问题
网页爬虫是搜索引擎中的非常重要的系统,负责爬取几十亿、上百亿的网页。爬虫的工作原理是,通过解析已经爬取页面中的网页链接,然后再爬取这些链接对应的网页。而同一个网页链接有可能被包含在多个页面中,这就会导致爬虫在爬取的过程中,重复爬取相同的网页。如果你是一名负责爬虫的工程师,你会如何避免这些重复的爬取呢?
算法解析
这个问题要处理的对象是网页链接,也就是 URL,需要支持的操作有两个,添加一个 URL 和查询一个 URL。除了这两个功能性的要求之外,在非功能性方面,我们还要求这两个操作的执行效率要尽可能高。除此之外,因为我们处理的是上亿的网页链接,内存消耗会非常大,所以在存储效率上,我们要尽可能地高效。
满足这些条件的数据结构有哪些呢?显然,散列表、红黑树、跳表这些动态数据结构,都能支持快速地插入、查找数据,但是在内存消耗方面,是否可以接受呢?
拿散列表来举例。假设我们要爬取 10 亿个网页,为了判重,我们把这 10 亿网页链接存储在散列表中。估算下,大约需要多少内存?
假设一个 URL 的平均长度是 64 字节,那单纯存储这 10 亿个 URL,需要大约 60GB 的内存空间。因为散列表必须维持较小的装载因子,才能保证不会出现过多的散列冲突,导致操作的性能下降。而且,用链表法解决冲突的散列表,还会存储链表指针。所以,如果将这 10 亿个 URL 构建成散列表,那需要的内存空间会远大于 60GB,有可能会超过 100GB。
位图
先看一个简单的问题,我们有 1 千万个整数,整数的范围在 1 到 1 亿之间。如何快速查找某个整数是否在这 1 千万个整数中呢?
当然,这个问题还是可以用散列表来解决。不过,我们可以使用一种比较“特殊”的散列表,那就是位图。我们申请一个大小为 1 亿、数据类型为布尔类型(true 或者 false)的数组。我们将这 1 千万个整数作为数组下标,将对应的数组值设置成 true。比如,整数 5 对应下标为 5 的数组值设置为 true,也就是 array[5]=true。
当我们查询某个整数 K 是否在这 1 千万个整数中的时候,我们只需要将对应的数组值 array[K]取出来,看是否等于 true。如果等于 true,那说明 1 千万整数中包含这个整数 K;相反,就表示不包含这个整数 K。
很多语言中提供的布尔类型,大小是 1 个字节的,并不能节省太多内存空间。实际上,表示 true 和 false 两个值,我们只需要用一个二进制位(bit)就可以了。那如何通过编程语言,来表示一个二进制位呢?
这里就要用到位运算了。我们可以借助编程语言中提供的数据类型,比如 int、long、char 等类型,通过位运算,用其中的某个位表示某个数字。
import ("fmt""strings")type bitmap struct {bytes []uint32}func (b *bitmap) Add(k int) {byteIndex := k / 32bitIndex := k % 32for len(b.bytes) < byteIndex + 1 {b.bytes = append(b.bytes, 0)}b.bytes[byteIndex] |= (1 << bitIndex)}func (b *bitmap) Exists(k int) bool {byteIndex := k / 32bitIndex := k % 32if len(b.bytes) < byteIndex + 1 {return false}return (b.bytes[byteIndex] & (1 << bitIndex)) != 0}func (b *bitmap) String() string {ret := []string{}for _, bt := range b.bytes {ret = append(ret, fmt.Sprintf("%032b", bt))}return strings.Join(ret, "")}
