堆是一种特殊的树,需要满足两个条件:
- 堆是一个完全二叉树,也就是说除了最后一层,其他层的节点都是满的,并且最后一层的节点都靠左排列
- 堆中每个节点的值都大于等于(或小于等于)左右子节点的值;
其中大于等于子节点的堆我们称最大堆,反之是最小堆。最大堆的根节点是整个树中的最大元素,最小堆的根节点则是整个树中的最小元素。
堆的最佳存储方式是数组,因为通过数组下标即可找到任一节点的父节点,左右子节点。而不需要额外空间存储左右子节点的指针。
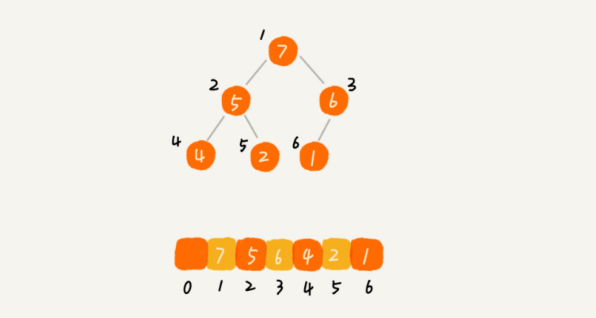
从图中我们可以看到,数组中下标为 i 的节点的左子节点,就是下标为 2i 的节点,右子节点就是下标为 2i+1 的节点,父节点就是下标为 i / 2 的节点。(当然根节点也可以从0开始,不过使用1的人更常见)
下面用代码创建了一个堆,但是这个堆很明显还没有堆化:(例子是从1开始)
class Heap {constructor(data, Max = 10000){ // max 表示容量this.list = Array(Max)for(let i = 0; i < data.length; i++) {this.list[i+1] = data[i]}this.heapSize = data.length // 堆的实际大小}}const heap = new Heap([2,5,8,3,7,12,9,6])console.log(heap.list) // [ <1 empty item>, 2, 5, 8, 3, 7, 12, 9, 6, <9991 empty items> ]
其实建堆,最重要的操作就是堆化,那么如何堆化呢?
有两种思路:
- 思路1:先按照上面的代码,先创建二叉树,然后再使用方法把这个二叉树进行堆化,使其变成满足条件的堆。
思路是:自下往上,我们对整个堆的最后一个子节点(也可以理解成一个三角子树,包含两个节点或三个节点)进行交换,使其满足堆的性质,然后再递归,只要把所有子节点(非叶子节点,叶子节点本身只有一个节点,本来就是一个堆)递归完成就可以了,自下而上的进行。那么我们就需要获取到堆的最后一个节点索引。观察堆的结构就能发现规律,其实最后一个子节点(非叶子节点)的索引(从1开始计数)就是 Math.floor(this.heapSize / 2)。
class Heap {constructor(data, Max = 10000) {this.list = Array(Max)for (let i = 1; i <= data.length; i++) {this.list[i] = data[i-1]}this.heapSize = data.lengththis.build()}build() {// 获取最后一个子节点的索引,注意不是叶子节点let i = Math.floor(this.heapSize / 2)while (i > 0) {this.max_heapify(i--)}}max_heapify(i) {//其实这个方法有些地方也叫shiftDown , 只不过这里是用递归写的,下面会有个while循环的写法const leftIndex = 2 * iconst rightIndex = 2 * i + 1let maxIndex = leftIndex // 左子节点是一定存在的,否则就不是子节点而是叶子节点if (rightIndex <= this.heapSize &&this.list[rightIndex] > this.list[leftIndex]) {maxIndex = rightIndex}if (this.list[maxIndex] > this.list[i]) {swap(this.list, maxIndex, i)this.max_heapify(maxIndex) // 这一步很关键,因为换位后需要重新递归堆化换位后的元素是否满足}}}function swap(A, i, j) {const t = A[i]A[i] = A[j]A[j] = t}const heap = new Heap([2,5,8,3,7,12,9,6])console.log(heap.list)// [ <1 empty item>, 12, 7, 9, 6, 5, 8, 2, 3, <9991 empty items> ]
上面代码的图展示: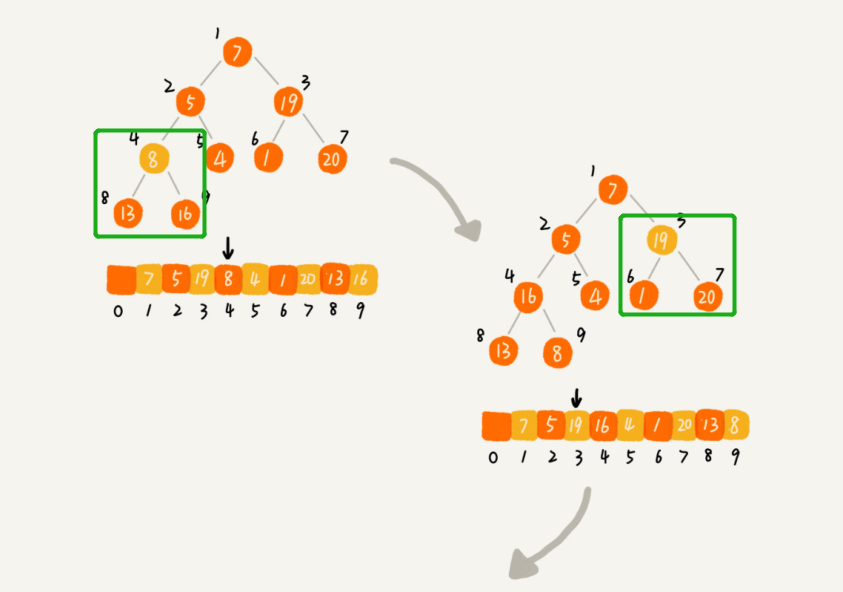
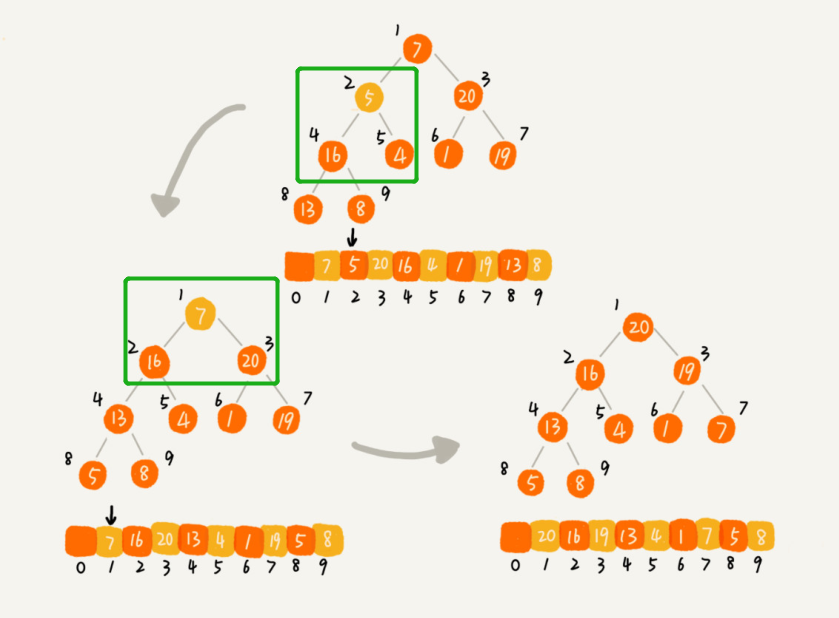
- 思路2:刚上面我们是先把数据构建出一个二叉树,再进行堆化操作使之满足堆的定义。我们现在选择边插入边进行堆化的过程。这个过程也叫 shiftUp。这样思路也是很简单的。我们每次只要把插入的元素跟父节点~~(i/2)进行比较,如果父节点小则交换,交换后记得递归一直往上冒泡,否则无需任何操作。shiftUp 相对简单很多。
class Heap {constructor(data, Max = 10000) {this.list = Array(Max)// 注意这里是从索引1开始的,主要是方便下面取父节点的索引 ~~(i / 2)for (let i = 1; i <= data.length; i++) {this.list[i] = data[i-1]// 每次插入就进行最大堆化this.shiftUp(i)}this.heapSize = data.length}shiftUp(i){while (i > 1 && this.list[i] > this.list[~~(i / 2)]) {swap(this.list, i, ~~(i / 2))i = ~~(i / 2)}}}const heap = new Heap([2, 5, 8, 3, 7, 12, 9, 6])// [12, 7, 9, 6, 3, 5, 8, 2] 注意这个结果跟上面的结果有差异的
上面的两种建堆方法,相比而言,第一种性能更好。第一种方法的时间复杂度是O(n)的,第二种方法的时间复杂度是O(nlogn)。
删除一个元素:
当我们从堆顶删除一个元素后,堆是不满足最大堆的定义的,所以我们需要堆化,为了避免数组在删除过程中产生‘空洞’,我们每次在删除堆顶元素后,把最后一个元素移上来,并且将堆的大小 -1(this.heapSize-1),以维持堆的大小。然后再对堆进行堆化(思路是将节点跟左右子节点中较大的值进行比较,如果当前节点比子节点中的较大值小就需要交换位置,如此下沉,直到最后一个元素),这个堆化过程因为是自上而下的,所以叫 shiftDown。
其实我们在上面讲的堆化的第一个思路使用的 max_heapify 方法就是 shiftDown 的思路,只不过是采用递归实现的。这里为了区分,使用 while 循环实现一次。
我们的思路是将当前节点(从根节点开始)跟左右两子节点中较大值比较。如果当前节点小的话就交换位置。使用while 循环其实我们只需要一个判断,就是判断当前节点是否有左子节点即可(不超过堆的总大小),因为有右节点是一定有左节点的,只要有左子节点就要继续循环下去。
