传统的配置文件xml很必要(查询修改)
业务场景
若业务查询条件为排列组合条件的时候,就最好写xml,全写Plus代码会使得逻辑复杂
比如过滤查询场景…
xml还是很强大的.
业务场景
过滤和列表查询应该合并为一个接口,为什么?
因为我们的分行业数据是点一页返回一页的,不输入分页信息默认返回第一页
如果过滤功能的查询返回结果不止一页,那么用户查看第二页的过滤结果的时候,他点击页码2跟他不过滤查询点击页码2调用的肯定是同一个查询接口,所以合并起来写
SQL基础分页方式
mybatis接口
List<TaiModelChange> filterAndLikeQuery(TaiModelChangeQryRequest taiModelChangeQryRequest);
xml文件,$可以做计算
<?xml version="1.0" encoding="UTF-8"?><!DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN" "http://mybatis.org/dtd/mybatis-3-mapper.dtd"><mapper namespace="com.iwhalecloud.aiFactory.aiResource.modelChange.dao.TaiModelChangeMapper"><select id="filterAndLikeQuery" parameterType="com.iwhalecloud.aiFactory.aiResource.modelChange.vo.TaiModelChangeNewRequest" resultType="com.iwhalecloud.aiFactory.aiResource.modelChange.dto.TaiModelChange" useCache="false">SELECT * FROM tai_model_change t<where><if test="name != null and name != ''" >and t.name LIKE concat('%',#{name},'%')</if><if test="status != null and status != ''" >and t.status = #{status}</if></where>ORDER BYt.CREATE_TIME DESCLIMIT ${(pageInfo.current-1)*pageInfo.size} , #{pageInfo.size}</select></mapper>
实现类
/*** @Author: liuyan* @Date: 2021/8/5 14:30*/@Servicepublic class TaiModelChangeServiceImpl implements TaiModelChangeService {@AutowiredTaiModelChangeMapper taiModelChangeMapper;@AutowiredTaiModelTamplateValMapper taiModelTamplateValMapper;@AutowiredTaiModelTemplateAttrMapper taiModelTemplateAttrMapper;@AutowiredTaiModelChangeTemplateMapper taiModelChangeTemplateMapper;@AutowiredInferenceTaiModelMapper inferenceTaiModelMapper;/*** 列表展示 与 过滤查询 二合一** @param taiModelChangeQryRequest* @return*/@Overridepublic PageInfo<TaiModelChangeResponse> getChangeModel(TaiModelChangeQryRequest taiModelChangeQryRequest) {Page pageInfo = taiModelChangeQryRequest.getPageInfo();if (pageInfo == null) {pageInfo = new Page();pageInfo.setCurrent(0);pageInfo.setSize(10);taiModelChangeQryRequest.setPageInfo(pageInfo);}List<TaiModelChange> taiModelChanges = taiModelChangeMapper.filterAndLikeQuery(taiModelChangeQryRequest);ArrayList<TaiModelChangeResponse> taiModelChangeResponses = new ArrayList<>();Iterator<TaiModelChange> iterator = taiModelChanges.iterator();while (iterator.hasNext()) {TaiModelChange next = iterator.next();TaiModelChangeResponse taiModelChangeResponse = queryChangeModel(next);taiModelChangeResponses.add(taiModelChangeResponse);}PageInfo<TaiModelChangeResponse> taiModelChangeResponsePageInfo = new PageInfo<>(pageInfo.getCurrent(), pageInfo.getSize(), pageInfo.getTotal(), taiModelChangeResponses);return taiModelChangeResponsePageInfo;}}
实体类Page:
import com.baomidou.mybatisplus.plugins.Page;
实体类PageInfo:
package com.iwhalecloud.aiFactory.common.dto;import lombok.ToString;import java.io.Serializable;import java.util.Collections;import java.util.List;@ToStringpublic class PageInfo<T> implements Serializable {/*** 总数*/private int total = 0;/*** 每页显示条数,默认 10*/private int size = 10;/*** 总页数*/private int pages = 0;/*** 当前页*/private int current = 1;private int pageCount; // 总页数/*** 查询数据列表*/private List<T> list = Collections.emptyList();public PageInfo() {}public PageInfo(int current, int size) {this.size = size;this.current = current;}public PageInfo(int current, int size, int total, List<T> list) {this.total = total;this.size = size;this.current = current;this.list = list;this.pages = (total + size - 1) / size;}public int getTotal() {return total;}public PageInfo<T> setTotal(int total) {this.total = total;pages = (total + size - 1) / size;return this;}public int getSize() {return size;}public PageInfo<T> setSize(int size) {this.size = size;pages = (total + size - 1) / size;return this;}public int getPages() {return pages;}public int getCurrent() {return current;}public PageInfo<T> setCurrent(int current) {this.current = current;return this;}public List<T> getList() {return list;}public PageInfo<T> setList(List<T> list) {this.list = list;return this;}public int getPageCount() {return pageCount;}public void setPageCount(int pageCount) {this.pageCount = pageCount;}}
Mybatis 进行数值计算
场景:分页的时候,传入参数为当前页数,每页数量,使用limt时要自己计算初始下标。
使用 $,用{}将要计算的数据包起来。
LIMIT ${pageNum * pageSize}, #{callRecordQueryDto.pageSize}
#、$的区别:
#{ }是预编译处理,MyBatis在处理#{ }时,会将sql中的#{ }替换为?,然后调用PreparedStatement的set方法来赋值,传入字符串后,会在值两边加上单引号,如传入1,2,3就会变成’1,2,3’。
${ }是字符串替换,MyBatis在处理${ }时,会将sql中的${ }替换为变量的值,传入的数据不会在两边加上单引号。
注意:使用${ }会导致sql注入,不利于系统的安全性! SQL注入:就是通过把SQL命令插入到Web表单提交或输入域名或页面请求的查询字符串,最终达到欺骗服务器执行恶意的SQL命令。常见的有匿名登录(在登录框输入恶意的字符串)、借助异常获取数据库信息等
一般能用#的就别用$
$方式一般用于传入数据库对象,例如传入字段名、表名等,例如order by ${column}。
$方式还用于传递数值计算公式,因为#方式时预编译处理PreparedStatement,只能识别字段?代表已有字段,所以识别不了计算公式引用。
标准的两层数据模型【新增】架构
dto文件夹:Dto(Bean)不必多说
vo文件夹:MsgTaskRequest,继承dto MsgTask,可以封装额外的集合
两层数据结构定义
//MsgTask略//MsgUser略@Datapublic class MsgTaskRequest extends MsgTask {private List<MsgUser> msgUser;}
持久层与业务层实现
Mapper
无需定义,serviceimpl层使用Plus-Mapper自带接口实现插入,使用Plus-IService自带接口实现批量插入,
Service事务控制
