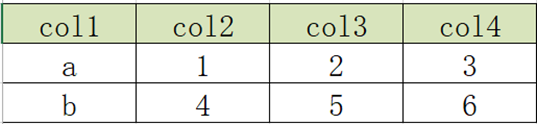
- 目标结果表
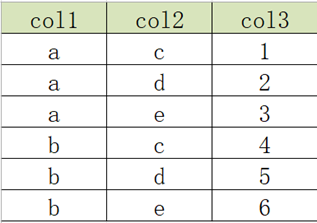
实现:
select col1, 'c' as col2, col2 as col3 from col2row1
UNION ALL
select col1, 'd' as col2, col3 as col3 from col2row1
UNION ALL
select col1, 'e' as col2, col4 as col3 from col2row1;
3.4 列转行:单列转多行
- 原始数据表
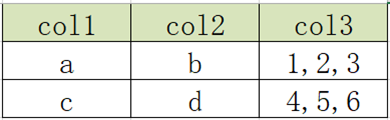
- 目标结果表
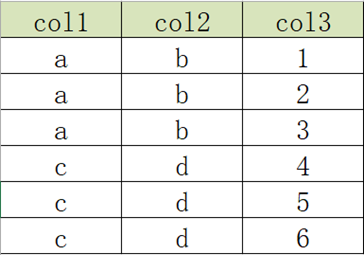
explode语法:用于将一个集合或者数组中的每个元素展开,将每个元素变成一行。
| explode( Map | Array) |
|---|
测试:
| select explode(split(“a,b,c,d”,”,”)); |
|---|
实现:
select
col1,
col2,
lv.col3 as col3
from
col2row2
lateral view
explode(split(col3, ',')) lv as col3;
3.5 列转行:单列转多行
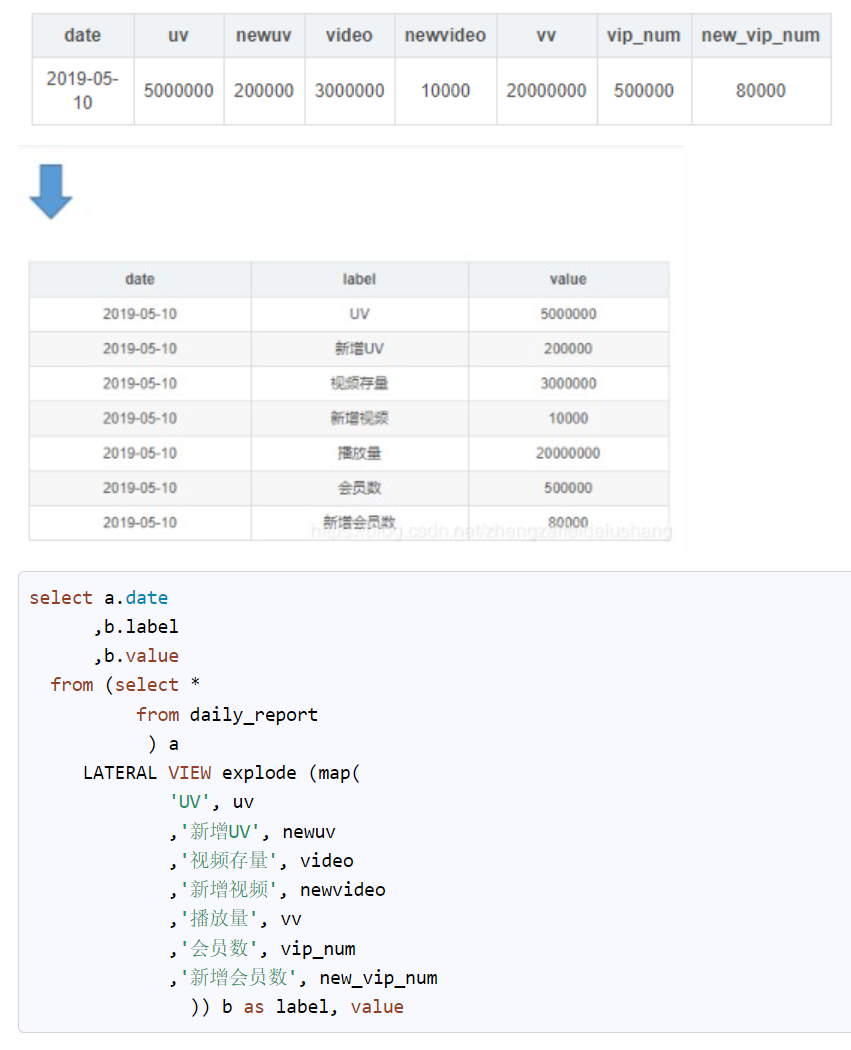
4. JSON数据处理
4.1 处理方式
- 方式一:使用JSON函数进行处理
Hive中提供了两个专门用于解析JSON字符串的函数:get_json_object、json_tuple,这两个函数都可以实现将JSON数据中的每个字段独立解析出来,构建成表。
- 方式二:使用Hive内置的JSON Serde加载数据
Hive中除了提供JSON的解析函数以外,还提供了一种专门用于加载JSON文件的Serde来实现对JSON文件中数据的解析,在创建表时指定Serde,加载文件到表中,会自动解析为对应的表格式。
4.2 JSON函数:get_json_object
用于解析JSON字符串,可以从JSON字符串中返回指定的某个对象列的值。
- 语法 | get_json_object(json_txt, path) - Extract a json object from path | | —- |
第一个参数:指定要解析的JSON字符串
第二个参数:指定要返回的字段,通过$.columnName的方式来指定path
- 特点:每次只能返回JSON对象中一列的值
使用:
select
json,
get_json_object(json,"$.device") as device
from tb_json_test1;
4.3 JSON函数:json_tuple
用于实现JSON字符串的解析,可以通过指定多个参数来解析JSON返回多列的值。
- 语法
| json_tuple(jsonStr, p1, p2, …, pn)
like get_json_object, but it takes multiple names and return a tuple | | —- |
第一个参数:指定要解析的JSON字符串
第二个参数:指定要返回的第1个字段
……
第N+1个参数:指定要返回的第N个字段
使用:
select
--解析所有字段
