简介
在了解一致性hash之前,我们先必须了解传统的hash算法,以及其在大规模分布式系统中的局限性。
当数据量太大而无法存储在一个节点或机器上时,事情就变得有趣了。我们需要多台机器来存储数据,那么,数据到底存储在哪个节点上呢?这个问题最简单的解决方案就是用hash取模来确定。

下图为传统 hash 取模算法示意图,基于该算法可以实现简单的负载均衡。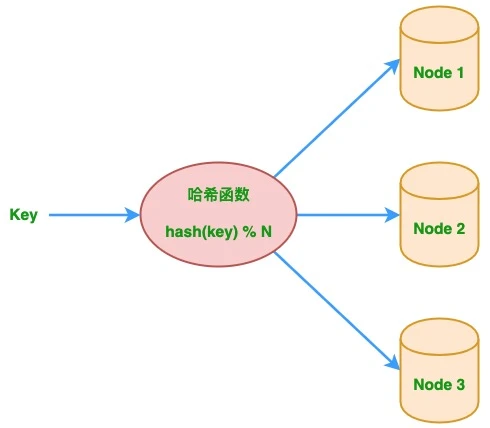
大规模系统中的hash算法
在动态变化的分布式环境中,选择的hash算法至少应该满足如下两个条件:
- 均衡性 - hash 结果应平均分配到各个节点,这样从算法上解决了数据的负载均衡问题。
- 分散性 - 数据应该分散的存储在集群中的各个节点上(节点自身可能有备份),不必每个节点都存储所有的数据。
但是在分布式系统中,节点出现故障很常见。任何节点都可能会因为各种异常原因突然宕机,针对这种情况,我们期望系统只是出现性能降低,正常的功能不应受到影响。
针对系统的不同,有的系统可以接受该问题。
而对于传统的hash算法来说,增加或减少节点对新增的数据不会造成影响。但是对于旧的数据来说,就会有严重的问题(由于节点数量N发生了变化,导致上述算法计算出的节点和存储时不一致)。
要解决这个问题,我们必须在发送这种情况之后重新分配所有已经存在的键,这可能是非常昂贵的操作,并且会对正在运行的系统产生不利的影响。
一致性hash算法
一致性hash算法是一种特殊的算法,它能够在整个系统增加或减少节点时,有效的减少数据的搬迁操作。
优点
- 可拓展性(Scalability)- 增加或减少节点时,有效减少数据的搬迁操作。
- 适应数据的快速增长 - 当分布式系统中的数据不断增长时,部分节点中可能会包含很多数据、造成数据分布不均衡,此时使用该算法可以仅对部分数据进行重新分配即可。
原理
一致性哈希算法通过一个叫作一致性哈希环的数据结构实现。这个环的起点是0,终点是2^32 - 1,并且起点与终点连接,故这个环的整数分布范围是[0, 2^32-1],如下图所示: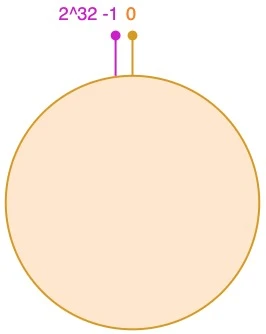
步骤一,计算每个key的hash,并放置到环上 ——N = 2^32。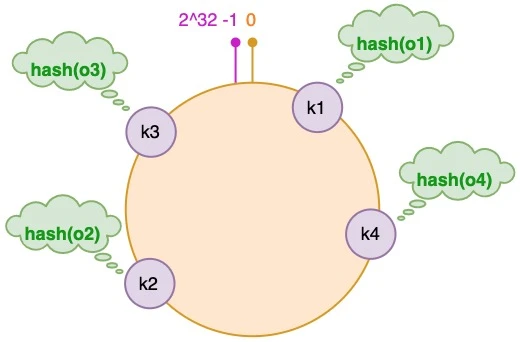
步骤二,将数据节点放置到环上。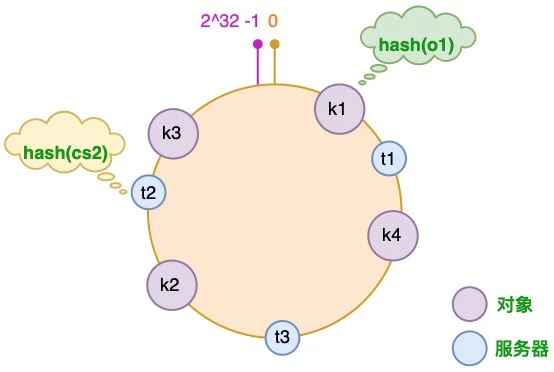
步骤三,为每个 key 选择一个数据节点——顺时针遍历hash环,直到找到第一个数据节点。
在这个算法下,如果增加或减少数据节点,则只需要移动顺时针方向上两个服务器之间的数据即可。
如果采用常规的hash算法,则所有数据都需要重新计算hash值,使用一致性hash则只需要移动部分数据。
虚拟节点
一致性哈希的基本原理到这里就已经结束了,但对于新增服务器的情况还存在一些问题。新增的节点只分担了一个节点的负载,其他节点并没有因为新节点的加入而减少负载压力。如果新节点的性能与原有节点的性能一致甚至可能更高,那么这种结果并不是我们所期望的。
针对这个问题,可以通过引入虚拟节点来解决负载不均衡的问题。即将每台物理服务器虚拟为一组虚拟服务器,将虚拟服务器放置到哈希环上,如果要确定对象的服务器,需先确定对象的虚拟服务器,再由虚拟服务器确定物理服务器。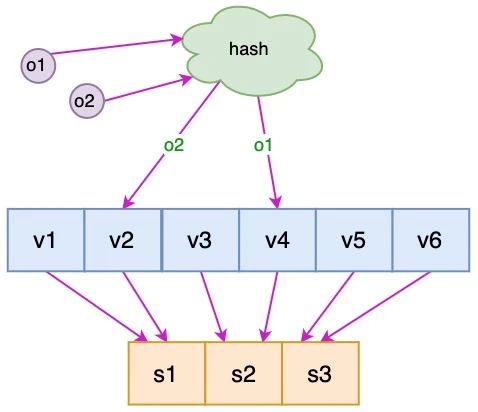
图中 o1 和 o2 表示对象,v1 ~ v6 表示虚拟服务器,s1 ~ s3 表示物理服务器。
参考
https://segmentfault.com/a/1190000021199728
https://leehao.me/%E4%B8%80%E8%87%B4%E6%80%A7Hash-Consistent-Hashing-%E5%8E%9F%E7%90%86%E5%89%96%E6%9E%90/

若有收获,就点个赞吧
0 人点赞
