RabbitMQ 是采用 Erlang 语言实现 AMQP(Advanced Message Queuing Protocol,高级消息队列协议)的消息中间件,它最初起源于金融系统,用于在分布式系统中存储转发消息。
RabbitMQ 发展到今天,被越来越多的人认可,这和它在易用性、扩展性、可靠性和高可用性等方面的卓著表现是分不开的。RabbitMQ 的具体特点可以概括为以下几点:
- 可靠性: RabbitMQ使用一些机制来保证消息的可靠性,如持久化、传输确认及发布确认等。
- 灵活的路由: 在消息进入队列之前,通过交换器来路由消息。对于典型的路由功能,RabbitMQ 己经提供了一些内置的交换器来实现。针对更复杂的路由功能,可以将多个交换器绑定在一起,也可以通过插件机制来实现自己的交换器。这个后面会在我们讲 RabbitMQ 核心概念的时候详细介绍到。
- 扩展性: 多个RabbitMQ节点可以组成一个集群,也可以根据实际业务情况动态地扩展集群中节点。
- 高可用性: 队列可以在集群中的机器上设置镜像,使得在部分节点出现问题的情况下队列仍然可用。
- 支持多种协议: RabbitMQ 除了原生支持 AMQP 协议,还支持 STOMP、MQTT 等多种消息中间件协议。
- 多语言客户端: RabbitMQ几乎支持所有常用语言,比如 Java、Python、Ruby、PHP、C#、JavaScript等。
- 易用的管理界面: RabbitMQ提供了一个易用的用户界面,使得用户可以监控和管理消息、集群中的节点等。在安装 RabbitMQ 的时候会介绍到,安装好 RabbitMQ 就自带管理界面。
- 插件机制: RabbitMQ 提供了许多插件,以实现从多方面进行扩展,当然也可以编写自己的插件。感觉这个有点类似 Dubbo 的 SPI机制。
几种常见MQ的对比:
| RabbitMQ | ActiveMQ | RocketMQ | Kafka | |
|---|---|---|---|---|
| 公司/社区 | Rabbit | Apache | 阿里 | Apache |
| 开发语言 | Erlang | Java | Java | Scala&Java |
| 协议支持 | AMQP,XMPP,SMTP,STOMP | OpenWire,STOMP,REST,XMPP,AMQP | 自定义协议 | 自定义协议 |
| 可用性 | 高 | 一般 | 高 | 高 |
| 单机吞吐量 | 一般 | 差 | 高 | 非常高 |
| 消息延迟 | 微秒级 | 毫秒级 | 毫秒级 | 毫秒以内 |
| 消息可靠性 | 高 | 一般 | 高 | 一般 |
追求可用性:Kafka、 RocketMQ 、RabbitMQ
追求可靠性:RabbitMQ、RocketMQ
追求吞吐能力:RocketMQ、Kafka
追求消息低延迟:RabbitMQ、Kafka
基于注解的Rabbit MQ使用
- 一般基于SpringAMQP操作RabbitMQ
- SpringAMQP是基于RabbitMQ封装的一套模板,并且还利用SpringBoot对其实现了自动装配,使用起来非常方便。
- 引入AMQP依赖,配置RabbitMQ的主机名、IP、端口号等信息(发送方和接收方都要配置)
- 发送方获取RabbitTemplate,转换并发送消息
- 获取方创建一个消息队列,并注入到容器中
- 获取方创建一个Listener,其内部的方法通过
@RabbitListener注解绑定响应的消息队列并接收消息
Rabbit MQ组件
RabbitMQ 整体上是一个生产者与消费者模型,主要负责接收、存储和转发消息。可以把消息传递的过程想象成:当你将一个包裹送到邮局,邮局会暂存并最终将邮件通过邮递员送到收件人的手上,RabbitMQ就好比由邮局、邮箱和邮递员组成的一个系统。从计算机术语层面来说,RabbitMQ 模型更像是一种交换机模型。
下面再来看看图1—— RabbitMQ 的整体模型架构。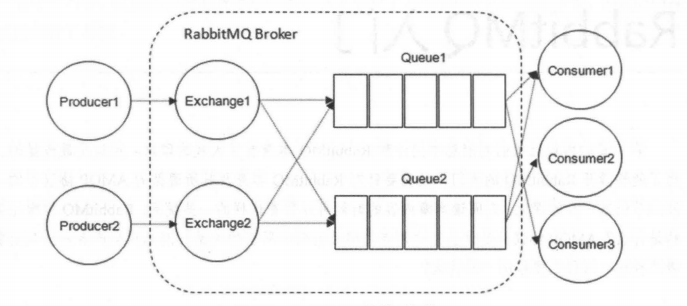
Producer(生产者) 和 Consumer(消费者)
