什么是随机森林
Random Forest(随机森林)是一种基于树模型的Bagging的优化版本,一棵树的生成肯定还是不如多棵树,因此就有了随机森林,解决决策树泛化能力弱的特点。(可以理解成三个臭皮匠顶过诸葛亮)
而同一批数据,用同样的算法只能产生一棵树,这时Bagging策略可以帮助我们产生不同的数据集。Bagging策略来源于bootstrap aggregation:从样本集(假设样本集N个数据点)中重采样选出Nb个样本(有放回的采样,样本数据点个数仍然不变为N),在所有样本上,对这n个样本建立分类器(ID3\C4.5\CART\SVM\LOGISTIC),重复以上两步m次,获得m个分类器,最后根据这m个分类器的投票结果,决定数据属于哪一类。
RF 思想
RF 使用多个 CART 决策树作为基学习器,然后不同树之间没有关联。当我们进行分类任务时,新的输入样本进入,就让森林中的每一棵决策树分别进行判断和分类,每个决策树会得到一个自己的分类结果,决策树的分类结果中哪一个分类最多,那么随机森林就会把这个结果当作最终的结果。
生成决策树的方法
用随机选择的特征,即使用Bagging方法。这么做的原因是:如果训练集中的某几个特征对输出结果有很强的预测性,那么这些特征会被每个决策树所应用,这样会导致树之间具有相关性,这样并不会减小模型的方差。
随机森林的建立过程
第一步:原始训练集中有N个样本,且每个样本有M维特征。从数据集D中有放回的随机抽取x个样本组成训练子集(bootstrap方法),一共进行w次采样,即生成w个训练子集。
第二步:每个训练子集形成一棵决策树,一共w棵决策树。而每一次未被抽到的样本则组成了w个oob(用来做预估)。
第三步:对于单个决策树,树的每个节点处从M个特征中随机挑选m(m
随机森林算法优缺点总结
随机森林是Bagging的一个拓展变体,是在以决策树为基学习器构建Bagging集成的基础上,进一步在决策树的训练过程中引入了随机属性选择。
随机森林简单、容易实现、计算开销小,在很多实际应用中都变现出了强大的性能,被誉为“代表集成学习技术水平的方法”。可以看出,随机森林对Bagging只做了小改动。并且,Bagging满足差异性的方法是对训练集进行采样;而随机森林不但对训练集进行随机采样,而且还随机选择特征子集,这就使最终集成的泛化性进一步提升。
随着基学习器数目的增加,随机森林通常会收敛到更低的泛化误差,并且训练效率是优于Bagging的。
优点:
- 训练可以高度并行化,对于大数据时代的大样本训练速度有优势。
- 由于可以随机选择决策树节点划分特征,这样在样本特征维度很高的时候,仍然能高效的训练模型。
- 在训练后,可以给出各个特征对输出的重要性。
- 由于采用了随机采样,训练出的模型的方差小,泛化能力强。
- 相对于Boosting系列的Adaboost和GBDT,RF实现比较简单。
- 对部分特征缺失不敏感。
缺点:
- 在某些噪声比较大的样本集上,RF模型容易陷入过拟合。
取值划分比较多的特征容易对RF的决策产生更大的影响,从而影响拟合的模型的效果。
为什么是有放回的抽样
保证样本间有重叠,若不放回,每个训练样本集及其分布都不一样,可能导致训练的各决策树差异性很大,最终多数表决无法“求同”。
为什么 RF 的训练效率优于 bagging
因为在个体决策树的构建过程中,Bagging使用的是“确定型”决策树,Bagging在选择划分属性时要对每棵树对所有特征进行考察,而随机森林仅仅考察一个特征子集。
随机森林需要剪枝吗?
不需要,后剪枝是为了避免过拟合,随机森林选择变量与树的数量,已经避免了过拟合,没必要去剪枝了。一般随机森林要控制的是树的规模,而不是树的置信度,剩下的每棵树需要做的就是尽可能的在自己所对应的数据(特征)集情况下尽可能的做到最好的预测结果。剪枝的作用其实被集成方法消解了,所以作用不大。
随机森林如何处理缺失值?
根据随机森林创建和训练的特点,随机森林对缺失值的处理还是比较特殊的。
首先,给缺失值预设一些估计值,比如数值型特征,选择其余数据的中位数或众数作为当前的估计值。
- 然后,根据估计的数值,建立随机森林,把所有数据放进随机森林里面跑一遍。记录每一组数据在决策树中一步一步分类的路径。
- 判断哪组数据和缺失值数据路径最相似,引入一个相似度矩阵,来记录数据之间的相似度,比如有N组数据,相似度矩阵大小就是N*N.
