一、前言
最近搞了一个月的视频多目标优化,同时优化点击率和衍生率(ysl, 点击后进入第二个页面后续的点击次数),线上AB实验取得了不错的效果,总结一下优化的过程,更多的偏向实践。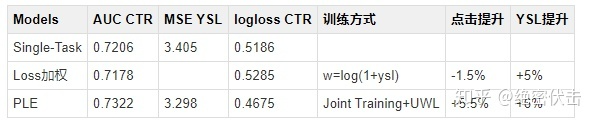
表1:线上实验结果
二、业界方案
2.1 样本Loss加权
保证一个主目标的同时,将其它目标转化为样本权重,改变数据分布,达到优化其它目标的效果。
如果  ,则
,则  .
.
优点:
- 模型简单,仅在训练时通过梯度乘以样本权重实现对其它目标的加权
- 模型上线简单,和base完全相同,不需要额外开销
- 在主目标没有明显下降时,其它目标提升较大(线上AB测试,主目标点击降低了1.5%,而衍生率提升了5%以上)
缺点:
本质上并不是多目标建模,而是将不同的目标转化为同一个目标。样本的加权权重需要根据AB测试才能确定。
2.2 多任务学习-Shared-Bottom Multi-task Model
模型结构如图1所示:
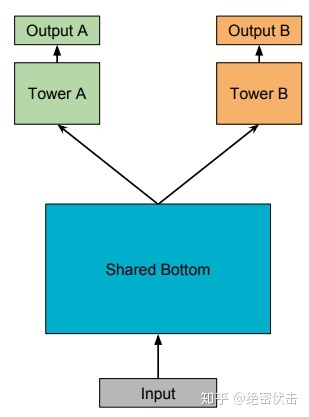
图1:Shared-Bottom Multi-task Model
Shared-Bottom 网络通常位于底部,表示为函数 ,多个任务共用这一层。往上,
,多个任务共用这一层。往上,  个子任务分别对应一个 tower network,表示为
个子任务分别对应一个 tower network,表示为  ,每个子任务的输出为:
,每个子任务的输出为: 
优点:浅层参数共享,互相补充学习,任务相关性越高,模型的loss可以降低到更低
缺点:
任务没有好的相关性时,这种Hard parameter sharing会损害效果
2.3 多任务学习-MOE
模型结构如图2所示:
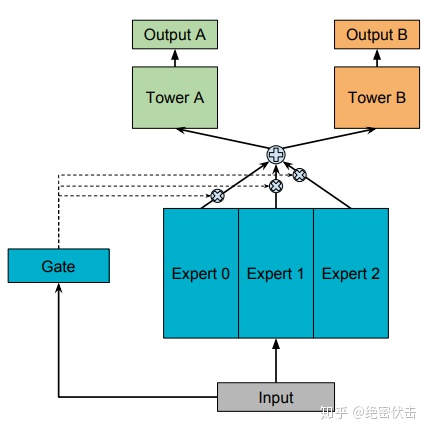
图2:MOE(One-gate Mixture-of-Experts)
前面的Shared-Bottom是一种Hard parameter sharing,会导致不相关任务联合学习效果不佳,为了解决这个问题,Google提出了Soft parameter sharing,MOE是其中的一种实现。
MOE由一组专家系统(Experts)组成的神经网络结构替换原来的Shared-Bottom部分,每一个Expert都是一个前馈神经网络,再加上一个门控网络(Gate)。MOE可以表示为:

 是第
是第  个任务的输出,
个任务的输出,  是
是  个expert network(expert network可认为是一个神经网络),
个expert network(expert network可认为是一个神经网络),  是门控网络,可以表示为:
是门控网络,可以表示为:
可以看出 产生
产生  个experts上的概率分布,最终的输出是所有experts的加权和。MOE可以看成多个独立模型的集成方法。
个experts上的概率分布,最终的输出是所有experts的加权和。MOE可以看成多个独立模型的集成方法。
2.4 多任务学习-MMOE
MMOE(Multi-gate Mixture-of-Experts)是在MOE的基础上,使用了多个门控网络,
 个任就对应
个任就对应  个门控网络,模型结构如图3所示:
个门控网络,模型结构如图3所示: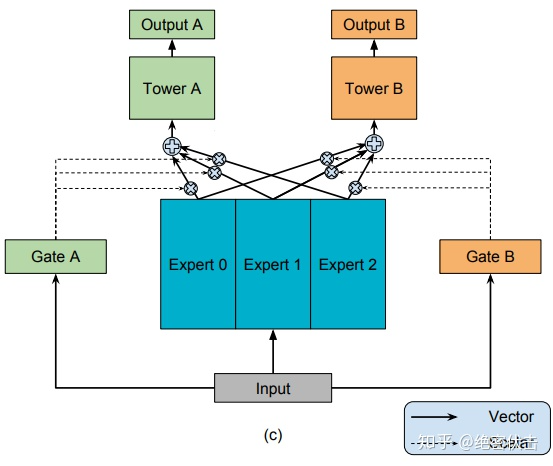
图3:MMOE(Multi-gate Mixture-of-Experts)
MMOE可以表示为:

其中, 是第
是第  个子任务中组合 experts 结果的门控网络,每一个任务都有一个独立的门控网络。
个子任务中组合 experts 结果的门控网络,每一个任务都有一个独立的门控网络。
优点:MMOE是MOE的改进,相对于 MOE的结构中所有任务共享一个门控网络,MMOE的结构优化为每个任务都单独使用一个门控网络。这样的改进可以针对不同任务得到不同的 Experts 权重,从而实现对 Experts 的选择性利用,不同任务对应的门控网络可以学习到不同的Experts 组合模式,因此模型更容易捕捉到子任务间的相关性和差异性。
2.5 多任务学习-ESMM