- Producer(生产者) :生产消息的一方(邮件投递者)
- Consumer(消费者) :消费消息的一方(邮件收件人)
消息一般由 2 部分组成:消息头(或者说是标签 Label)和 消息体。消息体也可以称为 payLoad ,消息体是不透明的,而消息头则由一系列的可选属性组成,这些属性包括 routing-key(路由键)、priority(相对于其他消息的优先权)、delivery-mode(指出该消息可能需要持久性存储)等。生产者把消息交由 RabbitMQ 后,RabbitMQ 会根据消息头把消息发送给感兴趣的 Consumer(消费者)。
Exchange(交换器)
在 RabbitMQ 中,消息并不是直接被投递到 Queue(消息队列) 中的,中间还必须经过 Exchange(交换器) 这一层,Exchange(交换器) 会把我们的消息分配到对应的 Queue(消息队列) 中。
Exchange(交换器) 用来接收生产者发送的消息并将这些消息路由给服务器中的队列中,如果路由不到,或许会返回给 Producer(生产者) ,或许会被直接丢弃掉 。这里可以将RabbitMQ中的交换器看作一个简单的实体。
RabbitMQ 的 Exchange(交换器) 有4种类型,不同的类型对应着不同的路由策略:direct(默认),fanout, topic, 和 headers,不同类型的Exchange转发消息的策略有所区别。这个会在介绍 Exchange Types(交换器类型) 的时候介绍到。
Exchange(交换器) 示意图如下: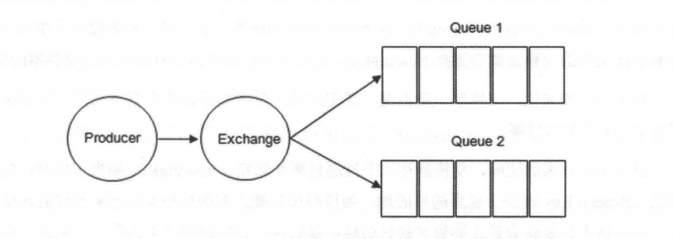
生产者将消息发给交换器的时候,一般会指定一个 RoutingKey(路由键),用来指定这个消息的路由规则,而这个 RoutingKey 需要与交换器类型和绑定键(BindingKey)联合使用才能最终生效。
RabbitMQ 中通过 Binding(绑定) 将 Exchange(交换器) 与 Queue(消息队列) 关联起来,在绑定的时候一般会指定一个 BindingKey(绑定建) ,这样 RabbitMQ 就知道如何正确将消息路由到队列了,如下图所示。一个绑定就是基于路由键将交换器和消息队列连接起来的路由规则,所以可以将交换器理解成一个由绑定构成的路由表。Exchange 和 Queue 的绑定可以是多对多的关系。
Binding(绑定) 示意图: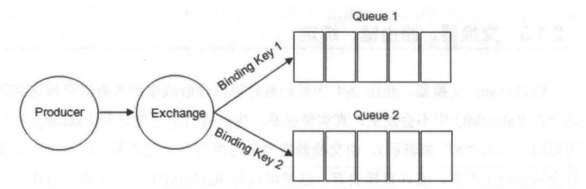
生产者将消息发送给交换器时,需要一个RoutingKey,当 BindingKey 和 RoutingKey 相匹配时,消息会被路由到对应的队列中。在绑定多个队列到同一个交换器的时候,这些绑定允许使用相同的 BindingKey。BindingKey 并不是在所有的情况下都生效,它依赖于交换器类型,比如fanout类型的交换器就会无视,而是将消息路由到所有绑定到该交换器的队列中。
Queue(消息队列)
Queue(消息队列) 用来保存消息直到发送给消费者。它是消息的容器,也是消息的终点。一个消息可投入一个或多个队列。消息一直在队列里面,等待消费者连接到这个队列将其取走。
RabbitMQ 中消息只能存储在队列中,这一点和 Kafka 这种消息中间件相反。Kafka 将消息存储在 topic(主题) 这个逻辑层面,而相对应的队列逻辑只是topic实际存储文件中的位移标识。 RabbitMQ 的生产者生产消息并最终投递到队列中,消费者可以从队列中获取消息并消费。
多个消费者可以订阅同一个队列,这时队列中的消息会被平均分摊(Round-Robin,即轮询)给多个消费者进行处理,而不是每个消费者都收到所有的消息并处理,这样避免消息被重复消费。
RabbitMQ 不支持队列层面的广播消费,如果有广播消费的需求,需要在其上进行二次开发,这样会很麻烦,不建议这样做。
Broker(消息中间件的服务节点)
对于 RabbitMQ 来说,一个 RabbitMQ Broker 可以简单地看作一个 RabbitMQ 服务节点,或者RabbitMQ服务实例。大多数情况下也可以将一个 RabbitMQ Broker 看作一台 RabbitMQ 服务器。