比如刚刚那个例子,如果用散列表存储这 1 千万的数据,数据是 32 位的整型数,也就是需要 4 个字节的存储空间,那总共至少需要 40MB 的存储空间。如果我们通过位图的话,数字范围在 1 到 1 亿之间,只需要 1 亿个二进制位,也就是 12MB 左右的存储空间就够了。
不过,这里我们有个假设,就是数字所在的范围不是很大。如果数字的范围很大,比如刚刚那个问题,数字范围不是 1 到 1 亿,而是 1 到 10 亿,那位图的大小就是 10 亿个二进制位,也就是 120MB 的大小,消耗的内存空间,不降反增。
布隆过滤器就是为了解决刚刚这个问题,对位图这种数据结构的一种改进。
布隆过滤器
还是刚刚那个例子,数据个数是 1 千万,数据的范围是 1 到 10 亿。布隆过滤器的做法是,我们仍然使用一个 1 亿个二进制大小的位图,然后通过哈希函数,对数字进行处理,让它落在这 1 到 1 亿范围内。比如我们把哈希函数设计成 f(x)=x%n。其中,x 表示数字,n 表示位图的大小(1 亿),也就是,对数字跟位图的大小进行取模求余。
为了降低hash冲突概率,当然我们可以设计一个复杂点、随机点的哈希函数。除此之外,还有其他方法吗?我们来看布隆过滤器的处理方法。既然一个哈希函数可能会存在冲突,那用多个哈希函数一块儿定位一个数据,是否能降低冲突的概率呢?我们来看看布隆过滤器的做法。
使用 K 个哈希函数,对同一个数字进行求哈希值,那会得到 K 个不同的哈希值,我们分别记作 X1,X2,X3,…,XK。我们把这 K 个数字作为位图中的下标,将对应的 BitMap[X1],BitMap[X2],BitMap[X3],…,BitMap[XK]都设置成 true,也就是说,我们用 K 个二进制位,来表示一个数字的存在。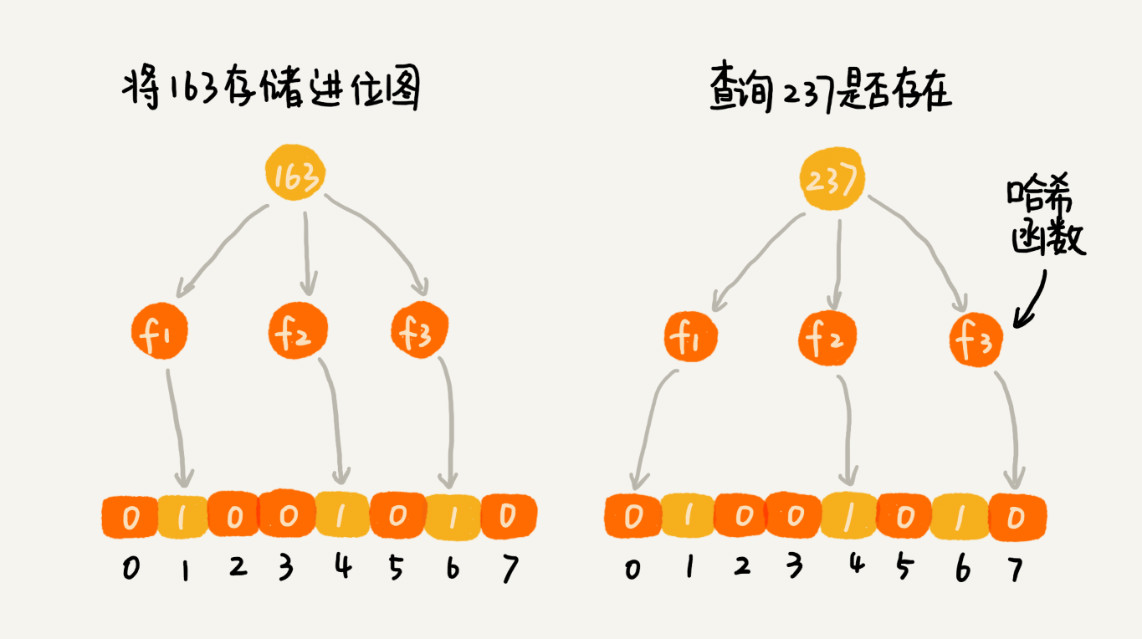
对于两个不同的数字来说,经过一个哈希函数处理之后,可能会产生相同的哈希值。但是经过 K 个哈希函数处理之后,K 个哈希值都相同的概率就非常低了。尽管采用 K 个哈希函数之后,两个数字哈希冲突的概率降低了,但是,这种处理方式又带来了新的问题,那就是容易误判。
布隆过滤器的误判有一个特点,那就是,它只会对存在的情况有误判。如果某个数字经过布隆过滤器判断不存在,那说明这个数字真的不存在,不会发生误判;如果某个数字经过布隆过滤器判断存在,这个时候才会有可能误判,有可能并不存在。不过,只要我们调整哈希函数的个数、位图大小跟要存储数字的个数之间的比例,那就可以将这种误判的概率降到非常低。
总结
布隆过滤器非常适合不需要 100% 准确的、允许存在小概率误判的大规模判重场景。除了爬虫网页去重这个例子,还有比如统计一个大型网站的每天的 UV 数,也就是每天有多少用户访问了网站,我们就可以使用布隆过滤器,对重复访问的用户进行去重。
布隆过滤器的误判率,主要跟哈希函数的个数、位图的大小有关。当我们往布隆过滤器中不停地加入数据之后,位图中不是 true 的位置就越来越少了,误判率就越来越高了。所以,对于无法事先知道要判重的数据个数的情况,我们需要支持自动扩容的功能。
当布隆过滤器中,数据个数与位图大小的比例超过某个阈值的时候,我们就重新申请一个新的位图。后面来的新数据,会被放置到新的位图中。但是,如果我们要判断某个数据是否在布隆过滤器中已经存在,我们就需要查看多个位图,相应的执行效率就降低了一些。
参考链接

若有收获,就点个赞吧
0 人点赞
