1.缓存
1.1使用场景
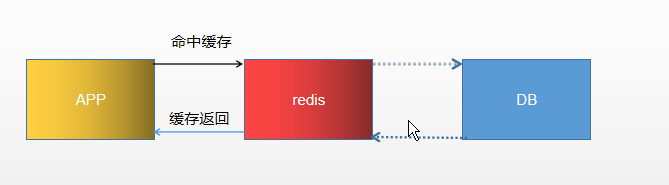
1.2缓存更新的 缓存一致性
redis缓存不一致的原因,主要 是 【查询数据库,再更新缓存的过程】这一组操作是不原子的 是不原子的。
最简单的强一致性就是加锁 【分布式锁】 和使用队列
【注意】不要去更新key而是直接删除key。
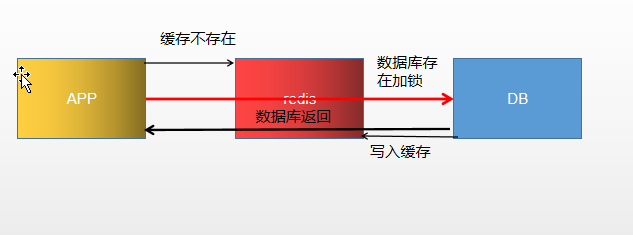
1. 先修改数据后删除缓存(建议!)
正常: 全部访问成功或者数据库查询 失败
情况1. 【1. 查询数据库 ✔ 】 【2.删除缓存✔】 数据最终一致
情况2. 【1. 查询数据库 ❌】 【2.删除缓存 (回滚了不需要删除) ❌】 数据最终一致
情况3. 【1.查询数据库 ✔】 【2.删除缓存 (回滚了不需要删除) ❌】 数据最终不一致
可以看到情况3可能导致数据不一致的问题
解决方案:用队列进行删除失败重试 直到成功
2. 先删除缓存再修改数据库(不建议)
会出现aba问题 解决方案双删
该方案会导致不一致的原因是。同时有一个请求A进行更新操作,另一个请求B进行查询操作。那么会出现如下情形:
- (1)请求A进行写操作,删除缓存
- (2)请求B查询发现缓存不存在
- (3)请求B去数据库查询得到旧值
- (4)请求B将旧值写入缓存
- (5)请求A将新值写入数据库 上述情况就会导致不一致的情形出现。而且,如果不采用给缓存设置过期时间策略,该数据永远都是脏数据。
那么,如何解决呢?采用延时双删策略 伪代码如下
public void write(String key,Object data){redis.delKey(key);db.updateData(data);Thread.sleep(1000);redis.delKey(key);}
转化为中文描述就是
- (1)先淘汰缓存
- (2)再写数据库(这两步和原来一样)
- (3)休眠1秒,再次淘汰缓存 这么做,可以将1秒内所造成的缓存脏数据,再次删除。
2.热点数据监控
1.客户端监控
2.代理监控
3.redis 服务监控 Redis Monitor
4.流量出口监测 packbeat
3.缓存问题
1.缓存雪崩
2.缓存击穿
3.缓存穿透
布隆过滤器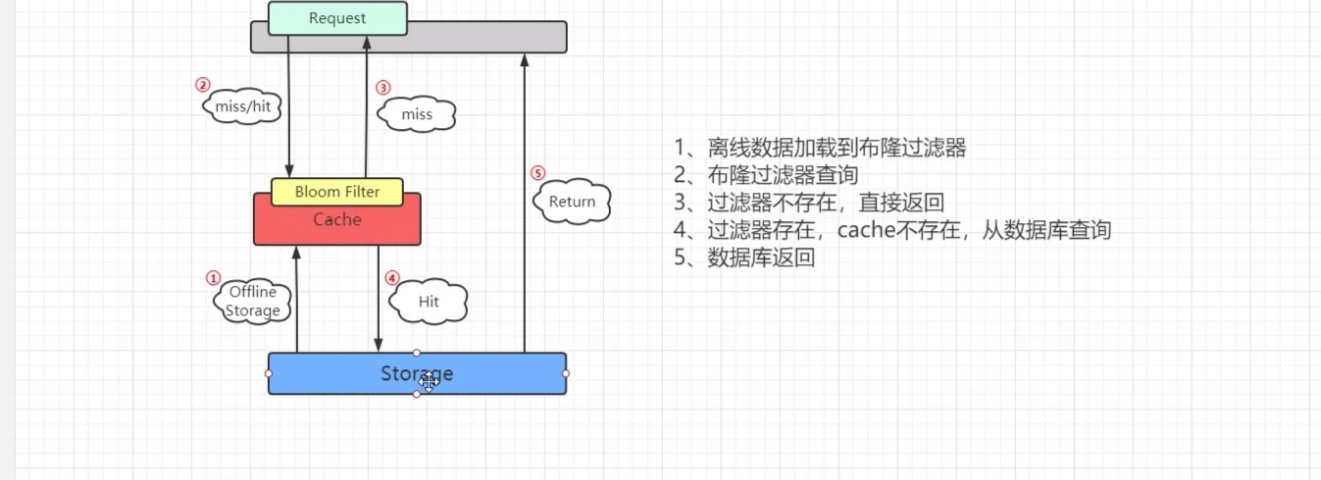
4.布隆过滤器
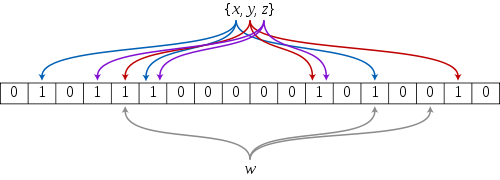
直观的说,bloom算法类似一个hash set,用来判断某个元素(key)是否在某个集合中。
和一般的hash set不同的是,这个算法无需存储key的值,对于每个key,只需要k个比特位,每个存储一个标志,用来判断key是否在集合中。
算法:
1. 首先需要k个hash函数,每个函数可以把key散列成为1个整数
2. 初始化时,需要一个长度为n比特的数组,每个比特位初始化为0
3. 某个key加入集合时,用k个hash函数计算出k个散列值,并把数组中对应的比特位置为1
4. 判断某个key是否在集合时,用k个hash函数计算出k个散列值,并查询数组中对应的比特位,如果所有的比特位都是1,认为在集合中。
优点:不需要存储key,节省空间
缺点:
1. 算法判断key在集合中时,有一定的概率key其实不在集合中
