- 1.redis 高级功能
- 订阅者的客户端会显示如下消息
1) “message”
2) “runoobChat”
3) “Redis PUBLISH test”
1) “message”
2) “runoobChat”
3) “Learn redis by runoob.com”
gif 演示如下: - 1.2.事务(来自菜鸟教程)
- 1.3.lua脚本(来自菜鸟教程)
- 1.4 lua脚本的应用
- 1.5 管道 【数据冷备,大批量key】
- 管道技术的优势
- 2.redis的持久化 [备份,恢复]
- 3.redis的内存策略[内存淘汰机制,内存满了怎么办?]
- 3.2 LRU算法 最近没使用的删除
- 3.3LFU(最近最少使用的算法)
- 4.redis为什么如此快?【单线程,多路io复用,纯内存的】
1.redis 高级功能
1.1 发布订阅(来自菜鸟教程)
Redis 发布订阅 (pub/sub) 是一种消息通信模式:发送者 (pub) 发送消息,订阅者 (sub) 接收消息。
Redis 客户端可以订阅任意数量的频道。
下图展示了频道 channel1 , 以及订阅这个频道的三个客户端 —— client2 、 client5 和 client1 之间的关系: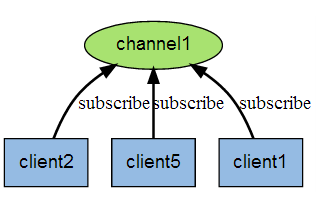
当有新消息通过 PUBLISH 命令发送给频道 channel1 时, 这个消息就会被发送给订阅它的三个客户端: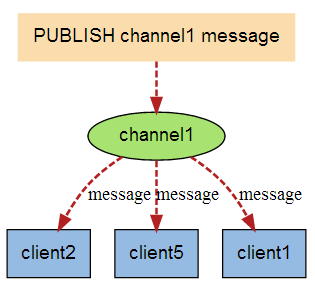
实例
以下实例演示了发布订阅是如何工作的,需要开启两个 redis-cli 客户端。
在我们实例中我们创建了订阅频道名为 runoobChat:
第一个 redis-cli 客户端
redis 127.0.0.1:6379> SUBSCRIBE runoobChat
Reading messages… (press Ctrl-C to quit)
1) “subscribe”
2) “redisChat”
3) (integer) 1
现在,我们先重新开启个 redis 客户端,然后在同一个频道 runoobChat 发布两次消息,订阅者就能接收到消息。
第二个 redis-cli 客户端
redis 127.0.0.1:6379> PUBLISH runoobChat “Redis PUBLISH test”
(integer) 1
redis 127.0.0.1:6379> PUBLISH runoobChat “Learn redis by runoob.com”
(integer) 1
订阅者的客户端会显示如下消息
1) “message”
2) “runoobChat”
3) “Redis PUBLISH test”
1) “message”
2) “runoobChat”
3) “Learn redis by runoob.com”
gif 演示如下:
- 开启本地 Redis 服务,开启两个 redis-cli 客户端。
- 在第一个 redis-cli 客户端输入 SUBSCRIBE runoobChat,意思是订阅
runoobChat频道。 - 在第二个 redis-cli 客户端输入 PUBLISH runoobChat “Redis PUBLISH test” 往 runoobChat 频道发送消息,这个时候在第一个 redis-cli 客户端就会看到由第二个 redis-cli 客户端发送的测试消息。

Redis 发布订阅命令
下表列出了 redis 发布订阅常用命令:
| 序号 | 命令及描述 |
|---|---|
| 1 | PSUBSCRIBE pattern [pattern …] 订阅一个或多个符合给定模式的频道。 |
| 2 | PUBSUB subcommand [argument [argument …]] 查看订阅与发布系统状态。 |
| 3 | PUBLISH channel message 将信息发送到指定的频道。 |
| 4 | PUNSUBSCRIBE [pattern [pattern …]] 退订所有给定模式的频道。 |
| 5 | SUBSCRIBE channel [channel …] 订阅给定的一个或多个频道的信息。 |
| 6 | UNSUBSCRIBE [channel [channel …]] 指退订给定的频道。 |
1.2.事务(来自菜鸟教程)
需要注意的是 redis事务不是真的事务 只是一组堵塞原子性的操作 并不能失败回滚
比如 事务{1.set name 123,2.set dick 100,3.gat name 123}
可见第三个命令错误,但是1 ,2 命令还是能执行成功
实例
以下是一个事务的例子, 它先以 MULTI 开始一个事务, 然后将多个命令入队到事务中, 最后由 EXEC 命令触发事务, 一并执行事务中的所有命令:
redis 127.0.0.1:6379> MULTI
OK
redis 127.0.0.1:6379> SET book-name “Mastering C++ in 21 days”
QUEUED
redis 127.0.0.1:6379> GET book-name
QUEUED
redis 127.0.0.1:6379> SADD tag “C++” “Programming” “Mastering Series”
QUEUED
redis 127.0.0.1:6379> SMEMBERS tag
QUEUED
redis 127.0.0.1:6379> EXEC
1) OK
2) “Mastering C++ in 21 days”
3) (integer) 3
4) 1) “Mastering Series”
2) “C++”
3) “Programming”
单个 Redis 命令的执行是原子性的,但 Redis 没有在事务上增加任何维持原子性的机制,所以 Redis 事务的执行并不是原子性的。
事务可以理解为一个打包的批量执行脚本,但批量指令并非原子化的操作,中间某条指令的失败不会导致前面已做指令的回滚,也不会造成后续的指令不做。
这是官网上的说明 From redis docs on transactions: It’s important to note that even when a command fails, all the other commands in the queue are processed – Redis will not stop the processing of commands.