json_tuple(json,"device","deviceType","signal","time") as (device,deviceType,signal,stime)
from tb_json_test1;
-- 搭配侧视图
select
json,device,deviceType,signal,stime
from tb_json_test1
lateral view json_tuple(json,"device","deviceType","signal","time") b
as device,deviceType,signal,stime;
4.4 JSONSerde
上述解析JSON的过程中是将数据作为一个JSON字符串加载到表中,再通过JSON解析函数对JSON字符串进行解析,灵活性比较高,但是对于如果整个文件就是一个JSON文件,在使用起来就相对比较麻烦。
Hive中为了简化对于JSON文件的处理,内置了一种专门用于解析JSON文件的Serde解析器,在创建表时,只要指定使用JSONSerde解析表的文件,就会自动将JSON文件中的每一列进行解析。
使用:
--创建表
create table tb_json_test2 (
device string,
deviceType string,
signal double,
`time` string
)
ROW FORMAT SERDE 'org.apache.hive.hcatalog.data.JsonSerDe'
STORED AS TEXTFILE;
-- 加载数据
load data local inpath '/export/data/device.json' into table tb_json_test2;
5. 窗口函数应用实例
5.1 连续登陆用户
当前有一份用户登录数据如下图所示,数据中有两个字段,分别是userId和loginTime。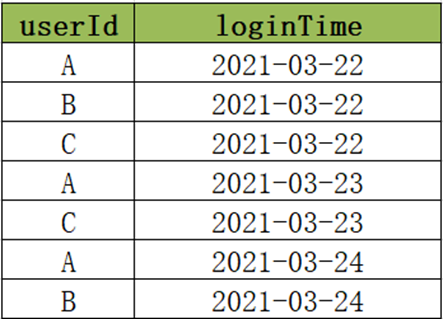
- 分析
基于以上的需求根据数据寻找规律,要想得到连续登陆用户,必须找到两个相同用户ID的行之间登陆日期之间的关系。有两种方案可以实现该需求:
方案一:实现表中的数据自连接,构建笛卡尔积,在结果中找到符合条件的id(不推荐);
方案二:使用窗口函数来实现。
5.1.1 方案一:自连接过滤实现(不推荐)
-- 构建笛卡尔积
create table tb_login_tmp as
select
a.userid as a_userid,
a.logintime as a_logintime,
b.userid as b_userid,
b.logintime as b_logintime
from tb_login a,tb_login b;
select
a_userid,a_logintime,b_userid,b_logintime
from tb_login_tmp
where a_userid = b_userid
and cast(substr(a_logintime,9,2) as int) - 1 = cast(substr(b_logintime,9,2) as int);
5.1.2 方案二:窗口函数实现(推荐)
- 窗口函数lead
功能:用于从当前数据中基于当前行的数据向后偏移取值
语法:lead(colName,N,defautValue)
- colName:取哪一列的值
- N:向后偏移N行
