Focal Loss
Focal loss主要是为了解决one-stage目标检测中正负样本比例严重失衡的问题。该损失函数降低了大量简单负样本在训练中所占的权重,也可理解为一种困难样本挖掘。
Focal loss是在交叉熵损失函数基础上进行的修改,首先回顾二分类交叉上损失: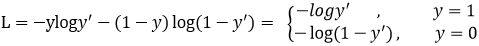
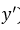 是经过激活函数的输出,所以在0-1之间。可见普通的交叉熵对于正样本而言,输出概率越大损失越小。对于负样本而言,输出概率越小则损失越小。此时的损失函数在大量简单样本的迭代过程中比较缓慢且可能无法优化至最优。那么Focal loss是怎么改进的呢?
是经过激活函数的输出,所以在0-1之间。可见普通的交叉熵对于正样本而言,输出概率越大损失越小。对于负样本而言,输出概率越小则损失越小。此时的损失函数在大量简单样本的迭代过程中比较缓慢且可能无法优化至最优。那么Focal loss是怎么改进的呢?
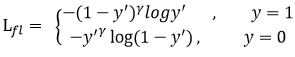
首先在原有的基础上加了一个因子,其中gamma>0使得减少易分类样本的损失。使得更关注于困难的、错分的样本。
例如gamma为2,对于正类样本而言,预测结果为0.95肯定是简单样本,所以(1-0.95)的gamma次方就会很小,这时损失函数值就变得更小。而预测概率为0.3的样本其损失相对很大。对于负类样本而言同样,预测0.1的结果应当远比预测0.7的样本损失值要小得多。对于预测概率为0.5时,损失只减少了0.25倍,所以更加关注于这种难以区分的样本。这样减少了简单样本的影响,大量预测概率很小的样本叠加起来后的效应才可能比较有效。
此外,加入平衡因子alpha,用来平衡正负样本本身的比例不均:文中alpha取0.25,即正样本要比负样本占比小,这是因为负例易分。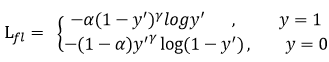
只添加alpha虽然可以平衡正负样本的重要性,但是无法解决简单与困难样本的问题。
gamma调节简单样本权重降低的速率,当gamma为0时即为交叉熵损失函数,当gamma增加时,调整因子的影响也在增加。实验发现gamma为2是最优。
SWA(Stochastic Weight Averaging)
SWA是一种通过随机梯度下降改善深度学习模型泛化能力的方法,而且这种方法不会为训练增加额外的消耗,这种方法可以嵌入到Pytorch中的任何优化器类中。
- SWA可以改进模型训练过程的稳定性;
- SWA的扩展方法可以达到高精度的贝叶斯模型平均的效果,同时对深度学习模型进行校准;
- 即便是在低精度下训练的SWA,即SWALP,也可以达到全精度下SGD训练的效果。
SWA能够work的关键有两点:第一,SWA采用改良的学习率策略以便SGD能够继续探索能使模型表现更好的参数空间。比如,我们可以在训练过程的前75%阶段使用标准的学习率下降策略。然后,在剩下的阶段保持学习率不变。第二,将SGD经过的参数进行平均。比如,可以将每个epoch最后25%训练时间的权重进行平均。
Multi-Sample Dropout
本文阐述的也是一种 dropout 技术的变形——multi-sample dropout。传统 dropout 在每轮训练时会从输入中随机选择一组样本(称之为 dropout 样本),而 multi-sample dropout 会创建多个 dropout 样本,然后平均所有样本的损失,从而得到最终的损失。这种方法只要在 dropout 层后复制部分训练网络,并在这些复制的全连接层之间共享权重就可以了,无需新运算符。
通过综合 M 个 dropout 样本的损失来更新网络参数,使得最终损失比任何一个 dropout 样本的损失都低。这样做的效果类似于对一个 minibatch 中的每个输入重复训练 M 次。因此,它大大减少了训练迭代次数。
为什么 Multi-Sample Dropout 可以加速训练
