1.基本数据类型
通用存储结构
1.redisDb
redis数据库数据类型 在服务启动的时候会根据configured来初始化数据库的数量 默认是16个
typedef struct redisDb {dict *dict; /* The keyspace for this DB key 空间*/ /*hash存储key value*/dict *expires; /* Timeout of keys with a timeout set 超时key的集合 再惰性删除和定时删除的时候使用 */dict *blocking_keys; /* Keys with clients waiting for data (BLPOP) 堵塞读的key*/dict *ready_keys; /* Blocked keys that received a PUSH 收到的堵塞key*/dict *watched_keys; /* WATCHED keys for MULTI/EXEC CAS */int id; /* Database ID 数据库id */long long avg_ttl; /* Average TTL, just for stats */unsigned long expires_cursor; /* Cursor of the active expire cycle. */list *defrag_later; /* List of key names to attempt to defrag one by one, gradually. */} redisDb;
2.dict
typedef struct dict {dictType *type;void *privdata;dictht ht[2];long rehashidx; /* rehashing not in progress if rehashidx == -1 */unsigned long iterators; /* number of iterators currently running */} dict;
3.dictht 真正的hash表实现
如注释所示dict维护了两个哈希字典来做扩容
/* This is our hash table structure. Every dictionary has two of this as we* implement incremental rehashing, for the old to the new table. */typedef struct dictht {dictEntry **table;unsigned long size;unsigned long sizemask;unsigned long used;} dictht;
4.dictEntry
typedef struct dictEntry {void *key; //key 的指针union {void *val; //值uint64_t u64;int64_t s64;double d;} v;struct dictEntry *next;//下一个} dictEntry;
5. redisobject
redisobject居然也不是真正的存储数据结构而是多封了一层再指向真正的存储结构.
- 第一,可以改进内部编码,而对外的数据结构和命令没有影响,这样一旦开发开发出优秀的内部编码,无需改动外部数据结构和命令。
- 第二,多种内部编码实现可以在不同场景下发挥各自的优势。例如ziplist比较节省内存,但是在列表元素比较多的情况下,性能会有所下降,
为了节省宝贵的性能 redis优先选择内存占用小的数据结构来存储数据。这样多封一层就能解耦
typedef struct redisObject {unsigned type:4; // type类型unsigned encoding:4; // encoding类型unsigned lru:LRU_BITS; /* LRU time (relative to global lru_clock) or* LFU data (least significant 8 bits frequency* and most significant 16 bits access time). */int refcount;void *ptr;} robj;