比如:
redis 127.0.0.1:7000> multi
OK
redis 127.0.0.1:7000> set a aaa
QUEUED
redis 127.0.0.1:7000> set b bbb
QUEUED
redis 127.0.0.1:7000> set c ccc
QUEUED
redis 127.0.0.1:7000> exec
1) OK
2) OK
3) OK
如果在 set b bbb 处失败,set a 已成功不会回滚,set c 还会继续执行。
Redis 事务命令
下表列出了 redis 事务的相关命令:
| 序号 | 命令及描述 |
|---|---|
| 1 | DISCARD 取消事务,放弃执行事务块内的所有命令。 |
| 2 | EXEC 执行所有事务块内的命令。 |
| 3 | MULTI 标记一个事务块的开始。 |
| 4 | UNWATCH 取消 WATCH 命令对所有 key 的监视。 |
| 5 | WATCH key [key …] 监视一个(或多个) key ,如果在事务执行之前这个(或这些) key 被其他命令所改动,那么事务将被打断。 |
1.3.lua脚本(来自菜鸟教程)
lua脚本也是原子性的 lua脚本在运行时会堵塞main线程 也不能失败回滚
比如 “redis.call(‘set’,’name’,’888’) redis.call(‘set’,’name’,’dickson’) redis.call(‘gat’)”
一二两条命令依然执行。
避免lua脚本死循环 “while(1){}” 这样的脚本会导致redis服务器堵塞不可用,需要注意
Redis 脚本使用 Lua 解释器来执行脚本。 Redis 2.6 版本通过内嵌支持 Lua 环境。执行脚本的常用命令为 EVAL。
语法
Eval 命令的基本语法如下:
redis 127.0.0.1:6379> EVAL script numkeys key [key …] arg [arg …]
实例
以下实例演示了 redis 脚本工作过程:
redis 127.0.0.1:6379> EVAL “return {KEYS[1],KEYS[2],ARGV[1],ARGV[2]}” 2 key1 key2 first second
1) “key1”
2) “key2”
3) “first”
4) “second”
Redis 脚本命令
下表列出了 redis 脚本常用命令:
| 序号 | 命令及描述 |
|---|---|
| 1 | EVAL script numkeys key [key …] arg [arg …] 执行 Lua 脚本。 |
| 2 | EVALSHA sha1 numkeys key [key …] arg [arg …] 执行 Lua 脚本。 |
| 3 | SCRIPT EXISTS script [script …] 查看指定的脚本是否已经被保存在缓存当中。 |
| 4 | SCRIPT FLUSH 从脚本缓存中移除所有脚本。 |
| 5 | SCRIPT KILL 杀死当前正在运行的 Lua 脚本。 |
| 6 | SCRIPT LOAD script 将脚本 script 添加到脚本缓存中,但并不立即执行这个脚本。 |
1.4 lua脚本的应用
1.4.1 ip限流
local num = redis.call('incr',KEYS[1]) // 计算加1 不存在会创建if tonumber(num) == 1 thenredis.call('expire',KEYS[1],ARGV[1]) // 设置过期时间return 1elseif tonumber(num) > tonumber(ARGV[2]) thenreturn 0elsereturn 1end
执行 lua脚本
6秒钟限时访问10次
redis-cil --eval "[脚本名]" app:ip:limit:[ip],6 10
1.4.2 分布式锁
需要注意的是该脚本只是个DEMO 该实现本身是有问题的,虽然redisson也是用lua脚本实现的分布式锁。
该实现是有问题的 不设置锁有效时间的情况下 如果一台服务器突然暴毙会导致死锁 导致整个集群堵塞,设置的锁有效期太短也会导致锁被其他线程获取破坏了线程的互斥性 出现线程问题 如果需要使用的话 请使用 Redisson的 锁实现 Redisson的锁会启动后会启动一个 时间轮的wathchdog 来定时延长锁的有效时间。如果服务器暴毙 watchdog也会暴毙。时间到了就会自动释放锁
private static final Long lockReleaseOK = 1L;static String luaScript = "if redis.call('get', KEYS[1]) == ARGV[1] then return redis.call('del',KEYS[1]) else return 0 end";// lua脚本,用来释放分布式锁public static boolean releaseLock(String key ,String lockValue){if(key == null || lockValue == null) {return false;}try {Jedis jedis = getJedisPool().getResource();Object res =jedis.eval(luaScript,Collections.singletonList(key),Collections.singletonList(lockValue));jedis.close();return res!=null && res.equals(lockReleaseOK);} catch (Exception e) {return false;}}
1.4.3 ETC
还有许多锁实现是需要用lua脚本实现的
lua脚本还可以快速修改数据等等…
1.5 管道 【数据冷备,大批量key】
1.5.1 为什么需要管道
管道类似于 batch 将命令一次性打包发给服务端 一次性处理大大的减少冷备大量数据的时间 需要注意的是redis是有个缓冲区 缓冲区满了了就发送 不是真的一次性发送大量命令。
1.5.2 简单使用(来自菜鸟教程)
Redis是一种基于客户端-服务端模型以及请求/响应协议的TCP服务。这意味着通常情况下一个请求会遵循以下步骤:
- 客户端向服务端发送一个查询请求,并监听Socket返回,通常是以阻塞模式,等待服务端响应。
- 服务端处理命令,并将结果返回给客户端。
Redis 管道技术
Redis 管道技术可以在服务端未响应时,客户端可以继续向服务端发送请求,并最终一次性读取所有服务端的响应。
实例
查看 redis 管道,只需要启动 redis 实例并输入以下命令:
$(echo -en “PING\r\n SET runoobkey redis\r\nGET runoobkey\r\nINCR visitor\r\nINCR visitor\r\nINCR visitor\r\n”; sleep 10) | nc localhost 6379
+PONG
+OK
redis
:1
:2
:3
以上实例中我们通过使用 PING 命令查看redis服务是否可用, 之后我们设置了 runoobkey 的值为 redis,然后我们获取 runoobkey 的值并使得 visitor 自增 3 次。
在返回的结果中我们可以看到这些命令一次性向 redis 服务提交,并最终一次性读取所有服务端的响应
管道技术的优势
一些测试数据
在下面的测试中,我们将使用Redis的Ruby客户端,支持管道技术特性,测试管道技术对速度的提升效果。
require ‘rubygems’
require ‘redis’
def bench(descr)
start = Time.now
