1 SQL语句之DQL(Data Query Language)
数据准备
#创建商品表:CREATE TABLE product(pid INT PRIMARY KEY AUTO_INCREMENT,pname VARCHAR(20),price DOUBLE,category_id VARCHAR(32));INSERT INTO product(pid,pname,price,category_id) VALUES(1,'联想',5000,'c001');INSERT INTO product(pid,pname,price,category_id) VALUES(2,'海尔',3000,'c001');INSERT INTO product(pid,pname,price,category_id) VALUES(3,'雷神',5000,'c001');INSERT INTO product(pid,pname,price,category_id) VALUES(4,'JACK JONES',800,'c002');INSERT INTO product(pid,pname,price,category_id) VALUES(5,'真维斯',200,'c002');INSERT INTO product(pid,pname,price,category_id) VALUES(6,'花花公子',440,'c002');INSERT INTO product(pid,pname,price,category_id) VALUES(7,'劲霸',2000,'c002');INSERT INTO product(pid,pname,price,category_id) VALUES(8,'香奈儿',800,'c003');INSERT INTO product(pid,pname,price,category_id) VALUES(9,'相宜本草',200,'c003');INSERT INTO product(pid,pname,price,category_id) VALUES(10,'面霸',5,'c003');INSERT INTO product(pid,pname,price,category_id) VALUES(11,'好想你枣',56,'c004');INSERT INTO product(pid,pname,price,category_id) VALUES(12,'香飘飘奶茶',1,'c005');INSERT INTO product(pid,pname,price,category_id) VALUES(13,'果9',1,NULL);
1.1 基本查询
# 查询商品表中的所有的商品信息
SELECT * FROM product;
# 查询商品表中的所有商品名以及商品价格
SELECT pname, price FROM product;
# 查询所有商品的商品名
SELECT pname FROM product;
# 别名查询, 可以对于查询后的结果,给列重新起一个名字。
# 使用关键字as
# select 列名 as 别名, 列名 as 别名 from 表名;
SELECT pname AS 商品名, price AS 价格 FROM product;
SELECT pname AS '商品名', price AS '价格' FROM product;
# AS 这个关键字在别名查询中可以省略
# select 列名 别名, 列名 别名 from 表名;
SELECT pname 商品名字, price 商品价格 FROM product;
# 除了可以给列起一个别名之外,还可以给表起一个别名
# select 列 from 表 AS 别名;
SELECT * FROM product AS 商品表; -- 现在看不出效果,需要多表查询才能看到效果.
# 查询所有的商品价格,对于查询后的商品价格进行去重
# 去重可以使用一个关键字,叫做distinct
# select distinct 列 from 表;
SELECT DISTINCT price FROM product;
# 计算查询,对于查询后的结果可以重新计算
# 查询所有的商品名以及商品价格, 给商品价格加上50进行显示
SELECT pname, price + 50 AS price FROM product;
1.2 条件查询
/*
条件查询
运算符:
>, >=, <, <=, =, <>, !=
between ... and ...:在区间范围内。包含头和尾。比如:between 3 and 10。指的是在3和10 的区间。
in(...): 包含。只要包含其中之一就算满足条件。比如: in(3,5,7),包含3或者5或者7
like: 模糊查询,需要结合通配符去使用。
%:表示任意个任意的字符。
_:表示一个任意的字符
is null: 判断是否为空.
and: 与。 相当于java中的&&。 有假则假。
or: 或。 相当于java中的||。 有真则真。
not: 非。 相当于java中的!