public interface MsgTaskService extends IService<MsgTask> {public void msgTaskAdd(MsgTaskRequest msgTaskRequest);}package com.iwhalecloud.aiFactory.aiResource.aimessage.service.impl;import java.util.ArrayList;import java.util.Date;import java.util.List;import com.baomidou.mybatisplus.plugins.Page;import com.baomidou.mybatisplus.service.impl.ServiceImpl;import com.iwhalecloud.aiFactory.aiResource.aimessage.dao.MsgLogMapper;import com.iwhalecloud.aiFactory.aiResource.aimessage.dto.MsgLog;import com.iwhalecloud.aiFactory.aiResource.aimessage.dto.MsgTask;import com.iwhalecloud.aiFactory.aiResource.aimessage.dto.MsgUser;import com.iwhalecloud.aiFactory.aiResource.aimessage.dao.MsgUserMapper;import com.iwhalecloud.aiFactory.aiResource.aimessage.middle.MsgTaskConditionMiddle;import com.iwhalecloud.aiFactory.aiResource.aimessage.middle.MsgTaskSendDetailMiddle;import com.iwhalecloud.aiFactory.aiResource.aimessage.service.MsgTaskService;import com.iwhalecloud.aiFactory.aiResource.aimessage.dao.MsgTaskMapper;import com.iwhalecloud.aiFactory.aiResource.aimessage.service.MsgUserService;import com.iwhalecloud.aiFactory.aiResource.aimessage.vo.*;import com.iwhalecloud.aiFactory.common.util.BeanUtil;import org.apache.bcel.generic.IF_ACMPEQ;import org.springframework.beans.factory.annotation.Autowired;import org.springframework.stereotype.Service;import org.springframework.transaction.annotation.Transactional;/*** @author hasee* @description 针对表【msg_task】的数据库操作Service实现* @createDate 2022-04-18 15:06:27*/@Servicepublic class MsgTaskServiceImpl extends ServiceImpl<MsgTaskMapper, MsgTask>implements MsgTaskService {@AutowiredMsgTaskMapper msgTaskMapper;@AutowiredMsgUserMapper msgUserMapper;@AutowiredMsgLogMapper msgLogMapper;@Override@Transactional("resourceTransactionManager")public void msgTaskAdd(MsgTaskRequest msgTaskRequest) {List<MsgUser> msgUserList = msgTaskRequest.getMsgUser();MsgTask msgTask = new MsgTask();msgTask.setMsgTmplId(msgTaskRequest.getMsgTmplId());msgTask.setMsgTaskTitle(msgTaskRequest.getMsgTaskTitle());msgTask.setPlatformContent(msgTaskRequest.getPlatformContent());msgTask.setDingdingContent(msgTaskRequest.getDingdingContent());msgTask.setMsgContent(msgTaskRequest.getMsgContent());msgTask.setMsgType(msgTaskRequest.getMsgType());msgTask.setCreateTime(new Date());msgTask.setSendChannel(msgTaskRequest.getSendChannel());msgTask.setMsgTaskParam(msgTaskRequest.getMsgTaskParam());msgTask.setSuccessNum(msgTaskRequest.getSuccessNum());msgTask.setAttribute(msgTaskRequest.getAttribute());msgTask.setSendStatus(MsgTask.CONST_NOSEND_STATUS);msgTask.setSceneType(msgTaskRequest.getSceneType());msgTaskMapper.insert(msgTask);//TODO 发送时间由前端定时触发Integer msgTaskId = msgTask.getMsgTaskId();msgUserList.stream().forEach(e->{e.setMsgTaskId(msgTaskId);msgUserMapper.insert(e);});// msgUserService.insertBatch(msgUserList);for (MsgUser user:msgUserList) {String msgContentReplaced = replaceContent(msgTaskRequest, user)[0];MsgLog msgLog = new MsgLog();msgLog.setMsgTaskId(msgTaskId);msgLog.setUserId(user.getMsgUserId());msgLog.setMsgTitle(msgTaskRequest.getMsgTaskTitle());msgLog.setMsgContent(msgContentReplaced);msgLog.setMsgType(msgTaskRequest.getMsgType());msgLog.setMsgChannel(msgTaskRequest.getSendChannel());msgLog.setMsgState(MsgLog.HAVED_NO_READ);msgLog.setReceiveTime(new Date());msgLog.setSendState(MsgLog.SEND_STATUS_SUCCESS);msgLog.setCreateTime(new Date());msgLog.setUpdateTime(new Date());msgLog.setStatus(MsgLog.DELETE_STATUS_VALIDATED);msgLogMapper.insert(msgLog);}}public String[] replaceContent(MsgTaskRequest msgTaskRequest,MsgUser user){String platformContentReplaced= null;String dingdingContentReplaced= null;String msgContentReplaced = null;String userName = user.getUserName();if(msgTaskRequest.getPlatformContent()!=null){platformContentReplaced = msgTaskRequest.getPlatformContent().replace(MsgTask.CONTENT_VAR_USERNAME,userName);System.out.println("replace"+platformContentReplaced);}if(msgTaskRequest.getDingdingContent()!=null){dingdingContentReplaced = msgTaskRequest.getDingdingContent().replace(MsgTask.CONTENT_VAR_USERNAME,userName);}if(msgTaskRequest.getMsgContent()!=null){msgContentReplaced = msgTaskRequest.getMsgContent().replace(MsgTask.CONTENT_VAR_USERNAME,userName);}return new String[]{platformContentReplaced,dingdingContentReplaced,msgContentReplaced};}}
标准的三层数据模型【查询】架构
复杂且标准的三层结构如下: Entity:实体 Bo:business object业务层对象【也就是中间层middle】,接收业务连表聚合返回 Vo:表示层对象,Bo的扩充就是最终的Response
- 正常应该是Bean Dto Vo(req,response)
- 结果项目里是把Dto当作Bean来用了
- 所以我自己加了层Middle作为Dto,手写Mapper和XML去映射连接表Middle
注意:若是单表查询,直接写vo与逻辑业务mapper返回即可,因为不考虑连接查询的结果映射所以不需要新增中间层模型middle。也无需手写Mapper接口与XML
- 已知标准的两层数据模型新增架构中,新增接口的Request建议继承实体,对新增请求的参数封装
- 查询接口的Request无需继承实体且不建议继承Page,而是自定义
current与size字段,不然手写分页SQL实现会导致框架出错
dto文件夹:Dto(Bean)不必多说
middle文件夹:MsgTaskConditionMiddle具体业务SQL的返回结果有时候无法完全构成最终的响应结果(有些数据不在数据库Invalid bound statement),所以需要这一中间层要求字段与SQL返回字段严格映射。手写Mapper接口与XML
vo文件夹:MsgTaskConditionRequest,MsgTaskConditionResponse,有middle则MsgTaskConditionResponse继承MsgTaskConditionMiddle,没有middle则MsgTaskConditionResponse继承Entity即可,属于HTTP层模型
三层数据结构定义:
//dto略@Datapublic class MsgTaskConditionMiddle implements Serializable {private String msgTaskTitle;private String sendTime;private String msgType;private String sendChannel;}@Datapublic class MsgTaskConditionRequest implements Serializable {//分页参数private Integer current;private Integer size;//实际参数private String msgTaskTitle;private String headTime;private String tailTime;private String msgType;public static final String CONST_MSGTYPE_PLATFORM = "platform";public static final String CONST_MSGTYPE_ENT = "ent";}@Datapublic class MsgTaskConditionResponse extends MsgTaskConditionMiddle implements Serializable {//目标数private Integer targetUserCounts;//发送人private String sendBy;}
持久层与业务层实现:
Mapper
@Mapperpublic interface MsgTaskMapper extends BaseMapper<MsgTask> {public List<MsgTaskConditionMiddle> getTaskPage(MsgTaskConditionRequest msgTaskConditionRequest);}<?xml version="1.0" encoding="UTF-8"?>...<select id="getTaskPage"resultType="com.iwhalecloud.aiFactory.aiResource.aimessage.middle.MsgTaskConditionMiddle">SELECT a.msg_task_title,a.send_time,a.msg_type,a.send_channelFROM msg_task a<where><if test="headTime != null and headTime != '' and tailTime != null and tailTime != ''">and a.send_time between #{headTime} and #{tailTime}</if><if test="msgTaskTitle != null and msgType != ''">and a.msg_task_title = #{msgTaskTitle}</if><if test="msgType != null and msgType != ''">and a.msg_type = #{msgType}</if></where>ORDER BYa.CREATE_TIME DESCLIMIT ${(current-1)*size},#{size}</select></mapper>...
