1.redis 单机部署
1、下载redis
下载地址在:redis.io 首页
如果从官网下载慢,可以把链接贴到迅雷下载,再传到虚拟机:
cd /usr/local/soft/wget https://download.redis.io/releases/redis-6.0.9.tar.gz
2、解压压缩包
tar -zxvf redis-6.0.9.tar.gz
3、安装gcc依赖
Redis是C语言编写的,编译需要GCC。
Redis6.x.x版本支持了多线程,需要gcc的版本大于4.9,但是CentOS7的默认版本是4.8.5。
查看gcc的版本:
gcc -v
升级gcc版本:
yum -y install centos-release-sclyum -y install devtoolset-9-gcc devtoolset-9-gcc-c++ devtoolset-9-binutilsscl enable devtoolset-9 bashecho "source /opt/rh/devtoolset-9/enable" >>/etc/profile
确认gcc的版本(在同一个窗口中!):
gcc -v
4、编译安装
cd redis-6.0.9/srcmake install
安装成功的结果是src目录下面出现服务端和客户端的脚本
redis-server
redis-cli
redis-sentinel
5、修改配置文件
默认的配置文件是/usr/local/soft/redis-6.0.9/redis.conf
后台启动,不然窗口一关服务就挂了
daemonize no
改成
daemonize yes
下面一行必须改成 bind 0.0.0.0 或注释,否则只能在本机访问
bind 127.0.0.1
如果需要密码访问,取消requirepass的注释,在外网(比如阿里云)这个必须要配置!
requirepass yourpassword
6、使用指定配置文件启动Redis
/usr/local/soft/redis-6.0.9/src/redis-server /usr/local/soft/redis-6.0.9/redis.conf
查看端口是否启动成功:
netstat -an|grep 6379
7、进入客户端
/usr/local/soft/redis-6.0.9/src/redis-cli
8、停止redis(在客户端中)
redis> shutdown
或
ps -aux | grep rediskill -9 xxxx
9、配置别名的步骤[可选]
vim ~/.bashrc
添加两行:
alias redis='/usr/local/soft/redis-6.0.9/src/redis-server /usr/local/soft/redis-6.0.9/redis.conf'alias rcli='/usr/local/soft/redis-6.0.9/src/redis-cli'
编译生效:
source ~/.bashrc
这样就可以用redis启动服务,rcli进入客户端了
2.Sentinel集群(读写分离减少读压力)
1.部署
开启哨兵模式,至少需要3个Sentinel实例(奇数个,否则无法选举Leader)。
本例通过3个Sentinel实例监控3个Redis服务(1主2从)。
IP地址 节点角色&端口192.168.44.186 Master:6379 / Sentinel : 26379192.168.44.187 Slave :6379 / Sentinel : 26379192.168.44.188 Slave :6379 / Sentinel : 26379
防火墙记得关闭!!!
网络结构图: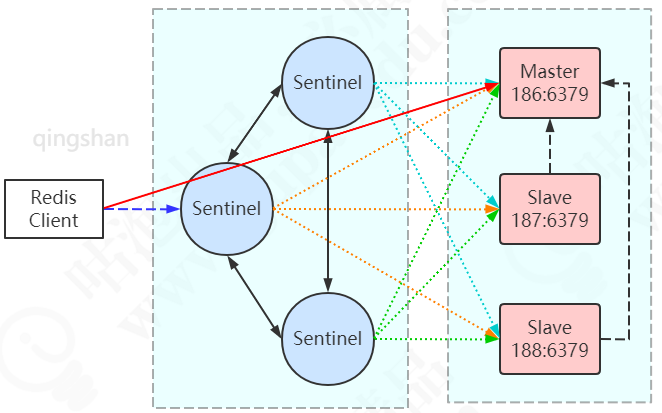
在187和188的redis.conf配置中找到被注释的这一行
# replicaof <masterip> <masterport>
replicaof 192.168.44.186 6379
在186、187、188创建sentinel配置文件(单例安装后根目录下默认有sentinel.conf,可以先备份默认的配置)
cd /usr/local/soft/redis-6.0.9mkdir logsmkdir rdbsmkdir sentinel-tmpcp sentinel.conf sentinel.conf.bak>sentinel.confvim sentinel.conf
sentinel.conf配置文件内容,三台机器相同
daemonize yesport 26379protected-mode nodir "/usr/local/soft/redis-6.0.9/sentinel-tmp"sentinel monitor redis-master 192.168.44.186 6379 2sentinel down-after-milliseconds redis-master 30000sentinel failover-timeout redis-master 180000sentinel parallel-syncs redis-master 1
配置解读:
| 配置 | 作用 |
|---|---|
| protected-mode | 是否允许外部网络访问,yes不允许 |
| dir | sentinel的工作目录 |
| sentinel monitor | sentinel监控的redis主节点 |
| down-after-milliseconds(毫秒) | master宕机多久,才会被Sentinel主观认为下线 |
| sentinel failover-timeout(毫秒) | 1 同一个sentinel对同一个master两次failover之间的间隔时间。2. 当一个slave从一个错误的master那里同步数据开始计算时间。直到slave被纠正为向正确的master那里同步数据时。3.当想要取消一个正在进行的failover所需要的时间。 4.当进行failover时,配置所有slaves指向新的master所需的最大时间。 |
| parallel-syncs | 这个配置项指定了在发生failover主备切换时最多可以有多少个slave同时对新的master进行 同步,这个数字越小,完成failover所需的时间就越长,但是如果这个数字越大,就意味着越 多的slave因为replication而不可用。可以通过将这个值设为 1 来保证每次只有一个slave 处于不能处理命令请求的状态。 |
在3台机器上分别启动Redis和Sentinel
cd /usr/local/soft/redis-6.0.9/src./redis-server ../redis.conf./redis-sentinel ../sentinel.conf
哨兵节点的另一种启动方式:
./redis-server ../sentinel.conf --sentinel
在3台机器上查看集群状态:
$ /usr/local/soft/redis-6.0.9/src/redis-cliredis> info replication
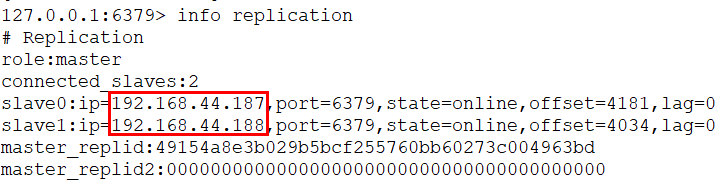
