
XML全称为Extensible Markup Language,意思是可扩展的标记语言。
XML的作用:
1.储存数据。
2.配置文件。
3.在网络中传输数据(用的不多,一般用json)
1. 语法
1.1 xml的文档声明
格式:<br /> <?xml version="1.0" encoding="utf-8"?> <br /> a. 文档声明必须以<?开头,以?>结尾。<br /> b. 文档声明必须写在xml中的第一行第一列。文档声明也可以省略,推荐不省略。<br /> c. xml文档声明中有两个属性,一个是version另一个encoding<br /> 其中version是必须的,表示版本号。<br /> encoding是可选的,如果不写,编码方式默认是utf-8
1.2 元素element
是xml文档中最重要的组成部分。<br /> 格式:<br /> <元素名></元素名><br /> <br /> a. 每个元素可以有开始标签,结束标签,以及元素体组成。 <br /> b. 元素体可以是一些文本,也可以是其他元素,也可以不写。<br /> c. 在一个xml中,最多只允许有一个根元素(就是最外层的元素),根元素里可以写多个子元素,元素名可以重名。<br /> d. 如果一个元素没有元素体,那么可以省略结束标签。但是这个元素要自闭和 <元素名/><br /> e. 在xml中,元素名是严格区分大小写的<br /> 元素名不要有特殊符号,比如空格,冒号等<br /> 元素名不要使用xml,XML,Xml等,因为容易混淆。<br />
1.3 属性attribute
格式:<br /> <元素名 属性名=属性值 属性名=属性值></元素名><br /> <br /> a. 属性必须写在开始标签中。<br /> b. 一个元素中可以有多个属性,多个属性之间使用空格隔开。多个属性的属性名不能重复。属性名不能以数字开头。<br /> c. 属性值必须使用双引号或者单引号包裹,推荐使用双引号。<br /> d. 属性名里面不要有特殊符号比如冒号空格等。<br />
1.4 注释:
格式:<br /> <!-- 注释内容 --><br /> 和java一样注释也是对程序进行解释说明的文字。<br /> 并且注释也不会被解析。<br />(插播:<br />用浏览器也能打开XML文件,并且会显示报错的具体原因,一般列不太准,但是行都差不多没问题。<br />)
1.5 转义字符
(不用背,用到的时候知道并且能查就行)
如果在xml中要使用一些特殊的字符,必须要进行转义。
这个转义后的字符,就是转义字符
< : <
> : >
“ : "
‘ : '
& : &
注意上面的;要含在里面
1.6 XML的CDATA区
(不需要背,有个印象,以后用的时候直接粘就行)
如果在一个xml中大量的出现转义字符,会影响xml文件的阅读性,也会影响我们的开发效率。
可以CDATA区来解决这个问题。
CDATA区里面的所有内容都不需要转义,都会原样输出。
格式:
<![CDATA[
内容
]]>
2 XML约束
xml语法是非常灵活的,但是如果过于灵活其实也不是特别好。
我们需要对xml的写法进行限制,
约束就是用来限制xml文件的编写的,可以限制xml中的元素名,属性,以及元素内容等等等。
在xml中约束有两种。
1. dtd
2. schema
学习目标:
能够根据已有的约束文档编写对应的xml。
2.1 DTD约束
DTD(Document Type Definition),文档类型定义,用来约束XML文档。规定XML文档中元素的名称,子元素的名称及顺序,元素的属性等。
如果要在xml中使用dtd约束,那么必须要把dtd约束引入到这个xml中。
如何引入?
