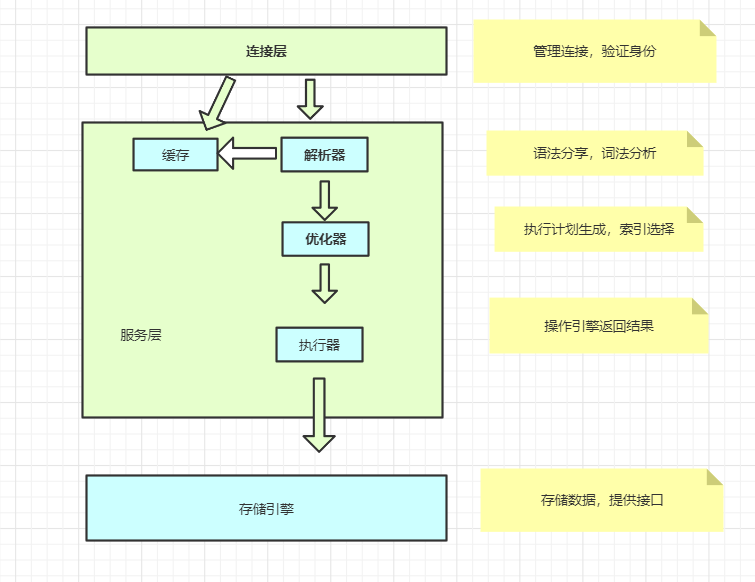
1.一条sql语句是如何执行的?
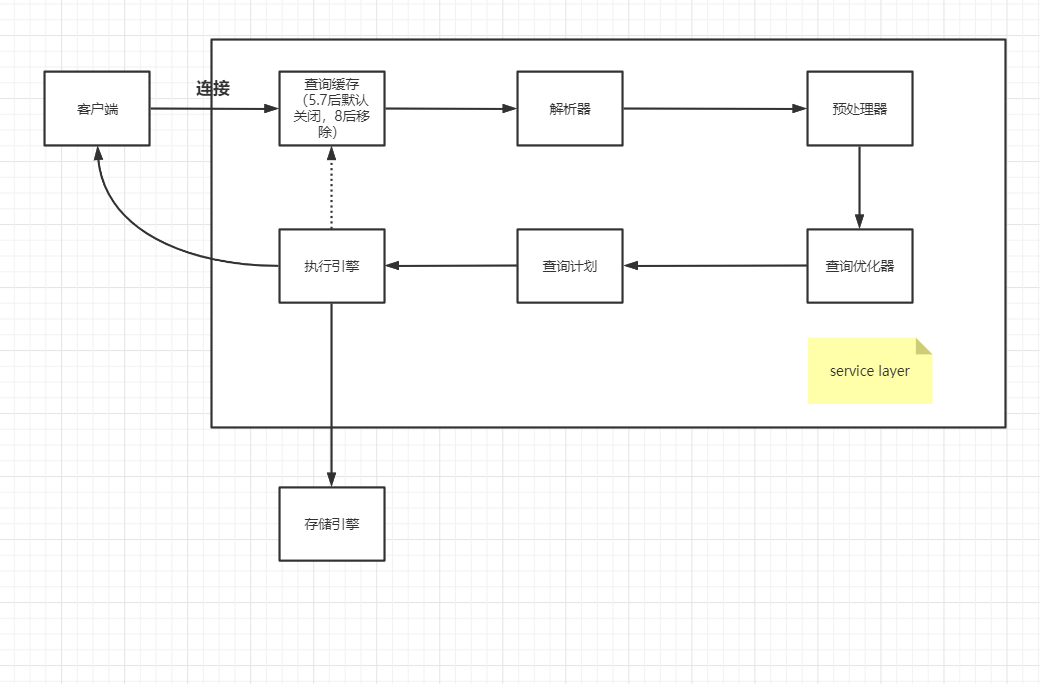
1.1 连接
可以的通过下面的命令查看有几个连接
show GLOBAl STATUS LIKE 'Thread%';
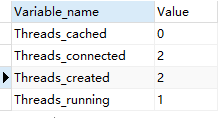
在客户端产生一个连接或者会话,在服务端就会创建一个线程,为了减少保存连接的服务器消耗,mysql会把长时间不会的连接(sleep)自断断开
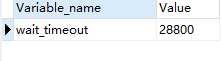
非互动交互超时 如JDBC
show GLOBAL VARIABLES like 'wait_timeout';
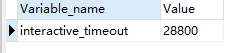
互动交互超时 如数据库工具超时时间
show GLOBAL VARIABLES like 'interactive_timeout';
最大连接数
show GLOBAL VARIABLES like 'max_connections';
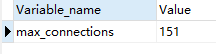
默认最大连接数为151,最大可以设置成100000
注意
mysql的设置默认是sdession级别的如果需要全局生效必须要加上globa
1.2 查询缓存
mysql 5.7之后缓存已经默认关闭,8.0之后的版本已经移除。需要对查询进行缓存一般使用的 ORM框架如 Mybatis.