下图展示了生产者将消息存入 RabbitMQ Broker,以及消费者从Broker中消费数据的整个流程。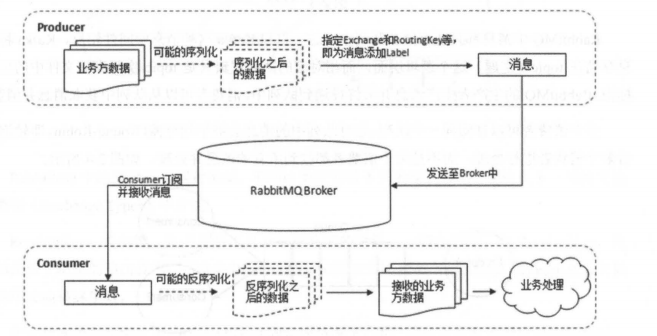
这样图1中的一些关于 RabbitMQ 的基本概念我们就介绍完毕了,下面再来介绍一下 Exchange Types(交换器类型) 。
Exchange Types(交换器类型)
RabbitMQ 常用的 Exchange Type 有 fanout、direct、topic、headers 这四种(AMQP规范里还提到两种 Exchange Type,分别为 system 与 自定义,这里不予以描述)。
① fanout
fanout 类型的Exchange路由规则非常简单,它会把所有发送到该Exchange的消息路由到所有与它绑定的Queue中,不需要做任何判断操作,所以 fanout 类型是所有的交换机类型里面速度最快的。fanout 类型常用来广播消息。
② direct
direct 类型的Exchange路由规则也很简单,它会把消息路由到那些 Bindingkey 与 RoutingKey 完全匹配的 Queue 中。 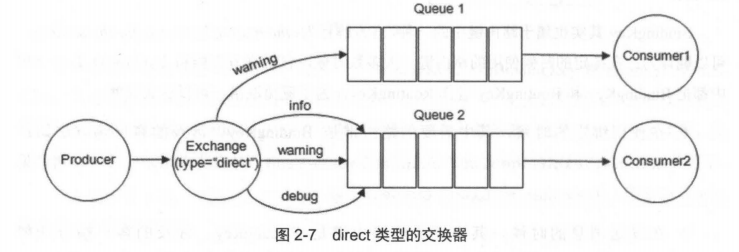
以上图为例,如果发送消息的时候设置路由键为“warning”,那么消息会路由到 Queue1 和 Queue2。如果在发送消息的时候设置路由键为”Info”或者”debug”,消息只会路由到Queue2。如果以其他的路由键发送消息,则消息不会路由到这两个队列中。
direct 类型常用在处理有优先级的任务,根据任务的优先级把消息发送到对应的队列,这样可以指派更多的资源去处理高优先级的队列。
③ topic
前面讲到direct类型的交换器路由规则是完全匹配 BindingKey 和 RoutingKey ,但是这种严格的匹配方式在很多情况下不能满足实际业务的需求。topic类型的交换器在匹配规则上进行了扩展,它与 direct 类型的交换器相似,也是将消息路由到 BindingKey 和 RoutingKey 相匹配的队列中,但这里的匹配规则有些不同,它约定:
- RoutingKey 为一个点号“.”分隔的字符串(被点号“.”分隔开的每一段独立的字符串称为一个单词),如 “com.rabbitmq.client”、“java.util.concurrent”、“com.hidden.client”;
- BindingKey 和 RoutingKey 一样也是点号“.”分隔的字符串;
- BindingKey 中可以存在两种特殊字符串“”和“#”,用于做模糊匹配,其中“”用于匹配一个单词,“#”用于匹配多个单词(可以是零个)。
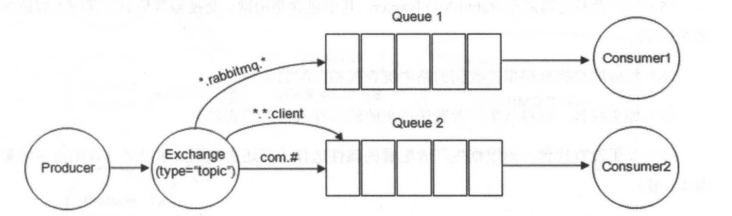
以上图为例:
- 路由键为 “com.rabbitmq.client” 的消息会同时路由到 Queue1 和 Queue2;
- 路由键为 “com.hidden.client” 的消息只会路由到 Queue2 中;
- 路由键为 “com.hidden.demo” 的消息只会路由到 Queue2 中;
- 路由键为 “java.rabbitmq.demo” 的消息只会路由到 Queue1 中;
- 路由键为 “java.util.concurrent” 的消息将会被丢弃或者返回给生产者(需要设置 mandatory 参数),因为它没有匹配任何路由键。
消息转换器
Spring会把你发送的消息序列化为字节发送给MQ,接收消息的时候,还会把字节反序列化为Java对象。
只不过,默认情况下Spring采用的序列化方式是JDK序列化。众所周知,JDK序列化存在下列问题:
- 数据体积过大
- 有安全漏洞
- 可读性差
显然,JDK序列化方式并不合适。我们希望消息体的体积更小、可读性更高,因此可以使用JSON方式来做序列化和反序列化。
在publisher和consumer两个服务中都引入依赖:
<dependency><groupId>com.fasterxml.jackson.dataformat</groupId><artifactId>jackson-dataformat-xml</artifactId><version>2.9.10</version></dependency>
配置消息转换器。
在启动类中添加一个Bean即可:
@Bean
public MessageConverter jsonMessageConverter(){
return new Jackson2JsonMessageConverter();
}
消息可靠性
消息可靠性主要靠发送方确认机制和接收方确认机制保障。
发送方确认机制
- 将信道(AMQP信道)设置为confirm模式,则在信道上的所有消息都会分配一个唯一ID;
- 一旦消息被成功投递到queue,信道会返回一个ack确认消息(包含消息唯一ID)给生产者(通过ConfirmCallback接口进行回调);
- 如果Rabbit MQ内部发生错误导致消息丢失,会发送一条nack消息给生产者(通过ReturnCallback接口进行回调);
- 所有发送的消息都会被confirm,即发送方会收到一条ack或nack,但不保证消息确认的快慢。
发送方的确认模式是异步的
接收方确认机制
- 消费者在声明队列时可以通过设置
noack=false参数开启手动确认机制,此时Rabbit MQ会等待消费者显示地发回ack确认信号后才把消息移除(消息的接收和确认是两个不同的过程)。默认情况下noack设置为true,即消息消费后会自动被删除。 - Rabbit MQ不会为消息的消费设置超时时间,仅仅通过检测消费者是否断开连接判断是否需要重新发送消息。这样做是为了允许消费者长时间处理一条消息,保证消息的最终一致性。
- 如果消费者在返回ack确认消息之前断开了连接,Rabbit MQ会为该消息重新分配一个消费者(这样做可能存在消息重复消费的隐患,需要根据消息ID进行去重)。
解决消息丢失
1.生产者丢了数据
生产者将数据发送到rabbitmq的时候,可能数据就在半路给搞丢了,例如网络问题。
解决⽅案:RabbitMQ提供transaction和confirm模式来确保⽣生产者不不丢消息。transaction机制就是说,发送消息前开启事物(channel.txSelect()),然后发送消息,如果发送过程中出现什什么异常, 事物就会回滚(channel.txRollback()),如果发送成功则提交事物(channel.txCommit())。然⽽缺点就是吞吐量量下降了了。 因此,⽣产上用confirm模式的居多。一旦channel进⼊confirm模式,所有在该信道上面发布的消息都将会被指派一个唯一的ID(从1开始),一旦消息被投递到所有匹配的队列之后,rabbitMQ就会发送一个 Ack给⽣产者(包含消息的唯⼀一ID),这就使得⽣产者知道消息已经正确到达目的队列了。如果rabiitMQ没能处理该消息,则会发送一个Nack消息给你,你可以进行重试操作。
# 1、开启发送端确认
spring.rabbitmq.publisher-confirm=true
# 2、向rabbitTemplate中添加ConfirmCallback接口的实现类
2.rabbitmq弄了数据
就是rabbitmq⾃己丢了数据,这个你必须开启rabbitmq的持久化,就是消息写⼊入之后会持久化到磁盘,哪怕是rabbitmq⾃己挂了,恢复之后会自动读取之前存储的数据,⼀般数据不会丢。除非极其罕见的是,rabbitmq还没持久化,⾃己就挂了,可能导致少量数据会丢失的,但是这个概率较⼩。
解决⽅案: 处理消息队列列丢数据的情况,⼀般是开启持久化磁盘的配置。这个持久化配置可以和confirm机制配合使用,你可以在消息持久化磁盘后,再给生产者发送⼀个Ack信号。这样,如果消息持久化磁盘之前, rabbitMQ阵亡了,那么生产者收不到Ack信号,⽣产者会自动重发。
# 1、开启rabbit端确认
spring.rabbitmq.publisher-returns=true
# 消息投递失败后立即回调
spring.rabbitmq.template.mandatory=true
# 2、向rabbitTemplate中添加ReturnCallback接口的实现类
@Configuration