shiftDown:
class Heap {constructor(data, Max = 10000) {this.list = Array(Max)// 注意这里是从索引1开始的,主要是方便下面取父节点的索引 ~~(i / 2)for (let i = 1; i <= data.length; i++) {this.list[i] = data[i - 1]// 每次插入就进行最大堆化this.shiftUp(i)}this.heapSize = data.length}shiftUp(i) {while (i > 1 && this.list[i] > this.list[~~(i / 2)]) {swap(this.list, i, ~~(i / 2))i = ~~(i / 2)}}shiftDown(i) {// 循环的条件是只要当前节点有左子节点就需要比较while (2 * i <= this.heapSize) {// 默认左子节点是最大值索引let maxIndex = 2 * i// 判断右节点是否存在,且如果比左子节点大则取其索引if (maxIndex + 1 <= this.heapSize &&this.list[maxIndex + 1] > this.list[maxIndex]) {maxIndex = 2 * i + 1}// 如果当前节点比左右子节点中的最大值都大说明已经满足最大堆条件,就不用循环了if (this.list[i] > this.list[maxIndex]) {break}// 否则交换位置,并且继续往下判断swap(this.list, i, maxIndex)i = maxIndex}}extract() {if (this.heapSize === 0) return nullconst item = this.list[1]// 将堆中最后一个元素跟第一个元素交换位置swap(this.list, 1, this.heapSize)// 将堆的大小减1this.heapSize--this.shiftDown(1)return item}}const heap = new Heap([2, 5, 8, 3, 7, 12, 9, 6])console.log(heap.list) // [12, 7, 9, 6, 3, 5, 8, 2]console.log(heap.extract())console.log(heap.list) // 9, 7, 8, 6, 3, 5, 2
其实上面的逻辑已经把堆排序的逻辑讲明白了,每次我们只要调用heap.extract()即可取出堆顶的最大值,并进行堆化。
堆排序:
堆排序方法1:
只要在上面的代码上加一个方法即可:
function heapSort(A) {const heap = new Heap(A)while (heap.heapSize > 0) {A[heap.heapSize - 1] = heap.extract()}}let A = [2, 5, 8, 3, 7, 12, 9, 6]heapSort(A)console.log(A) // [ 2, 3, 5, 6, 7, 8, 9, 12 ]
上面heapSort函数中的while循环的结束条件修改一下,就可以取出数组中前k大的元素。
比如:
function maxk(A, k) {const heap = new MaxHeap(A)const r = []// 取k次就能取出前k大的元素集合while (k-- > 0) {r.push(heap.extract())}return r}