1.3 解析器
1.3.1 词法解析器
1.3.2 语法解析器
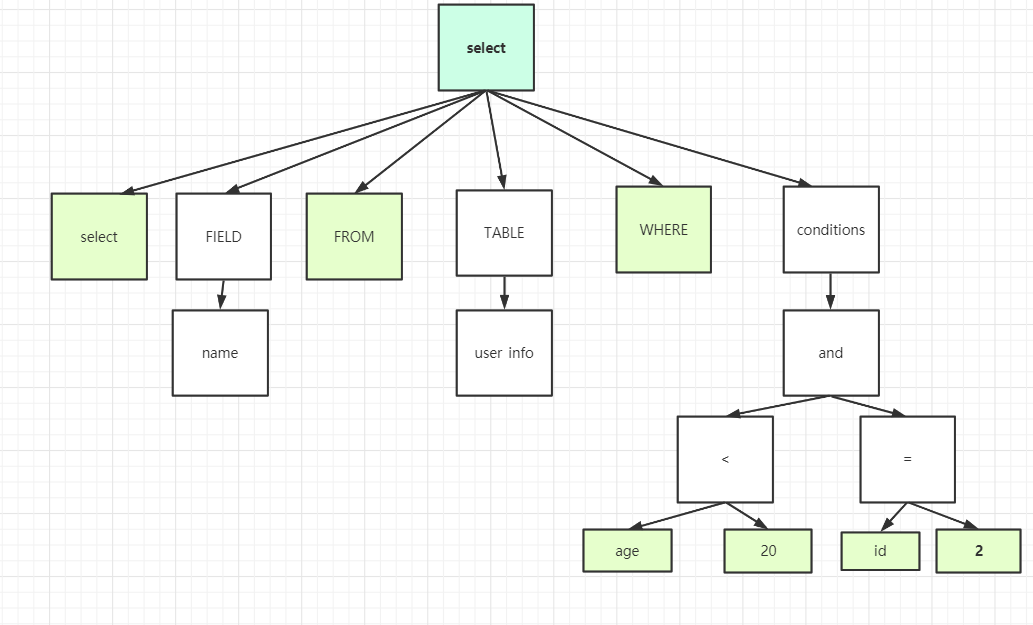
对sql语句进行语法分析生成语法树
比如下面的sql就build被解析成如下的解析树
select name from user_info where age <20 and id =2;
1.4 预处理器
会检查解析树,解决解析器无法解析的语义,检查表和列名是否存在,检查名字和别名是否有歧义
1.5 优化器
在mysql当前版本中的优化器是基于成本的优化器,他会根据解析树生成不同的执行计划再选择其中花费最小的执行计划
下面的语句可以看到上一条查询语句的开销
show status like 'Last_query_cost'
1.6 执行计划
可以通过下面的sql看生成的执行计划
EXPLAIN SELECT * FROM t_job WHERE JOB_ID =1

EXPLAIN format=json SELECT * FROM t_job WHERE JOB_ID =1
{"query_block": {"select_id": 1,"cost_info": {"query_cost": "1.00"},"table": {"table_name": "t_job","access_type": "const","possible_keys": ["PRIMARY"],"key": "PRIMARY","used_key_parts": ["JOB_ID"],"key_length": "8","ref": ["const"],"rows_examined_per_scan": 1,"rows_produced_per_join": 1,"filtered": "100.00","cost_info": {"read_cost": "0.00","eval_cost": "0.20","prefix_cost": "0.00","data_read_per_join": "688"},"used_columns": ["JOB_ID","BEAN_NAME","METHOD_NAME","PARAMS","CRON_EXPRESSION","STATUS","REMARK","CREATE_TIME"]}}}
2.存储引擎
每一张表都会在下有一个文件夹 一个表文件有一个对应的frm文件 innnerdb会额外生成 .idb文件 myisam会生成.myd和.myi文件
show VARIABLES like 'datadir'
2.1如何选择存储引擎
大部分情况下我们都可以用innerdb其他情况可以见
https://dev.mysql.com/doc/refman/5.7/en/storage-engines.html
3.总结
4.一条更新语句是如何执行的?