运算符可以用作条件筛选。
格式:
select 列 from 表名 where 条件;
*/
# 查询商品名称为“花花公子”的商品所有信息:
SELECT * FROM product WHERE pname = '花花公子';
# 查询价格为800商品所有信息
SELECT * FROM product WHERE price = 800;
# 查询价格不是800的所有商品所有信息
SELECT * FROM product WHERE price != 800;
SELECT * FROM product WHERE price <> 800;
SELECT * FROM product WHERE NOT(price = 800);
# 查询商品价格大于60元的所有商品信息
SELECT * FROM product WHERE price > 60;
# 查询商品价格大于60元的所有商品名和商品价格
SELECT pname, price FROM product WHERE price > 60;
# 查询商品价格在200到1000之间所有商品
SELECT * FROM product WHERE price >= 200 AND price <= 1000;
SELECT * FROM product WHERE price BETWEEN 200 AND 1000; --注意此处必须从小到大写,200必须在1000前面。
# 查询商品价格是200或800的所有商品
SELECT * FROM product WHERE price = 200 OR price = 800;
SELECT * FROM product WHERE price IN(200, 800); -- 表示商品价格只要包含200或者800即可。
# 查询含有'霸'字的所有商品
# 含有霸,并没有在精确的查找,所以可以使用模糊查询 like
# like需要结合通配符去使用
# %表示任意个(0个1个或者多个) 任意字符
# _表示一个任意的字符。
# 名字包含霸, 霸前面可以有任意个字符, 后面也可以有任意个字符。
SELECT * FROM product WHERE pname LIKE '%霸%';
# 查询商品名字以香开头的商品
# 第一个字肯定是香, 剩下的东西可以是任意个字符
SELECT * FROM product WHERE pname LIKE '香%';
# 查询第二个字为'想'的所有商品
# 前面要有一个字符, 第二个字符要是一个想,剩下的可以是任意个任意的字符
SELECT * FROM product WHERE pname LIKE '_想%';
# 查询商品名是四个字的商品
# 名字必须要有四个字符
SELECT * FROM product WHERE pname LIKE '____';
# 商品没有分类的商品信息
# 如果分类id是null表示这个商品没有分类。
SELECT * FROM product WHERE category_id IS NULL;
# 查询有分类的商品
SELECT * FROM product WHERE category_id IS NOT NULL;
1.3 排序查询
/*
排序查询 order by
可以对于查询后的结果按照指定列进行排序。
格式:
select * from 表名 order by 要排序的列 [asc | desc];
asc:表示升序排序(从小到大)
desc:表示降序排序 (从大到小)
asc 和desc都可以省略,如果省略,默认是升序排序。
*/
# 查询所有商品信息,按照价格从小到大排序。
SELECT * FROM product ORDER BY price ASC;
# 也可以省略 asc,如果省略,默认就是升序
SELECT * FROM product ORDER BY price;
# 查询所有商品信息,按照价格从大到小排序
SELECT * FROM product ORDER BY price DESC;
# 在价格排序(降序)的基础上,以id排序(降序)
SELECT * FROM product ORDER BY price DESC, pid DESC;
# 显示商品的价格(去重复),并排序(降序)
SELECT DISTINCT price FROM product ORDER BY price DESC;
1.4 聚合查询
/*
聚合函数
聚合函数用作纵向查询。
count:用来统计指定的列的数据条数。不会统计null值.
