简介
我们有时需要对接口做一些幂等性设计,尤其是在分布式系统中需要重试的情况下;
- 对于一个 search 的接口来说,不需要做什么额外的保护;
- 对于一个 create 或 update 的接口来说,如果不做幂等性设计的话,当上游业务重试时可能就会引发一些问题;
为什么需要幂等性?因为在分布式系统中,服务间的调用可能会有三个状态,一个是成功(Success),一个是失败(Failed),一个是超时(Timeout)。前两者都是明确的状态,而超时则是完全不知道是什么状态。
考虑以下几种情况:
- 网络传输丢包导致数据包没有发送到目标端;
- 请求发送到目标端,但是目标端正在处理,但是已经到超时时间了;
- 请求发送到目标端,目标端处理完毕,返回的时候网络丢包导致没有接收到请求。
- …
于是上游系统完全不知道下游系统是否收到了请求,收到了请求是否处理了,成功 / 失败的状态在返回时是否遇到了网络问题等。总之,请求方完全不知道是怎么回事。
在这种情况下,一般有两种处理方式。
- 一种是需要下游系统提供相应的查询接口。上游系统在 timeout 后去查询一下。如果查到了,就表明已经做了,成功了就不用做了,失败了就走失败流程。
- 另一种是通过幂等性的方式。也就是说,把这个查询操作交给下游系统,上游系统只管重试,下游系统保证一次和多次的请求结果是一样的。
全局唯一标识
要做到幂等性的交易接口,需要有一个唯一的标识,来标志交易是同一笔交易。
因为绝大部分请求都是正常的请求,具体实现上如果每次都去数据库查询这个ID是否已存在可能会造成性能问题,可以使用 唯一索引 + 数据库异常 来减少一次数据库调用(但是这样可能需要在数据结构中增加一个唯一索引字段)。
为了解决分配冲突的问题,需要使用一个不会冲突的算法,介绍以下两种。
如果具体要实现的话,还可以参考其他的像 Redis 或 MongoDB 的全局 ID 生成算法。
UUID
UUID 的问题是,它的字符串占用的空间比较大,索引的效率非常低,生成的 ID 太过于随机,完全不是人读的,而且没有递增,如果要按前后顺序排序的话,基本不可能。
Snowflake
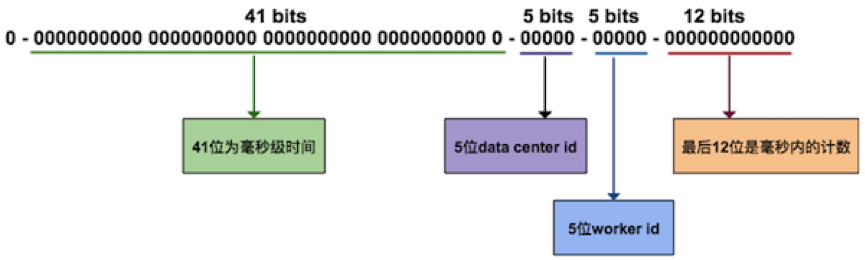
Snowflake是 twitter 的一个开源项目,它是一个分布式ID的生成算法。其核心思想是,产生一个 long 型的 ID,其中:
- 41bits 作为毫秒数。大概可以用 69.7 年。
- 10bits 作为机器编号(5bits 是数据中心,5bits 的机器 ID),支持 1024 个实例。
- 12bits 作为毫秒内的序列号。一毫秒可以生成 4096 个序号。
注:
- twitter官方github说这个算法已经过时;
- 此算法基于时钟,官方github也给出了一些建议。
参考链接
https://time.geekbang.org/column/article/4050
MQ中幂等性设计
https://github.com/twitter-archive/snowflake

若有收获,就点个赞吧
0 人点赞