Service
public interface MsgTaskService extends IService<MsgTask> {public List<MsgTaskConditionResponse> getTaskPage(MsgTaskConditionRequest msgTaskConditionRequest);}/*** @author hasee* @description 针对表【msg_task】的数据库操作Service实现* @createDate 2022-04-18 15:06:27*/@Servicepublic class MsgTaskServiceImpl extends ServiceImpl<MsgTaskMapper, MsgTask>implements MsgTaskService {@AutowiredMsgTaskMapper msgTaskMapper;@Overridepublic List<MsgTaskConditionResponse> getTaskPage(MsgTaskConditionRequest msgTaskConditionRequest) {if (msgTaskConditionRequest.getSize()==null){int defaultSize = 10;msgTaskConditionRequest.setSize(defaultSize);}if (msgTaskConditionRequest.getCurrent()==null){msgTaskConditionRequest.setCurrent(1);}List<MsgTaskConditionMiddle> msgTaskConditionMiddles = msgTaskMapper.getTaskPage(msgTaskConditionRequest);ArrayList<MsgTaskConditionResponse> responses = new ArrayList<>();for (MsgTaskConditionMiddle msgTaskConditionMiddle:msgTaskConditionMiddles) {MsgTaskConditionResponse msgTaskConditionResponse = new MsgTaskConditionResponse();BeanUtil.copyProperties(msgTaskConditionMiddle,msgTaskConditionResponse);msgTaskConditionResponse.setTargetUserCounts(100);}return responses;}}
写XML,SQL语句怎么写?
SQL执行顺序
<select id="getSendDetailPage"resultType="com.iwhalecloud.aiFactory.aiResource.aimessage.middle.MsgTaskSendDetailMiddle">SELECT b.user_code,b.user_name,c.send_time,a.send_state,a.msg_stateFROM msg_log a LEFT JOIN msg_user b ON a.user_id = b.msg_user_idLEFT JOIN msg_task c ON a.msg_task_id = c.msg_task_id<where><if test="sendChannel != null and sendChannel != ''">and a.msg_channel = #{sendChannel}</if><if test="sendStatus != null and sendStatus != ''">and a.send_state = #{sendStatus}</if></where>ORDER BYa.CREATE_TIME DESCLIMIT ${(current-1)*size},#{size}</select>
WHERE过滤条件
等于
<select id="getSendDetailPage"resultType="com.iwhalecloud.aiFactory.aiResource.aimessage.middle.MsgTaskSendDetailMiddle">SELECT b.user_code,b.user_name,c.send_time,a.send_state,a.msg_stateFROM msg_log a LEFT JOIN msg_user b ON a.user_id = b.msg_user_idLEFT JOIN msg_task c ON a.msg_task_id = c.msg_task_id<where><if test="sendChannel != null and sendChannel != ''">and a.msg_channel = #{sendChannel}</if><if test="sendStatus != null and sendStatus != ''">and a.send_state = #{sendStatus}</if></where>ORDER BYa.CREATE_TIME DESCLIMIT ${(current-1)*size},#{size}</select>
between
<select id="getTaskPage"resultType="com.iwhalecloud.aiFactory.aiResource.aimessage.middle.MsgTaskConditionMiddle">SELECT a.msg_task_title,a.send_time,a.msg_type,a.send_channelFROM msg_task a<where><if test="headTime != null and headTime != '' and tailTime != null and tailTime != ''">and a.send_time between #{headTime} and #{tailTime}</if><if test="msgTaskTitle != null and msgType != ''">and a.msg_task_title = #{msgTaskTitle}</if><if test="msgType != null and msgType != ''">and a.msg_type = #{msgType}</if></where>ORDER BYa.CREATE_TIME DESCLIMIT ${(current-1)*size},#{size}</select>
like
<select id="filterAndLikeQuery" parameterType="com.iwhalecloud.aiFactory.aiResource.modelChange.vo.TaiModelChangeQryRequest" resultType="com.iwhalecloud.aiFactory.aiResource.modelChange.dto.TaiModelChange" useCache="false">SELECT * FROM tai_model_change t<where><if test="name != null and name != ''" >and t.name LIKE concat('%',#{name},'%')</if><if test="status != null and status != ''" >and t.status = #{status}</if><if test="modeChangeType != null and modeChangeType != ''">and t.mode_change_type = #{modeChangeType}</if><if test="createStaffId != null">and create_staff_id = #{createStaffId}</if></where>ORDER BYt.CREATE_TIME DESC</select>
GROUP和HAVING
GROUP BY语法可以根据给定数据列的每个成员对查询结果进行分组统计,最终得到一个分组汇总表。
select子句中的列名必须为分组列或列函数,列函数对于group by子句定义的每个组返回一个结果。
某个员工信息表结构和数据如下:
id name dept salary edlevel hiredate1 张三 开发部 2000 3 2009-10-112 李四 开发部 2500 3 2009-10-013 王五 设计部 2600 5 2010-10-024 王六 设计部 2300 4 2010-10-035 马七 设计部 2100 4 2010-10-066 赵八 销售部 3000 5 2010-10-057 钱九 销售部 3100 7 2010-10-078 孙十 销售部 3500 7 2010-10-06
