聚合方式
平均
先对邻居embedding中每个维度取平均,然后与目标节点embedding拼接后进行非线性转换。
GCN归纳式聚合
直接对目标节点和所有邻居emebdding中每个维度取平均(替换伪代码中第5、6行),后再非线性转换:
.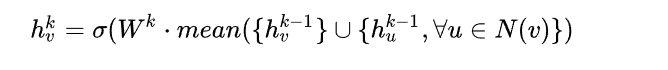
LSTM
LSTM函数不符合“排序不变量”的性质,需要先对邻居随机排序,然后将随机的邻居序列embedding 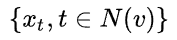 作为LSTM输入。
作为LSTM输入。
pooling
先对每个邻居节点上一层embedding进行非线性转换(等价单个全连接层,每一维度代表在某方面的表示(如信用情况)),再按维度应用 max/mean pooling,捕获邻居集上在某方面的突出的/综合的表现 以此表示目标节点embedding。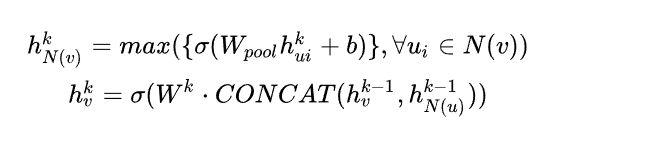
无监督和有监督设定
无监督loss
希望节点u与“邻居”v的embedding也相似(对应公式第一项),而与“没有交集”的节点  不相似(对应公式第二项)。
不相似(对应公式第二项)。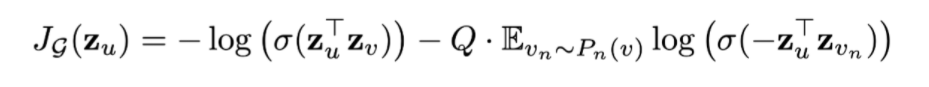
 为节点u通过GraphSAGE生成的embedding。
为节点u通过GraphSAGE生成的embedding。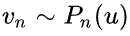 表示负采样:节点
表示负采样:节点  是从节点u的负采样分布
是从节点u的负采样分布  采样的,Q为采样样本数。
采样的,Q为采样样本数。
若有收获,就点个赞吧
0 人点赞