模拟master宕机,在186执行:
redis> shutdown
注意看sentinel.conf里面的redis-master被修改了,变成了当前master的IP端口。
$ /usr/local/soft/redis-6.0.9/src/redis-cliredis> info replication
这个时候会有一个slave节点被Sentinel设置为master。
再次启动master,它不一定会被选举为master。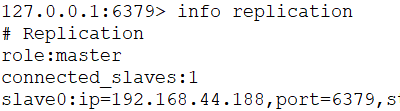
2. 哨兵模式的原理和详解
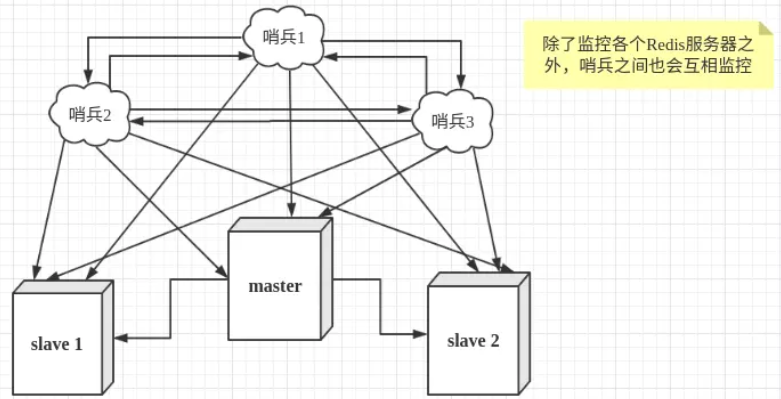
1.哨兵集群中的每个节点都会启动三个定时任务
- 第一个定时任务: 每个sentinel节点每隔1s向所有的master、slaver、别的sentinel节点发送一个PING命令,作用:心跳检测
- 第二个定时任务: 每个sentinel每隔2s都会向master的sentinel:hello这个channel中发送自己掌握的集群信息和自己的一些信息(比如host,ip,run id),这个是利用redis的pub/sub功能,每个sentinel节点都会订阅这个channel,也就是说,每个sentinel节点都可以知道别的sentinel节点掌握的集群信息,作用:信息交换,了解别的sentinel的信息和他们对于主节点的判断
第三个定时任务: 每个sentinel节点每隔10s都会向master和slaver发送INFO命令,作用:发现最新的集群拓扑结构
2.哨兵如何判断master宕机
主观下线
这个就是上面介绍的第一个定时任务做的事情,当sentinel节点向master发送一个PING命令,如果超过own-after-milliseconds(默认是30s,这个在sentinel的配置文件中可以自己配置)时间都没有收到有效回复,不好意思,我就认为你挂了,就是说为的主观下线(SDOWN),修改其flags状态为SRI_S_DOWN
客观下线
要了解什么是客观下线要先了解几个重要参数:
quorum:如果要认为master客观下线,最少需要主观下线的sentinel节点个数,举例:如果5个sentinel节点,quorum = 2,那只要2个sentinel主观下线,就可以判断master客观下线
- majority:如果确定了master客观下线了,就要把其中一个slaver切换成master,做这个事情的并不是整个sentinel集群,而是sentinel集群会选出来一个sentinel节点来做,那怎么选出来的呢,下面会讲,但是有一个原则就是需要大多数节点都同意这个sentinel来做故障转移才可以,这个大多数节点就是这个参数。注意:如果sentinel节点个数5,quorum=2,majority=3,那就是3个节点同意就可以,如果quorum=5,majority=3,这时候majority=3就不管用了,需要5个节点都同意才可以。
- configuration epoch:这个其实就是version,类似于中国每个皇帝都要有一个年号一样,每个新的master都要生成一个自己的configuration epoch,就是一个编号
客观下线处理过程
- 每个主观下线的sentinel节点都会向其他sentinel节点发送 SENTINEL is-master-down-by-addr ip port current_epoch runid,(ip:主观下线的服务id,port:主观下线的服务端口,current_epoch:sentinel的纪元,runid:*表示检测服务下线状态,如果是sentinel 运行id,表示用来选举领头sentinel(下面会讲选举领头sentinel))来询问其它sentinel是否同意服务下线。
- 每个sentinel收到命令之后,会根据发送过来的ip和端口检查自己判断的结果,如果自己也认为下线了,就会回复,回复包含三个参数:down_state(1表示已下线,0表示未下线),leader_runid(领头sentinal id),leader_epoch(领头sentinel纪元)。由于上面发送的runid参数是*,这里后两个参数先忽略。
- sentinel收到回复之后,根据quorum的值,判断达到这个值,如果大于或等于,就认为这个master客观下线
选择领头sentinel的过程
(raft算法)
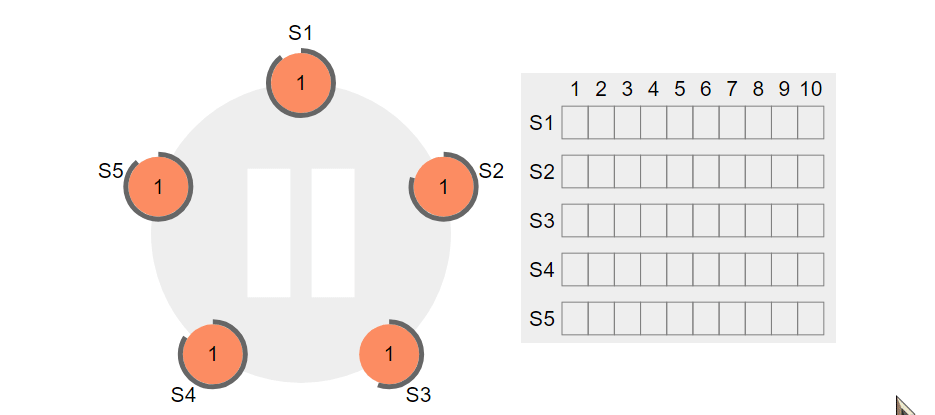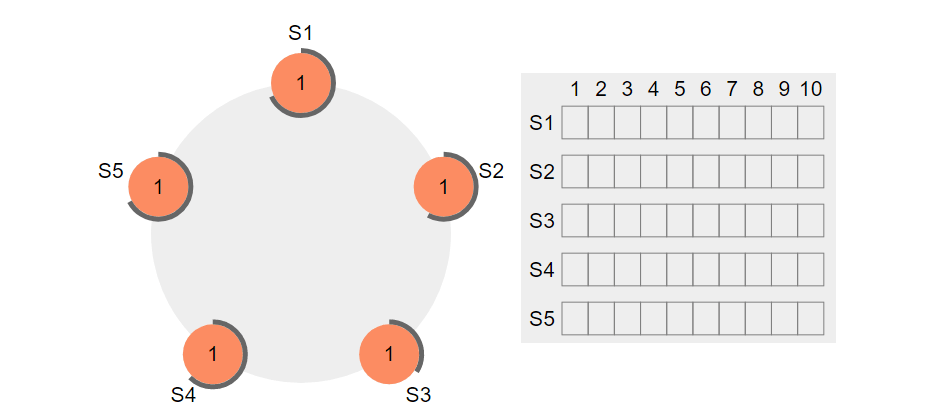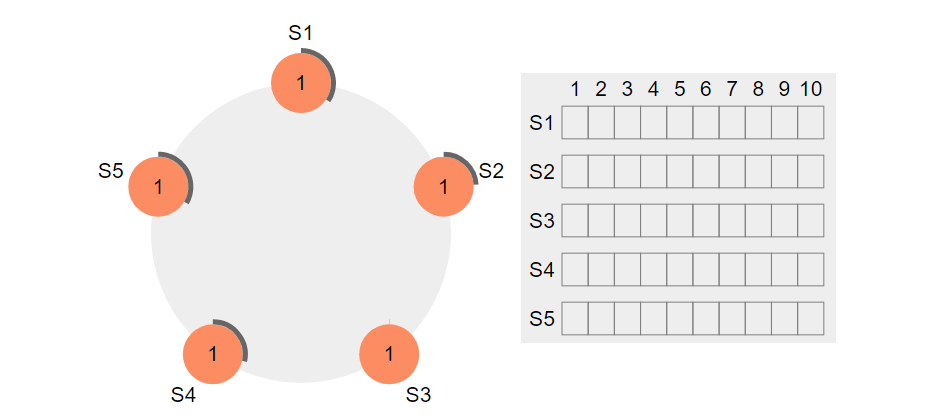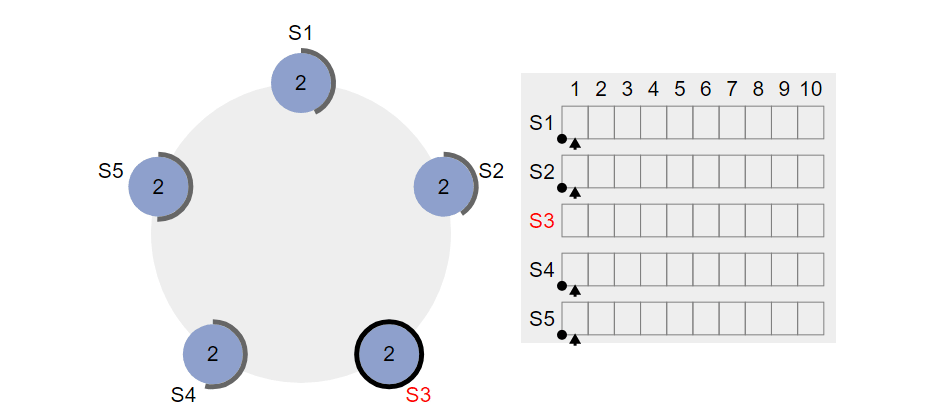
到现在为止,已经知道了master客观下线,那就需要一个sentinel来负责故障转移,那到底是哪个sentinel节点来做这件事呢?需要通过选举实现,具体的选举过程如下:
- 判断客观下线的sentinel节点向其他节点发送SENTINEL is-master-down-by-addr ip port current_epoch runid(注意:这时的runid是自己的run id,每个sentinel节点都有一个自己运行时id)
- 目标sentinel回复,由于这个选择领头sentinel的过程符合先到先得的原则,举例:sentinel1判断了客观下线,向sentinel2发送了第一步中的命令,sentinel2回复了sentinel1,说选你为领头,这时候sentinel3也向sentinel2发送第一步的命令,sentinel2会直接拒绝回复
- 当sentinel发现选自己的节点个数超过majority(注意上面写的一种特殊情况quorum>majority)的个数的时候,自己就是领头节点
- 如果没有一个sentinel达到了majority的数量,等一段时间,重新选举
故障转移过程
通过上面的介绍,已经有了领头sentinel,下面就是要做故障转移了,故障转移的一个主要问题和选择领头sentinel问题差不多,到底要选择哪一个slaver节点来作为master呢?按照我们一般的常识,我们会认为哪个slaver中的数据和master中的数据相识度高哪个slaver就是master了,其实哨兵模式也差不多是这样判断的,不过还有别的判断条件,详细介绍如下:
在进行选择之前需要先剔除掉一些不满足条件的slaver,这些slaver不会作为变成master的备选
- 剔除列表中已经下线的从服务
- 剔除有5s没有回复sentinel的info命令的slaver
- 剔除与已经下线的主服务连接断开时间超过 down-after-milliseconds*10+master宕机时长的slaver
选主过程
- 选择优先级最高的节点,通过sentinel配置文件中的replica-priority配置项,这个参数越小,表示优先级越高
- 如果第一步中的优先级相同,选择offset最大的,offset表示主节点向从节点同步数据的偏移量,越大表示同步的数据越多
-
后续事项
新的主节点已经选择出来了,并不是到这里就完事了,后续还需要做一些事情,如下