- defaultValue:如果取不到返回的默认值 ```sql — 连续登陆2天 with t1 as ( select userid, logintime, —本次登陆日期的第二天 date_add(logintime,1) as nextday, —按照用户id分区,按照登陆日期排序,取下一次登陆时间,取不到就为0 lead(logintime,1,0) over (partition by userid order by logintime) as nextlogin from tb_login ) select distinct userid from t1 where nextday = nextlogin;
— 连续登陆3天 with t1 as ( select userid, logintime, —本次登陆日期的第三天 date_add(logintime,2) as nextday, —按照用户id分区,按照登陆日期排序,取下下一次登陆时间,取不到就为0 lead(logintime,2,0) over (partition by userid order by logintime) as nextlogin from tb_login ) select distinct userid from t1 where nextday = nextlogin;
— 连续登陆n天 select userid, logintime, —本次登陆日期的第N天 date_add(logintime,N-1)as nextday, —按照用户id分区,按照登陆日期排序,取下下一次登陆时间,取不到就为0 lead(logintime,N-1,0)over (partition by userid order by logintime) as nextlogin from tb_login;
<a name="Gc4Zt"></a>
### 5.2 级联累加求和
当前有一份消费数据如下,记录了每个用户在每个月的所有消费记录,数据表中一共有三列:<br />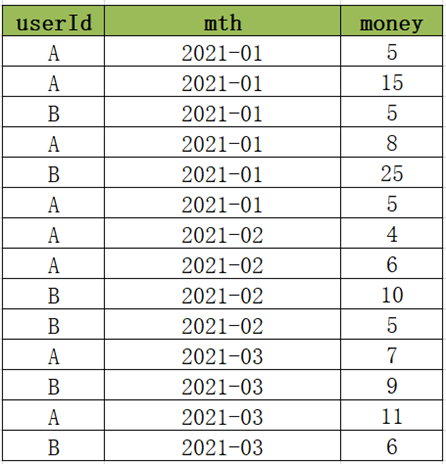<br />userId:用户唯一id,唯一标识一个用户,mth:用户消费的月份,一个用户可以在一个月多次消费,money:用户每次消费的金额。<br />现在需要基于用户每个月的多次消费的记录进行分析,统计得到每个用户在每个月的消费总金额以及当前累计消费总金额,最后结果如下:<br />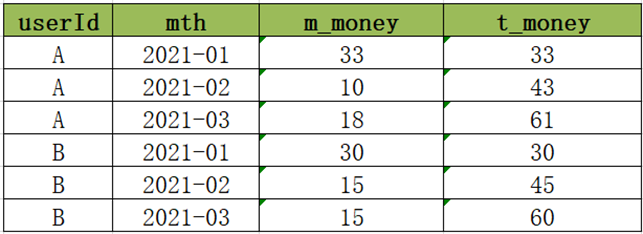<br />以用户A为例:<br /> A在2021年1月份,共四次消费,分别消费5元、15元、8元、5元,所以本月共消费33元,累计消费33元。<br /> A在2021年2月份,共两次消费,分别消费4元、6元,所以本月共消费10元,累计消费43元。
- **分析**
如果要实现以上需求,首先要统计出每个用户每个月的消费总金额,分组实现集合,但是需要按照用户ID,将该用户这个月之前的所有月份的消费总金额进行累加实现。该需求可以通过两种方案来实现:<br />方案一:分组统计每个用户每个月的消费金额,然后构建**自连接**,根据条件分组聚合 <br />方案二:分组统计每个用户每个月的消费金额,然后使用**窗口聚合**函数实现
- 统计得到每个用户每个月的消费总金额
| create table tb_money_mtn as<br />select<br /> userid,<br /> mth,<br /> sum(money) as m_money<br />from tb_money<br />group by userid,mth; |