2. 无法删除
典型的应用场景:
某些存储系统的设计中,会存在空查询缺陷:当查询一个不存在的key时,需要访问慢设备,导致效率低下。
比如一个前端页面的缓存系统,可能这样设计:先查询某个页面在本地是否存在,如果存在就直接返回,如果不存在,就从后端获取。但是当频繁从缓存系统查询一个页面时,缓存系统将会频繁请求后端,把压力导入后端。
这是只要增加一个bloom算法的服务,后端插入一个key时,在这个服务中设置一次
需要查询后端时,先判断key在后端是否存在,这样就能避免后端的压力。
布隆过滤器[1](Bloom Filter)是由布隆(Burton Howard Bloom)在1970年提出的。它实际上是由一个很长的二进制向量和一系列随机映射函数组成,布隆过滤器可以用于检索一个元素是否在一个集合中。它的优点是空间效率和查询时间都远远超过一般的算法,缺点是有一定的误识别率(假正例False positives,即Bloom Filter报告某一元素存在于某集合中,但是实际上该元素并不在集合中)和删除困难,但是没有识别错误的情形(即假反例False negatives,如果某个元素确实没有在该集合中,那么Bloom Filter 是不会报告该元素存在于集合中的,所以不会漏报)。
在日常生活中,包括在设计计算机软件时,我们经常要判断一个元素是否在一个集合中。比如在字处理软件中,需要检查一个英语单词是否拼写正确(也就是要判断 它是否在已知的字典中);在 FBI,一个嫌疑人的名字是否已经在嫌疑名单上;在网络爬虫里,一个网址是否被访问过等等。最直接的方法就是将集合中全部的元素存在计算机中,遇到一个新 元素时,将它和集合中的元素直接比较即可。一般来讲,计算机中的集合是用哈希表(hash table)来存储的。它的好处是快速准确,缺点是费存储空间。当集合比较小时,这个问题不显著,但是当集合巨大时,哈希表存储效率低的问题就显现出来 了。比如说,一个象 Yahoo,Hotmail 和 Gmai 那样的公众电子邮件(email)提供商,总是需要过滤来自发送垃圾邮件的人(spamer)的垃圾邮件。一个办法就是记录下那些发垃圾邮件的 email 地址。由于那些发送者不停地在注册新的地址,全世界少说也有几十亿个发垃圾邮件的地址,将他们都存起来则需要大量的网络服务器。如果用哈希表,每存储一亿 个 email 地址, 就需要 1.6GB 的内存(用哈希表实现的具体办法是将每一个 email 地址对应成一个八字节的信息指纹(详见:googlechinablog.com/2006/08/blog-post.html), 然后将这些信息指纹存入哈希表,由于哈希表的存储效率一般只有 50%,因此一个 email 地址需要占用十六个字节。一亿个地址大约要 1.6GB, 即十六亿字节的内存)。因此存贮几十亿个邮件地址可能需要上百 GB 的内存。除非是超级计算机,一般服务器是无法存储的[2]。(该段引用谷歌数学之美:http://www.google.com.hk/ggblog/googlechinablog/2007/07/bloom-filter_7469.html)
5.redisson
分布式redis利器
https://github.com/redisson/redisson/wiki/Table-of-Content

若有收获,就点个赞吧
0 人点赞