领头sentinel向别的slaver发送slaveof命令,告诉他们新的master是谁谁谁,你们向这个master复制数据
- 如果之前的master重新上线时,领头sentinel同样会给起发送slaveof命令,将其变成从节点
1. 哨兵模式是结点如何相互发现的?
非常神奇的是我们部署哨兵的时候之配置了 sentinel monitor redis-master 192.168.44.186 6379 2 也就是只配置了master的地址 为什么其他哨兵上线的时候会再配置文件中发现并配置其他哨兵节点和slave节点的信息呢?
daemonize yesport 26379protected-mode nodir "/root/redis/redis-6.0.9/sentinel-tmp"sentinel myid e55acfb38d611736dfcca8b2651b04def5b680cbsentinel deny-scripts-reconfig yessentinel monitor redis-master 192.168.122.1 6381 2sentinel auth-pass redis-master 123456# Generated by CONFIG REWRITEpidfile "/var/run/redis.pid"user default on nopass ~* +@allsentinel config-epoch redis-master 2sentinel leader-epoch redis-master 2sentinel known-replica redis-master 192.168.122.1 6380sentinel known-replica redis-master 192.168.122.1 6379sentinel known-sentinel redis-master 192.168.122.1 26381 d27c0b3d3688372e8beca9827a1b5baf1c994808sentinel known-sentinel redis-master 192.168.122.1 26380 b3a7356236aa9c8af67e0d8b000ea916da6a2cb4sentinel current-epoch 2
实际上sentinel利用了master的发布/订阅机制,去自动发现其它也监控了同一个master的sentinel节点。
因为Sentinel是一个特殊状态的Redis节点,它也有发布订阅的功能。
哨兵上线时,给所有的Reids节点(master/slave)的名字为sentinel:hello的channle发送消息。
每个哨兵都订阅了所有Reids节点名字为sentinel:hello的channle,所以能互相感知对方的存在,而进行监控。
2. 主从拷贝原理和细节

Talk is cheap. Show me the code
redis 主从拷贝的代码实现主要是replication.c
/* ---------------------------------- MASTER -------------------------------- */void createReplicationBacklog(void) /* 创建backlog的buffer */void resizeReplicationBacklog(long long newsize) /* 调整复制备份日志的大小,当replication backlog被修改的时候 */void freeReplicationBacklog(void) /* 释放备份日志 */void feedReplicationBacklog(void *ptr, size_t len) /* 往备份日志中添加添加数据操作,会引起master_repl_offset偏移量的增加 */void feedReplicationBacklogWithObject(robj *o) /* 往backlog添加数据,以Redis 字符串对象作为参数 */void replicationFeedSlaves(list *slaves, int dictid, robj **argv, int argc) /* 将主数据库复制到从数据库 */void replicationFeedMonitors(redisClient *c, list *monitors, int dictid, robj **argv, int argc) /* 发送数据给monitor监听者客户端 */long long addReplyReplicationBacklog(redisClient *c, long long offset) /* slave从客户单添加备份日志 */int masterTryPartialResynchronization(redisClient *c) /* 主数据库尝试分区同步 */void syncCommand(redisClient *c) /* 同步命令函数 */void replconfCommand(redisClient *c) /* 此函数用于从客户端进行配置复制进程中的执行参数设置 */void sendBulkToSlave(aeEventLoop *el, int fd, void *privdata, int mask) /* 给slave客户端发送BULK数据 */void updateSlavesWaitingBgsave(int bgsaveerr) /* 此方法将用于后台保存进程快结束时调用,更新slave从客户端 *//* ----------------------------------- SLAVE -------------------------------- */void replicationAbortSyncTransfer(void) /* 中止与master主数据的同步操作 */void replicationSendNewlineToMaster(void) /* 从客户端发送空行给主客户端,破坏了原本的协议格式,避免让主客户端检测出从客户端超时的情况 */void replicationEmptyDbCallback(void *privdata) /* 清空数据库后的回调方法,当老数据被刷新出去之后等待加载新数据的时候调用 */void readSyncBulkPayload(aeEventLoop *el, int fd, void *privdata, int mask) /* 从客户端读取同步的Sync的BULK数据 */char *sendSynchronousCommand(int fd, ...) /* 从客户端发送给主客户端同步数据的命令,附上验证信息,和一些参数配置信息 */int slaveTryPartialResynchronization(int fd) /* 从客户端尝试分区同步操作 */void syncWithMaster(aeEventLoop *el, int fd, void *privdata, int mask) /* 与主客户端保持同步,期间包括端口号等的确认,socket连接 */int connectWithMaster(void) /* 连接主客户端 */void undoConnectWithMaster(void) /* 撤销连接主客户端 */int cancelReplicationHandshake(void) /* 当已经存在一个复制进程时,中止一个非阻塞的replication复制的尝试 */void replicationSetMaster(char *ip, int port) /* 设定主客户端的ip地址和端口号 */void replicationUnsetMaster(void)void slaveofCommand(redisClient *c)void roleCommand(redisClient *c)void replicationSendAck(void) /* 发送ACK包给主客户端 ,告知当前的进程偏移量 *//* ---------------------- MASTER CACHING FOR PSYNC -------------------------- */void replicationCacheMaster(redisClient *c) /* 缓存客户端信息 */void replicationDiscardCachedMaster(void) /* 当某个客户端将不会再回复的时候,可以释放掉缓存的主客户端 */void replicationResurrectCachedMaster(int newfd) /* 将缓存客户端复活 *//* ------------------------- MIN-SLAVES-TO-WRITE --------------------------- */void refreshGoodSlavesCount(void) /* 更新slave从客户端数量 */void replicationScriptCacheInit(void)void replicationScriptCacheFlush(void)void replicationScriptCacheAdd(sds sha1)int replicationScriptCacheExists(sds sha1)void replicationCron(void)
void disklessLoadRestoreBackups(redisDb *backup, int restore, int empty_db_flags){if (restore) {/* Restore. *///emptyDbGeneric 会 Remove all keys from all the databases in a Redis server.emptyDbGeneric(server.db,-1,empty_db_flags,replicationEmptyDbCallback);for (int i=0; i<server.dbnum; i++) {dictRelease(server.db[i].dict);dictRelease(server.db[i].expires);server.db[i] = backup[i];}} else {/* Delete (Pass EMPTYDB_BACKUP in order to avoid firing module events) . */emptyDbGeneric(backup,-1,empty_db_flags|EMPTYDB_BACKUP,replicationEmptyDbCallback);for (int i=0; i<server.dbnum; i++) {dictRelease(backup[i].dict);dictRelease(backup[i].expires);}}zfree(backup);}
可以看到slave收到回复 会移除本地全部的key从master再从 master服务器中接受快照。
全量同步
Redis全量复制一般发生在Slave初始化阶段,这时Slave需要将Master上的所有数据都复制一份。具体步骤如下:
- 从服务器连接主服务器,发送SYNC命令;
- 主服务器接收到SYNC命名后,开始执行BGSAVE命令生成RDB文件并使用缓冲区记录此后执行的所有写命令;
- 主服务器BGSAVE执行完后,向所有从服务器发送快照文件,并在发送期间继续记录被执行的写命令;
- 从服务器收到快照文件后丢弃所有旧数据,载入收到的快照;
- 主服务器快照发送完毕后开始向从服务器发送缓冲区中的写命令;
- 从服务器完成对快照的载入,开始接收命令请求,并执行来自主服务器缓冲区的写命令;
增量同步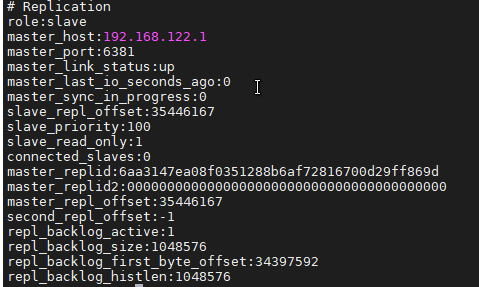
slave 和 master 维护一个偏移量 如果两个偏移一致就说明数据是一致性的 如果slave的便宜量小于master说明slave的数据落后于slave(slave是只读的所以不会超过master)
Redis增量复制是指Slave初始化后开始正常工作时主服务器发生的写操作同步到从服务器的过程。
增量复制的过程主要是主服务器每执行一个写命令就会向从服务器发送相同的写命令,从服务器接收并执行收到的写命令。
Redis主从同步策略
主从刚刚连接的时候,进行全量同步;全同步结束后,进行增量同步。当然,如果有需要,slave 在任何时候都可以发起全量同步。redis 策略是,无论如何,首先会尝试进行增量同步,如不成功,要求从机进行全量同步。
哨兵模式解决的问题和缺点
哨兵模式实现了mastr -slave 主节点下线后进行故障转移的功能。
mastr -slave 模式 进行了读写分离 slave 节点进行读mastr 进行写 这大大减少了读压力大的问题。但是依然没有解决写压力大的问题。如果频繁进行写的话依然会导致mastr节点挂掉
3.数据分片
1.一致性hash算法 hash环
一致性Hash算法也是使用取模的方法,只是,刚才描述的取模法是对服务器的数量进行取模,而一致性Hash算法是对2^ 32-1取模,什么意思呢简单来说,一致性Hash算法将整个Hash值控件组织成一个虚拟的圆环,如假设某哈希函数H的值空间为0-2^32-1取模(即哈希值是一个32位无符号整型),整个哈希环如下: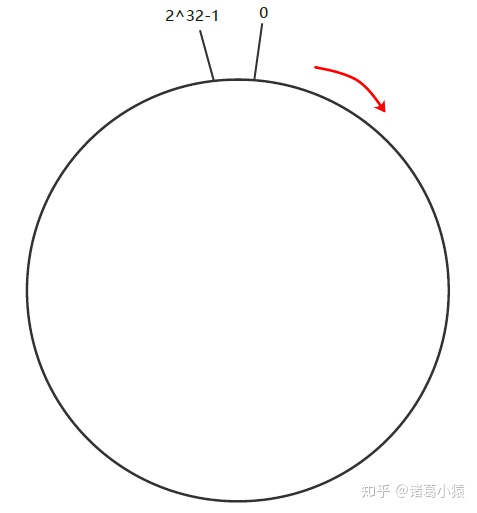
整个空间按顺时针方向组织,圆环的正上方的点代表0,0点右侧的第一个点代表1,以此类推,2、3、4、5、6……直到2^ 32-1,也就是说0点左侧的第一个点代表2^ 32-1, 0和2^ 32-1在零点中方向重合,我们把这个由2^32个点组成的圆环称为Hash环。
下一步将各个服务器使用Hash进行一个哈希,具体可以选择服务器的主机名(考虑到ip变动,不要使用ip)作为关键字进行哈希,这样每台机器就能确定其在哈希环上的位置,这里假设将上文中三个master节点的IP地址哈希后在环空间的位置如下: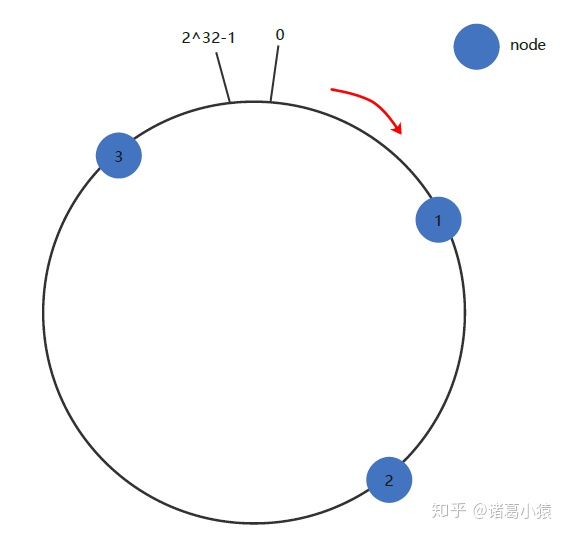
下面将三条key-value数据也放到环上:将数据key使用相同的函数Hash计算出哈希值,并确定此数据在环上的置。将数据从所在位置顺时针找第一台遇到的服务器节点,这个节点就是该key存储的服务器!