堆排序方法2:
简单吧。上面的排序是基于先建堆,再堆化的过程的,这个过程需要O(n)的空间。其实我们可以直接把数组当成一个堆来看,直接堆化,然后把堆顶的最大元素跟最后一个元素交换位置,这个时候树是不满于堆的条件的,我们再堆化。如此循环。直到最后一个元素。
function heapSort(A, size = A.length) {// 先堆化let lastNodeIndex = ~~((size - 1) / 2)while (lastNodeIndex >= 0) {shiftDown(A, lastNodeIndex--, size)}console.log(A);// 排序while (size > 1) {// 直接把堆顶跟最后一个元素交换位置,最大值就到了最后位置上,然后把堆的 size-1,再堆化swap(A, size - 1, 0)size--shiftDown(A, 0, size)}}function shiftDown(A, i, n) {while (2 * i + 1 < n) {// 同样无需判断左子节点是否存在,因为作为非叶子节点是肯定有左子节点的。let maxIndex = 2 * i + 1if (2 * i + 2 < n && A[2 * i + 2] > A[2 * i + 1]) maxIndex += 1if (A[i] > A[maxIndex]) breakswap(A, i, maxIndex)i = maxIndex}}function swap(A, i, j) {;[A[i], A[j]] = [A[j], A[i]]}let A = [2, 5, 8, 3, 7, 12, 9, 6]heapSort(A)console.log(A)
堆排序为什么没有快速排序性能好?
第一点,堆排序数据访问的方式没有快速排序友好。在讲数组的时候,有提到cpu对数组有预读机制,有缓存的概念
第二点,对于同样的数据,在排序过程中,堆排序算法的数据交换次数要多于快速排序。
建堆的过程会打乱数据原有的相对先后顺序,导致原数据的有序度 降低。比如,对于一组已经有序的数据来说,经过建堆之后,数据反而变得更无序了。
那么可以减少交换操作吗?
答案是有的,我们可以参照插入排序的思路,在寻找插入位置的时候,并不进行位置交换,而只是把数组往后移动,记录可能插入的位置。
代码如下:
shiftDown(i) {+ let x = this.list[i] // 缓存需要插入的值xwhile (2 * i <= this.heapSize) {let maxIndex = 2 * iif (maxIndex + 1 <= this.heapSize &&this.list[maxIndex + 1] > this.list[maxIndex]) {maxIndex = 2 * i + 1}// 每次用子节点中的较大值跟x比较if (x > this.list[maxIndex]) {break}- // swap(this.list, i, maxIndex)// 关键步骤在这里,我们每次找到较大值后,用这个较大值替换i位置上的值+ this.list[i] = this.list[maxIndex]i = maxIndex}// 最后只要把我们需要插入的位置i赋上x即可this.list[i] = x}
思考题:如何从1百万的数据中选出前k(100)名最大的元素呢?