sum: 用来求指定列的数据和。
avg: 用来求指定列的平均值
max: 求指定列的最大值。
min: 求指定列的最小值。
聚合函数要放在sql语句的查询字段位置。
select 字段 from 表;
格式:
聚合函数(列名)
*/
# 查询price这一列有多少条数据
SELECT COUNT(price) FROM product;
# 查询category_id 这一列有多少条数据
SELECT COUNT(category_id) FROM product;
# 如果想要查询表中有多少条数据,可以使用count(*)
SELECT COUNT(*) FROM product;
# 查询价格大于200商品的总条数
SELECT COUNT(*) FROM product WHERE price > 200;
# 查询分类为'c001'的所有商品的价格总和
SELECT SUM(price) FROM product WHERE category_id = 'c001';
# 查询分类为'c002'所有商品的平均价格
SELECT AVG(price) FROM product WHERE category_id = 'c002';
# 查询商品的最大价格和最小价格
SELECT MAX(price) FROM product;
SELECT MIN(price) FROM product;
SELECT MAX(price) AS 最大价格, MIN(price) AS 最小价格 FROM product;
1.5 分组查询
/*
查询每个分类商品的总价格。
可以对商品分类进行分组,可以使用mysql中的分组查询。
分组查询要使用关键字:group by去实现。
格式:
group by 要分组的字段
分组之后,使用聚合函数查询,查询的是每个组里面的数据。
分组group by,一定要结合聚合函数去使用。
*/
# 查询每个分类商品的总价格。
# 先根据商品分类进行分组,然后再查询总价格
SELECT category_id, SUM(price) FROM product GROUP BY category_id;
# 统计各个分类商品的个数
# 对商品分类id进行分组。
# 明确两个东西: 1. 对什么进行分组, 2. 查什么,聚合函数就用什么。
SELECT category_id, COUNT(*) FROM product GROUP BY category_id;
# 统计各个分类商品的个数,且只显示个数大于1的信息
/*
where 和 having都用作条件筛选。
where: 用在分组前,对分组前的数据进行条件筛选
having: 用在分组后,对分组后的数据进行条件筛选
*/
SELECT category_id, COUNT(*) FROM product GROUP BY category_id HAVING COUNT(*) > 1;
