- 带你开始探究 Go iota
- 我为什么会探究 iota 呢?
- iota 由来
- Go iota 究竟有何用处
- 我们知道 iota 的值是从第一行 0 ,开始逐行递增的,对应 iota + 1 只是普通的表达式计算,对于 iota 来说是没有影响的。
- 我们也可以通过修改源代码,然后再编译为新的 go 来执行我们的程序,修改代码块为:src/cmd/compile/internal/noder/noder.go#L456 constDecl() 在 cs.iota++ 之前打印,得到以下值,也印证了我上面说的话。
- iota 能不能被用于普通变量申明?
- -iota 是什么❓
- -iota 是对 iota 增加了一个负号,算是一个表达式,所以对应的结果仅仅是做了一个负值计算。
- iota 源码级探究
- 有关 go 支持 enum 的说明和 issues
- 参考资料
带你开始探究 Go iota
我为什么会探究 iota 呢?
这就要从我最近遇到的一次 protobuf 解析报错说起,错误信息如下:
cannot parse reserved wire type
所以有关这个错误的原因,可以查看👇这篇文章
https://stackoverflow.com/questions/62033409/cannot-find-solutions-to-a-protobuf-unmarshal-error
在查看这个错误的源码定义时,发现它们是一组 const iota 定义,而 const 值是通过 -iota 来赋值的,具体代码:protobuf/encoding/protowire/wire.go
from: google.golang.org/protobuf/encoding/protowire/wire.go
const (_ = -iotaerrCodeTruncatederrCodeFieldNumbererrCodeOverflowerrCodeReservederrCodeEndGroup)
说实话,我用 Go 这么久,还是第一次见 -iota,所以我就一下子来了兴趣,特别想要了解它,首先想到的就是去查 go ref/spec https://golang.org/ref/spec#Iota,但是文中并没有提到 -iota 的用法。
为了了解清楚 iota ,所以我就开始探究,并将我探究的过程记录下来,抛砖引玉,希望可以跟大家一起探讨。
iota 由来
Iota (大写 I 小写 l,中文音译:约塔),是一个全名,而不是某一组词的缩写。iota 是希腊字母中的第 9 个字母。
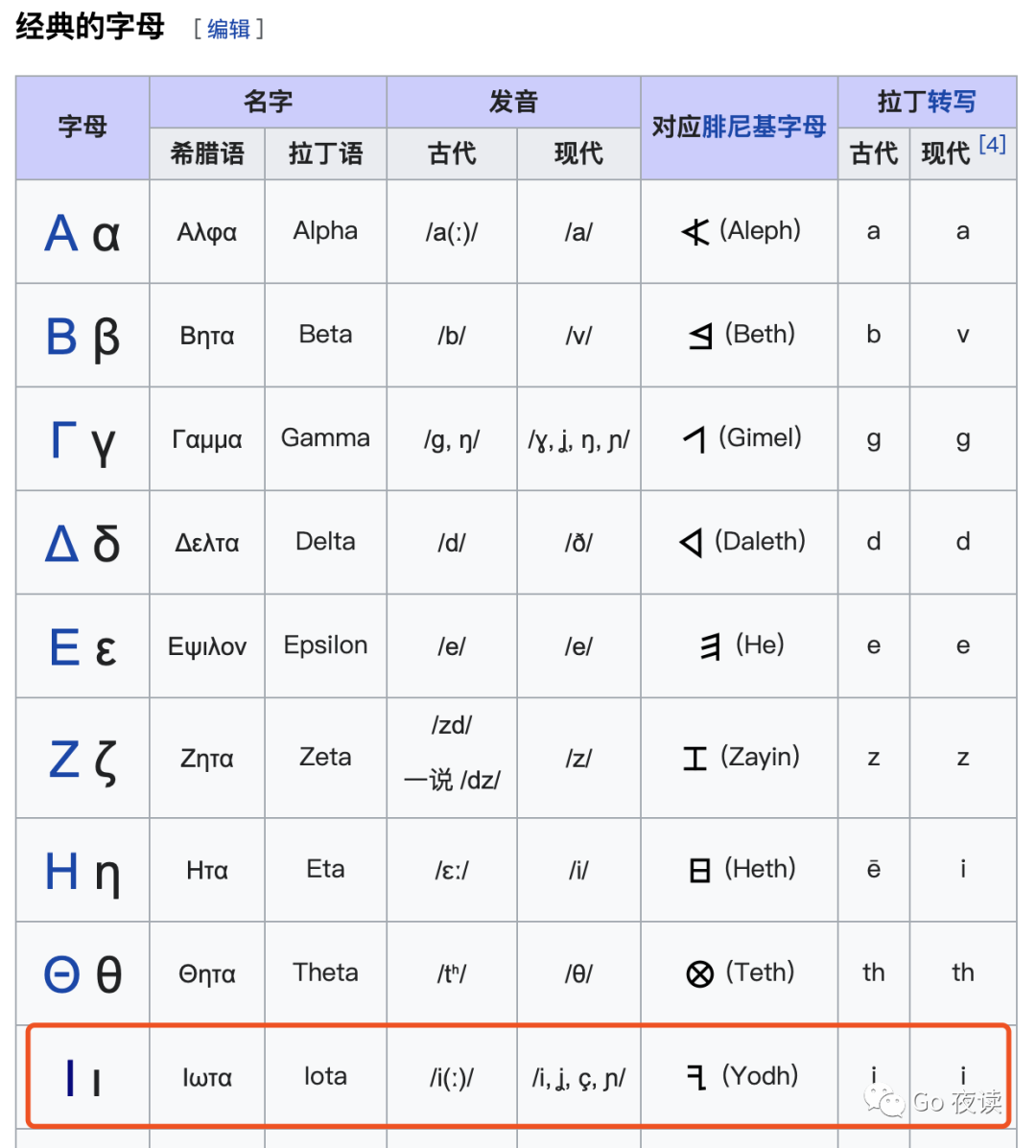
希腊字母 iota 的词源(Etymology)
