UUID算法是一个非常常用的分布式唯一ID算法,如果没有其他特殊的需求,通常来说直接使用UUID即可。
但假如说有其他的需求,UUID通常来说也是满足不了的,比如:
- 生成的唯一ID递增——方便排序
- 通过ID可以得出一些其他信息
- 某个服务
- 某台物理机
- 某台虚拟机
- 某个时间
分布式追踪系统中,如果使用这种ID,可以一次性获取许多必要的信息。当然为了可读性,通常来说,独立的获取比较简洁。
单线程唯一ID
class UniqueID {constructor() {this._id = 0;}Generate() {return ++this._id;}}
如果你想在重启后生成的ID与之前的不重复,则简单的加入时间戳或者读取之前生成的最后一个ID,然后继续生成即可。
多线程唯一ID
package mainimport ("sync/atomic")type UniqueID struct {seed int64}func (u *UniqueID) Generate() int64 {return atomic.AddInt64(&u.seed, 1)}
分布式唯一ID
UUID
优点:
- 简单,代码方便。
- 生成ID性能非常好,基本不会有性能问题。
- 全球唯一,在遇见数据迁移,系统数据合并,或者数据库变更等情况下,可以从容应对。
缺点:
- 没有排序,无法保证趋势递增。
- UUID往往是使用字符串存储,查询的效率比较低。
- 存储空间比较大,如果是海量数据库,就需要考虑存储量的问题。
- 传输数据量大。
- 不可读。
使用 Redis 生成
假如一个集群中有5台Redis。可以初始化每台Redis的值分别是 1,2,3,4,5,然后步长都是5。各个Redis生成的ID为:
A:1,6,11,16,21
B:2,7,12,17,22
C:3,8,13,18,23
D:4,9,14,19,24
E:5,10,15,20,25
比较适合使用Redis来生成每天从0开始的流水号。比如订单号=日期+当日自增长号。可以每天在Redis中生成一个Key,使用INCR进行累加。
snowflake
snowflake是Twitter开源的分布式ID生成算法,结果是一个long型的ID。
其核心思想是:使用41bit作为毫秒数,10bit作为机器的ID(5个bit是数据中心,5个bit的机器ID),12bit作为毫秒内的流水号(意味着每个节点在每毫秒可以产生 4096 个 ID),最后还有一个符号位,永远是0。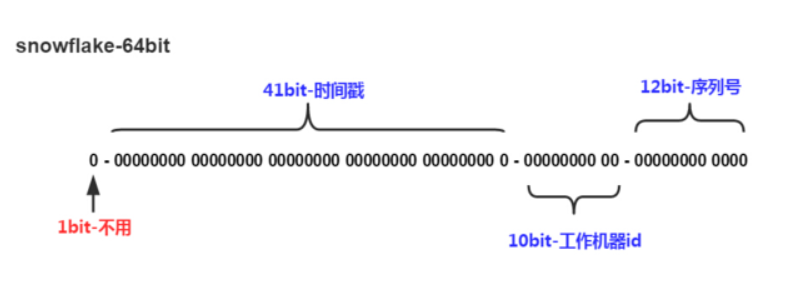
缺点:
UidGenerator 主要通过预先分配和使用内存连续的数组最大程度利用 CPU cache来提高性能。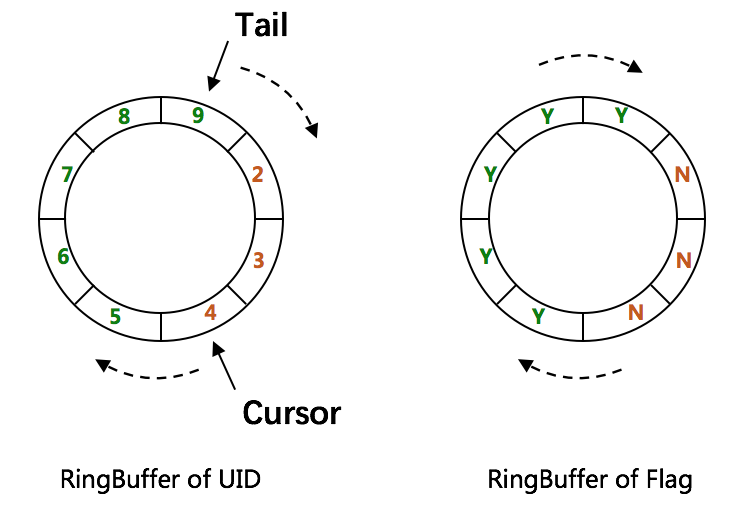
如上图所示:
- 使用两个 Ring。一个用来缓存 UID,另一个用来缓存UID状态(是否可填充,是否可消费);
- 初始化时填充两个 Ring;
- 消费时,通过检查剩余可用 slot 的数量,来判断是否需要进行填充;
- 周期性填充;
- 因为使用了预先填充的方式,所以降低了对硬件时间的依赖。
Mongodb ObjectId
MongoDB的ObjectId和snowflake算法类似。
ObjectId 由 12byte 组成,组成部分如下:
- 4-byte 时间戳
- 5-byte 随机值
- 3-byte 自增 counter,初始化时为一个随机值
参考链接
https://github.com/twitter-archive/snowflake
https://juejin.cn/post/6844903562007314440
https://github.com/baidu/uid-generator/blob/master/README.zh_cn.md
https://www.cnblogs.com/haoxinyue/p/5208136.html
https://docs.mongodb.com/manual/reference/method/ObjectId/

若有收获,就点个赞吧
0 人点赞