- 如果缺失值是类别变量,通过权重投票得到新估计值,如果是数值型变量,通过加权平均得到新的估计值,如此迭代,直到得到稳定的估计值。
随机森林的过拟合问题
交叉验证解决随机森林不会发生过拟合的原因
在建立每一棵决策树的过程中,有两点需要注意:采样和完全分裂。
随机森林有两个随机采样的过程,对输入的数据要进行行、列的采样。对于行采样,采用有放回的方式,也就是在采样得到的样本集合中,可能有重复的样本。假设输入样本为N个,那么采样样本也为N个。这样使得在训练的时候,每一棵树的输入样本都不是全部的样本,使得相对不容易出现over-fitting.
然后进行列采样,从M个特征中,选择m个(m<
一般的决策树还有剪枝的步骤,但是随机森林的两个随机采样的过程保证了随机性,所以就算不剪枝,也不会出现过拟合。
随机森林与梯度提升树(GBDT)的区别
随机森林:决策树+bagging=随机森林
梯度提升树:决策树+Boosting=GBDT
两者的区别在于bagging 与boosting之间的区别。
像神经网络这样为消耗时间的算法,bagging可通过并行节省大量的时间开销。
bagigng和boosting都可以有效地提高分类的准确性
bootstrap, boosting, bagging几种方法的联系
Rand forest与bagging的区别:
- Rand forest是选与输入样本的数目相同多的次数(可能一个样本会被选取多次,同时也会造成一些样本不会被选取到),而bagging一般选取比输入样本的数目少的样本;
- bagging是用全部特征来得到分类器,而rand forest是需要从全部特征中选取其中的一部分来训练得到分类器; 一般Rand forest效果比bagging效果好!
boosting:其中主要的是AdaBoost(AdaptiveBoosting)。初始化时对每一个训练例赋相等的权重1/n,然后用该学算法对训练集训练t轮,每次训练后,对训练失败的训练例赋以较大的权重,也就是让学习算法在后续的学习中集中对比较难的训练铡进行学习,从而得到一个预测函数序列h一⋯h其中h.也有一定的权重,预测效果好的预测函数权重较大,反之较小。最终的预测函数H对分类问题采用有权重的投票方式,对回归问题采用加权平均的方法对新示例进行判别。(类似Bagging方法,但是训练是串行进行的,第k个分类器训练时关注对前k-1分类器中错分的文档,即不是随机取,而是加大取这些文档的概率).
Bagging与Boosting的区别:
在于Bagging的训练集的选择是随机的,各轮训练集之间相互独立,而Boostlng的训练集的选择是独立的,各轮训练集的选择与前面各轮的学习结果有关;Bagging的各个预测函数没有权重,而Boosting是有权重的;Bagging的各个预测函数可以并行生成,而Boosting的各个预测函数只能顺序生成。对于象神经网络这样极为耗时的学习方法。Bagging可通过并行训练节省大量时间开销。
bagging和boosting都可以有效地提高分类的准确性。在大多数数据集中,boosting的准确性比bagging高。在有些数据集中,boosting会引起退化。
Bagging和Boosting的区别:
1)样本选择上:
Bagging:训练集是在原始集中有放回选取的,从原始集中选出的各轮训练集之间是独立的。
Boosting:每一轮的训练集不变,只是训练集中每个样例在分类器中的权重发生变化。而权值是根据上一轮的分类结果进行调整。
2)样例权重:
Bagging:使用均匀取样,每个样例的权重相等
Boosting:根据错误率不断调整样例的权值,错误率越大则权重越大。
3)预测函数:
Bagging:所有预测函数的权重相等。
Boosting:每个弱分类器都有相应的权重,对于分类误差小的分类器会有更大的权重。
4)并行计算:
Bagging:各个预测函数可以并行生成
Boosting:各个预测函数只能顺序生成,因为后一个模型参数需要前一轮模型的结果。
为什么说bagging是减少variance,而boosting是减少bias?