思路就是:我们维护一个大小为100的最小堆,先从100万数据中取前100个元素放入这个堆,然后遍历剩下的数据,如果元素比堆顶元素大就把堆顶元素删除,并将这个元素插入堆中;如果比堆顶元素小,则无需处理。直到遍历完100万的数据后,堆里面的100个元素其实就是我们要的结果。这个时间复杂度是O(nlogk)的,相比于归并,快排的O(nlogn)要优化不小。
堆这种数据结构更多的是用来做动态数据(频繁的删除,插入数据等)的维护。堆排序的效率比归并排序,比快速排序差那么一点。
索引堆
索引堆,顾名思义,与上面普通堆的最大区别就是在对堆进行数据交换的时候,不再是原数组中的元素交换,而是索引,只交换索引,交换的效率就大大提高了。
索引堆的引入主要有两个原因:
为了保存原数组的索引,方便后续的随机访问,比如优先队列把,我们就可能需要提升原数组某个任务的优先级。
相比之前的堆化等操作,索引堆可以减小交换操作的消耗,尤其是对于元素交换需要很多资源的对象来说,比如如果每个元素都是存储着十万级别的字符串文本。
function swap(A, i, j) {[A[i], A[j]] = [A[j], A[i]]}class IndexHeap {constructor(data, Max = 10000) {this.indexList = Array(Max)this.data = Array(data.length)// 注意这里是从索引1开始的,主要是方便下面取父节点的索引 ~~(i / 2)for (let i = 1; i <= data.length; i++) {this.indexList[i] = i// 内部维护一个新数组 索引从1开始this.data[i] = data[i - 1]// 每次插入就进行最大堆化this.shiftUp(i)}this.heapSize = data.length}shiftUp(i) {// 注意这里比较的是数组里面的元素while (i > 1 && this.data[this.indexList[i]] > this.data[this.indexList[~~(i / 2)]]) {swap(this.indexList, i, ~~(i / 2))i = ~~(i / 2)}}shiftDown(i) {// 循环的条件是只要当前节点有左子节点就需要比较while (2 * i <= this.heapSize) {// 默认左子节点是最大值索引let maxIndex = 2 * i// 判断右节点是否存在,且如果比左子节点大则取其索引if (maxIndex + 1 <= this.heapSize &&// 注意这里比较的是数组里面的元素this.data[this.indexList[maxIndex + 1]] > this.data[this.indexList[maxIndex]]) {maxIndex = 2 * i + 1}// 如果当前节点比左右子节点中的最大值都大说明已经满足最大堆条件,就不用循环了if (this.indexList[i] > this.indexList[maxIndex]) {break}// 否则交换位置,并且继续往下判断swap(this.indexList, i, maxIndex)i = maxIndex}}extract() {if (this.heapSize === 0) return nullconst item = this.data[this.indexList[1]]// 将堆中最后一个元素跟第一个元素交换位置swap(this.indexList, 1, this.heapSize)// 将堆的大小减1this.heapSize--this.shiftDown(1)return item}// 通过索引可以修改原数组值,比如想提高某个进程的优先级。这个方法比较重要// change方法的关键就是要找到data[i+1]中索引i+1 ,然后才能堆化change(i, value) {// 内部的数组是从1开始的this.data[i + 1] = value// 重新堆化// 必须要找到元素的索引i+1在索引堆indexList中对应的位置jfor(let j=1;j<=this.heapSize;j++){if(this.indexList[j] === i+1){this.shiftDown(j)this.shiftUp(j)break}}}}function heapSort(A) {const heap = new IndexHeap(A)while (heap.heapSize > 0) {A[heap.heapSize - 1] = heap.extract()}}let A = [2, 5, 8, 3, 7, 12, 9, 6]const heap = new IndexHeap(A)heapSort(A)console.log(A);heap.change(3,28)console.log(heap.indexList);
上面的change方法为了找到data[i]的索引在堆中的位置j,必须进行循环遍历。时间复杂度是O(n)的。有没有方法可以O(1)就能找到这个位置j呢?