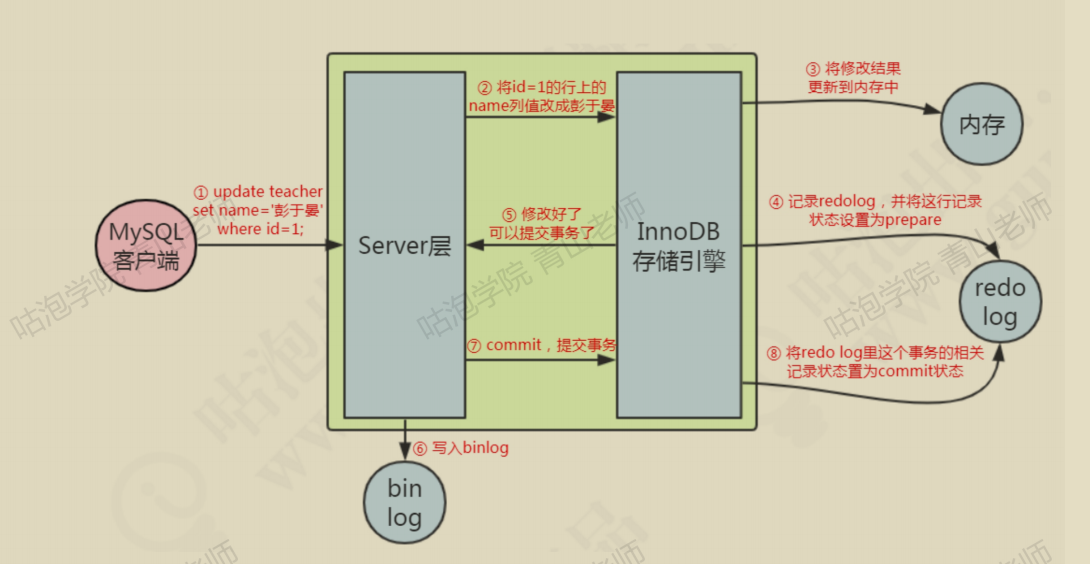
4.1 缓存池 Buffer Pool
内存比外存快!!
1.操作系统页
因为系统io操作和内存操作速度是天壤之别,所以一般操作系统会有一个系统页的概念,这个参数在当前操作系统内普遍是4Kb 为了避免频繁的裂页和合并页 ssd提升存储效率往往需要4kb对齐。
doublewrite buffer就是为了避免 数据页到操作系统页的写入异常
2.数据页
在mysql中数据读取的最小单位也是页,默认情况下是16384个字节也就是16kb。可以通过以下语句查看一般情况下是不需要修改的。
和数据库页一样提高查询的关键就是减少innerdb页 和b+树的分裂和合并下一章我们会讲到
show VARIABLES like "innodb_page_size"

3 Buffer Pool
因为外存比内存慢的多所以如果mysql是直接对文件进行读取的话数据是慢到无法使用的。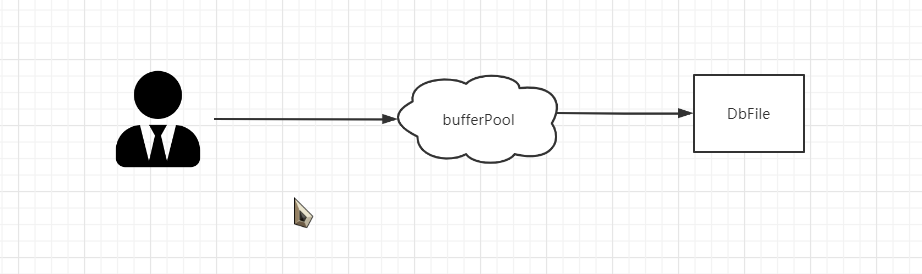
所以innerDb设计了一层缓存 Buffer Pool,如果读取的时候砸死缓存区中就直接缓存,如果不在缓存区中就再区外存中寻找。机智的小伙伴就会问了,那innerdb会不会有缓存一致性的问题?实际上用户不是直接操作DbFile而是将修改提交到bufferPool 再由后台线程 专门把缓存和硬盘不一致的脏页刷到 外存中去
show VARIABLES like "%pool%"
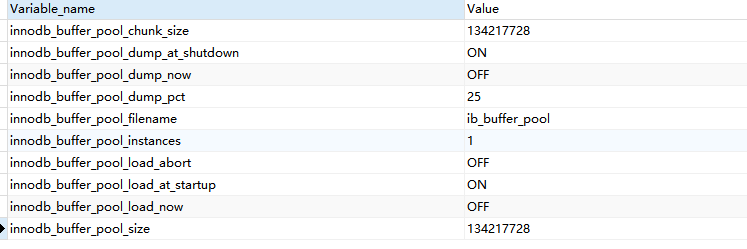
一般来说专门的DB机器buffer_pool应该到系统内存的70% 显然提高缓存区的大小可以提高db速度
4.2 Redo LOG
这就涉及到另一个问题了,刷脏的线程不是实时运行的,如果脏页还来不及写入数据库挂了,这样缓存就会出现修改丢失这怎么办?
为了避免出现这个问题,innerdb设置了一个重做日志,所有对页面的修改日志都会被记录到这个redolog中,如果有未同步到磁盘的数据埋在数据库启动的时候会根据redoLog执行操作。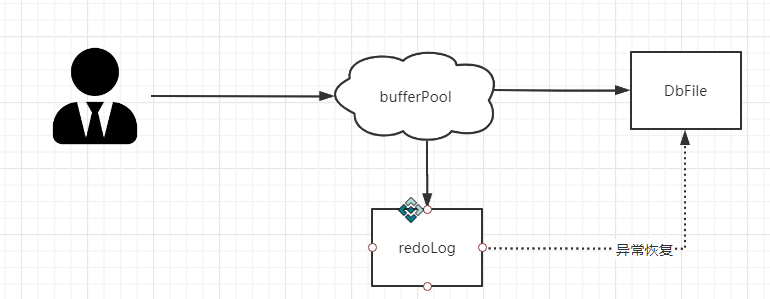
我们常说的ACID 中的d 持久化就是通过redolog保证的
这样又有一个问题,既然修改都是一个日志一个io那为什么还要走 bufferpool修改操作直接操作数据库就好了啊!
一方面直接走数据库会让缓存一致性问题变得十分难搞,另一方面顺序io的数据是远远要快于随机io的。
redolog在插入的时候是顺序io速度是非常快的,插入磁盘是随机io速度是慢的。
redolog位于 /bin/mysql下面有两个文件 ib_logfile0 和 ib_logfile1 默认两个文件 每个48m
show VARIABLES like "innodb_log%"
| innodb_log_files_in_group | redolog的文件数默认2 |
|---|---|
| innodb_log_buffer_size | redolog的大小48kb |
| innodb_log_group_home_dir | redolog的位置 不指定则为datadir的位置 |
4.2.1 redolog的特性
- redolog 是innoDb实现的不是所有存储引擎都有奔溃回复是innoDb的特性
- redolog 不记录数据页更新后的状态,而是记录修改属于物理日志
- redolog写满后会理解触发 bufferpool的磁盘同步
4.3 undolog