Iota From Ancient Greek ἰῶτα (iôta). (jot): In reference to a phrase in the New Testament: “until heaven and earth pass away, not an iota, not a dot, will pass from the Law” (Mt 5:18), iota being the smallest letter of the Greek alphabet.
维基百科
网上还有以下的阐述(但是我并不了解,所以无法考证,保留至此,以供大家参考)
希腊字母 iota 在编程语言 APL 中用于生成连续整数序列(可以参考阅读 iota Scheme 文献)。
APL 是 A Programming Language 或 Array Processing Language 的缩写。肯尼斯・艾佛森在 1962 年设计这个语言时他正在哈佛大学工作,1979 年他因对数学表达式和编程语言理论的贡献而得到图灵奖。在过去数十年的使用历史中,APL 从它的原始版本开始不断改变和发展,今天的版本与 1963 年发表时的版本已经非常不一样了。但它始终是一种解释执行的计算机语言。
维基百科
在 C++ 及其他语言中也有类似于 Go iota 的用法。
Go iota 究竟有何用处
可以被当做 enum 来使用,在 const 块中,默认值为 0,即第一行为 0,以后每一行加 1;
Go 中 iota 的使用大致是基于 APL 中的定义来实现的。
iota 的用法 / 注意事项 / 探究
- 不同 const 定义块互不干扰
- 所有注释行和空行全部忽略
- 从第 1 行开始,iota 从 0 逐行加 1
接下来我们来看一个 Go issues 上提到的一些有关 iota 使用的例子
https://github.com/golang/go/issues/39751
type myConst intconst (zero myConst = iota // iota = 0one // iota = 1three = iota + 1 // iota = 2foure // iota = 3five = iota + 1 // iota = 4)func testIota() {// 3 4 5 why not 3 4 6fmt.Println(three, foure, five)}
我们知道 iota 的值是从第一行 0 ,开始逐行递增的,对应 iota + 1 只是普通的表达式计算,对于 iota 来说是没有影响的。
我们也可以通过修改源代码,然后再编译为新的 go 来执行我们的程序,修改代码块为:src/cmd/compile/internal/noder/noder.go#L456 constDecl() 在 cs.iota++ 之前打印,得到以下值,也印证了我上面说的话。
constState.iota: 0
constState.iota: 1
constState.iota: 2constState.iota: 3constState.iota: 4
iota 能不能被用于普通变量申明?