ESMM(Entire Space Multi-Task Model)是针对任务依赖而提出,比如电商推荐中的多目标预估经常是ctr和cvr,其中转换这个行为只有在点击发生后才会发生。
cvr任务在训练时只能利用点击后的样本,而预测时,是在整个样本空间,这样导致训练和预测样本分布不一致,即样本选择性偏差。同时点击样本只占整个样本空间的很小比例,比如在新闻推荐中,点击率通常只有不到10%,即样本稀疏性问题。
为了解决这个问题,ESMM提出了转化公式:
那么,我们可以通过分别估计pctcvr(即 )和pctr(即
)和pctr(即  ),然后通过两者相除来解决。而pctcvr和pctr都可以在全样本空间进行训练和预估。但是这种除法在实际使用中,会引入新的问题。因为pctr其实是一个很小的值,预估时会出现pctcvr>pctr的情况,导致pcvr预估值大于1。ESSM巧妙的通过将除法改成乘法来解决上面的问题。它引入了pctr和pctcvr两个辅助任务,训练时,loss为两者相加。
),然后通过两者相除来解决。而pctcvr和pctr都可以在全样本空间进行训练和预估。但是这种除法在实际使用中,会引入新的问题。因为pctr其实是一个很小的值,预估时会出现pctcvr>pctr的情况,导致pcvr预估值大于1。ESSM巧妙的通过将除法改成乘法来解决上面的问题。它引入了pctr和pctcvr两个辅助任务,训练时,loss为两者相加。
模型的Loss为:
其中 和
和  分别是ctr和cvr任务的网络参数。这样模型可以同时得到pctr,pcvr,pctcvr三个任务的预估结果。模型结构如图4所示:
分别是ctr和cvr任务的网络参数。这样模型可以同时得到pctr,pcvr,pctcvr三个任务的预估结果。模型结构如图4所示: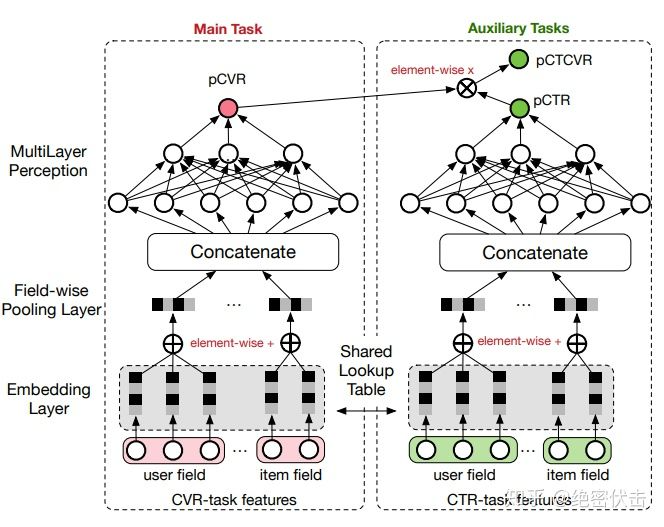
图4:ESMM模型结构三、实践方案
具体的实践中,我们主要参考了腾讯的PLE(Progressive Layered Extraction)模型,PLE相对于前面的MMOE和ESMM,主要解决以下问题:
多任务学习中往往存在跷跷板现象,也就是说,多任务学习相对于多个单任务学习的模型,往往能够提升一部分任务的效果,同时牺牲另外部分任务的效果。即使通过MMoE这种方式减轻负迁移现象,跷跷板现象仍然是广泛存在的。
前面的MMOE模型存在以下两方面的缺点MMOE中所有的Expert是被所有任务所共享的,这可能无法捕捉到任务之间更复杂的关系,从而给部分任务带来一定的噪声
- 不同的Expert之间没有交互,联合优化的效果有所折扣
PLE针对上面第一个问题,每个任务有独立的Expert,同时保留了共享的Expert,模型结构如图5所示: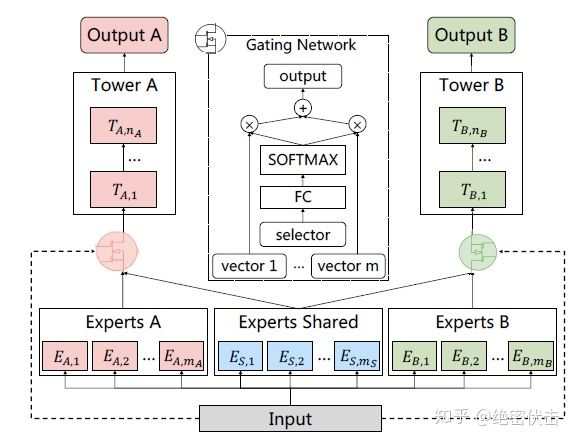
图5:Customized Gate Control (CGC) Model
图中ExpertsA和ExpertsB是任务A和B各自的专家系统,中间的Experts Shared是共享的专家系统。图中的selector表示选择的专家系统。对于任务A,使用Experts A和Experts Shared里面的多个Expert的输出。
任务  的输出可以表示为:
的输出可以表示为:
其中,  表示任务
表示任务  的tower network,
的tower network,  是门控网络,可以表示为:
是门控网络,可以表示为:
其中  是选择专家系统
是选择专家系统  中所有Expert的权重,可以表示为:
中所有Expert的权重,可以表示为:
其中  ,
,  和
和  分别是共享Experts个数以及任务
分别是共享Experts个数以及任务  独有Experts个数,
独有Experts个数,  是输入维度。
是输入维度。 由共享Experts和任务
由共享Experts和任务  的Experts组成,可以表示为:
的Experts组成,可以表示为:
PLE针对前面的第二个问题,考虑了不同Expert之前的交互,模型结构如图6所示: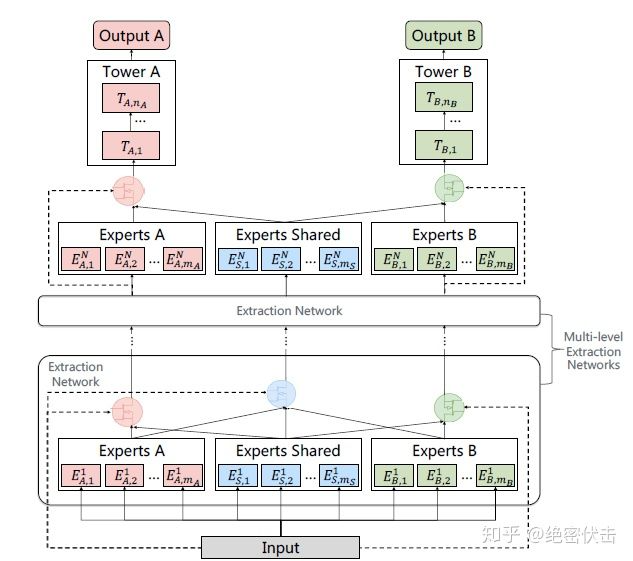
图6:Progressive Layered Extraction (PLE) Model