例如我们有a、b、c三个key,经过哈希计算后,在环空间上的位置如下:key-a存储在node1,key-b存储在node2,key-c存储在node3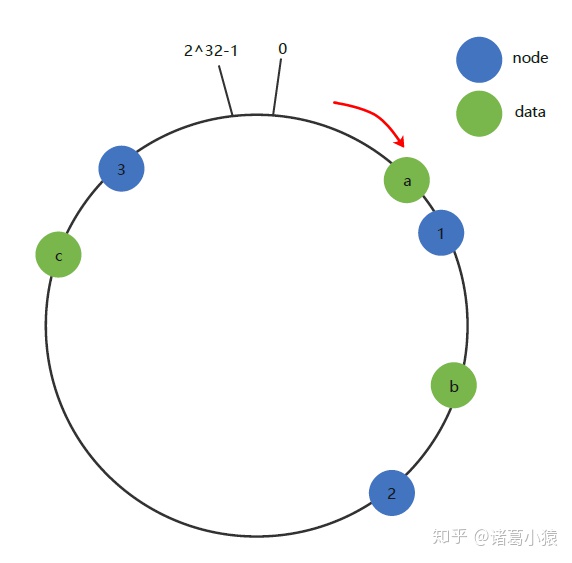
容错性和可扩展性
现假设Node 2不幸宕机,可以看到此时对象key-a和key-c不会受到影响,只有key-b被重定位到Node 3。一般的,在一致性Hash算法中,如果一台服务器不可用,则受影响的数据仅仅是此服务器到其环空间中前一台服务器(即沿着逆时针方向行走遇到的第一台服务器,如下图中Node 2与Node 1之间的数据,图中受影响的是key-2)之间数据,其它不会受到影响。
同样的,如果集群中新增一个node 4,受影响的数据是node 1和node 4之间的数据,其他的数据是不受影响的。
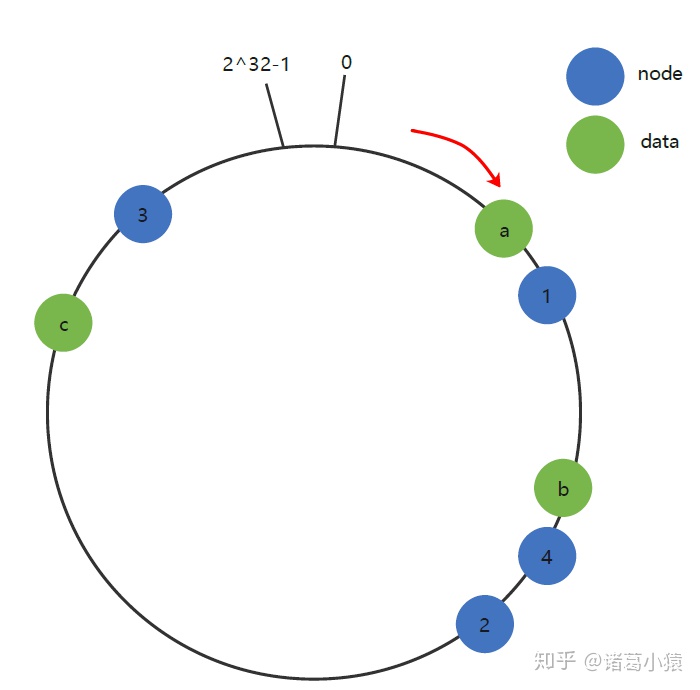
综上所述,一致性Hash算法对于节点的增减都只需重定位环空间中的一小部分数据,具有较好的容错性和可扩展性。
数据倾斜(添加虚拟节点)
一致性Hash算法在服务节点太少时,容易因为节点分部不均匀而造成数据倾斜(被缓存的对象大部分集中缓存在某一台服务器上)问题,例如系统中只有两台服务器,此时必然造成大量数据集中到Node 2上,而只有极少量会定位到Node 1上。其环分布如下: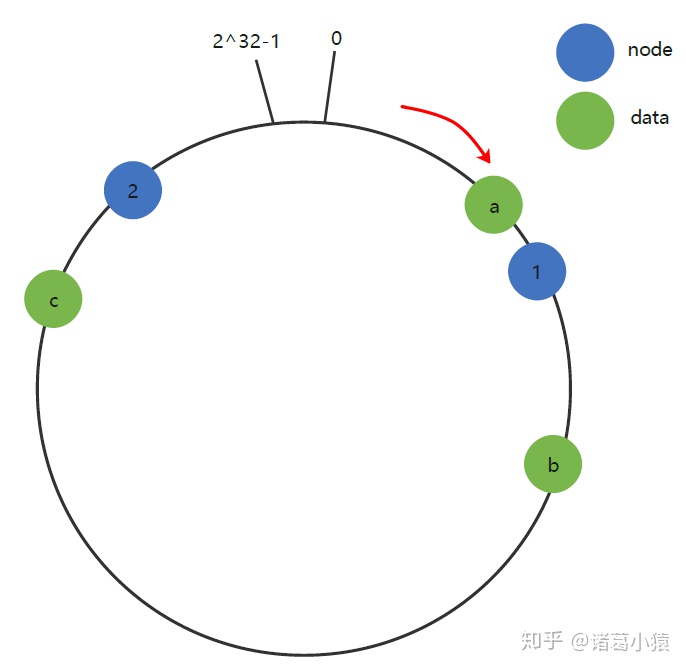
为了解决数据倾斜问题,一致性Hash算法引入了虚拟节点机制,即对每一个服务节点计算多个哈希,每个计算结果位置都放置一个此服务节点,称为虚拟节点。具体做法可以在主机名的后面增加编号来实现。例如上面的情况,可以为每台服务器计算三个虚拟节点,于是可以分别计算 “Node 1#1”、“Node 1#2”、“Node 1#3”、“Node 2#1”、“Node 2#2”、“Node 2#3”的哈希值,于是形成六个虚拟节点: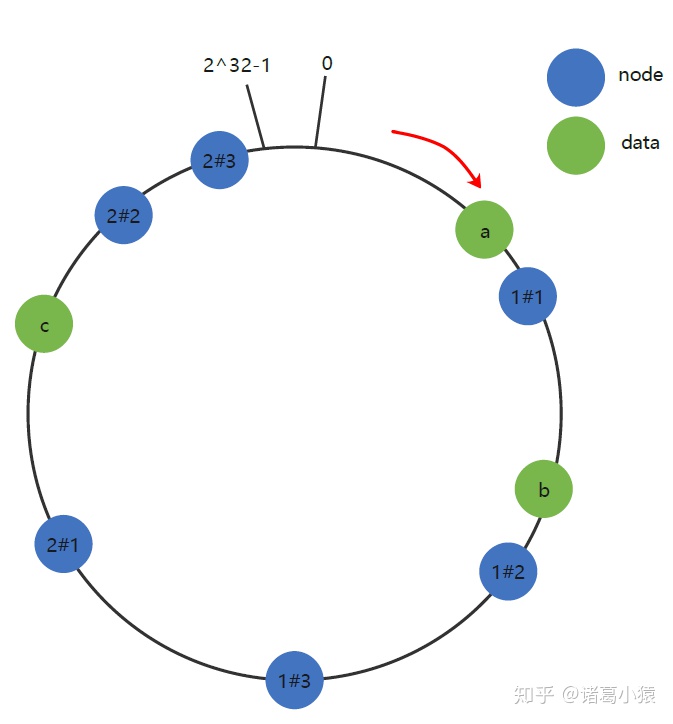
上图中虚拟节点node 1#1,node 1#2,node 1#3都属于真实节点node 1;虚拟节点node 2#1,node 2#2,node 2#3都属于真实节点node 2。
2.Jedis中一致性哈希算法
1.如何使用?
public void test3() {//设置连接池的相关配置JedisPoolConfig poolConfig = new JedisPoolConfig();poolConfig.setMaxTotal(2);poolConfig.setMaxIdle(1);poolConfig.setMaxWaitMillis(2000);poolConfig.setTestOnBorrow(false);poolConfig.setTestOnReturn(false);//定义redis的多个节点机器List<JedisShardInfo> list = new ArrayList<JedisShardInfo>() {{add(new JedisShardInfo("127.0.0.1", 6379));add(new JedisShardInfo("127.0.0.1", 6380));add(new JedisShardInfo("127.0.0.1", 6381));}};//定义redis分片连接池ShardedJedisPool jedisPool = new ShardedJedisPool(poolConfig, list);//获取连接操作redis 进行查询等其他操作//使用后一定关闭,还给连接池try (ShardedJedis jedis = jedisPool.getResource()) {//向redis中添加20个记录查看分片结果for (int i = 0; i < 10; i++) {//增加的记录格式为 key=NUM_i value=ijedis.set("NUM_" + i, "" + i);jedis.get("NUM_" + i);}}
2.如何实现?
主要代码在 https://github.com/redis/jedis/blob/818dc9db08f87004dca5ab7e4a8e8cf06c0ea15a/src/main/java/redis/clients/jedis/util/Sharded.java
jedis 用 treemap实现了一个hash环算法。 利用treemap红黑树提高查找速度。
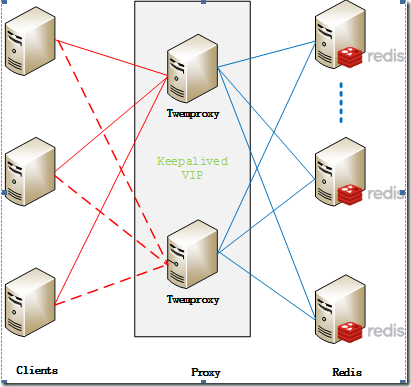
3.twemproxy +redis (不建议)