思路就是:如果我们把data[i]中的索引i在堆中的位置j用一个数组(比如reverse)来记录,是不是可以直接通过reverse[i]就能找到j了?即j=reverse[i]。
所以我们需要在每一次对indexList数组赋值的操作时,通过reverse数组来记录data[i]中索引i在堆中的位置
function swap(A, i, j) {[A[i], A[j]] = [A[j], A[i]]}class IndexHeap {constructor(data, Max = 10000) {this.indexList = Array(Max)// 内部维护一个新数组 索引从1开始this.data = Array(data.length)// 维护一个data[i]的索引i在indexList中的位置的数组reverse。这样在需要改变data数据时就不用去遍历indexList// reverse数组其实就是indexList数组的元素跟索引的一个反转。即indexList[j]=i reverse[i]=j// 这里初始化为0,因为我们的数组都是从1开始的,所以0说明data[i]中的i在堆中不存在,这个在取出堆顶元素交换位置的时候需要用到+ this.reverse = [...Array(data.length).keys()].map(n=>0)// 注意这里是从索引1开始的,主要是方便下面取父节点的索引 ~~(i / 2)for (let i = 1; i <= data.length; i++) {this.indexList[i] = i// 索引从1开始this.data[i] = data[i - 1]// 维护rev数组this.reverse[i] = i// 每次插入就进行最大堆化this.shiftUp(i)}this.heapSize = data.length}shiftUp(i) {// 注意这里比较的是数组里面的元素while (i > 1 && this.data[this.indexList[i]] > this.data[this.indexList[~~(i / 2)]]) {swap(this.indexList, i, ~~(i / 2))// 维护rev数组+ this.reverse[this.indexList[i]] = i+ this.reverse[this.indexList[~~(i / 2)]] = ~~(i / 2)i = ~~(i / 2)}}shiftDown(i) {// 循环的条件是只要当前节点有左子节点就需要比较while (2 * i <= this.heapSize) {// 默认左子节点是最大值索引let maxIndex = 2 * i// 判断右节点是否存在,且如果比左子节点大则取其索引if (maxIndex + 1 <= this.heapSize &&// 注意这里比较的是数组里面的元素this.data[this.indexList[maxIndex + 1]] > this.data[this.indexList[maxIndex]]) {maxIndex = 2 * i + 1}// 如果当前节点比左右子节点中的最大值都大说明已经满足最大堆条件,就不用循环了if (this.indexList[i] > this.indexList[maxIndex]) {break}// 否则交换位置,并且继续往下判断swap(this.indexList, i, maxIndex)// 维护rev数组+ this.reverse[this.indexList[i]] = i+ this.reverse[this.indexList[maxIndex]] = maxIndexi = maxIndex}}extract() {if (this.heapSize === 0) return nullconst item = this.data[this.indexList[1]]// 将堆中最后一个元素跟第一个元素交换位置swap(this.indexList, 1, this.heapSize)// 维护rev数组+ this.reverse[this.indexList[1]] = 1// +++ 注意这里是0,因为取出一个元素后,堆的大小要减1,就是交换后的最后一个元素已经不参与堆的计算了+ this.reverse[this.indexList[this.heapSize]] = 0// 将堆的大小减1this.heapSize--youxianduithis.shiftDown(1)return item}// 通过索引可以修改原数组值,比如想提高某个进程的优先级,change方法就是实现优先队列的思路change(i, value) {// 内部的数组是从1开始的this.data[i + 1] = value// 重新堆化// 必须要找到元素的索引i+1在索引堆indexList中对应的位置j// for(let j=1;j<=this.heapSize;j++){// if(this.indexList[j] === i+1){// console.log(j);// this.shiftDown(j)// this.shiftUp(j)// break// }// }let j = this.reverse[i + 1]console.log(j);this.shiftDown(j)this.shiftUp(j)}}function heapSort(A) {const heap = new IndexHeap(A)while (heap.heapSize > 0) {A[heap.heapSize - 1] = heap.extract()}}let A = [2, 5, 8, 3, 7, 12, 9, 6]const heap = new IndexHeap(A)console.log(heap.indexList);heap.change(3, 28)console.log(heap.indexList);
上面代码有两个需要注意的:
- 因为内部的data,indexList索引都是从1开始的,所以在初始化reverse数组的时候给所有元素用0填充了表示位置不存在。因为0是表示位置不存了。
- 在extract方法中,取出堆顶元素交换后要把最后一个元素在reverse中的值置为0.
