认识字符串
不可变数据类型,即字符串不可修改
- 成对引号(单引号、双引号) 来创建字符串
- 六个单 / 双引号来创建,用于换行书写字符串
- 要赋值给一个变量
如: a = ‘hello’,a = “python”,a = ‘’’world’’’、a = “””python”””
字符串输出
输出
```pythona = '''helloworld'''-------------------------->>> helloword
三引号的区别在于,三引号支持换行(不会显示或添加换行符)用于大文本。如果不想换行,则在每行末尾添加 「 \ 」
a = " I'm a boy "-------------------------->>> I'm a boy
单双引号混合写,用于引用或者英文
转义
a = 'I\'m a boy'-------------------------->>> I'm a boy
斜杠 「 \ 」 进行转义
加乘
a = 'hello'b = 'python'c = a + bprint(c)----------------------->>> 'hellopython'
a = 'hello'b = 2c = a * bprint(c)----------------------->>> 'hellohello'
在字符串中 「 + 」是拼接符的作用,「 * 」是复制的作用
r
原字符输出,在字符串前加 r,可保持原始字符串输出
a = r'I'm \n a boy'-------------------------->>> I'm \n a boy
斜杠 「 \ 」 进行转义
字符串属性
索引
语法: str[ index ],返回的是下标对应元素的字符串,字符串的正值索引默认从 0 开始从左到右,负值索引默认从 -1 开始从右到左。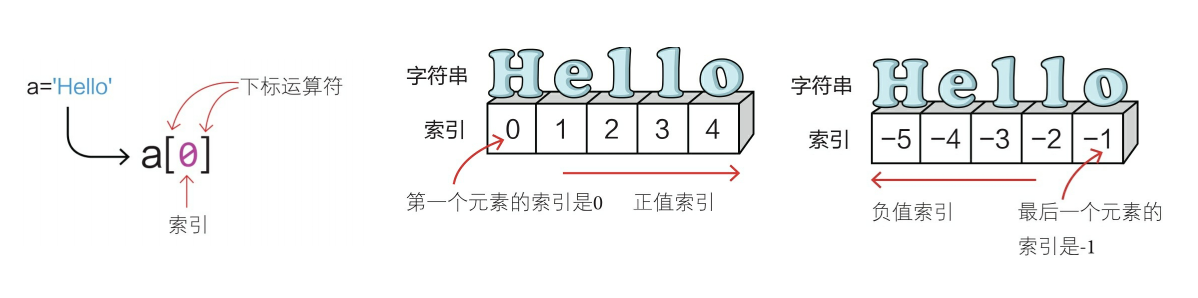
a = 'Hello'print(a[1])print(a[-5])print(a[5])---------------------------------------------------------------------->>> e>>> H>>> IndexError: string index out of range # 超过索引范围会报错
切片
对操作的对象截取其中一部分的操作,字符串、列表、元组都支持切片操作
- 语法: str [ start: end: step]
- start: 切片操作包含开始位置的元素。正数索引表示从左到右默认从 0 开始取元素,负数索引表示从右到左默认从 -1 开始取元素
- end: 切片操作不包含结束位置的元素。
- step: 代表每次取值的跨度,不写表示默认是 1。步长为负数,表示倒序(从右往左)选取数据
- 选取方向和步长的方向冲突,则无法选取数据
```python
a = ‘hello’ a[1: 3] a[: 3] # 省略开始索引,默认开始索引是 0,即 [: 3]与[0: 3]结果是一样的 a[0: ] # [0: ] 和 [:],结果也是一样的 a[:] a[: -1] # 负值索引,结果也可以看出不包含结束位置的元素 a[1: -1]
a[-4: -2] a[:: -1] a[1: 4: -1] # 选取方向与步长方向冲突,无法取值
‘el’ ‘hel’ ‘hello’ ‘hello’ ‘hell’ ‘ell’ ‘el’ ‘olleh’ ‘’ ```
字符串方法
修改
- replace()
- 字符串序列.replace( 旧子串, 新子串, 【 替换次数 】 )
- 如果查出子串次数,则替换次数为子串出现次数
- replace 返回值是修改后的字符串(赋值给变量),不会修改原来字符串
mystr = 'hello world and my baby'new_str = mystr.replace('o', 'a', 1)) # 指定次数替换print(new_str)
如果不写替换次数,默认全部替换
- split()
- 字符串序列.split( 分割字符,【 num 】)
- num 表示分割次数(即将来返回数据个数为 num+1 个)