我想列出每个部门最高薪水的结果,sql语句如下:
select dept , max(salary) AS MAXIMUMFROM STAFFGROUP BY DEPT查询结果如下:dept MAXIMUM开发部 4500设计部 2600销售部 3500解释一下这个结果:1、 满足“SELECT子句中的列名必须为分组列或列函数”,因为SELECT有group by中包含的列dept;2、“列函数对于group by子句定义的每个组各返回一个结果”,根据部门分组,对每个部门返回一个结果,就是每个部门的最高薪水。
将where子句与group by子句一起使用
分组查询可以在形成组和计算列函数之前具有消除非限定行的标准where子句。必须在group by子句之前指定where子句
例如,查询公司2010年入职的各个部门每个级别里的最高薪水
SELECT dept,edlevel,MAX(salary) AS MAXIMUMFROM STAFFWHERE hiredate > '2010-01-01'GROUP BY dept,edlevel查询结果如下:dept edlevel MAXIMUM设计部 4 2300设计部 5 2600销售部 5 3000销售部 7 3500
在SELECT语句中指定的每个列名也在GROUP BY子句中提到,未在这两个地方提到的列名将产生错误。
GROUP BY子句要对dept和edlevel的每个唯一组合各返回一行。
GROUP BY子句之后使用Having子句
可应用限定条件进行分组,以便系统仅对满足条件的组返回结果。因此,在GROUP BY子句后面包含了一个HAVING子句。
HAVING类似于WHERE(唯一的差别是WHERE过滤行,HAVING过滤组)HAVING支持所有WHERE操作符。
例如,查找雇员数超过2个的部门的最高和最低薪水:
SELECT dept ,MAX(salary) AS MAXIMUM ,MIN(salary) AS MINIMUMFROM STAFFGROUP BY deptHAVING COUNT(*) > 2ORDER BY dept查询结果如下:dept MAXIMUM MINIMUM设计部 2600 2100销售部 3500 3000
例如,查找雇员平均工资大于3000的部门的最高薪水和最低薪水:
SELECT dept,MAX(salary) AS MAXIMUM,MIN(salary) AS MINIMUMFROM STAFFGROUP BY deptHAVING AVG(salary) > 3000ORDER BY dept查询结果如下:dept MAXIMUM MINIMUM销售部 3500 3000
写XML,SQL标签怎么写?
if-test
<select id="getSendDetailPage"resultType="com.iwhalecloud.aiFactory.aiResource.aimessage.middle.MsgTaskSendDetailMiddle">SELECT b.user_code,b.user_name,c.send_time,a.send_state,a.msg_stateFROM msg_log a LEFT JOIN msg_user b ON a.user_id = b.msg_user_idLEFT JOIN msg_task c ON a.msg_task_id = c.msg_task_id<where><if test="sendChannel != null and sendChannel != ''">and a.msg_channel = #{sendChannel}</if><if test="sendStatus != null and sendStatus != ''">and a.send_state = #{sendStatus}</if></where>ORDER BYa.CREATE_TIME DESCLIMIT ${(current-1)*size},#{size}</select>
choose (when, otherwise)标签
有时候我们并不想应用所有的条件,而只是想从多个选项中选择一个。而使用if标签时,只要test中的表达式为 true,就会执行 if 标签中的条件。MyBatis 提供了 choose 元素。if标签是与(and)的关系,而 choose 是或(or)的关系。<br /> choose标签是按顺序判断其内部when标签中的test条件出否成立,如果有一个成立,则 choose 结束。当 choose 中所有 when 的条件都不满则时,则执行 otherwise 中的sql。类似于Java 的 switch 语句,choose 为 switch,when 为 case,otherwise 则为 default。<br /> 例如下面例子,同样把所有可以限制的条件都写上,方面使用。choose会从上到下选择一个when标签的test为true的sql执行。安全考虑,我们使用where将choose包起来,防止关键字多余错误。
<!-- choose(判断参数) - 按顺序将实体类 User 第一个不为空的属性作为:where条件 --><select id="getUserList_choose" resultMap="resultMap_user" parameterType="com.yiibai.pojo.User">SELECT *FROM User u<where><choose><when test="username !=null ">u.username LIKE CONCAT(CONCAT('%', #{username, jdbcType=VARCHAR}),'%')</when ><when test="sex != null and sex != '' ">AND u.sex = #{sex, jdbcType=INTEGER}</when ><when test="birthday != null ">AND u.birthday = #{birthday, jdbcType=DATE}</when ><otherwise></otherwise></choose></where></select>
foreach模板
你可以将任何可迭代对象(如 List、Set 等)、Map 对象或者数组对象作为集合参数传递给 foreach。
- 当使用可迭代对象或者数组时,index 是当前迭代的序号,item 的值是本次迭代获取到的元素。
- 当使用 Map 对象(或者 Map.Entry 对象的集合)时,index 是键,item 是值。
separator=” , “—in
属性separator 为逗号,前段传过来的myList 参数是list集合
<if test="myList != null">AND dm in<foreach collection="myList " item="item" open="(" separator="," close=")">#{item , jdbcType=VARCHAR }</foreach></if>最后渲染为sql语句为AND dm in ( '03' , '04')
separator=” OR “
属性separator 为or,前端传过来的myList 参数是list集合
<if test="myList != null">AND<foreach collection="myList " index="index" item="item" open="(" separator="or" close=")">dm = #{item , jdbcType=VARCHAR }</foreach></if>最后渲染为sql语句为AND ( dm = '01'or dm = '02' or dm = '03')
【Mybatis连接查询】
一直对association和collection有点混淆,现整理一篇文章,用于加强记忆。
现在有2个表book表、bookshelf书架表。
| BOOK | ||
|---|---|---|
| 字段名称 | 类型 | 备注 |
| id | int | 主键 |
| name | varchar | 书名 |
| type | int | 类型 |
| shelf_id | int | 书架id |
| Book_shelf | ||
|---|---|---|
| 字段名称 | 类型 | 备注 |
| id | int | 主键 |
| number | varchar | 书架编号 |
| num | int | 可存放数量 |
association【嵌套对象】