2.数据插槽 redis slot

4.redis cluster
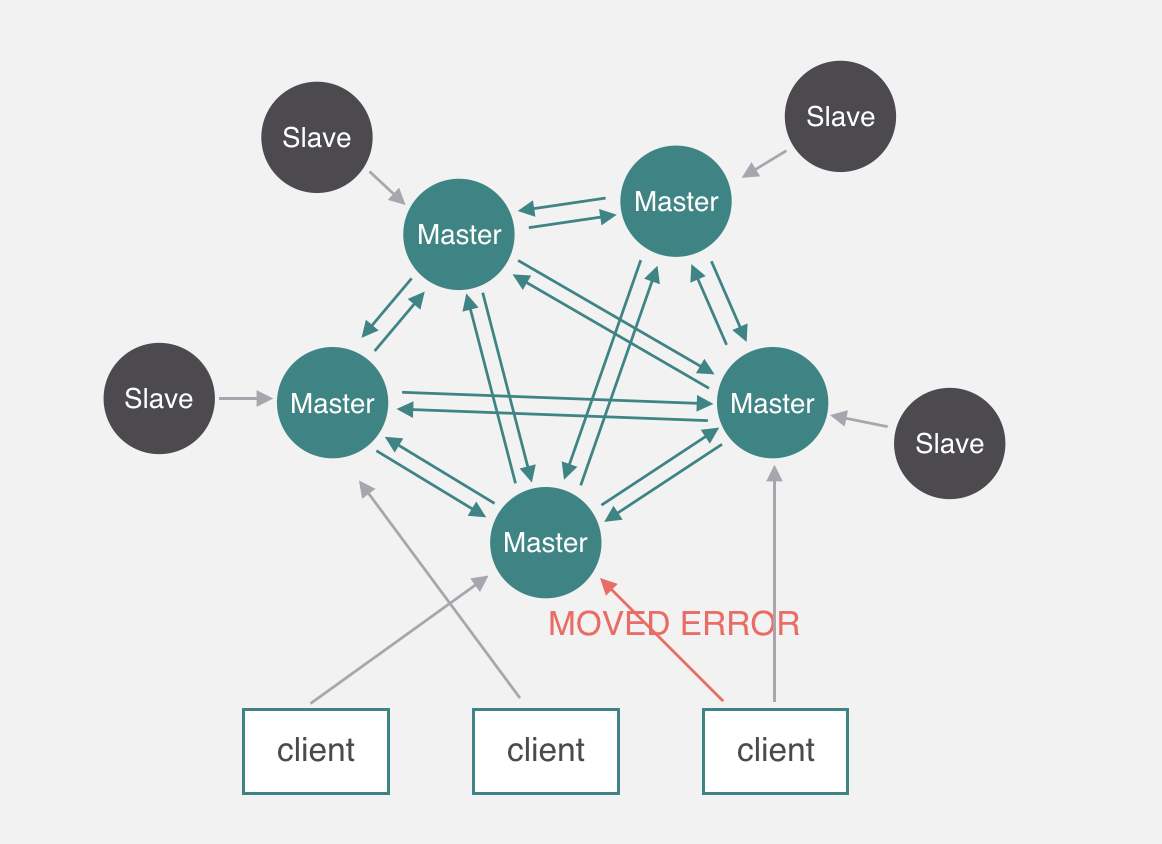
1.架构图
2.简单的搭建
为了节省机器,我们直接把6个Redis实例安装在同一台机器上(3主3从),只是使用不同的端口号。
机器IP 192.168.44.181
可以跟单机的redis安装在同一台机器上,因为数据目录不同,没有影响。
cd /usr/local/soft/redis-6.0.9mkdir redis-clustercd redis-clustermkdir 7291 7292 7293 7294 7295 7296
复制redis配置文件到7291目录
cp /usr/local/soft/redis-6.0.9/redis.conf /usr/local/soft/redis-6.0.9/redis-cluster/7291
修改7291的redis.conf配置文件,内容:
cd /usr/local/soft/redis-6.0.9/redis-cluster/7291>redis.confvim redis.conf
内容如下:
port 7291daemonize yesprotected-mode nodir /usr/local/soft/redis-6.0.9/redis-cluster/7291/cluster-enabled yescluster-config-file nodes-7291.confcluster-node-timeout 5000appendonly yespidfile /var/run/redis_7291.pid
把7291下的redis.conf复制到其他5个目录。
cd /usr/local/soft/redis-6.0.9/redis-cluster/7291cp redis.conf ../7292cp redis.conf ../7293cp redis.conf ../7294cp redis.conf ../7295cp redis.conf ../7296
批量替换内容
cd /usr/local/soft/redis-6.0.9/redis-clustersed -i 's/7291/7292/g' 7292/redis.confsed -i 's/7291/7293/g' 7293/redis.confsed -i 's/7291/7294/g' 7294/redis.confsed -i 's/7291/7295/g' 7295/redis.confsed -i 's/7291/7296/g' 7296/redis.conf
启动6个Redis节点
cd /usr/local/soft/redis-6.0.9/./src/redis-server redis-cluster/7291/redis.conf./src/redis-server redis-cluster/7292/redis.conf./src/redis-server redis-cluster/7293/redis.conf./src/redis-server redis-cluster/7294/redis.conf./src/redis-server redis-cluster/7295/redis.conf./src/redis-server redis-cluster/7296/redis.conf
是否启动了6个进程
ps -ef|grep redis
创建集群
注意用绝对IP,不要用127.0.0.1
cd /usr/local/soft/redis-6.0.9/src/redis-cli --cluster create 192.168.44.181:7291 192.168.44.181:7292 192.168.44.181:7293 192.168.44.181:7294 192.168.44.181:7295 192.168.44.181:7296 --cluster-replicas 1
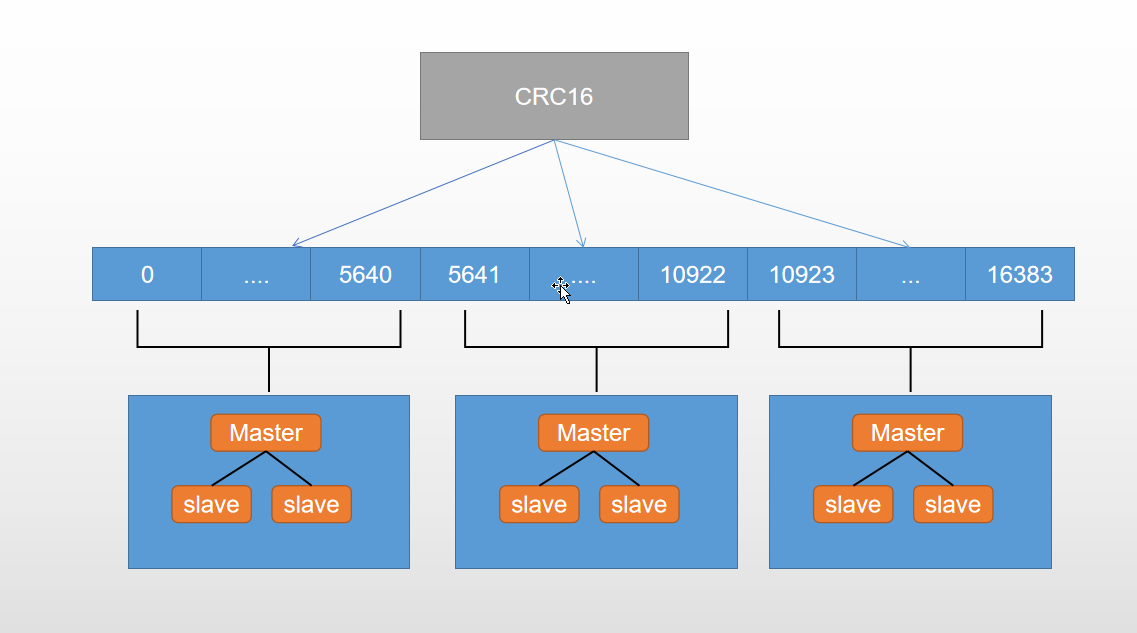
Redis会给出一个预计的方案,对6个节点分配3主3从,如果认为没有问题,输入yes确认