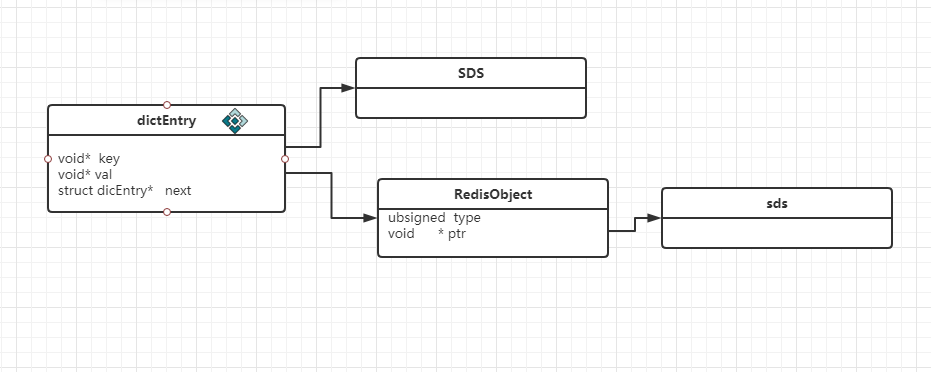
redisDb (简单认为是一个哈希表) 根据key获取 dictEntry —->redisObject —->具体encoding的数据实现
2.常用数据结构
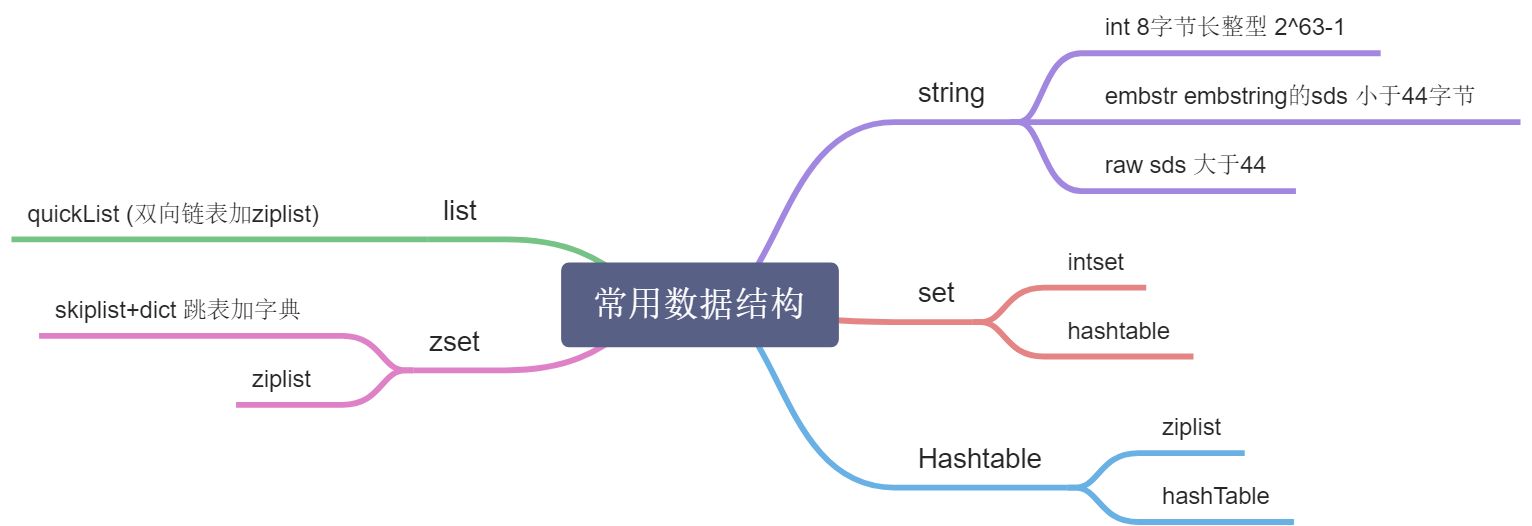
1.string
1.常用命令
//set 命令set name loafer//返回长度strlen name/** 添加至key的末尾 数据类型立刻转换成 raw*/append name bigdick/* 如果不存在则插入 返回影响条数 可以用来做分布式锁 */setnx name 123/*批量插入*/mset [key1] [value1] [key2] [value2]/*批量获取*/mget [key1][key2]// 步长++incr [key]// 步长++incrby [key] [步长]// --decr [key]// --步长decrby [key] [步长]//浮点数 ++incrbybyfloat [key] [步长]
2.数据结构
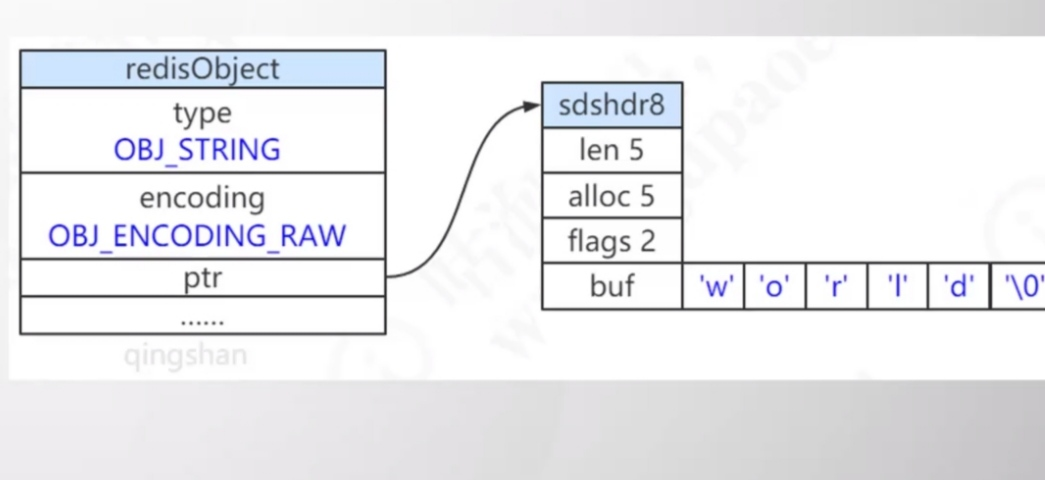
- int 8字节长整型 2^63-1
- embstr embstring的sds 小于44字节
- raw sds 大于44
 可以在redis源码中验证 可以看到该方法在 44位以下 createEmbeddedStringObject 之上返回createRawStringObject(ptr,len);
可以在redis源码中验证 可以看到该方法在 44位以下 createEmbeddedStringObject 之上返回createRawStringObject(ptr,len);/* Create a string object with EMBSTR encoding if it is smaller than* OBJ_ENCODING_EMBSTR_SIZE_LIMIT, otherwise the RAW encoding is* used.** The current limit of 44 is chosen so that the biggest string object* we allocate as EMBSTR will still fit into the 64 byte arena of jemalloc. */#define OBJ_ENCODING_EMBSTR_SIZE_LIMIT 44robj *createStringObject(const char *ptr, size_t len) {if (len <= OBJ_ENCODING_EMBSTR_SIZE_LIMIT)return createEmbeddedStringObject(ptr,len);elsereturn createRawStringObject(ptr,len);}
需要注意的是 int ->embstr ->raw 是不可逆的 不会随着数据量变小而变回int
2.SDS simple dynamic string
简单动态字符串
- 常数复杂度获得字符串长度。
- 杜绝缓冲区溢出。
- 减少修改字符串长度时所需的内存重分配次数。
- 二进制安全。
兼容部分C字符串函数
struct sdshdr {// buf 中已占用空间的长度int len;// buf 中剩余可用空间的长度int free;// 数据空间char buf[];};
3.常用场景
1.缓存 缓存json
2.分布式会话
3.分布式锁 setnx ex (需要设置获取锁的超时时间,不然会出现死锁)
4.分布式全局id
5.分布式计算器
6.限流计数器
7.位操作
…….