yield
puts “#{descr} #{Time.now-start} seconds”
end
def without_pipelining
r = Redis.new
10000.times {
r.ping
}
end
def with_pipelining
r = Redis.new
r.pipelined {
10000.times {
r.ping
}
}
end
bench(“without pipelining”) {
without_pipelining
}
bench(“with pipelining”) {
with_pipelining
}
从处于局域网中的Mac OS X系统上执行上面这个简单脚本的数据表明,开启了管道操作后,往返延时已经被改善得相当低了。
without pipelining 1.185238 seconds
with pipelining 0.250783 seconds
如你所见,开启管道后,我们的速度效率提升了5倍。
2.redis的持久化 [备份,恢复]
2.1 RDB :Redis DataBase 记录快照
2.1.1 RDB默认配置
#文件路径dir ./# 文件名称dbfilename dump.rdb# Save the DB on disk:# 在几秒内至少多少key发生变化的时候 redis自己bgsave# save <seconds> <changes># Compress string objects using LZF when dump .rdb databases?# By default compression is enabled as it's almost always a win.# If you want to save some CPU in the saving child set it to 'no' but# the dataset will likely be bigger if you have compressible values or keys.# 是否 以lzf压缩rdbcompression yes# Since version 5 of RDB a CRC64 checksum is placed at the end of the file.# This makes the format more resistant to corruption but there is a performance# hit to pay (around 10%) when saving and loading RDB files, so you can disable it# for maximum performances.## RDB files created with checksum disabled have a checksum of zero that will# tell the loading code to skip the check.# 是否开启数据校验rdbchecksum yes
2.1.2 手动触发
- save
- bgsave
save会堵塞主线程非常不建议!
如果在执行bgsave的时候redis服务器继续set key的时候 redis会把改动的内容缓存起来等任务执行结束后再追加到rdb中
2.1.3 特点
优势:
- 二进制文件 适合备份和恢复
- 生成文件的过程不影响主进程 (bgsave)
- 大数据恢复速度快
劣势:
在 save
2.2 AOF:Append only file ,日志
2.2.1 默认配置
# By default Redis asynchronously dumps the dataset on disk. This mode is# good enough in many applications, but an issue with the Redis process or# a power outage may result into a few minutes of writes lost (depending on# the configured save points).## The Append Only File is an alternative persistence mode that provides# much better durability. For instance using the default data fsync policy# (see later in the config file) Redis can lose just one second of writes in a# dramatic event like a server power outage, or a single write if something# wrong with the Redis process itself happens, but the operating system is# still running correctly.## AOF and RDB persistence can be enabled at the same time without problems.# If the AOF is enabled on startup Redis will load the AOF, that is the file# with the better durability guarantees.## rdb模式足够满足大部分应用了,但是会丢失几分钟的数据# aof模式是为提高系统的耐操性,如果一个实例使用aof模式的持久化的话只会丢失几秒钟数据# aof 和rdb 可以良好的共存如果aof启动的话 会在实例启动的时候加载aof文件#开关 默认关闭的appendonly no# 默认名appendfilename "appendonly.aof"# no 表示不执行 fsync 有操作系统保证#always 表示每次都同步到磁盘# eversec 默认 表示每秒# appendfsync alwaysappendfsync everysec# appendfsync no
需要注意的是appendfsync always非常消耗性能
2.2.2 appendonly.aof到底是啥

2.2.3 aof流程
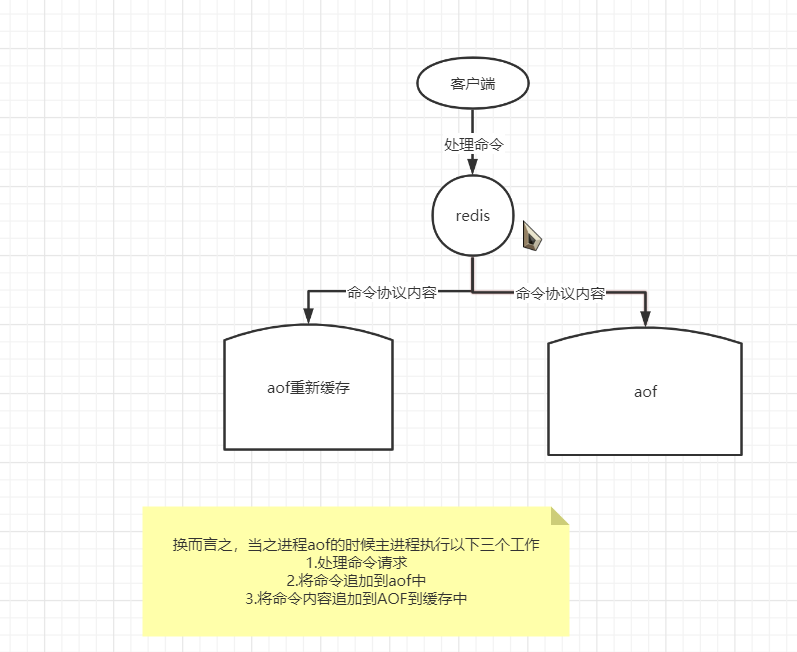
2.1.3 特点
- 可读
- 更加可靠
- 但是更加消耗性能
-
2.1.4 AOF重写
AOF重写可以由用户通过调用
BGREWRITEAOF手动触发。- 服务器在AOF功能开启的情况下,会维持以下三个变量:
- 记录当前AOF文件大小的变量
aof_current_size。 - 记录最后一次AOF重写之后,AOF文件大小的变量
aof_rewrite_base_size。 - 增长百分比变量
aof_rewrite_perc。
- 记录当前AOF文件大小的变量
- 每次当
serverCron(服务器周期性操作函数)函数执行时,它会检查以下条件是否全部满足,如果全部满足的话,就触发自动的AOF重写操作:- 没有BGSAVE命令(RDB持久化)/AOF持久化在执行;
- 没有BGREWRITEAOF在进行;
- 当前AOF文件大小要大于
server.aof_rewrite_min_size(默认为1MB),或者在redis.conf配置了auto-aof-rewrite-min-size大小; - 当前AOF文件大小和最后一次重写后的大小之间的比率等于或者等于指定的增长百分比(在配置文件设置了
auto-aof-rewrite-percentage参数,不设置默认为100%)
3.redis的内存策略[内存淘汰机制,内存满了怎么办?]