直观来说,带有 M 个 dropout 样本的 multi-sample dropout 的效果类似于通过复制 minibatch 中每个样本 M 次来将这个 minibatch 扩大 M 倍。例如,如果一个 minibatch 由两个数据样本(A, B)组成,使用有 2 个 dropout 样本的 multi-sample dropout 就如同使用传统 dropout 加一个由(A, A, B, B)组成的 minibatch 一样。其中 dropout 对 minibatch 中的每个样本应用不同的掩码。通过复制样本来增大 minibatch 使得计算时间增加了近 M 倍,这也使得这种方式并没有多少实际意义。相比之下,multi-sample dropout 只重复了 dropout 后的操作,所以在不显著增加计算成本的情况下也可以获得相似的收益。由于激活函数的非线性,传统方法(增大版 minibatch 与传统 dropout 的组合)和 multi-sample dropout 可能不会给出完全相同的结果。然而,如实验结果所示,迭代次数的减少还是显示出了 multi-sample dropout 的加速效果。
为什么 multi-sample dropout 很高效
如前所述,dropout 样本数为 M 的 multi-sample dropout 性能类似于通过复制 minibatch 中的每个样本 M 次来将 minibatch 的大小扩大 M 倍。这也是 multi-sample dropout 可以加速训练的主要原因。图 7 可以说明这一点。
[
](https://blog.csdn.net/weixin_37947156/article/details/95936865)
Lookahead
该研究表明这种更新机制能够有效地降低方差。研究者发现 Lookahead 对次优超参数没那么敏感,因此它对大规模调参的需求没有那么强。此外,使用 Lookahead 及其内部优化器(如 SGD 或 Adam),还能实现更快的收敛速度,因此计算开销也比较小。
研究者在多个实验中评估 Lookahead 的效果。比如在 CIFAR 和 ImageNet 数据集上训练分类器,并发现使用 Lookahead 后 ResNet-50 和 ResNet-152 架构都实现了更快速的收敛。
研究者还在 Penn Treebank 数据集上训练 LSTM 语言模型,在 WMT 2014 English-to-German 数据集上训练基于 Transformer 的神经机器翻译模型。在所有任务中,使用 Lookahead 算法能够实现更快的收敛、更好的泛化性能,且模型对超参数改变的鲁棒性更强。
这些实验表明 Lookahead 对内部循环优化器、fast weight 更新次数以及 slow weights 学习率的改变具备鲁棒性。
Lookahead Optimizer 怎么做
Lookahead 迭代地更新两组权重:slow weights φ 和 fast weights θ,前者在后者每更新 k 次后更新一次。Lookahead 将任意标准优化算法 A 作为内部优化器来更新 fast weights。
使用优化器 A 经过 k 次内部优化器更新后,Lookahead 通过在权重空间 θ φ 中执行线性插值的方式更新 slow weights,方向为最后一个 fast weights。
slow weights 每更新一次,fast weights 将被重置为目前的 slow weights 值。
标准优化方法通常需要谨慎调整学习率,以防止振荡和收敛速度过慢,这在 SGD 设置中更加重要。而 Lookahead 能借助较大的内部循环学习率减轻这一问题。
当 Lookahead 向高曲率方向振荡时,fast weights 更新在低曲率方向上快速前进,slow weights 则通过参数插值使振荡平滑。fast weights 和 slow weights 的结合改进了高曲率方向上的学习,降低了方差,并且使得 Lookahead 在实践中可以实现更快的收敛。
另一方面,Lookahead 还能提升收敛效果。当 fast weights 在极小值周围慢慢探索时,slow weight 更新促使 Lookahead 激进地探索更优的新区域,从而使测试准确率得到提升。