2.Hash 哈希
哈希表就是用一个 key 管理大量的子key -value (field -value)键值对 需要注意的 field 不能分片存储

1.常用命令
hset [key] [field] [value] //设置hmset [key] [f1] [v1] [f2] [v2] // 批量设值hget h1 ahmget [key] [v1] [v2]hkeys [name] //显示全部的key值hcals [name] //显示全部的value值hgetall [name] //显示全部的key value值hdel [name] [f] //删除对应属性hlen [name] //哈希表有几个键值对del [name] 删除
2.数据结构

1.ziplist
- zlbytes: ziplist的长度(单位: 字节),是一个32位无符号整数
- zltail: ziplist最后一个节点的偏移量,反向遍历ziplist或者pop尾部节点的时候有用。
- zllen: ziplist的节点(entry)个数
- entry: 节点
- zlend: 值为0xFF,用于标记ziplist的结尾
普通数组的遍历是根据数组里存储的数据类型 找到下一个元素的,例如int类型的数组访问下一个元素时每次只需要移动一个sizeof(int)就行(实际上开发者只需让指针p+1就行,在这里引入sizeof(int)只是为了说明区别)。
上文说了,ziplist的每个节点的长度是可以不一样的,而我们面对不同长度的节点又不可能直接sizeof(entry),那么它是怎么访问下一个节点呢?
ziplist将一些必要的偏移量信息记录在了每一个节点里,使之能跳到上一个节点或下一个节点。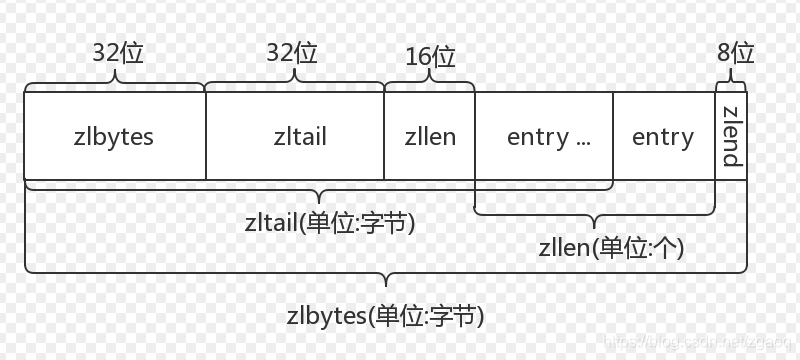