undolog(撤销日志或者回滚日志)记录了事务发送之前的状态分为 insert undo log和update undo log如果修改数据出现异常,可以用undolog来实现回滚
可以认为undolog记录的是泛型操作 insert会记录delete update会记录update原来的值 是逻辑格式日志show GLOBAL VARIABLES like '%undo%'

Redolog 和undolog与事务密切相关一般我们叫他事务日志
4.4 如何执行的
这是一个关于Sql执行的简化过程
我们假设有这么一条记录
| id | name | len |
|---|---|---|
| 1 | loafer | 15 |
update user set len = 200 where uid = 1
1.事务开始,从内存或者磁盘取到包含该数据的数据页返回给service层的执行器
2.service执行修改 把 uid =1 的数据的 len 设置成 200
- innodb把 len = 15加到undolog 中保证事务的隔离性和回滚
- innodb 吧 len = 200 加到redolog中保证事务的持久性
- 调用存储引擎的接口把len = 15插入到数据库
- 事务提交
5 innodb的架构
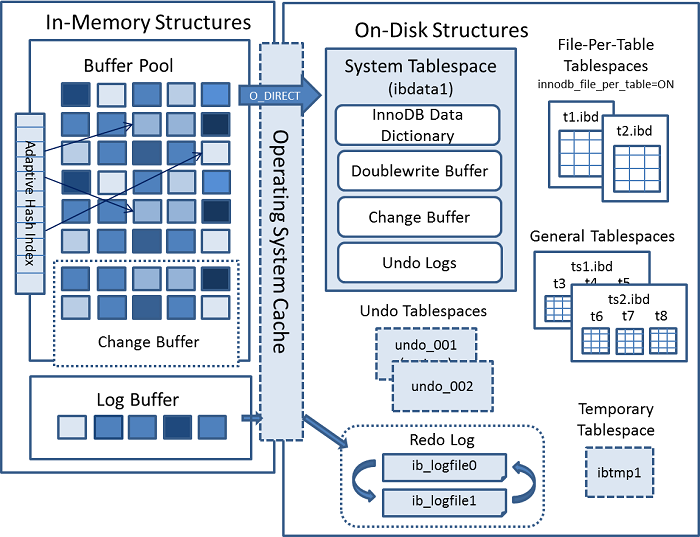
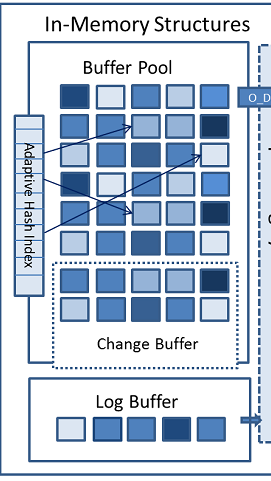
可以看到内存结构主要包括3个部分 BufferPool logBuffer 和 changeBuffer 3个缓冲结构 和 Adpaptive Hash iNdex和一个redolog
BuffePool
buffedrPool缓存的是页面,包括数据页,索引页
show VARIABLES like "%innodb_buffer_pool%"show statuslike "%innodb_buffer_pool%"
内存的缓存池满了怎么办? INNODB也是采用 LRU算法来管理 (链表熟悉新啊 不是传统的LRU 分成了young 和old)
LRU
lru算法的java实现
传统的Lru 可以用map+链表实现 value存的是链表的地址 。
下面是一个LRU缓存的双向链表加hashmap的简单实现
简单来说就是用hashmap来做 的索引避免链表查询每次遍历全部节点效率查询过低。
下面是LRUCache的简单实现
package leetcode.medium;import java.util.HashMap;public class LRUCache<K, E> {private Node<K, E> head;private Node<K, E> end;private volatile int limit;private final HashMap<K, Node<K,E>> hashMap;public void setLimit(int limit) {this.limit = limit;}public LRUCache(int limit) {if (limit <= 0) {throw new IllegalArgumentException("limit must > 0");}this.limit = limit;hashMap = new HashMap<>();}public E get(K key) {Node<K,E> node = hashMap.get(key);if (node == null) {return null;}refreshNode(node);return node.value;}public synchronized void