| --- |
<a name="PZzHz"></a>
#### 5.2.1 方案一:自连接分组聚合
```sql
select
a.userid as auserid,
a.mth as amth,
a.m_money as am_money,
sum(b.m_money) as t_money
from tb_money_mtn a join tb_money_mtn b on a.userid = b.userid
where a.mth >= b.mth
group by a.userid,a.mth,a.m_money;
5.2.2 方案二:窗口函数实现
- 窗口函数sum
功能:用于实现基于窗口的数据求和
语法:sum(colName) over (partition by col order by col)
- colName:对某一列的值进行求和
- 分析
基于每个用户每个月的消费金额,可以通过窗口函数对用户进行分区,按照月份排序,然后基于聚合窗口,从每个分区的第一行累加到当前和,即可得到累计消费金额。
实现:
select
userid,
mth,
m_money,
sum(m_money) over (partition by userid order by mth) as t_money
from tb_money_mtn;
5.3 分组TopN
普通的TopN只要基于数据进行排序,然后基于排序后的结果取前N个即可,相对简单,但是在TopN中有一种特殊的TopN计算,叫做分组TopN。
分组TopN指的是基于数据进行分组,从每个组内取TopN,不再基于全局取TopN。
例如:现在有一份数据如下,记录这所有员工的信息: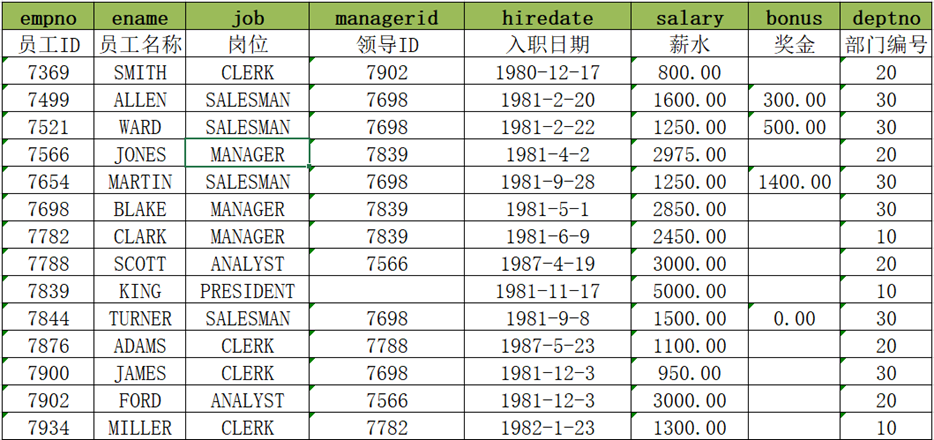
需求:统计查询每个部门薪资最高的前两名员工的薪水,这时候应该如何实现呢?
实现:
TopN函数:row_number、rank、dense_rank
- row_number:对每个分区的数据进行编号,如果值相同,继续编号
- rank:对每个分区的数据进行编号,如果值相同,编号相同,但留下空位
- dense_rank:对每个分区的数据进行编号,如果值相同,编号相同,不留下空位
with t1 as ( select empno, ename, salary, deptno, row_number() over (partition by deptno order by salary desc) as rn from tb_emp ) select * from t1 where rn < 3;6. 拉链表的设计与实现
6.1 数据同步问题
Hive在实际工作中主要用于构建离线数据仓库,定期的从各种数据源中同步采集数据到Hive中,经过分层转换提供数据应用。例如,每天需要从MySQL中同步最新的订单信息、用户信息、店铺信息等到数据仓库中,进行订单分析、用户分析。
例如:MySQL中有一张用户表:tb_user,每个用户注册完成以后,就会在用户表中新增该用户的信息,记录该用户的id、手机号码、用户名、性别、地址等信息。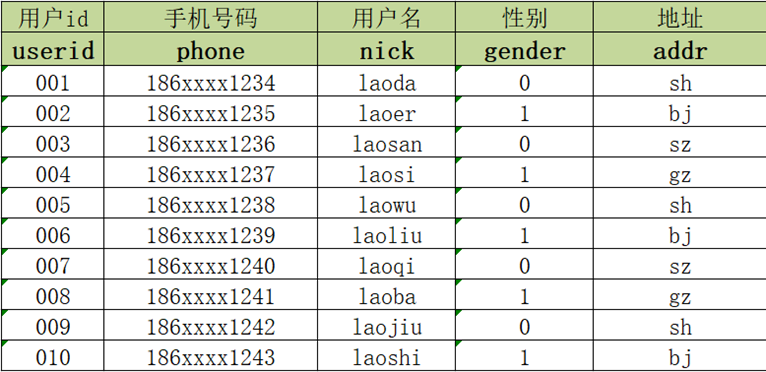
6.1.1 数据同步的问题
在实现数据仓库数据同步的过程中,我们必须保证Hive中的数据与MySQL中的数据是一致的,这样才能确保我们最终分析出来的结果是准确的,没有问题的,但是在实现同步的过程中,这里会面临一个问题:如果MySQL中的数据发生了修改,Hive中如何存储被修改的数据?