每个节点由三部分组成:prevlength、encoding、data
- prevlengh: 记录上一个节点的长度,为了方便反向遍历ziplist
- encoding: 当前节点的编码规则,下文会详细说
- data: 当前节点的值,可以是数字或字符串
为了节省内存,根据上一个节点的长度prevlength 可以将ziplist节点分为两类:
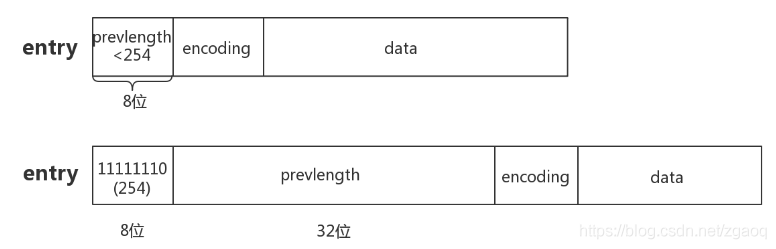
- entry的前8位小于254,则这8位就表示上一个节点的长度
- entry的前8位等于254,则意味着上一个节点的长度无法用8位表示,后面32位才是真实的prevlength。用254 不用255(11111111)作为分界是因为255是zlend的值,它用于判断ziplist是否到达尾部。
根据当前节点存储的数据类型及长度,可以将ziplist节点分为9类:
其中整数节点分为6类: 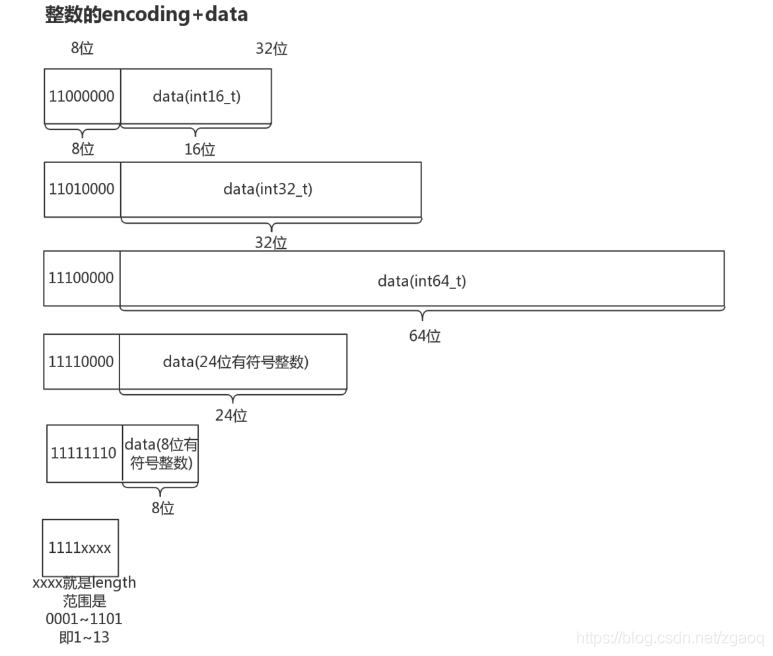
2.HashMap
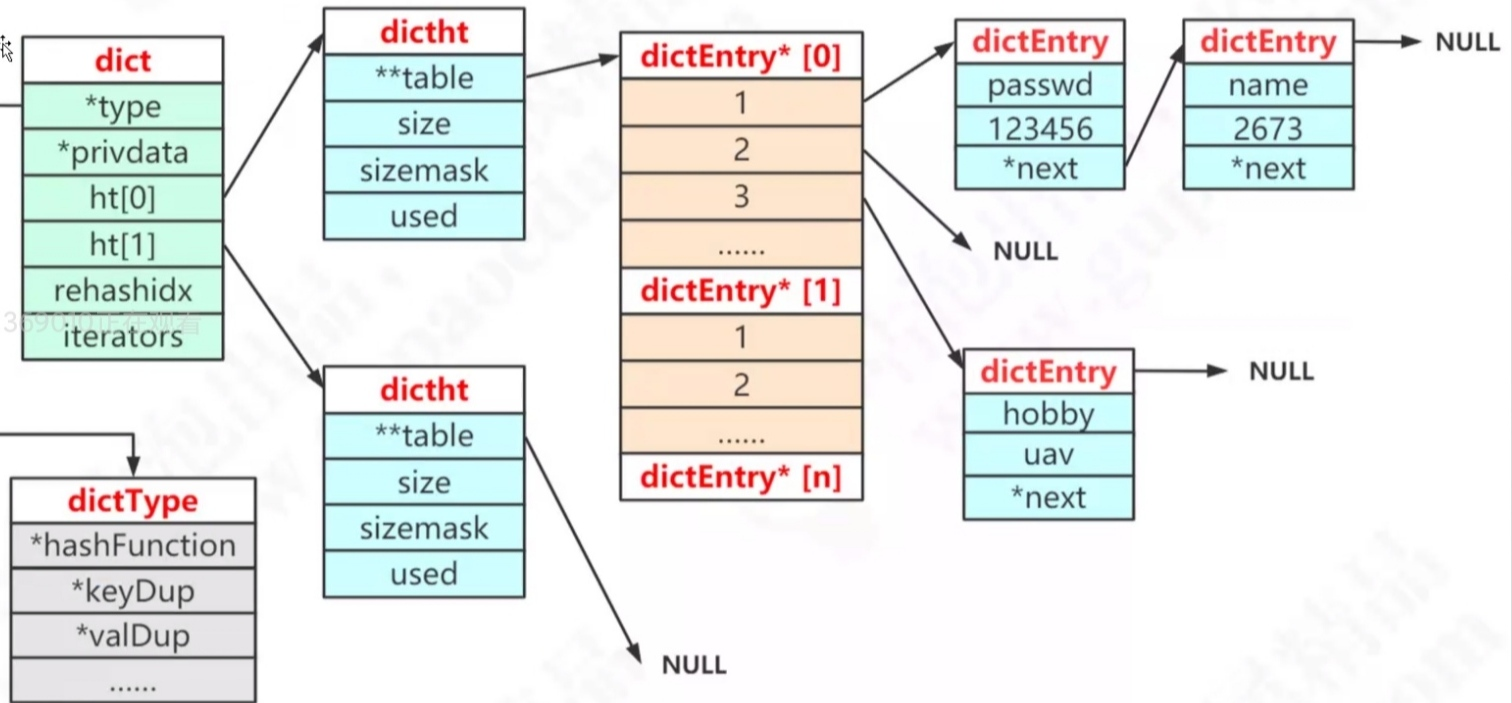
持有一个空的哈希表的目的就是为了 rehash扩容时用 可以在源码中看见hash碰撞的因子是5
static unsigned int dict_force_resize_ratio = 5;
3.常用场景
sting能做的hash基本也能做
特殊场景购物车

3. list (队列 ,栈)
1.常用命令

2,数据结构 quicklist 双向链表+ ziplist
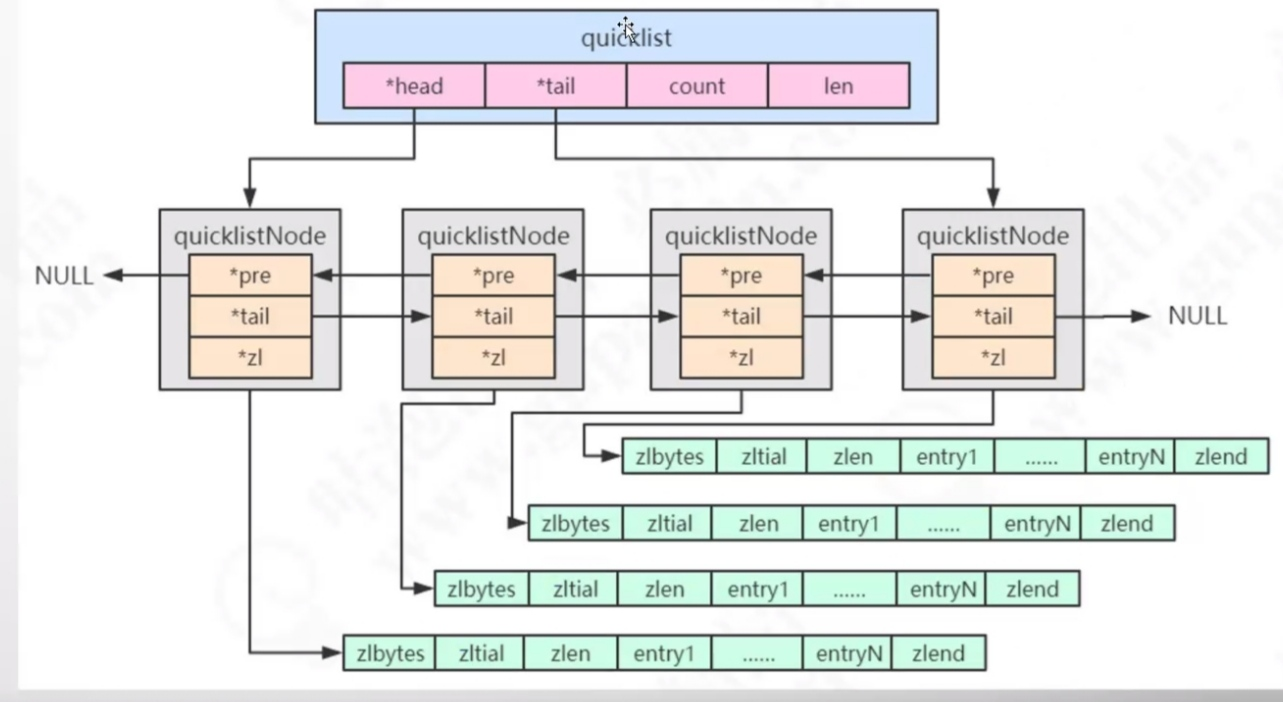
3,应用场景
1.消息队列
2.文章链表
3.评论链表
4 xxx列表….
