简介
由于 IP 层不保证传输的可靠性,所以当TCP确认数据包已经丢失时,就会启动重传操作。
TCP 有两套独立的重传机制:
- 基于时间
-
超时重传
TCP 超时重传的基础是怎样根据链接的 RTT 设置合理的超时时间(RTO)。
若 TCP 先于 RTT 开始重传,可能会在网络中引起不必要的重复数据
- 反之,则可能会造成网络的利用率(即单个连接吞吐量)下降
经典算法-设置RTO
TCP 超时时间选择的经典算法如下

 为平滑因子,推荐值为 0.8 - 0.9
为平滑因子,推荐值为 0.8 - 0.9
这种算法成为指数加权移动平均,或低通过滤器。
因为 SRTT 估计器得到的值会随着 RTT 的变化而变化,[RFC0793]推荐根据以下公式设置 RTO

 为时延离散因子,推荐值为 1.3 - 2.0
为时延离散因子,推荐值为 1.3 - 2.0- ubound 为上边界
- lbound 为下边界
以上方式即成为经典方法。
该方法在相对稳定的 RTT 分布的网络中可以取得不错的性能,然而在 RTT 变化较大的网络中无法获得期望的效果。
tcp 选择超时时间的具体算法较为复杂,在链接中贴了内核中计算RTO的函数。
计时器
- TCP 在每发送一个数据包之前,使用相关算法设置一个超时的计时器
- 如果在超时前收到了回包则取消计时器
- 否则,就进行重传
Linux 关于重传的设置
在 Linux 上,关于超时的设置有如下几个,我们可以用以下命令查看:
$ sudo sysctl -a | grep ipv4 | grep retrinet.ipv4.tcp_orphan_retries = 0net.ipv4.tcp_retries1 = 3net.ipv4.tcp_retries2 = 15net.ipv4.tcp_syn_retries = 6net.ipv4.tcp_synack_retries = 5
下面让我们来看一下这几个参数的意义
- tcp_retries1 (integer; default: 3; since Linux 2.2)
- 使用成功建立的连接上进行重传的次数
- 如果超过了限制,则需要通知网络层更新路由表
- 网络层不一定可以成功更新
- tcp_retries2 (integer; default: 15; since Linux 2.2)
- established 状态下,TCP 包最大重传次数
- 默认为 15此,时间大约为 13 - 30 min
- tcp_syn_retries (integer; default: 6; since Linux 2.2)
- SYN 包最大重试次数
- 默认为 6,大约 127 秒重试结束
- tcp_synack_retries (integer; default: 5; since Linux 2.2)
发送端收到重复的 ACK 后,就表明,先前发送的分组可能已丢失(也可能仅为延迟到达)。由于我们无法得知是哪种情况,因此TCP等待一定数目的重复 ACK 之后,就可以触发重传。——通常为 3 次。
概括如下:TCP 发送端在收到最少 dupthresh 个重复的 ACK 之后——可能丢失了部分数据分组——就进行重传,而不必等到计时器超时。
图解
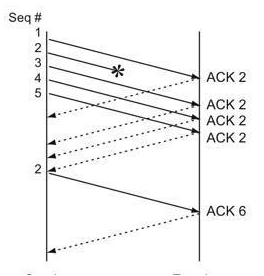
乱序包问题
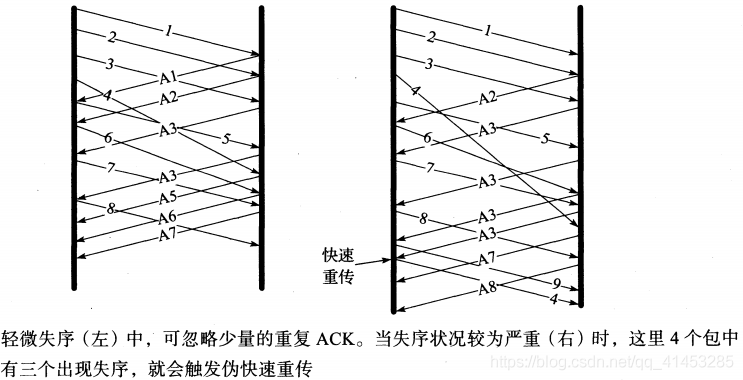
如上图所示,如果网络中的包发生乱序的问题,很可能会导致重传的发生。
Linux 中如何获取重传次数
$ netstat -s...Tcp:3366 active connection openings302 passive connection openings243 failed connection attempts206 connection resets received8 connections established142500 segments received109223 segments sent out1210 segments retransmitted4 bad segments received1392 resets sent...Detected reordering 14 times using SACK...
- 其中,最后一个为使用 SACK 时,发现的乱序包的数量。
RPS 与 RSS(Receive Side Scaling)
参考
《TCP/IP详解卷一》
https://man7.org/linux/man-pages/man7/tcp.7.html
https://elixir.bootlin.com/linux/v5.11.10/source/net/ipv4/tcp_timer.c#L448
https://time.geekbang.org/column/article/324357

若有收获,就点个赞吧
0 人点赞