2 SQL的备份与恢复
2.1 SQL备份
2.1.1 MySQL命令备份
数据库导出sql脚本的格式:
mysqldump -u用户名 -p密码 数据库名>生成的脚本文件路径
例如:
mysqldump -uroot -proot day04>d:\day04.sql
以上备份数据库的命令中需要用户名和密码,即表明该命令要在用户没有登录的情况下使用
2.1.2 可视化工具备份
选中数据库,右键 ”备份/导出” , 指定导出路径,保存成.sql文件即可。
2.2 SQL恢复
数据库的恢复指的是使用备份产生的sql文件恢复数据库,即将sql文件中的sql语句执行就可以恢复数据库内容。
2.2.1 MySQL命令恢复
使用数据库命令备份的时候只是备份了数据库内容,产生的sql文件中没有创建数据库的sql语句,在恢复数据库之前需要自己动手创建数据库。
在数据库外恢复
格式:mysql -uroot -p密码 数据库名 < 文件路径
例如:mysql -uroot -proot day04
在数据库内恢复
格式:source SQL脚本路径
例如:source d:\day0401.sql
注意:使用这种方式恢复数据,首先要登录数据库.
2.2.2 可视化工具恢复
数据库列表区域右键“从SQL转储文件导入数据库”, 指定要执行的SQL文件,执行即可。
2.3 实际开发中数据库的备份方式
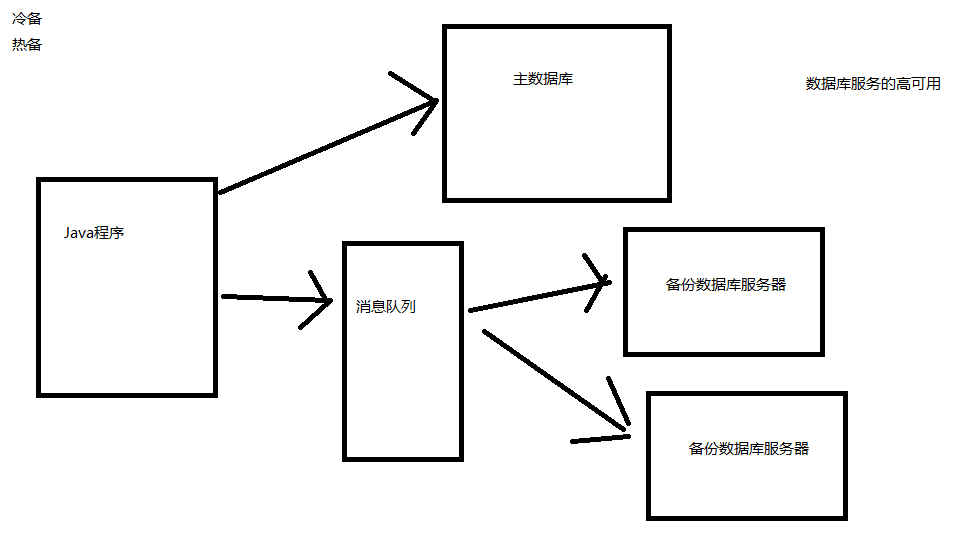
3 多表操作
3.1 一对多
3.1.1 关系图解
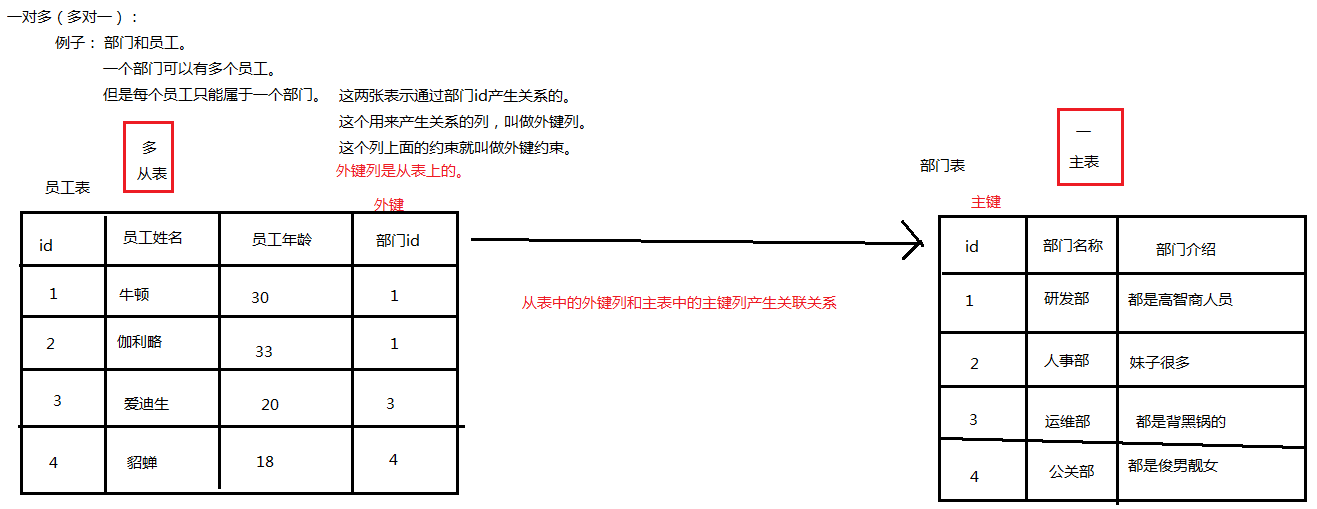
3.1.2 实现
/*
表与表一对多的关系。
部门和员工。
一个部门可以有多个员工,但是一个员工只能属于一个部门。
*/
# 创建部门表
CREATE TABLE department(
id INT PRIMARY KEY AUTO_INCREMENT,
dname VARCHAR(20), -- 部门名称
detail VARCHAR(20) -- 部门介绍
);
# 创建一个员工表
CREATE TABLE employee(
id INT PRIMARY KEY AUTO_INCREMENT,
ename VARCHAR(20), -- 员工姓名
age INT, -- 员工年龄
dep_id INT -- 员工所属部门id,用来和部门表产生关联关系,也是外键列
);
# 添加外键约束
# alter table 从表名 add [constraint 约束名称] foreign key (外键列名) references 主表名 (主表主键);
ALTER TABLE employee ADD FOREIGN KEY (dep_id) REFERENCES department (id);