association用于一对一、多对一场景使用。
现有需求:查询根据书籍id查询书籍信息和所在书架编号。
Book.PoJo
public class Book{private Integer id;private String name;private String type;private Integer shelfId;private BookShelf bookShelfDto;}
BookShelf.Pojo
public class BookShelf {private Integer id;private String number;private String num;}
mapper:type=”com.abc.Book”Bo
<resultMap id="bookResultMap" type="com.abc.Book"><id property="id" column="id"/><result property="name" column="name"/><result property="type" column="type"/><!--关联属性--><association property="bookShelfDto" ofType="com.abc.BookShelf"><id property="id" column="shelf_id"/><result property="number" column="number"/><result property="num" column="num"/></association></resultMap><select id="getBookInfo" resultMap="bookResultMap">select book.id,book.name,book.type,book.shelf_id,shelf.number,shelf.numfrom book left join book_shelf shelf on book.shelf_id = shelf.idwhere book.id = #{id}</select>
collection【嵌套集合】
应用场景为一对多关系,即实体里放集合。
表不变
现有需求:根据书架ID查询书架信息及书架存放的书籍信息。
Book.POJO
public class Book{private Integer id;private String name;private String type;private Integer shelfId;}
BookShelf.Pojo
public class BookShelf {private Integer id;private String number;private String num;private List<Book> bookList;}
mapper
<resultMap id="bookShelfResultMap" type="com.abc.BookShelf"><id property="id" column="shelf_id"/><result property="number" column="number"/><result property="num" column="num"/><!--关联属性--><collection property="bookList" javaType="com.abc.Book"><id property="id" column="id"/><result property="name" column="name"/><result property="type" column="type"/></collection></resultMap><select id="getBookShelfInfo" resultMap="bookShelfResultMap">select book.id,book.name,book.type,book.shelf_id,shelf.number,shelf.numfrom book left join book_shelf shelf on book.shelf_id = shelf.idwhere shelf.id = #{id}</select>Mapper.javaBookShelf getBookShelfInfo(Integer id);
排列组合【无嵌套连接】
任务场景:1条任务发送给N个用户,并且保存消息日志。但是1条任务当中有M种消息内容
- A表一条数据有m种内容字段
- A表与B表是常规的1对多关系
- C表的最终消息日志入库:由于是排列组合,所以最终的入库结果就是mn条记录。*第三张表是用来算乘积结果的
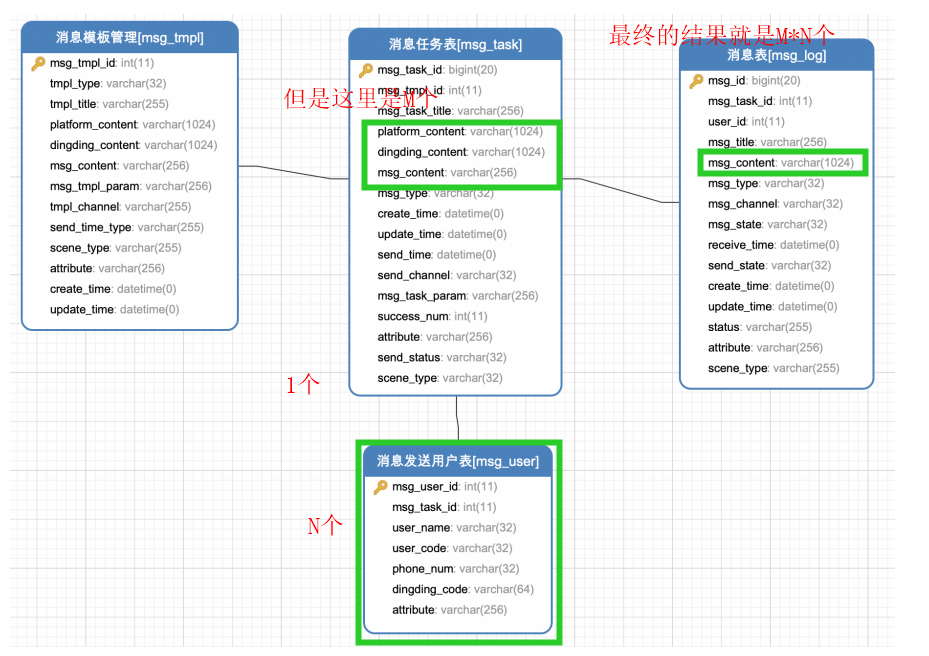
数据库建表
--A表CREATE TABLE `msg_task` (`msg_task_id` bigint(20) NOT NULL AUTO_INCREMENT COMMENT '消息任务id',`msg_tmpl_id` int(11) DEFAULT NULL COMMENT '消息模板 id',`msg_task_title` varchar(256) DEFAULT NULL COMMENT '消息任务标题',`platform_content` varchar(1024) DEFAULT NULL COMMENT '平台消息任务内容模板',`dingding_content` varchar(1024) DEFAULT NULL COMMENT '钉钉消息模板内容',`msg_content` varchar(256) DEFAULT NULL COMMENT '短息内容',`msg_type` varchar(32) DEFAULT NULL COMMENT '消息类型,数据字典维护: 平台=platform,企业=ent',`create_time` datetime DEFAULT NULL COMMENT '创建时间',`update_time` datetime DEFAULT NULL COMMENT '修改时间',`send_time` datetime DEFAULT NULL COMMENT '发送时间',`send_channel` varchar(32) DEFAULT NULL COMMENT '发送渠道,多个用逗号分隔.数据字典维护:平台=platform_channel,钉钉=dingding_channel,短信=msg_channel',`msg_task_param` varchar(256) DEFAULT NULL COMMENT '消息参数,json 存储',`success_num` int(11) DEFAULT NULL COMMENT '失败数量',`attribute` varchar(256) DEFAULT NULL COMMENT '扩展字段',`send_status` varchar(32) DEFAULT NULL COMMENT '发送状态,已发送=1,未发送=0',`scene_type` varchar(32) DEFAULT NULL COMMENT '场景类型,具体场景和环节使用对应的类型前缀,用点拼接.系统=sys,安全=security,审核=audit;',`send_user_id` bigint(20) DEFAULT NULL COMMENT '发送人ID',`send_user_name` varchar(20) DEFAULT NULL COMMENT '发送人名称',PRIMARY KEY (`msg_task_id`)) ENGINE=InnoDB AUTO_INCREMENT=121 DEFAULT CHARSET=utf8;--B表:CREATE TABLE `msg_user` (`msg_user_id` int(11) NOT NULL AUTO_INCREMENT COMMENT '消息发送用户 id',`msg_task_id` int(11) DEFAULT NULL COMMENT '消息任务 id',`user_name` varchar(32) DEFAULT NULL COMMENT '用户名称',`user_code` varchar(32) DEFAULT NULL COMMENT '用户编码',`phone_num` varchar(32) DEFAULT NULL COMMENT '用户电话',`dingding_code` varchar(64) DEFAULT NULL COMMENT '钉钉账号',`attribute` varchar(256) DEFAULT NULL COMMENT '扩展属性',PRIMARY KEY (`msg_user_id`)) ENGINE=InnoDB AUTO_INCREMENT=173 DEFAULT CHARSET=utf8;--C表CREATE TABLE `msg_log` (`msg_id` bigint(20) NOT NULL AUTO_INCREMENT COMMENT '消息id',`msg_task_id` bigint(20) NOT NULL COMMENT '消息任务id',`user_id` int(11) DEFAULT NULL COMMENT '接收人 id',`msg_title` varchar(256) DEFAULT NULL COMMENT '消息标题',`msg_content` varchar(1024) DEFAULT NULL COMMENT '消息内容',`msg_type` varchar(32) DEFAULT NULL COMMENT '消息类型, 数据字典维护:平台=platform,企业=ent',`msg_channel` varchar(32) DEFAULT NULL COMMENT '发送渠道,数据字典维护:平台=platform_channel,钉钉=dingding_channel,短信=msg_channel',`msg_state` varchar(32) DEFAULT NULL COMMENT '消息状态,数据字典维护:read = 已读, unread =未读',`receive_time` datetime DEFAULT NULL COMMENT '接收时间',`send_state` varchar(32) DEFAULT NULL COMMENT '发送状态,数据字典维护:success=成功,fail=失败',`create_time` datetime DEFAULT NULL COMMENT '创建时间',`update_time` datetime DEFAULT NULL COMMENT '修改时间',`status` varchar(255) DEFAULT NULL COMMENT '删除状态,有效 = 00A,失效 = 00X',`attribute` varchar(256) DEFAULT NULL COMMENT '扩展属性',`scene_type` varchar(255) DEFAULT NULL COMMENT '场景类型,具体场景和环节使用对应的类型前缀,用点拼接.系统=sys,安全=security,审核=audit.xxx.xxxx;',PRIMARY KEY (`msg_id`)) ENGINE=InnoDB AUTO_INCREMENT=172 DEFAULT CHARSET=utf8;
数据结构定义:无嵌套数据结构
package com.iwhalecloud.aiFactory.aiResource.aimessage.bo;import com.iwhalecloud.aiFactory.aiResource.aimessage.dto.MsgLog;import lombok.Data;import java.io.Serializable;import java.util.Date;@Datapublic class MsgTaskSendDetailBo extends MsgLog implements Serializable {//userString userCode;String userName;//taskDate sendTime;//logString sendState;String msgState;}
SQL:无嵌套连接
<select id="getSendDetailPage"resultType="com.iwhalecloud.aiFactory.aiResource.aimessage.bo.MsgTaskSendDetailBo">SELECT b.user_code,b.user_name,c.send_time,a.send_state,a.msg_state,a.attributeFROM msg_log a LEFT JOIN msg_user b ON a.user_id = b.msg_user_idLEFT JOIN msg_task c ON a.msg_task_id = c.msg_task_id<where><if test="msgTaskId != null and msgTaskId != ''">and c.msg_task_id = #{msgTaskId}</if><if test="sendChannel != null and sendChannel != ''">and a.msg_channel = #{sendChannel}</if><if test="sendStatus != null and sendStatus != ''">and a.send_state = #{sendStatus}</if>and a.status = "00A"</where>ORDER BYa.CREATE_TIME DESC</select>
传入列表实现批量查询
item内单条件查询
我知道如何只有一个入参的list,可以使用类似下面的语句实现
public List<XXXBean> getXXXBeanList(List<String> list);
xml
<select id="getXXXBeanList" resultType="XXBean">select 字段... from XXX where id in<foreach item="item" index="index" collection="list"open="(" separator="," close=")">#{item}</foreach></select>
item内多条件查询
但是传入多个条件的list, 在mybatis中的xml怎么写?麻烦指导下。
问题描述:比如有一张用户表,有以下字段:
id:主键
userName:用户名
userAge:用户年龄
userAddress:用户住址
我想根据id和userName两个条件构造出一个list入参,实现批量查询
SQL:
select * from user where (user_id,type) in ((568,6),(569,6),(600,8));
MyBatis XML:
select date_format(create_Time,'%Y-%m-%d %H:%i:%s') as createTime ,reason,operator,remarks,operationfrom refund_order_logwhere (order_no,channel) in<foreach collection="list" item="item" open="(" close=")" separator=",">(#{item.orderNo},#{item.channel})</foreach>and status =1order by create_time desc
连接查询出规格参数【自定义映射规则】
查询结果自定义封装
@Data@ToStringpublic class SpuItemAttrGroupVo {private String groupName;private List<Attr> attrs;}
查询语句
List<SpuItemAttrGroupVo> getAttrGroupWithAttrsBySpuId(@Param("spuId") Long spuId, @Param("catalogId") Long catalogId);
根据业务条件正确的查询出满足要求的结果,然后取出想要的resultMap返回
<resultMap id="spuAttrGroup" type="com.xunqi.gulimall.product.vo.SpuItemAttrGroupVo"><result property="groupName" column="attr_group_name"/><collection property="attrs" ofType="com.xunqi.gulimall.product.vo.Attr"><result property="attrId" column="attr_id"></result><result property="attrName" column="attr_name"></result><result property="attrValue" column="attr_value"></result></collection></resultMap><select id="getAttrGroupWithAttrsBySpuId" resultMap="spuAttrGroup">SELECTproduct.spu_id,pag.attr_group_id,pag.attr_group_name,product.attr_id,product.attr_name,product.attr_valueFROMpms_product_attr_value productLEFT JOIN pms_attr_attrgroup_relation paar ON product.attr_id = paar.attr_idLEFT JOIN pms_attr_group pag ON paar.attr_group_id = pag.attr_group_idWHEREproduct.spu_id = #{spuId}AND pag.catelog_id = #{catalogId}</select>