Robert Griesemer 在 2017 年 8 月 16 日提了一个 proposal 想要在 Go2 做这件事。
https://github.com/golang/go/issues/21473
-iota 是什么❓
这个用法我们可以直接查看 Go 标准包,src/text/scanner/scanner.go:
// The result of Scan is one of these tokens or a Unicode character.const (EOF = -(iota + 1)IdentIntFloatCharStringRawStringComment// internal use onlyskipComment)
如果你不通过测试,你知道 Ident 的值为 -2 吗?
还有 src/cmd/asm/internal/arch/arch.go:
// Pseudo-registers whose names are the constant name without the leading R.const (RFP = -(iota + 1)RSBRSPRPC)
以及 src/cmd/compile/internal/gc/bexport.go:
// Tags. Must be < 0.const (// ObjectspackageTag = -(iota + 1)constTagtypeTagvarTagfuncTagendTag// TypesnamedTagarrayTagsliceTagdddTagstructTagpointerTagsignatureTaginterfaceTagmapTagchanTag// ValuesfalseTagtrueTagint64TagfloatTagfractionTag // not used by gccomplexTagstringTagnilTagunknownTag // not used by gc (only appears in packages with errors)// Type aliasesaliasTag)
-iota 是对 iota 增加了一个负号,算是一个表达式,所以对应的结果仅仅是做了一个负值计算。
iota 源码级探究
非常感谢欧神对此处源码阅读的指导,大家如果对 Go 源码感兴趣,可以直接读欧神写的书📚《Go 语言原本》
在线阅读地址:https://golang.design/under-the-hood/
为什么 -iota 之后的 const 值是在递减呢?
https://golang.design/gossa?id=b49e9104-3750-4a47-ba55-e491489d8cf1

在 src/cmd/compile/internal/ir 下面有一个 ConstExpr
type ConstExpr struct {miniExprorigNodeval constant.Value}
注意:此处的 ConstExpr 是在 Go 仓库 master 上才有,在当前 go1.16.3 是没有这个定义的。
额外补充有关 ir 重构相关的内容
为什么要重构一个 ir 出来,我们可以根据 git commit history 追溯得知
如果要完全分解 gc 包,则需要将其定义的编译器 IR 移到一个单独的包中,该包可以由 gc 本身导入的包导入。
- https://go-review.googlesource.com/c/go/+/273008
- https://github.com/golang/go/commit/84e2bd611f9b62ec3b581f8a0d932dc4252ceb67#diff-48abec9cb23c79fc5e7fa7f2b4a81e079a9d405d257bbd72758e983506244c99
为什么要重构为 ConstExpr,我们可以在 CL 上看到描述:
- https://go-review.googlesource.com/c/go/+/275033
- https://github.com/golang/go/commit/a2058bac21f40925a33d7f99622c967b65827f29#diff-4d97274cfa5251d986ad72fc0a75c0f3a907d65b92426cbce4e6328821afc104
- 之前用 Name 表示常量折叠的表达式,不够优化,因为 Name 具有很多字段来支持声明的名称(与常量折叠的表达式无关),而常量表达式则相当简洁。
- 轻量级 ConstExpr 类型,可以简单地包装现有表达式并将其与值相关联。
言归正传,我们继续来看 iota 是如何计算的。
最容易想到的定位方法,就是全局检索: iota 然后查看其赋值即可,但是现实是远没有我们想象的那么简单。。。
// constState tracks state between constant specifiers within a// declaration group. This state is kept separate from noder so nested// constant declarations are handled correctly (e.g., issue 15550).type constState struct {group *syntax.Grouptyp ir.Ntypevalues []ir.Nodeiota int64}
入口函数 src/cmd/compile/main.go,
func main() {gc.Main(archInit)}
gc.Main: src/cmd/compile/internal/gc/main.go :
func Main(archInit func(*ssagen.ArchInfo)) {...// Parse and typecheck input.noder.LoadPackage(flag.Args())...}
LoadPackage 的伪代码:
func LoadPackage(filenames []string) {...for _, p := range noders {p.node()p.file = nil // release memory}...// Process top-level declarations in phases.// Phase 1: const, type, and names and types of funcs.// This will gather all the information about types// and methods but doesn't depend on any of it.//// We also defer type alias declarations until phase 2// to avoid cycles like #18640.// TODO(gri) Remove this again once we have a fix for #25838....// Phase 2: Variable assignments.// To check interface assignments, depends on phase 1....// Phase 3: Type check function bodies....// Phase 4: Check external declarations.// TODO(mdempsky): This should be handled when type checking their// corresponding ODCL nodes....// Phase 5: With all user code type-checked, it's now safe to verify map keys.// With all user code typechecked, it's now safe to verify unused dot imports.}
在 Process top-level declarations in phases 之前的 p.node () 主要就干了一件事:
typecheck.Target.Decls = append(typecheck.Target.Decls, p.decls(p.file.DeclList)...)