3.1 默认配置
# This option is usually useful when using Redis as an LRU or LFU cache, or to# set a hard memory limit for an instance (using the 'noeviction' policy).## WARNING: If you have replicas attached to an instance with maxmemory on,# the size of the output buffers needed to feed the replicas are subtracted# from the used memory count, so that network problems / resyncs will# not trigger a loop where keys are evicted, and in turn the output# buffer of replicas is full with DELs of keys evicted triggering the deletion# of more keys, and so forth until the database is completely emptied.## In short... if you have replicas attached it is suggested that you set a lower# limit for maxmemory so that there is some free RAM on the system for replica# output buffers (but this is not needed if the policy is 'noeviction').## 最大内存 默认配置32位系统好像是 2gb左右 64位会吃满内存# maxmemory <bytes># MAXMEMORY POLICY: how Redis will select what to remove when maxmemory# is reached. You can select one from the following behaviors:# 内存淘汰方法 注释很清楚# volatile-lru -> Evict using approximated LRU, only keys with an expire set.# allkeys-lru -> Evict any key using approximated LRU.# volatile-lfu -> Evict using approximated LFU, only keys with an expire set.# allkeys-lfu -> Evict any key using approximated LFU.# volatile-random -> Remove a random key having an expire set.# allkeys-random -> Remove a random key, any key.# volatile-ttl -> Remove the key with the nearest expire time (minor TTL)# noeviction -> Don't evict anything, just return an error on write operations.# LRU means Least Recently Used# LFU means Least Frequently Used## Both LRU, LFU and volatile-ttl are implemented using approximated# randomized algorithms.# 如果配置多个淘汰策略 redis会随机选择
3.2 LRU算法 最近没使用的删除
3.2.1 LRU算法的简单实现(java)
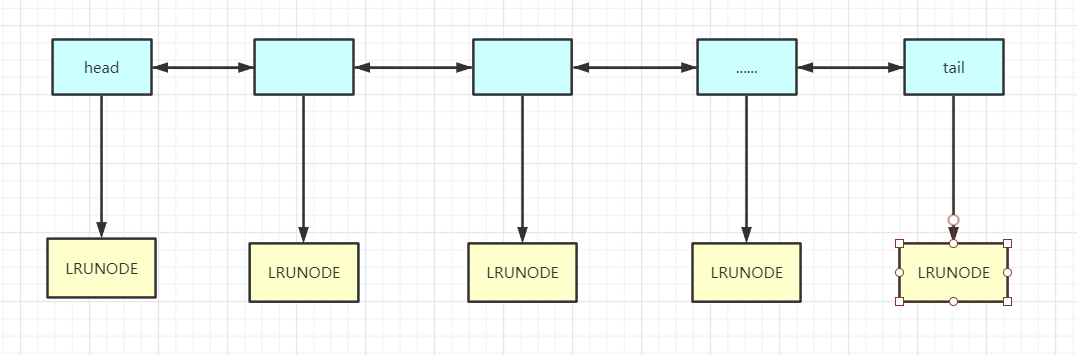
3.2.1 redis中的LRU算法实现(java)
要从redisobject说起
typedef struct redisObject {unsigned type:4; // type类型unsigned encoding:4; // encoding类型/* key对象内部时钟 */unsigned lru:LRU_BITS; /* LRU time (relative to global lru_clock) or* LFU data (least significant 8 bits frequency* and most significant 16 bits access time). */int refcount;void *ptr;} robj;
可以看到redisobject这个数据类型的包装类持有了一个内部时钟
同时redis服务器也自己维护了一个时钟 (每次去取的话操作内核空间硬件时钟 用户态太消耗性能!)
struct redisServer {pid_t pid;char *configfile;//全局时钟unsigned lruclock:LRU_BITS;...};
redis嫌LinkedList占用的空间太大了。Redis并不是直接基于字符串、链表、字典等数据结构来实现KV数据库,而是在这些数据结构上创建了一个对象系统Redis Object。在redisObject结构体中定义了一个长度24bit的unsigned类型的字段,用来存储对象最后一次被命令程序访问的时间:
By modifying a bit the Redis Object structure I was able to make 24 bits of space. There was no room for linking the objects in a linked list (fat pointers!)
毕竟,并不需要一个完全准确的LRU算法,就算移除了一个最近访问过的Key,影响也不太。
To add another data structure to take this metadata was not an option, however since LRU is itself an approximation of what we want to achieve, what about approximating LRU itself?
最初Redis是这样实现的:
随机选三个Key,把idle time最大的那个Key移除。后来,把3改成可配置的一个参数,默认为N=5:maxmemory-samples 5
when there is to evict a key, select 3 random keys, and evict the one with the highest idle time
就是这么简单,简单得让人不敢相信了,而且十分有效。但它还是有缺点的:每次随机选择的时候,并没有利用历史信息。在每一轮移除(evict)一个Key时,随机从N个里面选一个Key,移除idle time最大的那个Key;下一轮又是随机从N个里面选一个Key…有没有想过:在上一轮移除Key的过程中,其实是知道了N个Key的idle time的情况的,那我能不能在下一轮移除Key时,利用好上一轮知晓的一些信息?