因为有 blpop brpop 堵塞读方法就可以用来实现简单的消息队列.
4. set
1.常用命令
sadd [key] [v1] [v2] [v3]....//显示set内的值smembers [name]// set的长度scard [name]// 随机返回不删除srandmember [name]//随机弹出spop [name]//删除元素srem [v1] [v2]//是否在集合中sismember [name] [v1]
2. 数据结构
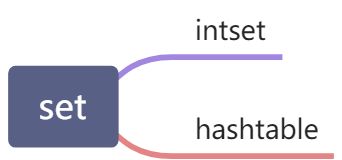 根据配置文件 intset —>hashtable
根据配置文件 intset —>hashtable
intset的实现非常简单
就是一个数组
intsetSearch 方法就是二分法查找
typedef struct intset {uint32_t encoding;uint32_t length;int8_t contents[];} intset;
static uint8_t intsetSearch(intset *is, int64_t value, uint32_t *pos) {int min = 0, max = intrev32ifbe(is->length)-1, mid = -1;int64_t cur = -1;if (intrev32ifbe(is->length) == 0) {if (pos) *pos = 0;return 0;} else {if (value > _intsetGet(is,intrev32ifbe(is->length)-1)) {//大于集合中最大的数if (pos) *pos = intrev32ifbe(is->length);return 0;} else if (value < _intsetGet(is,0)) {//小于集合中最小的数if (pos) *pos = 0;return 0;}}//采用二分查找算法进行搜索while(max >= min) {mid = ((unsigned int)min + (unsigned int)max) >> 1;cur = _intsetGet(is,mid);if (value > cur) {min = mid+1;} else if (value < cur) {max = mid-1;} else {break;}}if (value == cur) {//找到相同的元素if (pos) *pos = mid;return 1;} else {//未找到if (pos) *pos = min;return 0;}}
2. 常用场景(超好用)
- SINTER key [key …] //交集运算
- SINTERSTORE destination key [key ..] //将交集结果存入新集合destination中
- SUNION key [key ..] //并集运算
- SUNIONSTORE destination key [key …] //将并集结果存入新集合destination中
- SDIFF key [key …] //差集运算
- SDIFFSTORE destination key [key …] //将差集结果存入新集合destination中
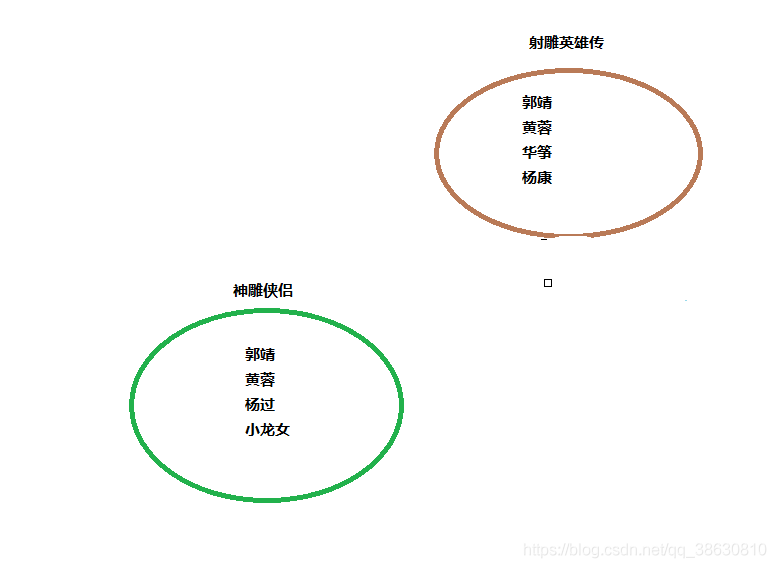
1. 127.0.0.1:6379> sadd shediao guojing huangrong huazheng yangkang2. (integer) 43. 127.0.0.1:6379> sadd shendiao guojing huangrong yangguo xiaolongnv4. (integer) 45. 127.0.0.1:6379> sinter shediao shendiao6. 1) "huangrong"7. 2) "guojing"8. 127.0.0.1:6379> sinterstore sheshendiao shediao shendiao9. (integer) 210. 127.0.0.1:6379> smembers sheshendiao11. 1) "huangrong"12. 2) "guojing"13. 127.0.0.1:6379> sunion shediao shendiao14. 1) "yangguo"15. 2) "xiaolongnv"16. 3) "yangkang"17. 4) "huangrong"18. 5) "guojing"19. 6) "huazheng"20. 127.0.0.1:6379> sunionstore shenshediao shediao shendiao21. (integer) 622. 127.0.0.1:6379> smembers shenshediao23. 1) "yangguo"24. 2) "xiaolongnv"25. 3) "yangkang"26. 4) "huangrong"27. 5) "guojing"28. 6) "huazheng"29. 127.0.0.1:6379> sdiff shediao shendiao30. 1) "huazheng"31. 2) "yangkang"32. 127.0.0.1:6379> sdiffstore diaoshenshe shediao shendiao33. (integer) 234. 127.0.0.1:6379> smembers diaoshenshe35. 1) "huazheng"36. 2) "yangkang"