Bagging对样本重采样,对每一重采样得到的子样本集训练一个模型,最后取平均。由于子样本集的相似性以及使用的是同种模型,因此各模型有近似相等的bias和variance(事实上,各模型的分布也近似相同,但不独立)。由于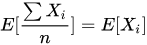 ,所以bagging后的bias和单个子模型的接近,一般来说不能显著降低bias。另一方面,若各子模型独立,则有
,所以bagging后的bias和单个子模型的接近,一般来说不能显著降低bias。另一方面,若各子模型独立,则有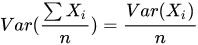 ,此时可以显著降低variance。若各子模型完全相同,则
,此时可以显著降低variance。若各子模型完全相同,则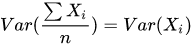 ,此时不会降低variance。bagging方法得到的各子模型是有一定相关性的,属于上面两个极端状况的中间态,因此可以一定程度降低variance。为了进一步降低variance,Random forest通过随机选取变量子集做拟合的方式de-correlated了各子模型(树),使得variance进一步降低。
,此时不会降低variance。bagging方法得到的各子模型是有一定相关性的,属于上面两个极端状况的中间态,因此可以一定程度降低variance。为了进一步降低variance,Random forest通过随机选取变量子集做拟合的方式de-correlated了各子模型(树),使得variance进一步降低。
(用公式可以一目了然:设有i.d.的n个随机变量,方差记为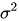 ,两两变量之间的相关性为
,两两变量之间的相关性为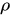 ,则
,则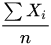 的方差为
的方差为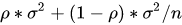 ,bagging降低的是第二项,random forest是同时降低两项。详见ESL p588公式15.1)
,bagging降低的是第二项,random forest是同时降低两项。详见ESL p588公式15.1)
boosting从优化角度来看,是用forward-stagewise这种贪心法去最小化损失函数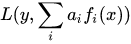 。例如,常见的AdaBoost即等价于用这种方法最小化exponential loss:
。例如,常见的AdaBoost即等价于用这种方法最小化exponential loss: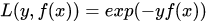 。所谓forward-stagewise,就是在迭代的第n步,求解新的子模型f(x)及步长a(或者叫组合系数),来最小化
。所谓forward-stagewise,就是在迭代的第n步,求解新的子模型f(x)及步长a(或者叫组合系数),来最小化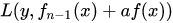 ,这里
,这里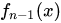
是前n-1步得到的子模型的和。因此boosting是在sequential地最小化损失函数,其bias自然逐步下降。但由于是采取这种sequential、adaptive的策略,各子模型之间是强相关的,于是子模型之和并不能显著降低variance。所以说boosting主要还是靠降低bias来提升预测精度。
随机森林特征筛选的方法
1)基尼系数
在决策树中cart树就是使用基尼系数来进行节点划分,在每一个节点划分的时候,计算每一个特征的基尼系数,选择基尼系数较小的特征,基尼系数越小,反应得到的结果集数据越纯,也就是划分的效果比较好,基本上都被正确的分类出来。
介绍了决策树节点划分的基本原理之后,我们是如何来使用基尼系数来计算特征的重要性?
假设我们给出的节点M,当前节点M的基尼系数是可以计算出来的,然后我们选择一个特征J进行划分,划分后的两个子集也有自己的基尼系数,计算划分前和划分后的基尼系数差值作为当前特征的重要性,如果差值越大说明当前的特征重要性越高。就拿特征J来说,如果我们划分后的结果很纯,那么计算出来的基尼系数很小,那么理所当然前后的差值较大,就达到了目的。
计算每一个特征在每一棵树的重要性,然后取加权平均得到最终的特征重要性评估
2)袋外误差(OOB)
首先要了解什么是袋外误差?
袋外的概念就是我们一次对样本进行采样,假设总共有M个样本,一次采样只采集A个样本,那么就有M-A个样本没有被采集到,这些样本就是用来作为测试样本后期衡量决策树的好坏,当然也拿来衡量特征的好坏。
OOB误差究竟怎么用?
第一步:
我们已经把随机森林需要的K颗树全部算出来了,每一棵树都会对对应的袋外数据计算相应的结果,计算的结果与实际的结果之间对比可以得到算法的计算误差,此处我们记为ERROR1
第二步:
我们对每一个特征随机添加一定的噪声(也有另外一种方法,就是将当前特征的值随机打散),对加入噪声的数据再次计算对应的误差得到ERROR2,然后计算ERROR1与ERROR2之间的差值,差值越大,说明当前的特征越重要。为什么重要?你可以这么想,当前我们的特征未加入噪声之前计算的误差比较小,得到的结果比较好,但是你加入了脏数据也就变为不好的数据,那么计算出来的结果就会比较差。相反,本来特征计算的结果效果不好,你加了一点脏数据前后差异理论上也不会差异太大,所以得到的误差差异也就不大。到此就说明了特征的重要性。

若有收获,就点个赞吧
0 人点赞