put(K key,E value) {Node<K,E> node = hashMap.get(key);if (node == null) {if (hashMap.size() >= limit) {// 删除最不常用的K oldKey = removeNode(head);hashMap.remove(oldKey);}Node<K, E> newNode = new Node<K, E>(key, value);addNode(newNode);hashMap.put(key, newNode);} else {node.value = value;//多次赋值,我们也默认提高优先级的refreshNode(node);}}private synchronized void refreshNode(Node<K, E> node) {if (node == end) {return;}removeNode(node);addNode(node);}private void addNode(Node<K, E> node) {if (end != null) {end.next = node;node.prev = end;}end = node;if (head == null) {head = node;}node.next = null;}private synchronized K removeNode(Node<K,E> node) {if (node == end) {end = end.prev;} else if (node == head) {head = head.next;} else {node.prev.next = node.next;node.next.prev = node.prev;}return node.key;}private static class Node<K, E> {Node<K, E> prev;Node<K, E> next;K key;E value;Node(K key, E value) {this.key = key;this.value = value;}}public static void main(String[] args) {LRUCache<String,String> lruCache = new LRUCache<>(5);lruCache.put("001", "d");lruCache.put("002", "di");lruCache.put("003", "dic");lruCache.put("004", "dick");lruCache.put("001", "dickson");}}
在innodb中也维护了一个双向链表来实现lru,存放指向缓存页的指针
**
innodb的read-ahead功能
为了提高性能添加了预读的性能
https://dev.mysql.com/doc/refman/5.7/en/innodb-performance-read_ahead.html
14.8.3.4 Configuring InnoDB Buffer Pool Prefetching (Read-Ahead)
A read-ahead request is an I/O request to prefetch multiple pages in the buffer pool asynchronously, in anticipation that these pages are needed soon. The requests bring in all the pages in one extent.