对于 const 来说, decls 就是执行 func (p *noder) constDecl(decl *syntax.ConstDecl, cs *constState) []ir.Node
func (p *noder) constDecl(decl *syntax.ConstDecl, cs *constState) []ir.Node {...n.SetIota(cs.iota)...cs.iota++return nn}
从而得到了我们的 iota 为一个递增的值。
而 typecheck 在 go 1.16.3 是在以上几个阶段的时候实时执行的,而在 master 上,已经不是这样实现了。
func typecheck(n ir.Node, top int) (res ir.Node) {...// Resolve definition of name and value of iota lazily.n = Resolve(n)...n = typecheck1(n, top)...if t != nil {n = EvalConst(n)t = n.Type()}...return n}
我们拆解以上逻辑块:
- Resolve 得到 iota 的值,注意这里的值其实是正值
// Resolve ONONAME to definition, if any.func Resolve(n ir.Node) (res ir.Node) {...if r.Op() == ir.OIOTA {if x := getIotaValue(); x >= 0 {return ir.NewInt(x)}return n}...}
getIotaValue() 是从 typecheckdefstack 中取最后一个 ir.Name,然后取 Offset_ 的值。
// type checks the whole tree of an expression.// calculates expression types.// evaluates compile time constants.// marks variables that escape the local frame.// rewrites n.Op to be more specific in some cases.var typecheckdefstack []*ir.Name...// getIotaValue returns the current value for "iota",// or -1 if not within a ConstSpec.func getIotaValue() int64 {if i := len(typecheckdefstack); i > 0 {if x := typecheckdefstack[i-1]; x.Op() == ir.OLITERAL {return x.Iota()}}}
ir.Name 中的 Offset_ 的相关操作:
func (n *Name) Iota() int64 { return n.Offset_ }func (n *Name) SetIota(x int64) { n.Offset_ = x }
- typecheck1 进行了一系列的猛操作就是为 EvalConst 铺路。
- EvalConst 逻辑块:
// EvalConst returns a constant-evaluated expression equivalent to n.// If n is not a constant, EvalConst returns n.// Otherwise, EvalConst returns a new OLITERAL with the same value as n,// and with .Orig pointing back to n.func EvalConst(n ir.Node) ir.Node {// Pick off just the opcodes that can be constant evaluated.switch n.Op() {// 而构建 Const 的关键就是 tokenForOp[n.Op()],到底是 + 还是 -return OrigConst(...)}...}
而 constant.UnaryOp 的代码就是根据 token.SUB (-) 计算值的:
// UnaryOp returns the result of the unary expression op y.// The operation must be defined for the operand.// If prec > 0 it specifies the ^ (xor) result size in bits.// If y is Unknown, the result is Unknown.//func UnaryOp(op token.Token, y Value, prec uint) Value {...case token.SUB:switch y := y.(type) {case unknownVal:return ycase int64Val:if z := -y; z != y {return z // no overflow}return makeInt(newInt().Neg(big.NewInt(int64(y))))case intVal:return makeInt(newInt().Neg(y.val))case ratVal:return makeRat(newRat().Neg(y.val))case floatVal:return makeFloat(newFloat().Neg(y.val))case complexVal:re := UnaryOp(token.SUB, y.re, 0)im := UnaryOp(token.SUB, y.im, 0)return makeComplex(re, im)}...}
终上所述,我们就大概了解其 Go iota 的递增、递减过程了。
有关 go 支持 enum 的说明和 issues
https://github.com/golang/go/issues/28987#issuecomment-497108307
Iota 或 enum 相关的 issues
参考资料
https://stackoverflow.com/questions/31650192/whats-the-full-name-for-iota-in-golang
https://stackoverflow.com/questions/28411850/why-is-it-called-iota
https://blog.learngoprogramming.com/golang-const-type-enums-iota-bc4befd096d3
文中所涉及的 CL:

若有收获,就点个赞吧
0 人点赞