>>> Performing hash slots allocation on 6 nodes...Master[0] -> Slots 0 - 5460Master[1] -> Slots 5461 - 10922Master[2] -> Slots 10923 - 16383Adding replica 192.168.44.181:7295 to 192.168.44.181:7291Adding replica 192.168.44.181:7296 to 192.168.44.181:7292Adding replica 192.168.44.181:7294 to 192.168.44.181:7293>>> Trying to optimize slaves allocation for anti-affinity[WARNING] Some slaves are in the same host as their masterM: 2058bd8fc0def0abe746816221c5b87f616e78ae 192.168.44.181:7291slots:[0-5460] (5461 slots) masterM: 4e41266f2fb7944420d66235475318f5f9526cd8 192.168.44.181:7292slots:[5461-10922] (5462 slots) masterM: 9ff8ac86b5faf3c0eca149f090800efea3b142e0 192.168.44.181:7293slots:[10923-16383] (5461 slots) masterS: 8383088d3ce75732fc9acb31ca4bce68833028f7 192.168.44.181:7294replicates 9ff8ac86b5faf3c0eca149f090800efea3b142e0S: d185adbfa62133e30cee291b028eff451502ecca 192.168.44.181:7295replicates 2058bd8fc0def0abe746816221c5b87f616e78aeS: 634709cf14809976ea40b65615f816e31d424748 192.168.44.181:7296replicates 4e41266f2fb7944420d66235475318f5f9526cd8Can I set the above configuration? (type 'yes' to accept):
注意看slot的分布:
7291 [0-5460] (5461个槽)7292 [5461-10922] (5462个槽)7293 [10923-16383] (5461个槽)
输入yes确认,集群创建完成
>>> Performing Cluster Check (using node 192.168.44.181:7291)M: 2058bd8fc0def0abe746816221c5b87f616e78ae 192.168.44.181:7291slots:[0-5460] (5461 slots) master1 additional replica(s)S: 8383088d3ce75732fc9acb31ca4bce68833028f7 192.168.44.181:7294slots: (0 slots) slavereplicates 9ff8ac86b5faf3c0eca149f090800efea3b142e0S: d185adbfa62133e30cee291b028eff451502ecca 192.168.44.181:7295slots: (0 slots) slavereplicates 2058bd8fc0def0abe746816221c5b87f616e78aeM: 9ff8ac86b5faf3c0eca149f090800efea3b142e0 192.168.44.181:7293slots:[10923-16383] (5461 slots) master1 additional replica(s)M: 4e41266f2fb7944420d66235475318f5f9526cd8 192.168.44.181:7292slots:[5461-10922] (5462 slots) master1 additional replica(s)S: 634709cf14809976ea40b65615f816e31d424748 192.168.44.181:7296slots: (0 slots) slavereplicates 4e41266f2fb7944420d66235475318f5f9526cd8[OK] All nodes agree about slots configuration.>>> Check for open slots...>>> Check slots coverage...[OK] All 16384 slots covered.