从dtd文档注释中找到以<!DOCTYPE开头的,并把它粘贴到xml中。
<!DOCTYPE beans SYSTEM “bean.dtd”>
beans表示这个xml文件的根元素
2.1.1 DTD语法(了解)
特殊符号的作用:<br /> ? : 可以出现0次,或者1次。 最多出现1次。<br /> * : 可以出现0次,或者1次,或者多次。 可以出现任意次。<br /> + : 可以出现1次,或者多次,至少出现1次。<br /> (): 对指定的数据进行分组<br /> | : 表示的多选一 <br /> , : 表示顺序。 比如: 苹果, 西瓜, 金钟<br />如果只有串字母后面什么也没有表示必须有一个<br />举例:<br /><br />其中,此处servlet-class必须有一个,servlet-class和jsp-file中选一个且必须有一个。<br /> <br /> #PCDATA表示元素体必须是文本,不能是其他元素
2.1.2 快捷编写
eclipse中:
导入了约束文件之后,使用快捷键编写xml。 alt + /
2.1.3 web.xml的编写
此处注意:用eclipse创建的Dynamic Web Project项目版本要选2.2的,因为2.2以后用的约束不是dtd而是schema。
2.1.4 DTD约束文档的阅读(不重要,简单了解)
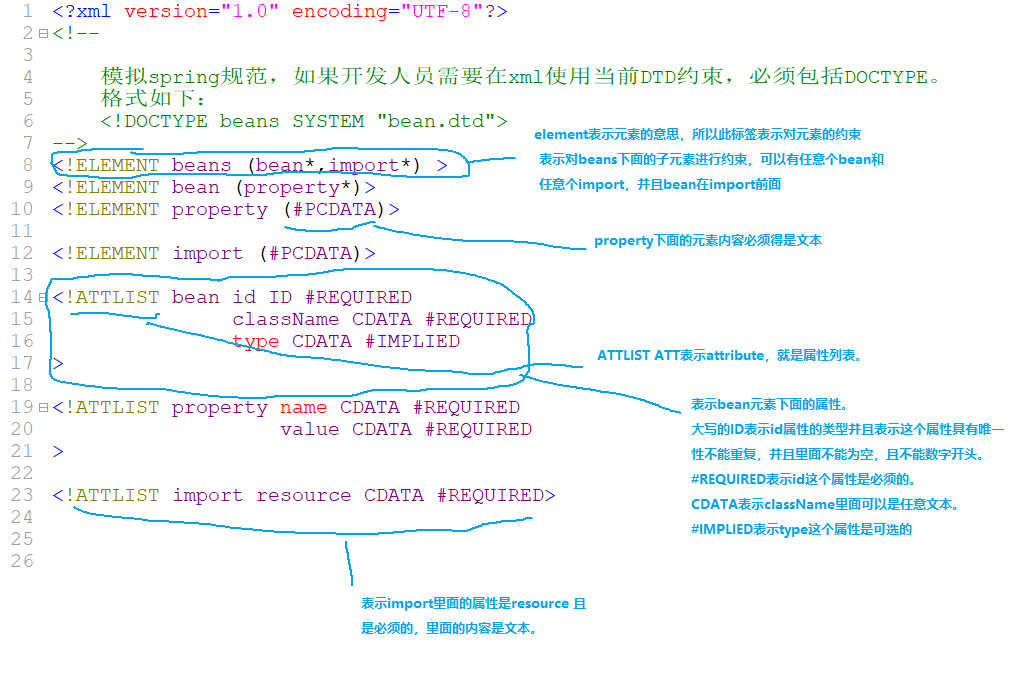
2.1.5 dtd文档声明的三种方式(dtd文档引入的三种方式)
1. 内部dtd。
指的是把dtd(嵌套)写在xml文件的内部。<br /> 极度不推荐,因为严重影响xml的可阅读性<br /> 格式:
<?xml version="1.0" encoding="utf-8" ?>
<!DOCTYPE beans [
... //dtd具体的语法
]>
<beans>
</beans>
这个dtd约束只在当前的xml中有效。<br />
2. 外部dtd-本地dtd (把dtd约束内容写到一个文件中,然后再通过文件的方式进行引入就可以了。)
格式:
<!DOCTYPE beans SYSTEM "bean.dtd">
beans表示:根元素
SYSTEM表示引入的本地dtd
“bean.dtd”:这个表示dtd文件在电脑的位置。表示的是当前文件夹下面的dtd文件。
3. 外部dtd-公共dtd (把dtd约束文件放到一个网络上,通过网络的方式访问这个dtd文件)
格式:
<!DOCTYPE web-app PUBLIC "-//Sun Microsystems, Inc.//DTD Web Application 2.2//EN" "http://java.sun.com/j2ee/dtds/web-app_2_2.dtd">
web-app:根元素
PUBLIC:使用的是公共dtd这种方式