连接查询当前spu对应的skus【分组技巧】
未写分组之前
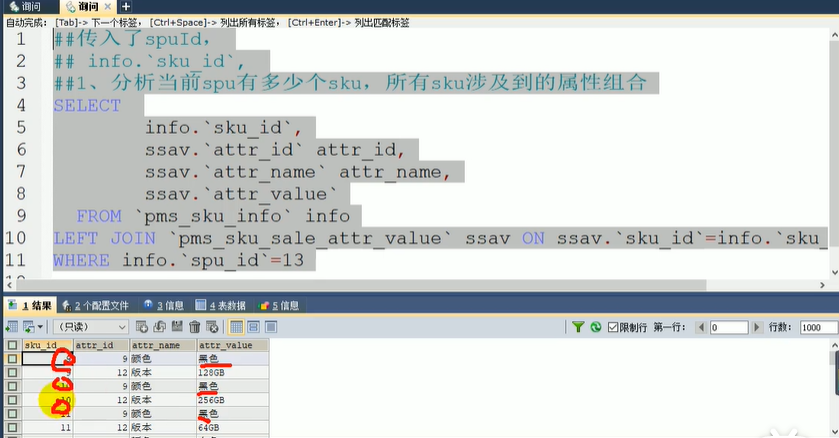
写上分组
查询结果自定义封装
<resultMap id="skuItemSaleAttrVo" type="com.xunqi.gulimall.product.vo.SkuItemSaleAttrVo"><result column="attr_id" property="attrId"></result><result column="attr_name" property="attrName"></result><collection property="attrValues" ofType="com.xunqi.gulimall.product.vo.AttrValueWithSkuIdVo"><result column="attr_value" property="attrValue"></result><result column="sku_ids" property="skuIds"></result></collection></resultMap>
SkuItemSaleAttrVo
@Data@ToStringpublic class SkuItemSaleAttrVo {private Long attrId;private String attrName;private List<AttrValueWithSkuIdVo> attrValues;}
AttrValueWithSkuIdVo
@Datapublic class AttrValueWithSkuIdVo {private String attrValue;private String skuIds;}
查询语句
List<SkuItemSaleAttrVo> getSaleAttrBySpuId(@Param("spuId") Long spuId);
<resultMap id="skuItemSaleAttrVo" type="com.xunqi.gulimall.product.vo.SkuItemSaleAttrVo"><result column="attr_id" property="attrId"></result><result column="attr_name" property="attrName"></result><collection property="attrValues" ofType="com.xunqi.gulimall.product.vo.AttrValueWithSkuIdVo"><result column="attr_value" property="attrValue"></result><result column="sku_ids" property="skuIds"></result></collection></resultMap><select id="getSaleAttrBySpuId" resultMap="skuItemSaleAttrVo">SELECTssav.attr_id attr_id,ssav.attr_name attr_name,ssav.attr_value,group_concat( DISTINCT info.sku_id ) sku_idsFROMpms_sku_info infoLEFT JOIN pms_sku_sale_attr_value ssav ON ssav.sku_id = info.sku_idWHEREinfo.spu_id = #{spuId}GROUP BYssav.attr_id,ssav.attr_name,ssav.attr_value</select>
GROUP BY:mysql规定select里的字段必须存在分组下面写出 ssav.attr_id attr_id,ssav.attr_name attr_name,ssav.attr_value,
未写出的也想要拿到怎么办?group_concat:为返回的select字段新增一个函数处理
SQL语法的规定,用了group by,则select之后的字段除聚合函数外都必须出现在group by中, 你可以少于group by中的字段,但不能包含group by中没有的字段
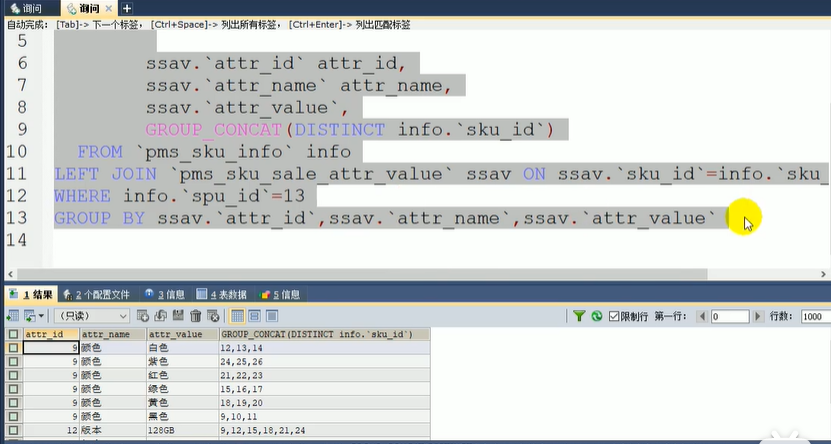
方便sku切换:查询结果中任选一个颜色对应的skuids和内存对应的skuids
将两个ids集合求交集,就能够确定出唯一的一个sku进行切换
yml
spring:datasource:resource:type: jdbcdriver-class-name: com.mysql.jdbc.Driverurl: jdbc:mysql://172.21.72.163:3306/ai_factory_resource_test?useUnicode=true&characterEncoding=utf-8&useSSL=false&serverTimezone=Asia/Shanghai&allowMultiQueries=trueusername: ai_platform_testpassword: ai_platform_testinitial-size: 5max-active: 30min-idle: 5max-wait: 60000validation-query: SELECT 1validationQueryTimeout: 5encrypt: falsetest-on-borrow: falsetest-while-idle: truemybatis-plus:resource:global-config:db-column-underline: trueconfiguration:map-underscore-to-camel-case: truecache-enabled: falsedatabase-id: mysqlmapper-locations: classpath*:mapper/**/*Mapper.xmltype-aliases-package: com.iwhalecloud.aiFactory.aiResource.*.dto
常用注解
@TableName
- 描述:表名注解 | 属性 | 类型 | 必须指定 | 默认值 | 描述 | | —- | —- | —- | —- | —- | | value | String | 否 | “” | 表名 | | schema | String | 否 | “” | schema | | keepGlobalPrefix | boolean | 否 | false | 是否保持使用全局的 tablePrefix 的值(如果设置了全局 tablePrefix 且自行设置了 value 的值) | | resultMap | String | 否 | “” | xml 中 resultMap 的 id | | autoResultMap | boolean | 否 | false | 是否自动构建 resultMap 并使用(如果设置 resultMap 则不会进行 resultMap 的自动构建并注入) | | excludeProperty | String[] | 否 | {} | 需要排除的属性名(@since 3.3.1) |
关于autoResultMap的说明:
mp会自动构建一个ResultMap并注入到mybatis里(一般用不上).
下面讲两句: 因为mp底层是mybatis,所以一些mybatis的常识你要知道,mp只是帮你注入了常用crud到mybatis里 注入之前可以说是动态的(根据你entity的字段以及注解变化而变化),但是注入之后是静态的(等于你写在xml的东西) 而对于直接指定typeHandler,mybatis只支持你写在2个地方:
- 定义在resultMap里,只作用于select查询的返回结果封装
- 定义在
insert和updatesql的#{property}里的property后面(例:#{property,typehandler=xxx.xxx.xxx}),只作用于设置值而除了这两种直接指定typeHandler,mybatis有一个全局的扫描你自己的typeHandler包的配置,这是根据你的property的类型去找typeHandler并使用.