# 添加数据
INSERT INTO department (dname, detail) VALUES ('研发部', '都是程序员');
INSERT INTO department (dname, detail) VALUES ('运维部', '都是网管');
INSERT INTO department (dname, detail) VALUES ('公关部', '都是高薪人员');
INSERT INTO employee (ename, age, dep_id) VALUES ('伽利略', 12, 1);
INSERT INTO employee (ename, age, dep_id) VALUES ('比尔盖茨', 42, 1);
INSERT INTO employee (ename, age, dep_id) VALUES ('扎克伯格', 30, 1);
INSERT INTO employee (ename, age, dep_id) VALUES ('张三丰', 130, 2);
INSERT INTO employee (ename, age, dep_id) VALUES ('川岛芳子', 23, 3);
-- 如果向从表中添加数据时,对应的外键在主表中是对应不存在的,那么就添加失败。
INSERT INTO employee (ename, age, dep_id) VALUES ('王叔叔', 50, 10);
-- 把员工表中id是5的员工删除掉
DELETE FROM employee WHERE id = 5;
-- 如果删除的是主表中的数据,如果这个数据被从表引用着,就不能删除。
-- 想要删除一个部门,必须把这个部门下面的所有员工全部删除,然后再删除部门。
DELETE FROM department WHERE id = 1;
3.2 多对多
3.2.1 关系图解
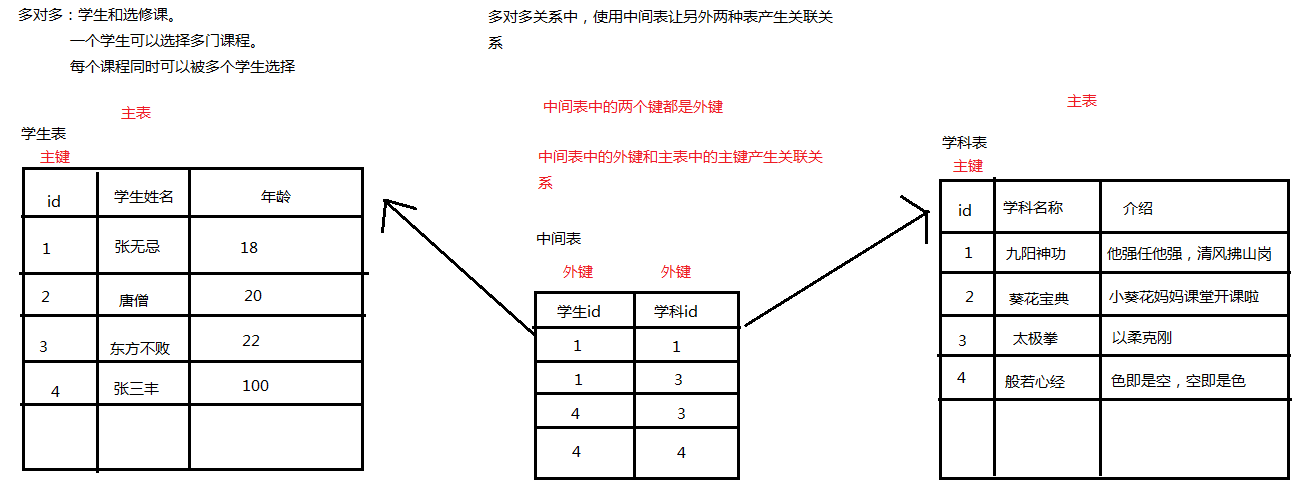
3.2.2 实现
/*
多对多关系实现
学生和选修课,
一个学生可以选择多个课程。
同时一个课程可以被多个学生选择。
建立三张表。
学生表。
学科表。
中间表。 中间表用来和另外两张表产生关联关系。
如果关键字当做表名或者字段名,建议加上``
外键约束的作用是保证的完整性。
*/
# 创建学生表
CREATE TABLE student(
id INT PRIMARY KEY AUTO_INCREMENT,
sname VARCHAR(20), -- 学生姓名
age INT -- 学生年龄
);
# 创建学科表
CREATE TABLE `subject` (
id INT PRIMARY KEY AUTO_INCREMENT,
sname VARCHAR(20), -- 学科名称
detail VARCHAR(20) -- 介绍
);