However if you think at this algorithm across its executions, you can see how we are trashing a lot of interesting data. Maybe when sampling the N keys, we encounter a lot of good candidates, but we then just evict the best, and start from scratch again the next cycle.
start from scratch太傻了。于是Redis又做出了改进:采用缓冲池(pooling)
当每一轮移除Key时,拿到了这个N个Key的idle time,如果它的idle time比 pool 里面的 Key的idle time还要大,就把它添加到pool里面去。这样一来,每次移除的Key并不仅仅是随机选择的N个Key里面最大的,而且还是pool里面idle time最大的,并且:pool 里面的Key是经过多轮比较筛选的,它的idle time 在概率上比随机获取的Key的idle time要大,可以这么理解:pool 里面的Key 保留了”历史经验信息”。
Basically when the N keys sampling was performed, it was used to populate a larger pool of keys (just 16 keys by default). This pool has the keys sorted by idle time, so new keys only enter the pool when they have an idle time greater than one key in the pool or when there is empty space in the pool.
采用”pool”,把一个全局排序问题 转化成为了 局部的比较问题。(尽管排序本质上也是比较,囧)。要想知道idle time 最大的key,精确的LRU需要对全局的key的idle time排序,然后就能找出idle time最大的key了。但是可以采用一种近似的思想,即随机采样(samping)若干个key,这若干个key就代表着全局的key,把samping得到的key放到pool里面,每次采样之后更新pool,使得pool里面总是保存着随机选择过的key的idle time最大的那些key。需要evict key时,直接从pool里面取出idle time最大的key,将之evict掉。这种思想是很值得借鉴的。