“-//Sun Microsystems, Inc.//DTD Web Application 2.2//EN”:这个约束的名字,名字可以随便写。
“http://java.sun.com/j2ee/dtds/web-app_2_2.dtd":这个约束文件在网络上的位置。
2.2 schema约束
Schema是新的XML文档约束;
Schema要比DTD强大很多,是DTD 替代者;
Schema本身也是XML文档,但Schema文档的扩展名为xsd,而不是xml。
Schema 功能更强大,数据类型更完善
Schema 支持名称空间
2.2.1 schema的引用和使用
引入schema约束的方式和引入dtd约束一样,直接把schema约束中注释的内容粘贴过来就可以了
引入过来的schema约束声明,本身就是一个开始标签,需要我们手动补齐结束标签。
引入过来之后,根元素直接就确定了,这个xml的根元素就是beans
<beans xmlns="http://www.itcast.cn/bean"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://www.itcast.cn/bean bean-schema.xsd"
>
</beans>
2.2.2 名称空间简介(也叫命名空间)
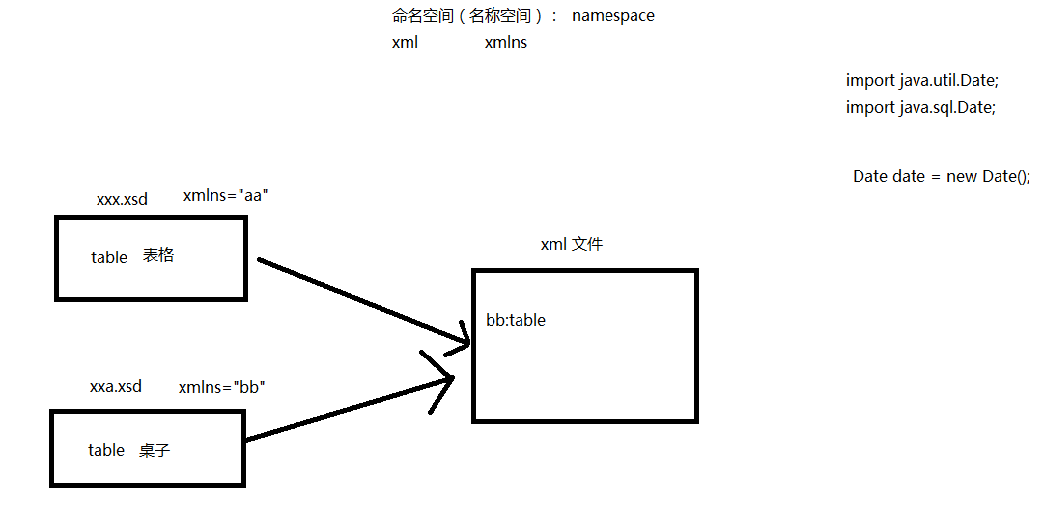
2.2.3 约束文档和xml的关系
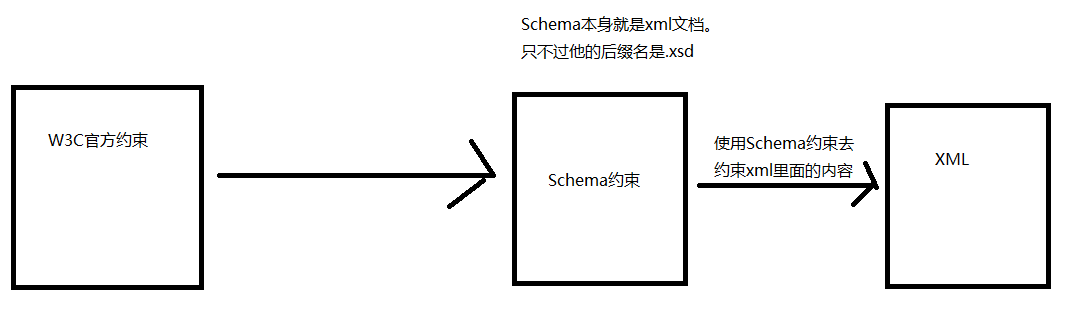
2.2.4 schema约束声明介绍
<?xml version="1.0" encoding="UTF-8"?>
<!--
schema约束声明
xmlns="http://www.itcast.cn/bean"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://www.itcast.cn/bean bean-schema.xsd"
xmlns="http://www.itcast.cn/bean"
表示引入的约束的名称空间的名字。
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
固定写法,引入的是w3c官方的东西
xsi:schemaLocation="http://www.itcast.cn/bean bean-schema.xsd"
这个表示的是引入的schema约束的位置。格式:
名称空间 约束文件的位置
-->
<beans xmlns="http://www.itcast.cn/bean"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://www.itcast.cn/bean bean-schema.xsd"
>
</beans>
2.2.5 隐式命名空间和显式命名空间