InnoDBuses two read-ahead algorithms to improve I/O performance: Linear read-ahead is a technique that predicts what pages might be needed soon based on pages in the buffer pool being accessed sequentially. You control whenInnoDBperforms a read-ahead operation by adjusting the number of sequential page accesses required to trigger an asynchronous read request, using the configuration parameterinnodb_read_ahead_threshold. Before this parameter was added,InnoDBwould only calculate whether to issue an asynchronous prefetch request for the entire next extent when it read the last page of the current extent. The configuration parameterinnodb_read_ahead_thresholdcontrols how sensitiveInnoDBis in detecting patterns of sequential page access. If the number of pages read sequentially from an extent is greater than or equal toinnodb_read_ahead_threshold,InnoDBinitiates an asynchronous read-ahead operation of the entire following extent.innodb_read_ahead_thresholdcan be set to any value from 0-64. The default value is 56. The higher the value, the more strict the access pattern check. For example, if you set the value to 48,InnoDBtriggers a linear read-ahead request only when 48 pages in the current extent have been accessed sequentially. If the value is 8,InnoDBtriggers an asynchronous read-ahead even if as few as 8 pages in the extent are accessed sequentially. You can set the value of this parameter in the MySQL configuration file, or change it dynamically with theSET GLOBALstatement, which requires privileges sufficient to set global system variables. See Section 5.1.8.1, “System Variable Privileges”. Random read-ahead is a technique that predicts when pages might be needed soon based on pages already in the buffer pool, regardless of the order in which those pages were read. If 13 consecutive pages from the same extent are found in the buffer pool,InnoDBasynchronously issues a request to prefetch the remaining pages of the extent. To enable this feature, set the configuration variableinnodb_random_read_aheadtoON. TheSHOW ENGINE INNODB STATUScommand displays statistics to help you evaluate the effectiveness of the read-ahead algorithm. Statistics include counter information for the following global status variables:This information can be useful when fine-tuning the
innodb_random_read_aheadsetting.