1.点赞
- 点赞:sadd like_msg_10010 friend_1
- 取消点赞: srem like_msg_10010 friend_1
- 获取点赞用户列表:smembers like_msg_10010
- 获取点赞数量:scard like_msg_10010
2.共同关注
说这个关注模型首先得说明几个前提
xiaolinziSet(我关注的人): uzi 微博会员小秘书 lol无双小智 微博会员 55开 SDR 电竞练习生 不拉的P特
UZISet(UZI关注的人): lol无双小智 55开 微博会员小秘书 微博会员 xiaohu
xiaozhiSet(小智关注的人): UZI 小莫
我和UZI共同关注:sinter xiaolinziSet UZISet —————》》uzi 微博会员小秘书 lol无双小智 微博会员
【取交集】
我关注的人也关注UZI:sismember xiaozhiSet UZI
- 我可能认识的人:sdiff UZISet xiaolinziSet —————-》》 xiaohu
3.打标签
5. zset有序set
1.常用命令
//插入数据并赋值zadd myzset 10 java 20 php 30 ruby 40 cpp 50 python//根据分值排序 降序zrange myzset 0 -1 withscores//根据分值排序 显示0-2条zrange myzset 0 2 withscores//倒排序zrangebyscore myzset 20 30//长度zcard myzset//remove by keyzrem myzset php cpp//分值减5zincrby myzset 5 python//统计 20-60分的数据zcount myzset 20 60//第几名zrank myzset python//key的分数zscore myzset python
2. 数据结构
 如果长度小于128且所以长度小于64 ziplist 否则使用skiplist+dict 跳表加字典
如果长度小于128且所以长度小于64 ziplist 否则使用skiplist+dict 跳表加字典
1.跳表

/* ZSETs use a specialized version of Skiplists */typedef struct zskiplistNode {sds ele;double score; // zset分数struct zskiplistNode *backward;struct zskiplistLevel {struct zskiplistNode *forward; //后退指针unsigned long span; //跨度} level[]; //层} zskiplistNode;//跳表typedef struct zskiplist {struct zskiplistNode *header, *tail; // 指向跳表头尾unsigned long length; //长度int level; //最大层数} zskiplist;// zset实现typedef struct zset {dict *dict;zskiplist *zsl;} zset;
3.常用场景
1.微博热搜排行榜
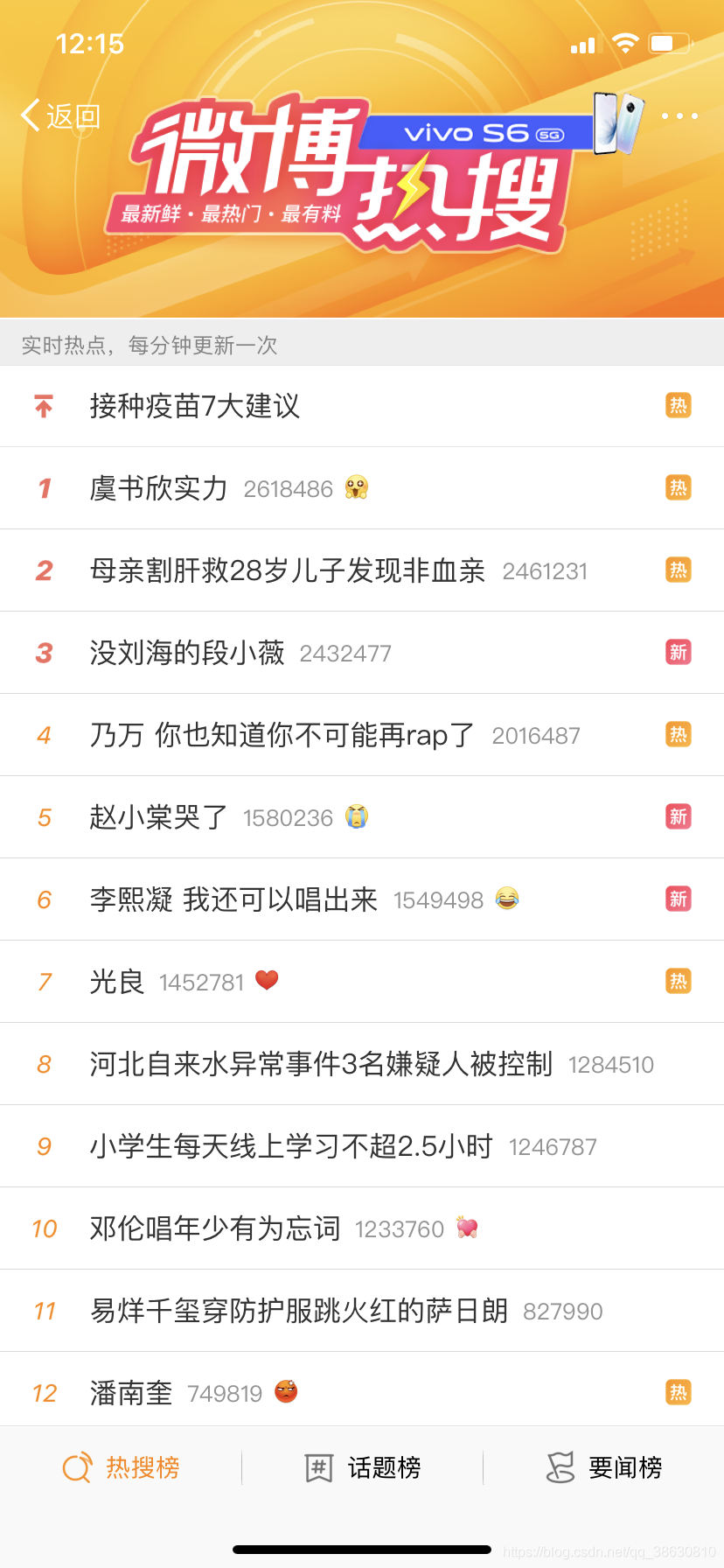
- 每点击一次新闻,增加一次浏览量: zincrby hotSearch_20200426 1 接种疫苗7大建议
- 展示当日热搜前十: zrevrange hotSearch_20200426 0 9 withscores
- 七日搜索榜单计算: zunionstore hotSearch_20200420-20200426 7 hotSearch_20200420 hotSearch_20200421 hotSearch_20200422 hotSearch_20200423 hotSearch_20200424 hotSearch_20200425 hotSearch_20200426
- 展示七日排行版前十:zrevrange hotSearch_20200420-20200426 0 9 withscores
3.其他数据类型
BitMap(状态判断 用户签到 统计活跃 用户在线)
就是通过一个bit位来表示某个元素对应的值或者状态,其中的key就是对应元素本身。我们知道8个bit可以组成一个Byte,所以bitmap本身会极大的节省储存空间。
setbit命令介绍
指令 SETBIT key offset value
设置或者清空key的value(字符串)在offset处的bit值(只能只0或者1)。
空间占用、以及第一次分配空间需要的时间
在一台2010MacBook Pro上,offset为230-1(分配128MB)需要~80ms,offset为226-1(分配8MB)需要8ms。<来自官方文档>
大概的空间占用计算公式是:($offset/8/1024/1024)MB
使用场景一:用户签到
很多网站都提供了签到功能(这里不考虑数据落地事宜),并且需要展示最近一个月的签到情况,如果使用bitmap我们怎么做?一言不合亮代码!
根据日期 offset =hash % 365 ; key = 年份#用户id
使用场景二:统计活跃用户
使用时间作为cacheKey,然后用户ID为offset,如果当日活跃过就设置为1