例如以下情况
- 2021-01-01:MySQL中有10条用户信息
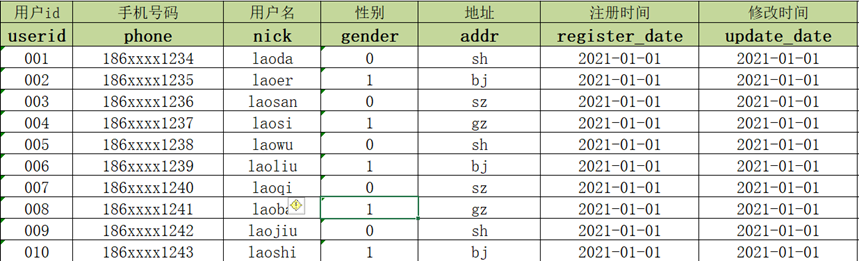
- 2021-01-02:MySQL中新增2条用户注册数据,并且有1条用户数据发生更新
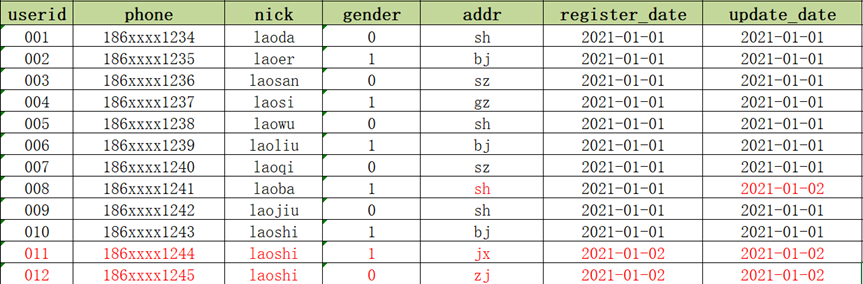
问题:新增的数据会直接加载到Hive表中,但是更新的数据如何存储在Hive表中?
6.1.2 解决方案
- 方案一:在Hive中用新的addr覆盖008的老的addr,直接更新
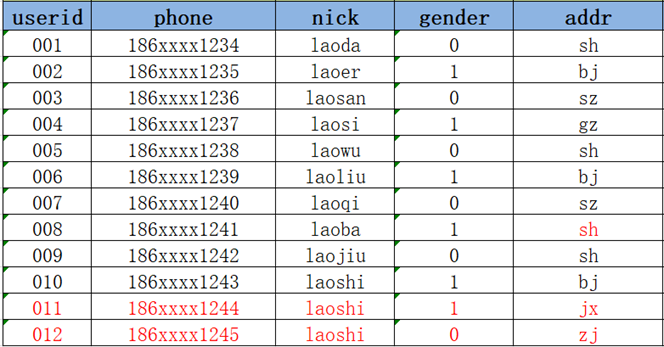
优点:实现最简单,使用起来最方便
缺点:没有历史状态,008的地址是1月2号在sh,但是1月2号之前是在gz的,如果要查询008的1月2号之前的addr就无法查询,也不能使用sh代替
- 方案二:每次数据改变,根据日期构建一份全量的快照表,每天一张表
2021-01-02:Hive中有一张表tb_user_2021-01-02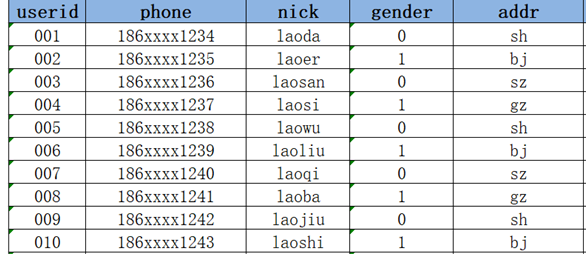
2021-01-03:Hive中有一张表tb_user_2021-01-03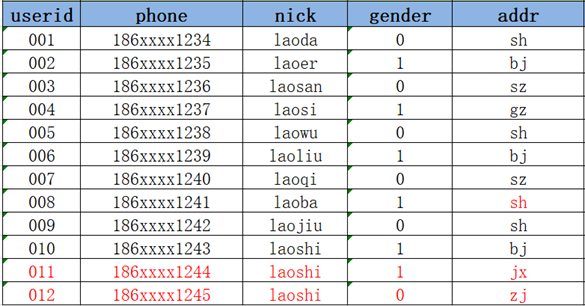
优点:记录了所有数据在不同时间的状态
缺点:冗余存储了很多没有发生变化的数据,导致存储的数据量过大
- 方案三:构建拉链表,通过时间标记发生变化的数据的每种状态的时间周期
6.2 拉链表的设计
拉链表的设计是将更新的数据进行状态记录,没有发生更新的数据不进行状态存储,用于存储所有数据在不同时间上的所有状态,通过时间进行标记每个状态的生命周期,查询时,根据需求可以获取指定时间范围状态的数据,默认用9999-12-31等最大值来表示最新状态。
6.2.1 实现过程
整体实现过程一般分为三步:
- 第一步先增量采集所有新增数据【增加的数据和发生变化的数据】放入一张增量表;
- 第二步创建一张临时表,用于将老的拉链表与增量表进行合并;
- 第三步,最后将临时表的数据覆盖写入拉链表中。例如:
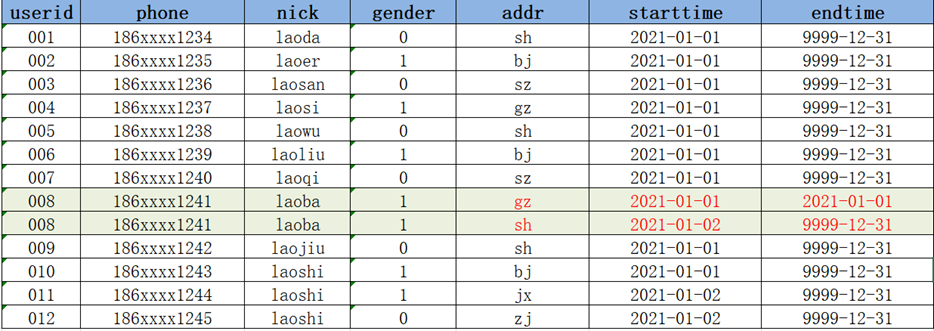
Step1:增量采集变化数据,放入增量表中
Step2:构建临时表,将Hive中的拉链表与临时表的数据进行合并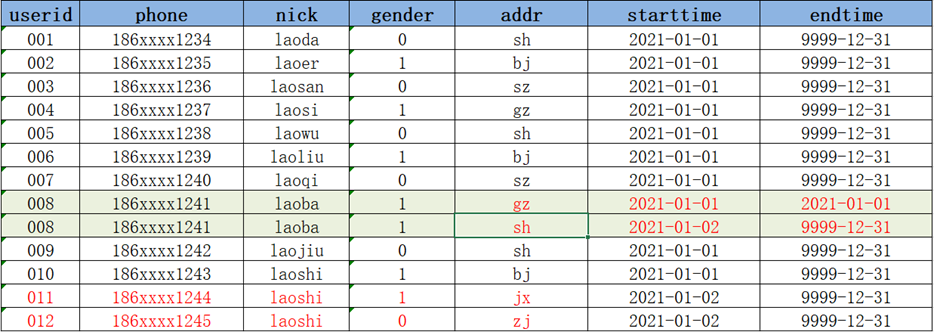
Step3:将临时表的数据覆盖写入拉链表中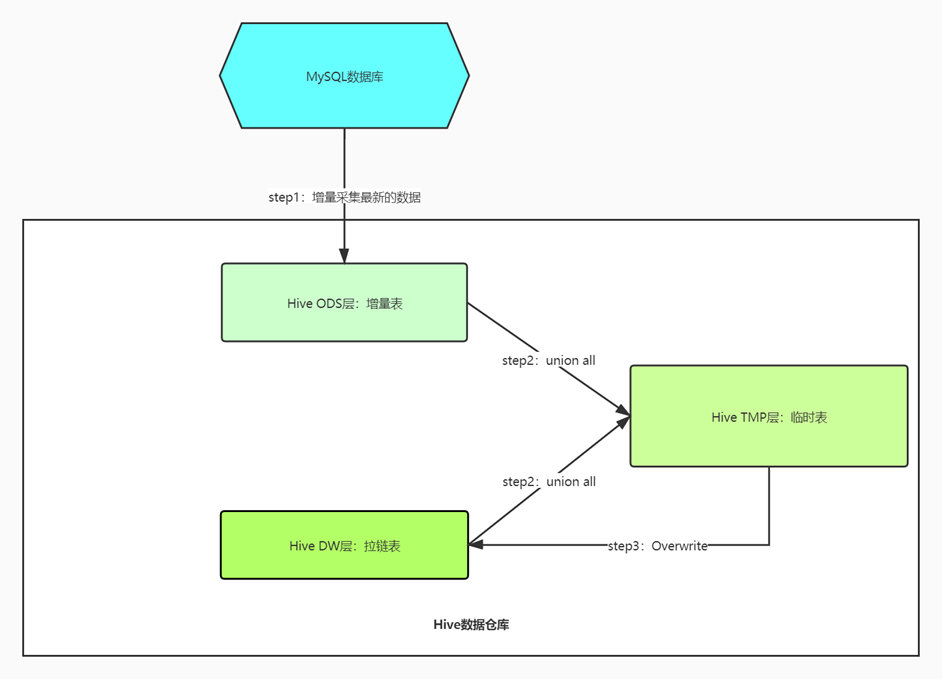
6.3 拉链表的实现
6.3.1 全量采集
创建dw层拉链表
--创建拉链表 create table dw_zipper( userid string, phone string, nick string, gender int, addr string, starttime string, endtime string ) row format delimited fields terminated by '\t';构建模拟数据: | 001 186xxxx1234 laoda 0 sh 2021-01-01 9999-12-31
002186xxxx1235 laoer 1 bj 2021-01-01 9999-12-31
003186xxxx1236 laosan 0 sz 2021-01-01 9999-12-31
004186xxxx1237 laosi 1 gz 2021-01-01 9999-12-31
005186xxxx1238 laowu 0 sh 2021-01-01 9999-12-31
006186xxxx1239 laoliu 1 bj 2021-01-01 9999-12-31
007186xxxx1240 laoqi 0 sz 2021-01-01 9999-12-31
008186xxxx1241 laoba 1 gz 2021-01-01 9999-12-31
009186xxxx1242 laojiu 0 sh 2021-01-01 9999-12-31
010 186xxxx1243 laoshi 1 bj 2021-01-01 9999-12-31 | | —- |加载拉链表数据 | —加载模拟数据
load data local inpath ‘/export/data/zipper.txt’ into table dw_zipper; | | —- |
6.3.2 增量采集
- 创建ods层增量表 ```sql create table ods_zipper_update( userid string, phone string, nick string, gender int, addr string, starttime string, endtime string ) row format delimited fields terminated by ‘\t’;
load data local inpath ‘/export/data/update.txt’ into table ods_zipper_update;
<a name="qZqp8"></a>
#### 6.3.3 合并数据
```sql
insert overwrite table tmp_zipper
select
userid,
phone,
nick,
gender,
addr,
starttime,
endtime
from ods_zipper_update
union all
--查询原来拉链表的所有数据,并将这次需要更新的数据的endTime更改为更新值的startTime
select
a.userid,
a.phone,
a.nick,
a.gender,
a.addr,
a.starttime,
--如果这条数据没有更新或者这条数据不是要更改的数据,就保留原来的值,否则就改为新数据的开始时间-1
if(b.userid is null or a.endtime < '9999-12-31', a.endtime , date_sub(b.starttime,1)) as endtime
from dw_zipper a left join ods_zipper_update b
on a.userid = b.userid ;
insert overwrite table dw_zipper select * from tmp_zipper;

若有收获,就点个赞吧
0 人点赞