Lookahead 的伪代码见下图 Algorithm 1。
其中最优化器 A 可能是 Adam 或 SGD 等最优化器,内部的 for 循环会用常规方法更新 fast weights θ,且每次更新的起始点都是从当前的 slow weights φ 开始。最终模型使用的参数也是慢更新那一套,因此快更新相当于做了一系列实验,然后慢更新再根据实验结果选一个比较好的方向,这有点类似 Nesterov Momentum 的思想。
看上去这只是一个小技巧?似乎它应该对实际的参数更新没什么重要作用?那么继续看看它到底为什么能 Work。
Lookahead 为什么能 Work
标准优化方法通常需要谨慎调整学习率,以防止振荡和收敛速度过慢,这在 SGD 设置中更加重要。而 Lookahead 能借助较大的内部循环学习率减轻这一问题。
当 Lookahead 向高曲率方向振荡时,fast weights 更新在低曲率方向上快速前进,slow weights 则通过参数插值使振荡平滑。fast weights 和 slow weights 的结合改进了高曲率方向上的学习,降低了方差,并且使得 Lookahead 在实践中可以实现更快的收敛。
另一方面,Lookahead 还能提升收敛效果。当 fast weights 在极小值周围慢慢探索时,slow weight 更新促使 Lookahead 激进地探索更优的新区域,从而使测试准确率得到提升。这样的探索可能是 SGD 更新 20 次也未必能够到达的水平,因此有效地提升了模型收敛效果。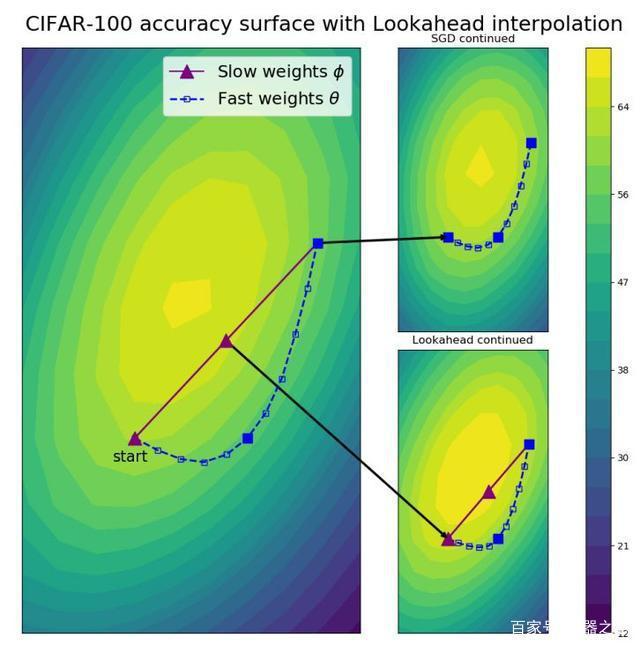
如上为 ResNet-32 在 CIFAR-100 训练 100 个 Epoch 后的可视化结果。在从上图可以看到模型已经接近最优解了,右上的 SGD 还会慢慢探索比较好的区域,因为当时的梯度已经非常小了。但是右下的 Lookahead 会根据 slow weights(紫色)探索到更好的区域。
当然这里只是展示了 Lookahead 怎么做,至于该算法更新步长、内部学习率等参数怎么算,读者可以查阅原论文。此外,Hinton 等研究者还给出了详细的收敛性分析,感兴趣的读者也可以细细阅读,毕竟当年 ICLR 2018 最佳论文可是找出了 Adam 原论文收敛性分析的错误。
实验分析
研究人员在一系列深度学习任务上使用 Lookahead 优化器和业内最强的基线方法进行了对比,其中包括在 CIFAR-10/CIFAR-100、ImageNet 上的图像分类任务。此外,研究人员在 Penn Treebank 数据集上训练了 LSTM 语言模型,也探索了基于 Transformer 的神经机器翻译模型在 WMT 2014 英语-德语数据集上的表现。对于所有实验,每个算法都使用相同数量的训练数据。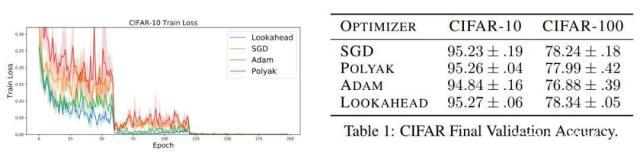
图 5:不同优化算法的性能比较。(左)在 CIFAR-100 上的训练损失。(右)使用不同优化器的 ResNet-18 在 CIFAR 数据集上的验证准确率。研究者详细研究了其它优化器的学习率和权重衰减(见论文附录 C)。Lookahead 和 Polyak 超越了 SGD。
图 6:ImageNet 的训练损失。星号表示激进的学习率衰减机制,其中 LR 在迭代 30、48 和 58 次时衰减。右表展示了使用 Lookahead 和 SGD 的 ResNet-50 的验证准确率。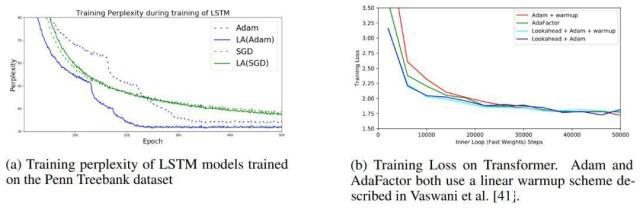
图 7:在 Penn Treebank 和 WMT-14 机器翻译任务上的优化性能。
从这些实验中,可以得到如下结论:
对于内部优化算法、k 和 α 的鲁棒性:研究人员在 CIFAR 数据集上的实验表明,Lookahead 可以始终如一地在不同初始超参数设置中实现快速收敛。我们可以看到 Lookahead 可以在基础优化器上使用更高的学习率进行训练,且无需对 k 和 α 进行大量调

若有收获,就点个赞吧
0 人点赞