@TableId
mybatis_plus 默认会使用 “id” 为主键字段,若你的主键不叫id,则需加上@TableId(value =“数据库你的主键字段”)注解即可
value:指定数据表主键字段名type:指定数据表主键类型,如:ID自增、UUID等。该属性的值是一个 IdType 枚举类型,默认为 IdType.NONE。
IdType:
| 值 | 描述 |
|---|---|
| AUTO | 数据库ID自增 |
| NONE | 无状态,该类型为未设置主键类型(注解里等于跟随全局,全局里约等于 INPUT) |
| INPUT | insert前自行set主键值 |
| ASSIGN_ID | 分配ID(主键类型为Number(Long和Integer)或String)(since 3.3.0),使用接口IdentifierGenerator的方法 nextId(默认实现类为 DefaultIdentifierGenerator雪花算法) |
| ASSIGN_UUID | 分配UUID,主键类型为String(since 3.3.0),使用接口IdentifierGenerator的方法 nextUUID(默认default方法) |
分布式全局唯一ID 长整型类型(please use ASSIGN_ID) |
|
32位UUID字符串(please use ASSIGN_UUID) |
|
分布式全局唯一ID 字符串类型(please use ASSIGN_ID) |
数据库设置自增
注意:如果使用@TableId(value = “id”, type = IdType.AUTO),
数据库表主键字段一定不要忘记设置自增:
当我用SQLyog尝试修改已有记录的mysql数据表的主键为自动增长时,报出以下错误
ALTER TABLE causes auto_increment resequencing, resulting in duplicate entry ’1′ for key ‘PRIMARY’
解决方法:
第1步:将主键字段值为0的那条记录值改为其他大于0且不重复的任意数
第2步:修改主键字段为auto_increment
第3步:把刚才修改过的那条记录的值还原
数据库主键名称
项目:Springboot mybatis-plus mysql
今天项目中新建了一张表,表的主键是area_code,在程序中直接使用mybatis-plus内置的selectById方法进行表数据查询,查询时直接报错: 运行时异常
: Invalid bound statement (not found): com.huanong.avatar.shuidi.mapper.SdWeatherThresholdMapper.selectById
原因
mybatis的selectById方法默认使用的主键名是id,而数据库中表的id是area_code,所以查询时会报错
解决
使用注解的方式,更改mybatis的selectById方法查询主键的名称即可,不多说,直接上代码
@TableId(“area_code”)
private String areaCode;
注:@TableId里面的字段需要同数据库的字段保持一致,不能同程序一致,
比如数据库的表字段area_code,程序是areaCode,注解中则需要写area_code,不然执行sql还会报错
org.springframework.jdbc.BadSqlGrammarException:### Error querying database. Cause: com.mysql.jdbc.exceptions.jdbc4.MySQLSyntaxErrorException: Unknown column 'areacode' in 'field list'
@TableField
Mybatis plus 中数据库中字段有SQL关键字的处理方法
在实体类关键字字段的位置使用注解:
@TableField(“‘关键字字段名’”)
@TableField("'number'")private String number;
描述:字段注解(非主键)
| 属性 | 类型 | 必须指定 | 默认值 | 描述 |
|---|---|---|---|---|
| value | String | 否 | “” | 数据库字段名 |
| el | String | 否 | “” | 映射为原生 #{ ... }逻辑,相当于写在 xml 里的 #{ ... }部分 |
| exist | boolean | 否 | true | 是否为数据库表字段 |
| condition | String | 否 | “” | 字段 where实体查询比较条件,有值设置则按设置的值为准,没有则为默认全局的 %s=#{%s},参考(opens new window) |
| update | String | 否 | “” | 字段 update set部分注入, 例如:update=”%s+1”:表示更新时会set version=version+1(该属性优先级高于 el属性) |
| insertStrategy | Enum | N | DEFAULT | 举例:NOT_NULL: insert into table_a(<if test="columnProperty != null">column</if>) values (<if test="columnProperty != null">#{columnProperty}</if>) |
| updateStrategy | Enum | N | DEFAULT | 举例:IGNORED: update table_a set column=#{columnProperty} |
| whereStrategy | Enum | N | DEFAULT | 举例:NOT_EMPTY: where <if test="columnProperty != null and columnProperty!=''">column=#{columnProperty}</if> |
| fill | Enum | 否 | FieldFill.DEFAULT | 字段自动填充策略 |
| select | boolean | 否 | true | 是否进行 select 查询 |
| keepGlobalFormat | boolean | 否 | false | 是否保持使用全局的 format 进行处理 |
| jdbcType | JdbcType | 否 | JdbcType.UNDEFINED | JDBC类型 (该默认值不代表会按照该值生效) |
| typeHandler | Class<? extends TypeHandler> | 否 | UnknownTypeHandler.class | 类型处理器 (该默认值不代表会按照该值生效) |
| numericScale | String | 否 | “” | 指定小数点后保留的位数 |
bean当中添加数据库当中不存在的字段名
其中@JsonInclude(JsonInclude.Include.NON_EMPTY)表示,如果返回值当中该字段为空,则不显示该字段
@JsonInclude(JsonInclude.Include.NON_EMPTY)@TableField(exist=false)private List<CategoryEntity> children;
关于jdbcType和typeHandler以及numericScale的说明:numericScale只生效于 update 的sql. jdbcType和typeHandler如果不配合@TableName#autoResultMap = true一起使用,也只生效于 update 的sql. 对于typeHandler如果你的字段类型和set进去的类型为equals关系,则只需要让你的typeHandler让Mybatis加载到即可,不需要使用注解
FieldStrategy
| 值 | 描述 |
|---|---|
| IGNORED | 忽略判断 |
| NOT_NULL | 非NULL判断 |
| NOT_EMPTY | 非空判断(只对字符串类型字段,其他类型字段依然为非NULL判断) |
| DEFAULT | 追随全局配置 |
FieldFill
| 值 | 描述 |
|---|---|
| DEFAULT | 默认不处理 |
| INSERT | 插入时填充字段 |
| UPDATE | 更新时填充字段 |
| INSERT_UPDATE | 插入和更新时填充字段 |
@Version
-
@EnumValue
@TableLogic
描述:表字段逻辑处理注解(逻辑删除) | 属性 | 类型 | 必须指定 | 默认值 | 描述 | | —- | —- | —- | —- | —- | | value | String | 否 | “” | 逻辑未删除值 | | delval | String | 否 | “” | 逻辑删除值 |
@KeySequence
- 描述:序列主键策略
oracle - 属性:value、resultMap | 属性 | 类型 | 必须指定 | 默认值 | 描述 | | —- | —- | —- | —- | —- | | value | String | 否 | “” | 序列名 | | clazz | Class | 否 | Long.class | id的类型, 可以指定String.class,这样返回的Sequence值是字符串”1” |
@OrderBy
- 描述:内置 SQL 默认指定排序,优先级低于 wrapper 条件查询 | 属性 | 类型 | 必须指定 | 默认值 | 描述 | | —- | —- | —- | —- | —- | | isDesc | boolean | 否 | 是 | 是否倒序查询 | | sort | short | 否 | Short.MAX_VALUE | 数字越小越靠前 |
代码规范
Mapper上加@Repository注解,不然autowired报错

若有收获,就点个赞吧
0 人点赞