那么我该如果计算某几天/月/年的活跃用户呢(暂且约定,统计时间内只有有一天在线就称为活跃),有请下一个redis的命令
命令 BITOP operation destkey key [key …]
说明:对一个或多个保存二进制位的字符串 key 进行位元操作,并将结果保存到 destkey 上。
说明:BITOP 命令支持 AND 、 OR 、 NOT 、 XOR 这四种操作中的任意一种参数
20190216 活跃用户 【1,2】
20190217 活跃用户 【1】
统计20190216~20190217 总活跃用户数: 1
统计20190216~20190217 在线活跃用户数: 2
使用场景三:用户在线状态
前段时间开发一个项目,对方给我提供了一个查询当前用户是否在线的接口。不了解对方是怎么做的,自己考虑了一下,
使用bitmap是一个节约空间效率又高的一种方法,只需要一个key,然后用户ID为offset,如果在线就设置为1,
不在线就设置为0,和上面的场景一样,5000W用户只需要6MB的空间。
geospatial 地理空间(附近的xx 打车距离计算)
朋友的定位,附近的人,打车距离的计算
Redis的Geo,3.2版本推出,可以推算地理位置的信息,两地之间的距离
城市经纬度查询:http://www.jsons.cn/lngcode/
geoadd
# geoadd 先经度后维度(官方文档疑似写错了)127.0.0.1:6379[1]> geoadd china:city 39.9 116.4 beijing(error) ERR invalid longitude,latitude pair 39.900000,116.400000经纬度反了会报错# 两极无法直接添加!南北极,而且我们一般会下载城市数据通过java程序一次性导入127.0.0.1:6379[1]> geoadd china:city 116.4 39.9 beijing# 批量 geoadd china:city 116.4 39.9 beijing 121.4 31.2 shanghai 114.1 22.5 shenzhen 113.3 23.1 guangzhou 114.2 22.3 xianggang 113.5 22.2 aomen 121.9 29.5 xiangshan(integer) 1127.0.0.1:6379[1]> geoadd china:city 121.4 31.2 shanghai(integer) 1127.0.0.1:6379[1]> geoadd china:city 114.1 22.5 shenzhen(integer) 1127.0.0.1:6379[1]> geoadd china:city 113.3 23.1 guangzhou(integer) 1127.0.0.1:6379[1]> geoadd china:city 114.2 22.3 xianggang(integer) 1127.0.0.1:6379[1]> geoadd china:city 113.5 22.2 aomen(integer) 1127.0.0.1:6379[1]> geoadd china:city 121.9 29.5 xiangshan(integer) 1
geopost
# 获取地理位置127.0.0.1:6379[1]> GEOPOS china:city beijing shanghai shenzhen xianggang1) 1) "116.39999896287918091"2) "39.90000009167092543"2) 1) "121.40000134706497192"2) "31.20000061483705878"3) 1) "114.09999936819076538"2) "22.50000113800319212"4) 1) "114.19999748468399048"2) "22.29999896492555678"
geodist
两人之间的直线距离
- m 表示单位为米。
- km 表示单位为千米。
- mi 表示单位为英里。
- ft 表示单位为英尺。
127.0.0.1:6379[1]> GEODIST china:city beijing xianggang"1968579.6084"127.0.0.1:6379[1]> GEODIST china:city beijing xianggang m"1968579.6084"127.0.0.1:6379[1]> GEODIST china:city beijing xianggang km"1968.5796"127.0.0.1:6379[1]> GEODIST china:city beijing xianggang ft"6458594.5159"127.0.0.1:6379[1]> GEODIST china:city beijing xianggang mi"1223.2217"
georadius
以给定的经纬度为中心,找出某一半径内所有的元素 实现附近的人: 1、获取所有附近的人的地址(GPS)