PLE中第  层的输出表示为:
层的输出表示为:
这里面,  包含两部分,可以表示为:
包含两部分,可以表示为:
其中  表示第
表示第  层Experts
层Experts  的输入为
的输入为  ,而
,而  表示Experts Shared的输入是
表示Experts Shared的输入是  ,
, 表示共享部分的gating network,这部分gating network的输入(selector)包含了所有的Experts(即包含Experts A,Experts B和Experts Shared),可以表示为:
表示共享部分的gating network,这部分gating network的输入(selector)包含了所有的Experts(即包含Experts A,Experts B和Experts Shared),可以表示为:  ,这里面
,这里面  就是所有的Experts。
就是所有的Experts。
最终每个任务的输出表示为:
下面是PLE用tensorflow的一个简单实现,只考虑两个任务。
def multi_level_extraction_network(hidden_layer,num_level,experts_units,experts_num):""":param hidden_layer::param num_level::param experts_units::param experts_num::return:"""gate_output_task1_final = hidden_layergate_output_task2_final = hidden_layergate_output_shared_final = hidden_layerselector_num = 2for i in range(num_level):# experts sharedexperts_weight = tf.get_variable(name='experts_weight_%d' % (i),dtype=tf.float32,shape=(gate_output_shared_final.get_shape()[1], experts_units, experts_num),initializer=init_ops.glorot_uniform_initializer())experts_bias = tf.get_variable(name='expert_bias_%d' % (i),dtype=tf.float32,shape=(experts_units, experts_num),initializer=init_ops.glorot_uniform_initializer())# experts Task 1experts_weight_task1 = tf.get_variable(name='experts_weight_task1_%d' % (i),dtype=tf.float32,shape=(gate_output_task1_final.get_shape()[1], experts_units, experts_num),initializer=init_ops.glorot_uniform_initializer())experts_bias_task1 = tf.get_variable(name='expert_bias_task1_%d' % (i),dtype=tf.float32,shape=(experts_units, experts_num),initializer=init_ops.glorot_uniform_initializer())# experts Task 2experts_weight_task2 = tf.get_variable(name='experts_weight_task2_%d' % (i),dtype=tf.float32,shape=(gate_output_task2_final.get_shape()[1], experts_units, experts_num),initializer=init_ops.glorot_uniform_initializer())experts_bias_task2 = tf.get_variable(name='expert_bias_task2_%d' % (i),dtype=tf.float32,shape=(experts_units, experts_num),initializer=init_ops.glorot_uniform_initializer())# gates sharedgate_shared_weigth = tf.get_variable(name='gate_shared_%d' % (i),dtype=tf.float32,shape=(gate_output_shared_final.get_shape()[1], experts_num * 3),initializer=init_ops.glorot_uniform_initializer())gate_shared_bias = tf.get_variable(name='gate_shared_bias_%d' % (i),dtype=tf.float32,shape=(experts_num * 3,),initializer=init_ops.glorot_uniform_initializer())# gates Task 1gate_weight_task1 = tf.get_variable(name='gate_weight_task1_%d' % (i),dtype=tf.float32,shape=(gate_output_task1_final.get_shape()[1], experts_num * selector_num),initializer=init_ops.glorot_uniform_initializer())gate_bias_task1 = tf.get_variable(name='gate_bias_task1_%d' % (i),dtype=tf.float32,shape=(experts_num * selector_num,),initializer=init_ops.glorot_uniform_initializer())# gates Task 2gate_weight_task2 = tf.get_variable(name='gate_weight_task2_%d' % (i),dtype=tf.float32,shape=(gate_output_task2_final.get_shape()[1], experts_num * selector_num),initializer=init_ops.glorot_uniform_initializer())gate_bias_task2 = tf.get_variable(name='gate_bias_task2_%d' % (i),dtype=tf.float32,shape=(experts_num * selector_num,),initializer=init_ops.glorot_uniform_initializer())# experts shared outputsexperts_output = tf.tensordot(gate_output_shared_final, experts_weight, axes=1)experts_output = tf.add(experts_output, experts_bias)experts_output = tf.nn.relu(experts_output)# experts Task1 outputsexperts_output_task1 = tf.tensordot(gate_output_task1_final, experts_weight_task1, axes=1)experts_output_task1 = tf.add(experts_output_task1, experts_bias_task1)experts_output_task1 = tf.nn.relu(experts_output_task1)# experts Task2 outputsexperts_output_task2 = tf.tensordot(gate_output_task2_final, experts_weight_task2, axes=1)experts_output_task2 = tf.add(experts_output_task2, experts_bias_task2)experts_output_task2 = tf.nn.relu(experts_output_task2)# gates Task1 outputsgate_output_task1 = tf.matmul(gate_output_task1_final, gate_weight_task1)gate_output_task1 = tf.add(gate_output_task1, gate_bias_task1)gate_output_task1 = tf.nn.softmax(gate_output_task1)gate_output_task1 = tf.multiply(concat_fun([experts_output_task1, experts_output], axis=2),tf.expand_dims(gate_output_task1, axis=1))gate_output_task1 = tf.reduce_sum(gate_output_task1, axis=2)gate_output_task1 = tf.reshape(gate_output_task1, [-1, experts_units])gate_output_task1_final = gate_output_task1# gates Task2 outputsgate_output_task2 = tf.matmul(gate_output_task2_final, gate_weight_task2)gate_output_task2 = tf.add(gate_output_task2, gate_bias_task2)gate_output_task2 = tf.nn.softmax(gate_output_task2)gate_output_task2 = tf.multiply(concat_fun([experts_output_task2, experts_output], axis=2),tf.expand_dims(gate_output_task2, axis=1))gate_output_task2 = tf.reduce_sum(gate_output_task2, axis=2)gate_output_task2 = tf.reshape(gate_output_task2, [-1, experts_units])gate_output_task2_final = gate_output_task2# gates shared outputsgate_output_shared = tf.matmul(gate_output_shared_final, gate_shared_weigth)gate_output_shared = tf.add(gate_output_shared, gate_shared_bias)gate_output_shared = tf.nn.softmax(gate_output_shared)gate_output_shared = tf.multiply(concat_fun([experts_output_task1, experts_output, experts_output_task2], axis=2),tf.expand_dims(gate_output_shared, axis=1))gate_output_shared = tf.reduce_sum(gate_output_shared, axis=2)gate_output_shared = tf.reshape(gate_output_shared, [-1, experts_units])gate_output_shared_final = gate_output_sharedreturn gate_output_task1_final, gate_output_task2_final

若有收获,就点个赞吧
0 人点赞