上面的实现其实已经回答了如何用堆实现优先队列的思路,change方法就是关键。
堆的应用:
优先级队列
前面讲过普通队列就是先进先出的顺序,但是优先级队列是按优先级来的,优先级最高的先出列。
有很多方式可以实现优先级队列,但使用堆来实现最直接,高效。堆和优先队列很相似,一个堆完全可以看做一个优先级队列,很多时候,只是概念上的区分。
优先级队列的应用场景有很多。比如,赫夫曼编码、图的最短路径、最小生成树算法等等。不仅如此,很多语言中,都提 供了优先级队列的实现,比如,Java 的 PriorityQueue,C++ 的 priority_queue 等。
1、合并有序小文件
假设有100个有序的小文件。每个文件的大小100MB,每个文件中存储的都是有序的字符串。如何将这100个小文件合并成一个有序的大文件呢?
首先使用数组来解决。这个过程很类似我们的归并排序的合并函数。我们先创建一个大小100的数组,从100个文件中,各取第一个字符,放入数组,然后比较大小,然后把最小的字符串放入合并后的大文件中,并从数组中删除。假设这个字符串来自a.txt文件,那我们继续从a.txt文件中取下一个字符串,放入到数组中,重新比较大小,并且把最小的字符串放入到大文件,然后把它从数组中删除。递归上面的操作,直到100个小文件全部放入大文件中。
显然数组也能愉快的解决这个问题,但上面还有个可以优化的地方,就是每次重新比较大小的时候,需要排序,需要遍历整个数组,显然效率没那么高。如何解决呢?
就是优先级队列。也就是堆。我们创建一个大小100的最小堆。按照上面的思路,我们先取100个字符串放入小顶堆(最小堆),然后堆化,那么堆顶的元素就是最小的字符串。并将这个字符串放入到大文件中,然后从堆中删除。继续从刚删除来了的字符串的文件中取出下一个字符串。重复上面的操作。直到100个文件全部写入大文件。
2、高性能的定时器
假设有一个定时器,定时器中维护了很多定时任务,每个任务都有一个触发执行的时间点。假设我们每隔1s就扫描一遍任务,若有到达时间的任务就取出执行。
但是这个时间间隔怎么确定呢?第一:任务的执行时间都是不确定的,可能要隔很久才能执行,这样很多次扫描都是无用的;第二:每次都需要重复扫描这个任务列表,效率很低。
为了解决上面的问题,可以使用优先队列。我们按照任务设定的执行时间,将这些任务储存在优先队列中,队列首部,也就是小顶堆的堆顶,存储的就是最先执行的任务。这样,只要取堆顶任务执行时间点跟当前时间比较,然后倒计时这个时间就可以了。
使用堆求Top K
Top K 的问题分成两类:一类是针对静态数据集合,也就是说数据集合事先确 定,不会再变。另一类是针对动态数据集合,也就是说数据集合事先并不确定,有数据动态地加 入到集合中。
针对静态数据,如何在一个包含 n 个数据的数组中,查找前 K 大数据呢?我们可以维护一个大 小为 K 的小顶堆,顺序遍历数组,从数组中取出取数据与堆顶元素比较。如果比堆顶元素大, 我们就把堆顶元素删除,并且将这个元素插入到堆中;如果比堆顶元素小,则不做处理,继续遍 历数组。这样等数组中的数据都遍历完之后,堆中的数据就是前 K 大数据了。
遍历数组需要 O(n) 的时间复杂度,一次堆化操作需要 O(logK) 的时间复杂度,所以最坏情况 下,n 个元素都入堆一次,所以时间复杂度就是 O(nlogK)。