# 创建中间表
CREATE TABLE stu_sub (
stu_id INT, -- 对应的学生的id
sub_id INT -- 对应学科的id
);
# 添加外键约束。 外键约束要加载中间表上面。
# alter table 中间表 add [constraint 约束名称] foreign key (外键列) references 主表名 (主键);
# 将中间表中的stu_id 和 学生表中的主键id进行关联
ALTER TABLE stu_sub ADD FOREIGN KEY (stu_id) REFERENCES student (id);
# 将中间表中的sub_id 和学科表中的主键id进行关联
ALTER TABLE stu_sub ADD FOREIGN KEY (sub_id) REFERENCES `subject` (id);
# 添加数据
INSERT INTO student (sname, age) VALUES ('张无忌', 12);
INSERT INTO student (sname, age) VALUES ('张三丰', 14);
INSERT INTO student (sname, age) VALUES ('东方不败', 16);
# 学科表添加数据
INSERT INTO `subject` (sname, detail) VALUES ('九阳神功', '他横由他横,明月照大江');
INSERT INTO `subject` (sname, detail) VALUES ('葵花宝典', '小葵花妈妈课堂开课啦');
INSERT INTO `subject` (sname, detail) VALUES ('太极拳', '以柔克刚');
# 向中间表添加数据。
INSERT INTO stu_sub (stu_id, sub_id) VALUES (1, 1);
INSERT INTO stu_sub (stu_id, sub_id) VALUES (1, 3);
INSERT INTO stu_sub (stu_id, sub_id) VALUES (2, 3);
# 往中间表添加数据
# 如果向中间表添加数据,如果中间表中的外键在主表中的主键是不存在的,那么就添加失败。
INSERT INTO stu_sub (stu_id, sub_id) VALUES (12, 13);
# 删除
# 如果删除的是主表数据,如果主表中的主键被中间表引用着,那么不能删除。
DELETE FROM student WHERE id = 1;
3.3 一对一(了解)
实际场景极其少见。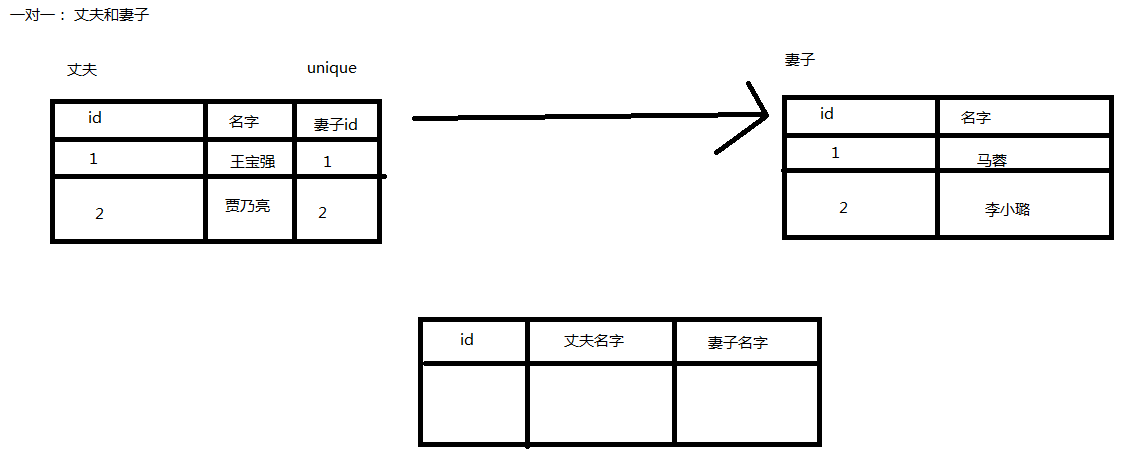
(插播:
如果关键字当作表名或者字段名,建议用重音符包括起来。 叫重音符。
)

若有收获,就点个赞吧
0 人点赞