<?xml version="1.0" encoding="UTF-8"?>
<aa:beans xmlns:aa="http://www.itcast.cn/bean"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://www.itcast.cn/bean bean-schema.xsd"
>
<!--
命名空间的两种声明方式
隐式命名空间:
我们之前用的都是隐式命名空间
xmlns="http://www.itcast.cn/bean"
显式命名空间:
引入命名空间的时候加上一个别名就可以了。
xmlns:别名="名称空间"
如果要使用该命名空间对应的约束下面的内容,则必须要通过别名的方式获取。
<aa:bean></aa:bean>
-->
<aa:bean className="" id=""></aa:bean>
</aa:beans>
注意:第二行加了别名aa之后,此时
2.3 XML解析
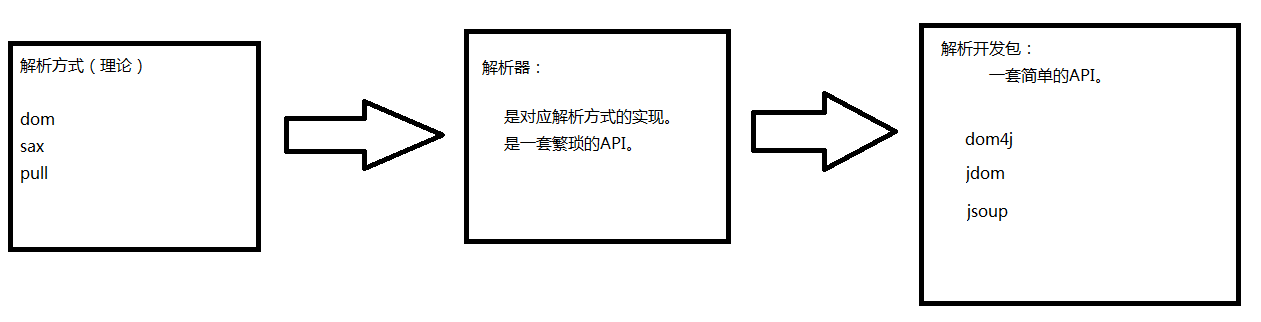
2.3.1 xml的解析方式:
1. dom解析(重要)<br /> 会把整个的xml文档都读取到内存中,然后再进行解析。<br /> 好处:可以保留xml文档的原有结构。我们可以对这个xml进行增删改查操作<br /> 缺点:占用内存非常大。<br /> <br /> 2. sax解析(了解)<br /> 会逐行扫描xml文档,每扫描一行,就释放一行。<br /> 好处:占用内存小,效率高<br /> 缺点:不能保留xml的结构,只能读取,不能进行其他操作。<br /> 3. pull解析(了解)<br /> 安卓内置的解析方式, 不需要关注,类似sax
2.3.2 解析方式、解析器、和解析开发包的关系
2.3.3 dom解析中的dom树
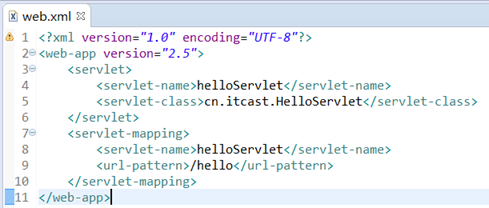
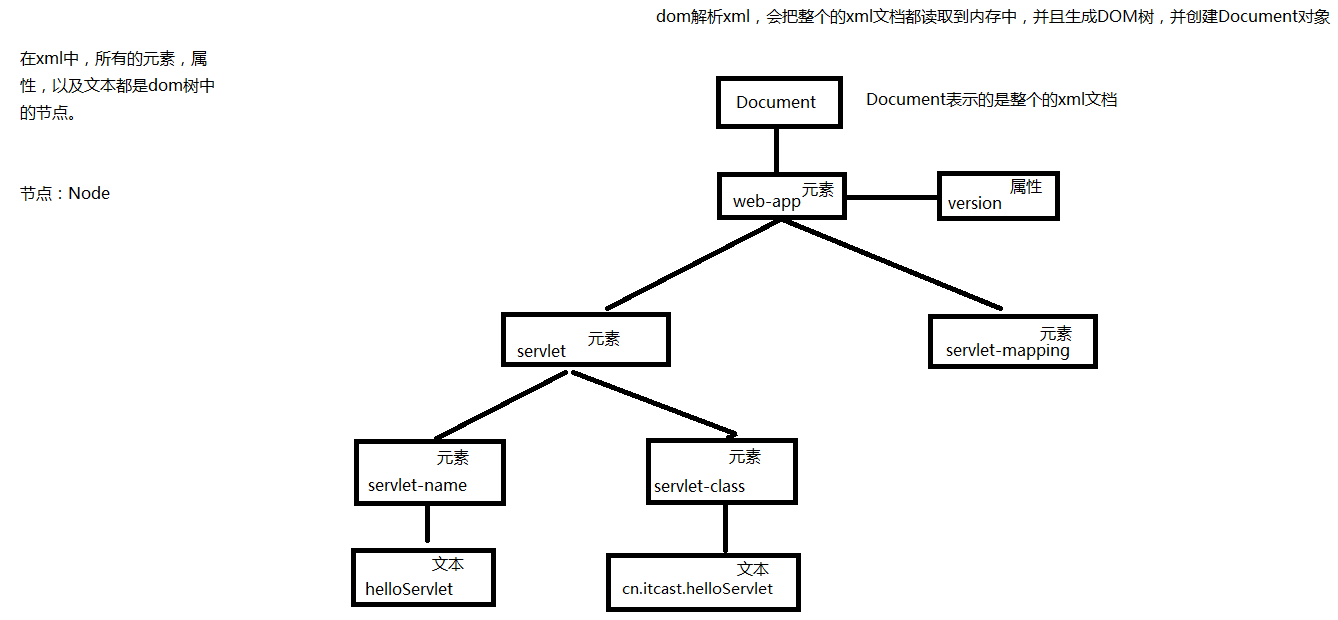
2.3.4 dom解析前的准备
准备一个要读取的xml文档
beans.xml ```xml <?xml version=”1.0” encoding=”UTF-8”?>
2. dom4j是第三方提供的一个解析开发包。<br /> 所以如果要用,需要导入jar包<br />3. dom4j里面的类(接口)和方法<br /> SAXReader:是核心类,用来读取xml文件。<br /> read方法:用来读取xml文件,返回一个Document对象。<br /> <br /> Document:表示的是整个的xml<br />getRootElement方法:可以获取到xml文件的根元素。返回值是Element类型<br /> <br /> Element: 表示的是元素。<br />attributeValue方法:可以获取到这个元素中指定属性的属性值。(就是根据属性名拿属性值)<br />elements方法:可以获取当前元素下面的所有的子元素