重置集群的方式是在每个节点上个执行cluster reset,然后重新创建集群
批量写入值
cd /usr/local/soft/redis-6.0.9/redis-cluster/vim setkey.sh
脚本内容
#!/bin/bashfor ((i=0;i<20000;i++))doecho -en "helloworld" | redis-cli -h 192.168.44.181 -p 7291 -c -x set name$i >>redis.logdone
chmod +x setkey.sh./setkey.sh
连接到客户端
redis-cli -p 7291redis-cli -p 7292redis-cli -p 7293
每个节点分布的数据
127.0.0.1:7291> dbsize(integer) 6652127.0.0.1:7292> dbsize(integer) 6683127.0.0.1:7293> dbsize(integer) 6665
新增节点如何重新分片:
一个新节点add-node加入集群后,是没有slots的。
redis-cli --cluster reshard 目标节点(IP端口)
这时会要求你输入分配的槽位,生成reshard计划,确定就会迁移数据
cluster管理命令
其他命令,比如添加节点、删除节点,重新分布数据:
redis-cli --cluster help
Cluster Manager Commands:create host1:port1 ... hostN:portN--cluster-replicas <arg>check host:port--cluster-search-multiple-ownersinfo host:portfix host:port--cluster-search-multiple-ownersreshard host:port--cluster-from <arg>--cluster-to <arg>--cluster-slots <arg>--cluster-yes--cluster-timeout <arg>--cluster-pipeline <arg>--cluster-replacerebalance host:port--cluster-weight <node1=w1...nodeN=wN>--cluster-use-empty-masters--cluster-timeout <arg>--cluster-simulate--cluster-pipeline <arg>--cluster-threshold <arg>--cluster-replaceadd-node new_host:new_port existing_host:existing_port--cluster-slave--cluster-master-id <arg>del-node host:port node_idcall host:port command arg arg .. argset-timeout host:port millisecondsimport host:port--cluster-from <arg>--cluster-copy--cluster-replacehelpFor check, fix, reshard, del-node, set-timeout you can specify the host and port of any working node in the cluster.
集群命令
cluster info :打印集群的信息
cluster nodes :列出集群当前已知的所有节点(node),以及这些节点的相关信息。
cluster meet :将 ip 和 port 所指定的节点添加到集群当中,让它成为集群的一份子。
cluster forget
cluster replicate
cluster saveconfig :将节点的配置文件保存到硬盘里面。
槽slot命令
cluster addslots [slot …] :将一个或多个槽(slot)指派(assign)给当前节点。
cluster delslots [slot …] :移除一个或多个槽对当前节点的指派。
cluster flushslots :移除指派给当前节点的所有槽,让当前节点变成一个没有指派任何槽的节点。
cluster setslot node
cluster setslot migrating
cluster setslot importing
cluster setslot stable :取消对槽 slot 的导入(import)或者迁移(migrate)。
键命令
cluster keyslot :计算键 key 应该被放置在哪个槽上。
cluster countkeysinslot :返回槽 slot 目前包含的键值对数量。
cluster getkeysinslot :返回 count 个 slot 槽中的键
3.分片算法 redis slot
4.故障转移
1.slave发现自己的master变成了FAIL
2.将自己记录的集群currerntEpoch加一 (这是一个集群状态相关的概念,可以当做记录集群状态变更的递增版本号。每个集群节点,都会通过 server.cluster->currentEpoch 记录当前的 currentEpoch。
集群节点创建时,不管是 master 还是 slave,都置 currentEpoch 为 0。当前节点接收到来自其他节点的包时,如果发送者的 currentEpoch(消息头部会包含发送者的 currentEpoch)大于当前节点的currentEpoch,那么当前节点会更新 currentEpoch 为发送者的 currentEpoch。因此,集群中所有节点的 currentEpoch 最终会达成一致,相当于对集群状态的认知达成了一致)并广播 FAILOVER_AUTH_REQUEST(gossip协议 在集群中无论添加几个节点复杂度是恒定的)
3.其它节点收到该信息,只有master响应,判断请求这合法性,并发生FAILER_AUTH_ACK,对每个Epoch只发送一次ack
4.尝试failover的slave收集FAILER_AUTH_ACK,
5.超过半数确认变成新的Master
6.广播pong通知全部节点 篡位成功
5.特点
1.无中心架构
2.数据按照Slot存储分布在多个节点,节点间数据共享,可动态调节数据分布
3.可扩展,可线性扩展到1000个节点 官方不推荐超过1000个,节点可动态添加或者删除
4.降低运维成本部署容易
5.高可用,部分节点不可用时集群依然可用,可用通过增加slave做stanby做数据副本,能够实现自动故障转移,节点之间通过gossip协议交换状态,用投票机制完成slave到master的提升。
gossip协议
举个例子
一个村庄(集群) 有 3户人家(redis group) 每户人家都有 爸爸(master) 和儿子(slave)两个人。
每个人都知道 整个村人名 和谁是哪户人家的爸爸 有一份对应关系的家谱(Cluster中的每个节点都维护一份在自己看来当前整个集群的状态)
一天小明爸爸死了,他当户主了 先把自己手上的家谱升级一个版本再 就随机 告诉3个人 【小明爸爸死了 2203房是小明当Master了】这3个人受到消息,再各自告诉三个人直到所有人都知道这个消息,但是 master收到到消息还会写信给小明 【我知道了你爸爸死了,同意你当家主!】 当一半的 家庭回信收到了 小明就是2203的master了。
Cluster中的每个节点都维护一份在自己看来当前整个集群的状态,主要包括:
- 当前集群状态
- 集群中各节点所负责的slots信息,及其migrate状态
- 集群中各节点的master-slave状态
- 集群中各节点的存活状态及不可达投票
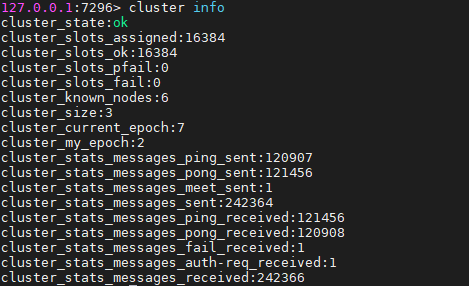
因为任意节点都有整个集群的拓扑结构,所以jedis集群只需要传入任意一个节点就可以缓存全部数据的哈希槽了。

若有收获,就点个赞吧
0 人点赞