至此,基于LRU的移除策略就分析完了。可以看到这种随机删除的方法再采样率为5的情况下基本持平。
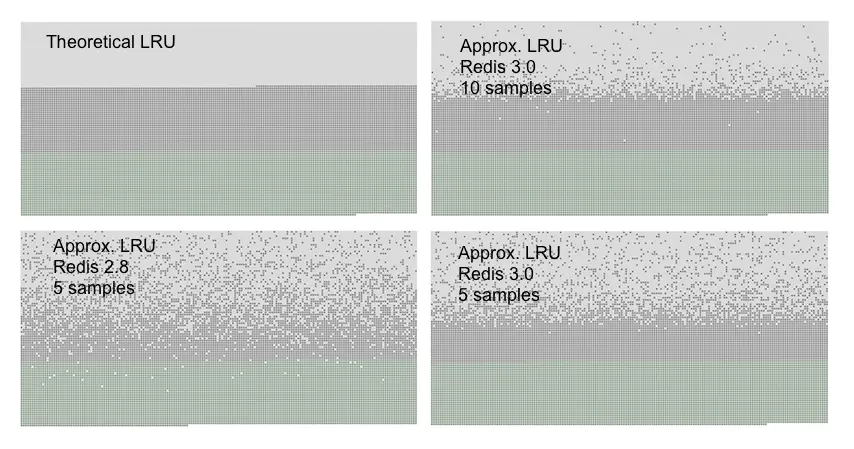
3.3LFU(最近最少使用的算法)
LFU是在Redis4.0后出现的,LRU的最近最少使用实际上并不精确,考虑下面的情况,如果在|处删除,那么A距离的时间最久,但实际上A的使用频率要比B频繁,所以合理的淘汰策略应该是淘汰B。LFU就是为应对这种情况而生的。
A~~A~~A~~A~~A~~A~~A~~A~~A~~A~~~|B~~~~~B~~~~~B~~~~~B~~~~~~~~~~~B|
- LFU把原来的key对象的内部时钟的24位分成两部分,前16位还代表时钟,后8位代表一个计数器。16位的情况下如果还按照秒为单位就会导致不够用,所以一般这里以时钟为单位。而后8位表示当前key对象的访问频率,8位只能代表255,但是redis并没有采用线性上升的方式,而是通过一个复杂的公式,通过配置两个参数来调整数据的递增速度。
下图从左到右表示key的命中次数,从上到下表示影响因子,在影响因子为100的条件下,经过10M次命中才能把后8位值加满到255.
# +--------+------------+------------+------------+------------+------------+# | factor | 100 hits | 1000 hits | 100K hits | 1M hits | 10M hits |# +--------+------------+------------+------------+------------+------------+# | 0 | 104 | 255 | 255 | 255 | 255 |# +--------+------------+------------+------------+------------+------------+# | 1 | 18 | 49 | 255 | 255 | 255 |# +--------+------------+------------+------------+------------+------------+# | 10 | 10 | 18 | 142 | 255 | 255 |# +--------+------------+------------+------------+------------+------------+# | 100 | 8 | 11 | 49 | 143 | 255 |# +--------+------------+------------+------------+------------+------------+
uint8_t LFULogIncr(uint8_t counter) {if (counter == 255) return 255;double r = (double)rand()/RAND_MAX;double baseval = counter - LFU_INIT_VAL;if (baseval < 0) baseval = 0;double p = 1.0/(baseval*server.lfu_log_factor+1);if (r < p) counter++;return counter;}
lfu-log-factor 10lfu-decay-time 1
- 上面说的情况是key一直被命中的情况,如果一个key经过几分钟没有被命中,那么后8位的值是需要递减几分钟,具体递减几分钟根据衰减因子lfu-decay-time来控制
unsigned long LFUDecrAndReturn(robj *o) {unsigned long ldt = o->lru >> 8;unsigned long counter = o->lru & 255;unsigned long num_periods = server.lfu_decay_time ? LFUTimeElapsed(ldt) / server.lfu_decay_time : 0;if (num_periods)counter = (num_periods > counter) ? 0 : counter - num_periods;return counter;}
lfu-log-factor 10lfu-decay-time 1
- 上面递增和衰减都有对应参数配置,那么对于新分配的key呢?如果新分配的key计数器开始为0,那么很有可能在内存不足的时候直接就给淘汰掉了,所以默认情况下新分配的key的后8位计数器的值为5(应该可配资),防止因为访问频率过低而直接被删除。
- 低8位我们描述完了,那么高16位的时钟是用来干嘛的呢?目前我的理解是用来衰减低8位的计数器的,就是根据这个时钟与全局时钟进行比较,如果过了一定时间(做差)就会对计数器进行衰减。
4.redis为什么如此快?【单线程,多路io复用,纯内存的】
本文只是总结 为什么单线程加纯内存如此之快见 https://programming.vip/docs/why-is-redis-so-fast.html
1.内存KEY,VALUE【主要原因】