可以看到mysql采用了线性预读和随机预读两个算法 默认情况下随机预读是关闭的,在预先加载可能会访问到的数据到bufferpool
mysql的新老区
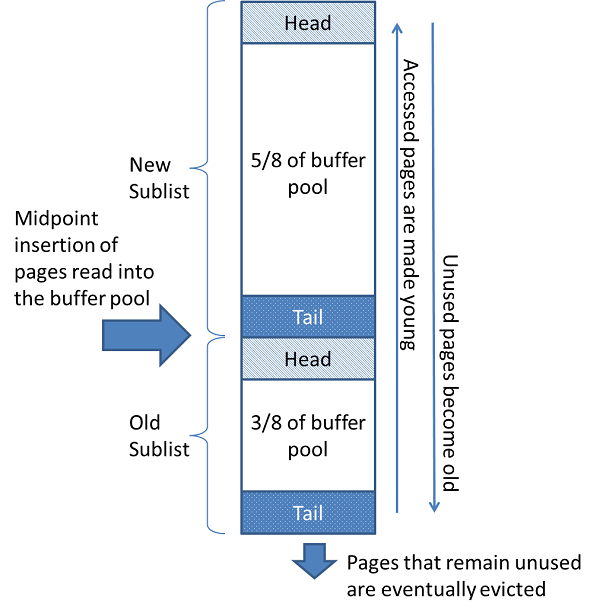
The buffer pool is managed as a list using a variation of the least recently used (LRU) algorithm. When room is needed to add a new page to the buffer pool, the least recently used page is evicted and a new page is added to the middle of the list. This midpoint insertion strategy treats the list as two sublists:
- At the head, a sublist of new (“young”) pages that were accessed recently
- At the tail, a sublist of old pages that were accessed less recently
所有新数据加入到buffer pool的时候,一律先放到冷数据区的head,不管是
预读的,还是普通的读操作。所以如果有一些预读的数据没有被用到,会在old
sublist (冷区)直接被淘汰。
放到LRU List以后,如果再次被访问,都把它移动到热区的head。
如果热区的数据长时间没有被访问,会被先移动到冷区的head部,最后慢慢
在tail被淘汰。受到old_blocks_pct控制 在5%到95%这个值越大 new区越小 这个LRU就越接近传统LRU.为了避免冷数据过大导致全表缓冲池池被污染(假设我们全表查询了一张千万数据的大表 访问一次后不会再用到了)如果短时间被访问了一次导致数据全被移动到热去的head 导致大量数据被淘汰。为了避免这个问题。innodb设置了一个参数来控制 innodb_old_blocks)time这个参数来控制默认是1秒 如果数据一秒加到buffpool立刻被访问则不会移动
ChangeBuffer
Buffering secondary index changes when secondary index pages are not in the buffer pool avoids expensive random access I/O operations that would be required to immediately read in affected index pages from disk. Buffered changes can be applied later, in batches, as pages are read into the buffer pool by other read operations. 当辅助索引页不在缓冲池中时,缓冲辅助索引更改可避免昂贵的随机访问I/O操作,这些操作需要立即从磁盘读取受影响的索引页。缓冲的更改可以在稍后批处理中应用,因为其他读取操作会将页读入缓冲池。 如果当前数据页不是唯一所以,不存在数据重发的情况,也就是不需要从磁盘加载索引来潘丹数据是否重发。这种情况下可以先把修改记录在内存的缓存池中,从而提升更新语句(
INSERT,UPDATE,和DELETE操作可以修改辅助索引。如果受影响的索引页不在缓冲池中,则可以在更改缓冲区中缓冲更改)的速度 避免昂贵的io操作
在引入innodb_change_buffer_max_size配置选项在MySQL 5.6中,系统表空间中磁盘上更改缓冲区的最大大小为系统表空间中磁盘上更改缓冲区的1/3。InnoDB缓冲池大小
在MySQL 5.6及更高版本中,innodb_change_buffer_max_size配置选项将更改缓冲区的最大大小定义为总缓冲池大小的百分比。默认情况下,innodb_change_buffer_max_size设置为25。最大设置为50。InnoDB如果操作会导致磁盘上的更改缓冲区超出定义的限制,则不对其进行缓冲。
更改缓冲区页不需要在缓冲池中持久化,可能会被LRU操作逐出。
logBuffer
用来对log buffer进行缓存 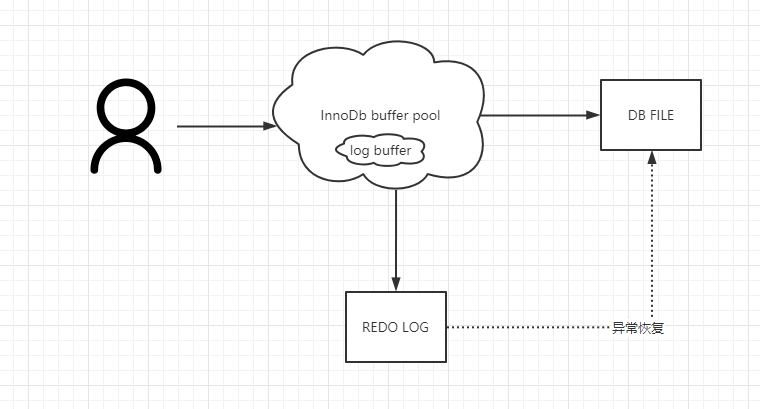

若有收获,就点个赞吧
0 人点赞