- split() 返回是列表 ```python mytitle = ‘I Love Python and I Love Code’ new_mytitle = mytitle.split(‘ ‘, 2) print(new_mytitle)
[‘I’, ‘Love’, ‘Python and I Love Code’] ```
- join()
- 字符或子串.join( 多字符串组成的子列 ),用一个字符或子串合并字符串
- 返回新的字符串 ```python mylist = [‘aa’, ‘bb’, ‘cc’] new_str = ‘…’.join(mylist) print(new_str)
aa…bb…cc ```
- 其他修改函数
- captilize(),字符串只有首字母转成大写,其他字母全部小写(即使非首字母是大写)
- title(),字符串每个首字母大写
- upper(),字符串小写转大写
- lower(),字符串大写转小写
- lstrip()、rstrip()、strip: 删除字符串 左边、右边、两边空格
- mystr.ljust/rjust/center(长度, 填充字符),左、右、两边对齐
查找
- find()
- 字符串序列.find( 子串, 【 开始位置下标,结束位置下标 】 )
- 字符串序列.rfind( 子串,开始位置下标,结束位置下标 ),查找方向从右侧开始
- 如果存在就返回子串开始的位置下标,否则返回 -1 ```python mystr = ‘hello world and my baby’ print(mystr.find(‘lo’)) # 查找 lo 位置
print(mystr.find(‘or’, 2, 9)) # 限定区间查找子串
print(mystr.find(‘ors’)) # 查找不到
- **index()**- 字符串序列**.index**(** 子串, 【 开始位置下标,结束位置下标 】**)- 同 find(),rfind()用法类似,唯一不同点在于返回结果不同- 如果存在就返回子串开始的位置下标,**否则返回错误**> 开始和结束位置下标可以省略,表示在整个字符串序列中查找<a name="I0e55"></a>#### 计量**计数**,用于获取子串在字符串中出现的次数- **count() **- 字符串序列**.count**( **子串, 【 开始位置下标,结束位置下标 】 **)- 如果存在就返回存在的次数,**否则返回 0**> 开始和结束位置下标可以省略,表示在整个字符串序列中查找出现的次数**计长**,用于获取子串在字符串中的长度- **len()**```python用 len() 获取一个字符串的最后一个字符fruit = 'banana'length = len(fruit)last = fruit[length-1]
len() 计长从 1 开始,而字符下标从 0 开始,因此要在字符长度上减去 1 才能获取下标
判断
startswith()
- 字符串序列.startswith( 子串,【 开始位置下标,结束位置下标 】 )
- 开始和结束位置下标可以省略,表示在整个字符串序列中查找
- 检查字符串以指定子串开头,是则返回 True,否则返回 False
endswith()
- 字符串序列.endswith( 子串,【 开始位置下标,结束位置下标 】 )
- 开始和结束位置下标可以省略,表示在整个字符串序列中查找
- 检查字符串以指定子串结尾,是则返回 True,否则返回 False
其它判断函数 ```python mystr = ‘hello python and worlf’
判断字符串是不是字母组成,注意不能空格
print(mystr.isalpha())
判断字符串是不是数字组成,注意不能有空格
print(mystr.isdigit())
判断字符串是不是数字、字母、空格组成
print(mystr.isalnum())
判断字符串是不是由空格(白)组成
print(mystr.isspace()) ```
判断真假,返回的结果是布尔型数据类型,存在返回 True,否则返回 False

若有收获,就点个赞吧
0 人点赞