针对动态数据求得 Top K 就是实时 Top K。怎么理解呢?我举一个例子。一个数据集合中有两 个操作,一个是添加数据,另一个询问当前的前 K 大数据。 如果每次询问前 K 大数据,我们都基于当前的数据重新计算的话,那时间复杂度就是 O(nlogK),n 表示当前的数据的大小。实际上,我们可以一直都维护一个 K 大小的小顶堆,当 有数据被添加到集合中时,我们就拿它与堆顶的元素对比。如果比堆顶元素大,我们就把堆顶元 素删除,并且将这个元素插入到堆中;如果比堆顶元素小,则不做处理。这样,无论任何时候需 要查询当前的前 K 大数据,我们都可以里立刻返回给他。
利用堆求动态数据集合的中位数
中位数就是中间位置的数,如果数据个数是奇数就返回第n/2+1个数据。如果是偶数,中位数就有两个n/2和n/2+1。
如果是静态数据,我们只要排序一次,然后就可以直接找到中位数。但是如果是动态数据,中位数是不变动的。如果每次都先排序,效率就很低了。
那么使用堆如何实现呢?非常巧妙
我们需要维护两个堆,一个大顶堆,一个小顶堆。大顶堆中存储前半部分数据,小顶堆中存储后 半部分数据,且小顶堆中的数据都大于大顶堆中的数据。
也就是说,如果有 n 个数据,n 是偶数,我们从小到大排序,那前 n/2个数据存储在大顶堆中, 后 n/2个数据存储在小顶堆中。这样,大顶堆中的堆顶元素就是我们要找的中位数。如果 n 是奇 数,情况是类似的,大顶堆就存储 n/2+1个数据,小顶堆中就存储 n/2个数据。
但是如果是动态的数据呢?如何调整两个堆,让大顶堆中的堆顶元素继续是中位数呢?
思路是:
如果新加入的数据小于等于大顶堆的堆顶元素,我们就将这个新数据插入到大顶堆;如果新加入 的数据大于等于小顶堆的堆顶元素,我们就将这个新数据插入到小顶堆。
这个时候就有可能出现,两个堆中的数据个数不符合前面约定的情况:如果 n 是偶数,两个堆中 的数据个数都是 ;如果 n 是奇数,大顶堆有 个数据,小顶堆有 个数据。这个时 候,我们可以从一个堆中不停地将堆顶元素移动到另一个堆,通过这样的调整,来让两个堆中的 数据满足上面的约定。
于是,我们就可以利用两个堆,一个大顶堆、一个小顶堆,实现在动态数据集合中求中位数的操 作。插入数据因为需要涉及堆化,所以时间复杂度变成了 O(logn),但是求中位数我们只需要返 回大顶堆的堆顶元素就可以了,所以时间复杂度就是 O(1)。
类似中位数的还有:
如何快速求接口的99%响应时间?
其实也是把100个接口按响应时间排序,从小到大,排在第99位的数据就是99%响应时间。思路跟上面的中位数一样的,还是创建两个堆,然后通过调节保持两个堆的比例就可以。
如何从1亿搜索关键词中快速获取Top10热门关键词?
思路跟从100万数据中取前k大的数据一样的思路。先统计词频,然后我们维护一个大小为10的最小堆。依次取出每个搜索关键词及对应出现的次数,然后与堆顶的搜索关键词对比。如果出现次数比堆 顶搜索关键词的次数多,那就删除堆顶的关键词,将这个出现次数更多的关键词加入到堆中。
上面的举例其实都是用到了一个很关键的点,就是堆在进行最大堆化,或者最小堆化操作的时候,时间复杂度是O(logn)。相比于数组的O(n)是很大的优化。

若有收获,就点个赞吧
0 人点赞