# 范围查找 经度110 纬度 30为圆心 半径100km内所有的城市127.0.0.1:6379[1]> GEORADIUS china:city 110 30 100 km(empty list or set)# 范围查找 经度110 纬度 30为圆心 半径1000km内所有的城市127.0.0.1:6379[1]> GEORADIUS china:city 110 30 1000 km1) "aomen"2) "xianggang"3) "shenzhen"4) "guangzhou"# 范围查找 经度110 纬度 30为圆心 半径100km内所有的城市 带上经纬度和城市距离该点的直线距离127.0.0.1:6379[1]> GEORADIUS china:city 110 30 1000 km withcoord withdist1) 1) "aomen"2) "935.1758"3) 1) "113.49999994039535522"2) "22.19999914574732003"2) 1) "xianggang"2) "953.3433"3) 1) "114.19999748468399048"2) "22.29999896492555678"3) 1) "shenzhen"2) "928.8366"3) 1) "114.09999936819076538"2) "22.50000113800319212"4) 1) "guangzhou"2) "834.6077"3) 1) "113.29999834299087524"2) "23.10000005307264104"# count 控制个数127.0.0.1:6379[1]> GEORADIUS china:city 110 30 1000 km withcoord withdist count 21) 1) "guangzhou"2) "834.6077"3) 1) "113.29999834299087524"2) "23.10000005307264104"2) 1) "shenzhen"2) "928.8366"3) 1) "114.09999936819076538"2) "22.50000113800319212"# GEORADIUSBYMEMBER 根据给定的元素确定中心点,再进行查找127.0.0.1:6379[1]> GEORADIUSBYMEMBER china:city shanghai 1000 km withdist1) 1) "xiangshan"2) "195.0791"2) 1) "shanghai"2) "0.0000"127.0.0.1:6379[1]> GEORADIUSBYMEMBER china:city shanghai 2000 km withdist1) 1) "aomen"2) "1271.1657"2) 1) "xianggang"2) "1220.4023"3) 1) "shenzhen"2) "1207.9869"4) 1) "guangzhou"2) "1205.0747"5) 1) "xiangshan"2) "195.0791"6) 1) "shanghai"2) "0.0000"7) 1) "beijing"2) "1067.7424"# GEOHASH 将二维的经纬度转换为一维的字符串,经过hash之后的结果## 如果两个字符串越像,则代表越接近!#127.0.0.1:6379[1]> GEOHASH china:city beijing shanghai1) "wx4fbxxfke0"2) "wtw36xbc1j0"
HyperLogLog(基数统计)
Redis 在 2.8.9 版本添加了 HyperLogLog 结构。
Redis HyperLogLog 是用来做基数统计的算法,HyperLogLog 的优点是,在输入元素的数量或者体积非常非常大时,计算基数所需的空间总是固定 的、并且是很小的。
在 Redis 里面,每个 HyperLogLog 键只需要花费 12 KB 内存,就可以计算接近 2^64 个不同元素的基 数。这和计算基数时,元素越多耗费内存就越多的集合形成鲜明对比。
但是,因为 HyperLogLog 只会根据输入元素来计算基数,而不会储存输入元素本身,所以 HyperLogLog 不能像集合那样,返回输入的各个元素。
stream
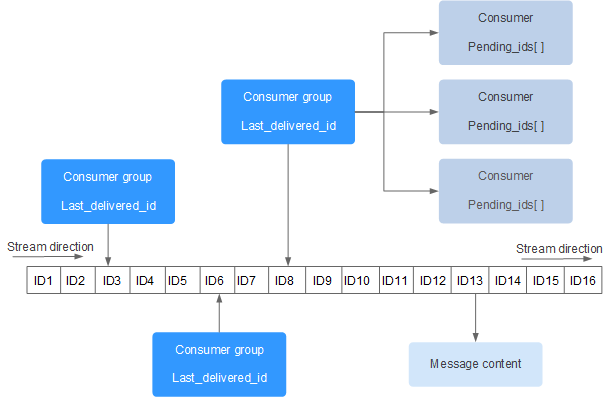
消息队列相关命令:
- XADD - 添加消息到末尾
- XTRIM - 对流进行修剪,限制长度
- XDEL - 删除消息
- XLEN - 获取流包含的元素数量,即消息长度
- XRANGE - 获取消息列表,会自动过滤已经删除的消息
- XREVRANGE - 反向获取消息列表,ID 从大到小
- XREAD - 以阻塞或非阻塞方式获取消息列表
消费者组相关命令:
- XGROUP CREATE - 创建消费者组
- XREADGROUP GROUP - 读取消费者组中的消息
- XACK - 将消息标记为”已处理”
- XGROUP SETID - 为消费者组设置新的最后递送消息ID
- XGROUP DELCONSUMER - 删除消费者
- XGROUP DESTROY - 删除消费者组
- XPENDING - 显示待处理消息的相关信息
- XCLAIM - 转移消息的归属权
- XINFO - 查看流和消费者组的相关信息;
- XINFO GROUPS - 打印消费者组的信息;
- XINFO STREAM - 打印流信息
3.总结
redis会优先选用内存占用少的数据结构在数据量扩大的时候再转换为时间复杂度少的数据结构。
ziplist就是典型的时间换空间的结构 所以 zset hashtable在数据较少的时候都采用ziplist
redisobject 不仅仅是解耦这一层 也做了 lru和fru等缓存删除策略

若有收获,就点个赞吧
0 人点赞