<a name="nOb4N"></a>
### 2.3.5 dom解析代码的实现
目标:把xml里面的元素和相应的属性值都读取出来。
```java
import java.util.List;
import org.dom4j.Document;
import org.dom4j.DocumentException;
import org.dom4j.Element;
import org.dom4j.io.SAXReader;
public class Demo02Xml {
public static void main(String[] args) throws Exception {
//创建核心类对象,用来读取xml文件
SAXReader reader = new SAXReader();
//调用read方法,读取xml,并且生成Document对象返回
Document document = reader.read("beans.xml");
//调用getRootElement方法,获取到根元素
Element rootElement = document.getRootElement();
//获取根元素beans下面的所有的子元素
List<Element> beanList = rootElement.elements();
//遍历这个集合,拿到这个集合中的每个子元素(bean元素)
for(Element bean : beanList) {
//bean表示的就是每一个子元素
//获取到bean元素上面的属性。
String id = bean.attributeValue("id");//获取id这个属性对应的属性值。
String className = bean.attributeValue("className");//获取className这个属性对应的属性值。
//打印结果
System.out.println(id + "--" + className);
//获取到这个bean元素下面的所有的子元素
List<Element> propertyList = bean.elements();
//遍历集合,拿到集合的每一个元素,也就是每一个property元素
for(Element property : propertyList) {
//property表示的就是bean下面的每个子元素
//根据属性名获取到对应的属性值
String name = property.attributeValue("name");
String value = property.attributeValue("value");
System.out.println(name + "--" + value);
}
}
}
}

若有收获,就点个赞吧
0 人点赞