2.单线程
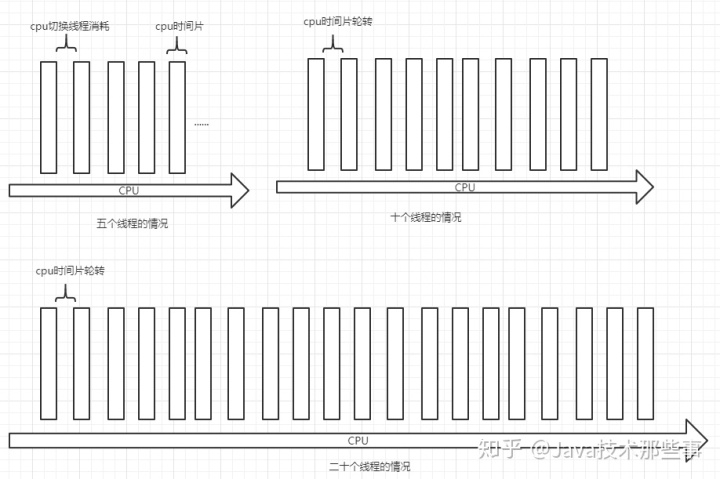
为了避免线程切换的消耗。线程时间片的切换 需要内核对线程的挂起和启动消耗性能。为了减少内存频繁切换和挂起的问题 部分语言发明了用户线程即协程。
3.io多路复用
iO多路复用是一种同步IO模型,实现一个线程可以监视多个文件句柄;一旦某个文件句柄就绪,就能够通知应用程序进行相应的读写操作;没有文件句柄就绪时会阻塞应用程序,交出cpu。多路是指网络连接,复用指的是同一个线程
1.同步堵塞方式
举个例子 每来一个客人都有一个服务员 全程接待 从用户进来 吃饭到吃完 位置都有一个服务员站这等待服务。
这显然是浪费性能的。
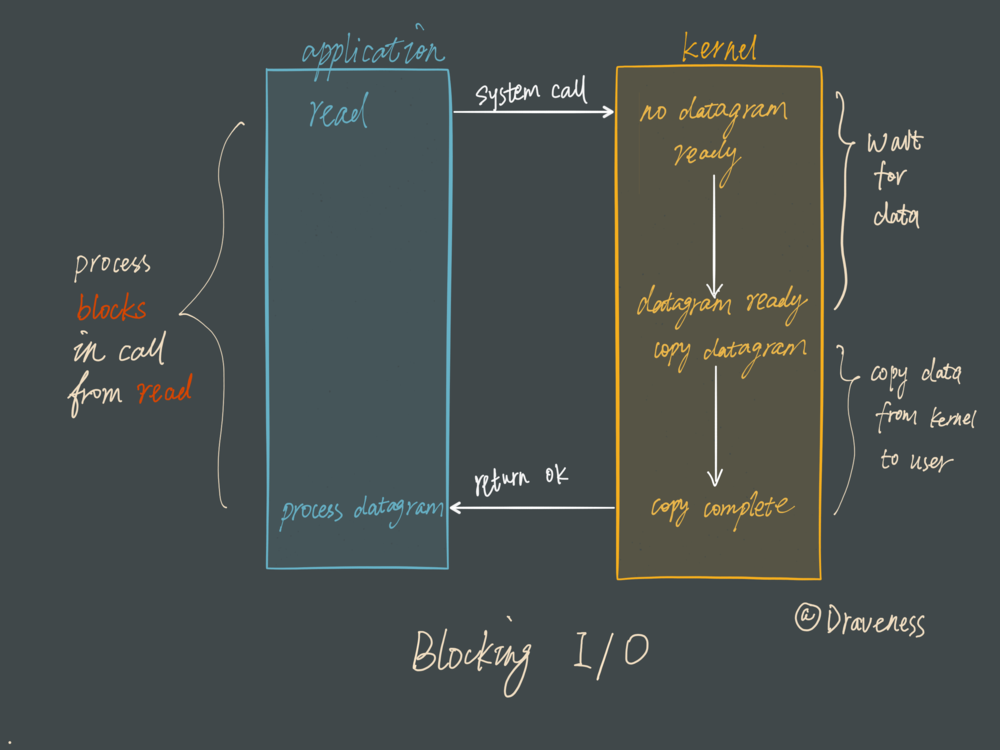
2.多路复用
每个服务员复制多个客人,到客人有需求了再去服务。
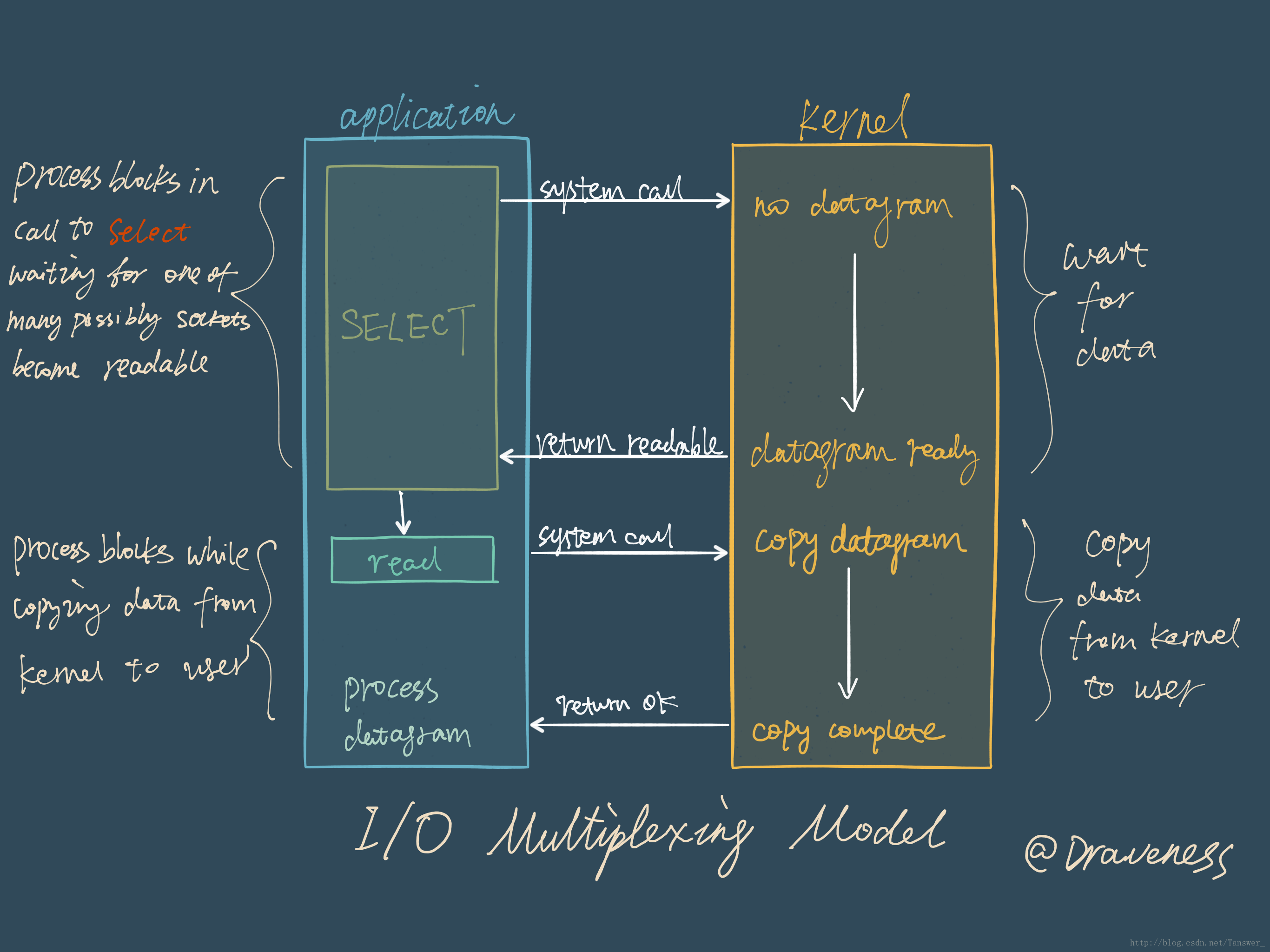
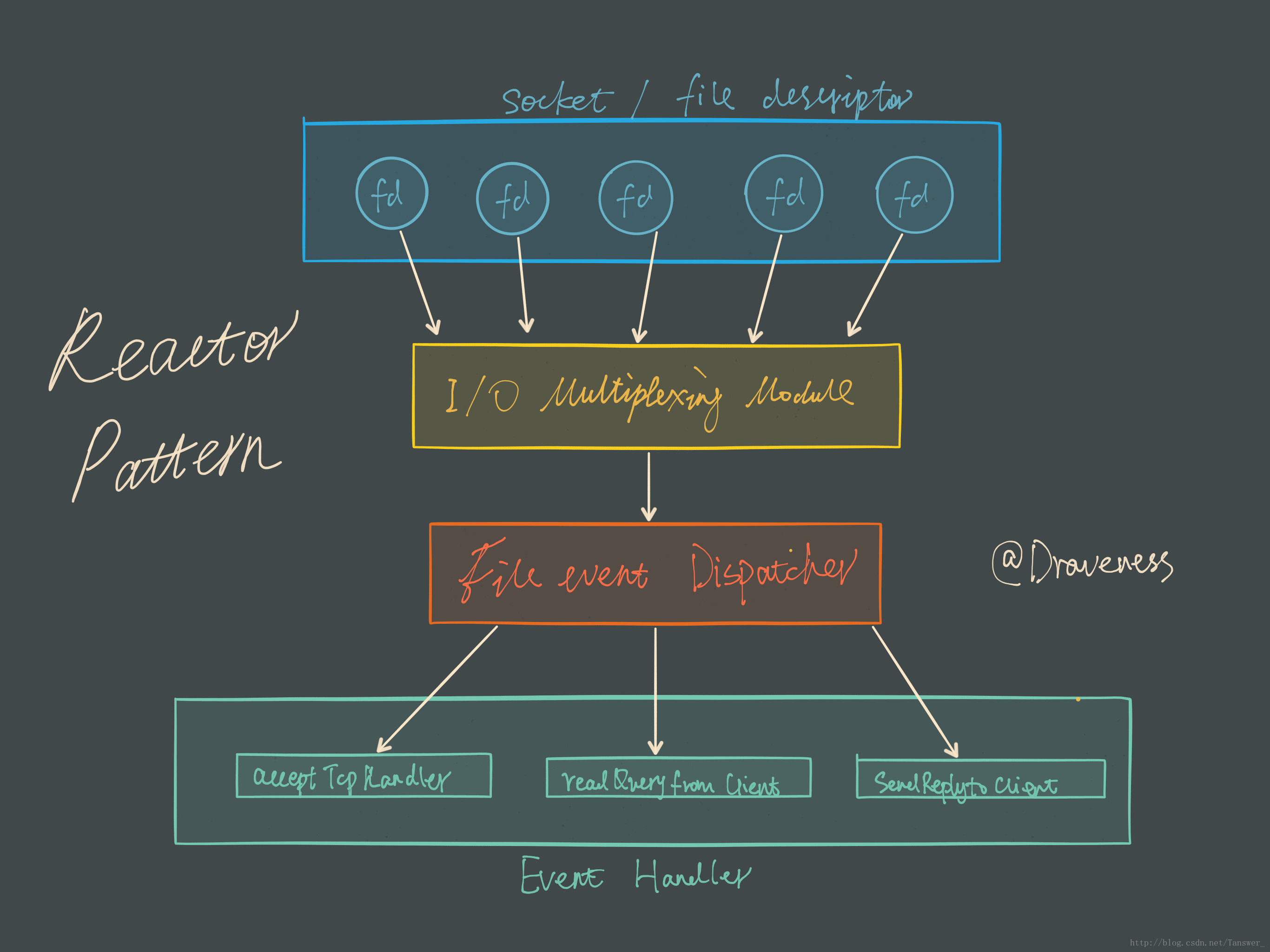
Reactor 设计模式
Redis 服务采用 Reactor 的方式来实现文件事件处理器(每一个网络连接其实都对应一个文件描述符)
红色的方块是redis中的文件时间分发器他是单线程的,但是他拿多路复用器的会调后会去向队员的缓存区写数据。
文件事件处理器使用 I/O 多路复用模块同时监听多个 FD,当 accept、read、write 和 close 文件事件产生时,文件事件处理器就会回调 FD 绑定的事件处理器。
虽然整个文件事件处理器是在单线程上运行的,但是通过 I/O 多路复用模块的引入,实现了同时对多个 FD 读写的监控,提高了网络通信模型的性能,同时也可以保证整个 Redis 服务实现的简单。
I/O 多路复用模块
I/O 多路复用模块封装了底层的 select、epoll、avport 以及 kqueue 这些 I/O 多路复用函数,为上层提供了相同的接口。
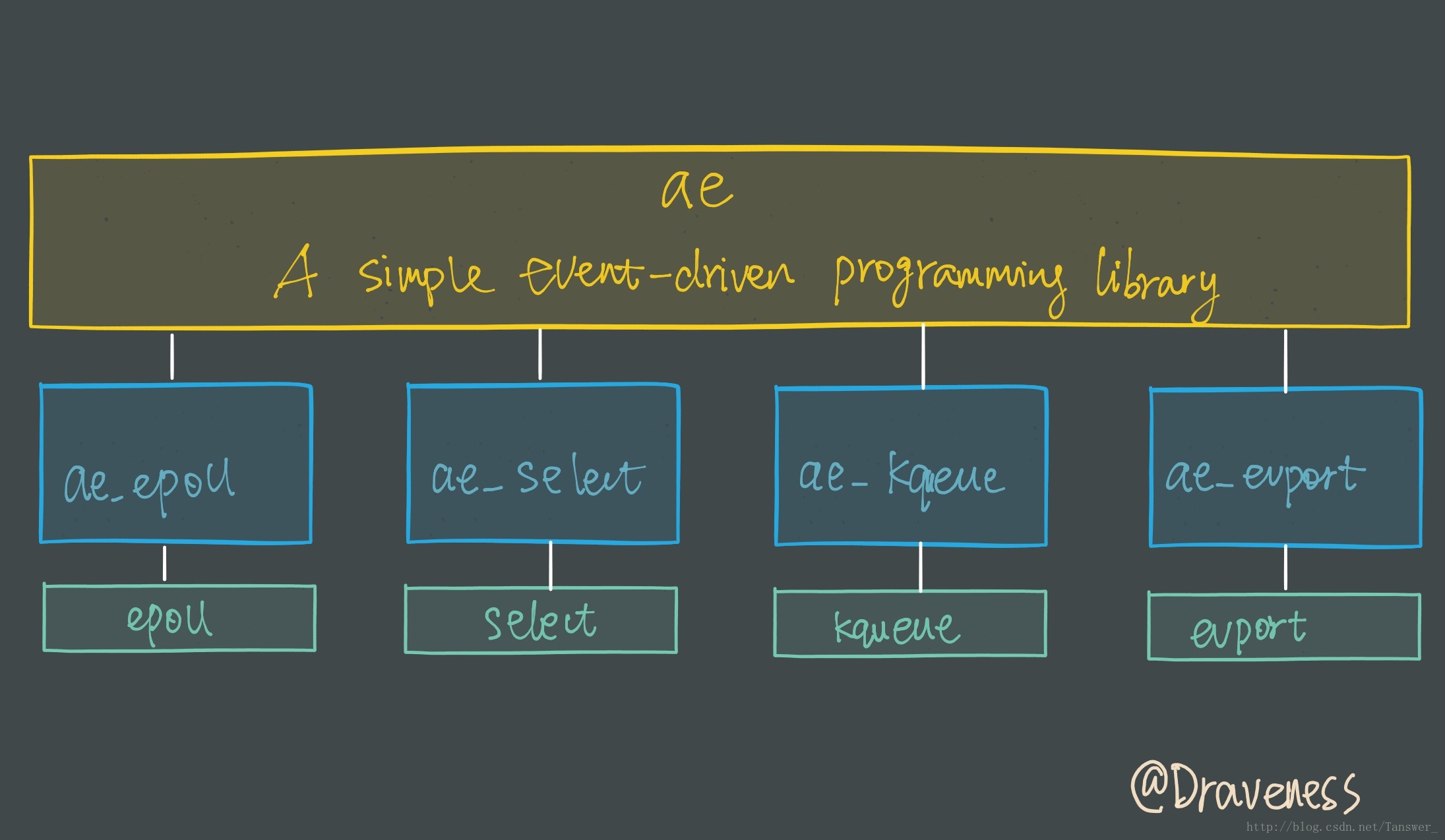
#ifdef HAVE_EVPORT#include "ae_evport.c"#else#ifdef HAVE_EPOLL#include "ae_epoll.c"#else#ifdef HAVE_KQUEUE#include "ae_kqueue.c"#else#include "ae_select.c"#endif#endif#endif
按照执行效率来选择实现,看到没有IOCP,这就是为什么redis不支持windows的原因。

若有收获,就点个赞吧
0 人点赞