public class TestConfiguration {
@Autowired
private RabbitTemplate rabbitTemplate;
@Bean
@PostConstruct // TestConfiguration类初始化后再调用该方法设置rabbitTemplate
public void initRabbitTemplate() {
// 发送端确认
// 向 rabbitTemplate 中添加消息确认回调(ConfirmCallback接口的实现类)
rabbitTemplate.setConfirmCallback(new RabbitTemplate.ConfirmCallback() {
/**
* 发送确认回调
* @param correlationData 消息关联数据(消息ID)
* @param ack 确认标记
* @param cause 失败原因
*/
@Override
public void confirm(CorrelationData correlationData, boolean ack, String cause) {
String msg;
msg = ack ? "成功投递" : "投递失败";
System.out.println(msg);
}
});
// 消息抵达队列确认(rabbitmq端确认)
rabbitTemplate.setReturnCallback(new RabbitTemplate.ReturnCallback() {
/**
* 若消息未到达指定队列,触发此失败回调
* @param message 投递失败的消息详情
* @param replyCode 回复的状态码
* @param replyText 回复的文本内容
* @param exchange 投递的交换机
* @param routingKey 消息的路由键
*/
@Override
public void returnedMessage(Message message, int replyCode,
String replyText, String exchange, String routingKey)
{
System.out.println("消息未成功抵达queue");
}
});
}
}
3.消费端弄丢了数据
rabbitmq如果丢失了数据,主要是因为你消费的时候,刚消费到,还没处理,结果进程挂了,比如重启了,那么就尴尬了,rabbitmq认为你都消费了,这数据就丢了。
解决⽅案:启⽤手动确认模式可以解决这个问题(重试机制)⼿动确认模式,如果消费者来不及处理就死掉时,没有响应ack时会重复发送⼀条信息给其他消费者;如果监听程序处理异常了,且未对异常进行捕获, 会一直重复接收消息,然后⼀直抛异常;如果对异常进行了捕获,但是没有在finally里ack,也会一直重复发送消息(重试机制)。
# 1、开启接收端手动确认
spring.rabbitmq.listener.simple.acknowledge-mode=manual
# 2、在listerner中手动进行确认或拒收
public class Consumer {
@RabbitListener(queues = "123")
public void handler1(Message message, Channel channel) {
// 通过 Message 对象获取消息的ID
long deliveryTag = message.getMessageProperties().getDeliveryTag();
try {
// 手动进行ACK确认
channel.basicAck(deliveryTag, true);
/*
拒收消息
boolean multiple:是否支持批量处理;
boolean requeue:是否重新进入队列)
*/
channel.basicNack(deliveryTag, false, false);
} catch (IOException e) {
e.printStackTrace();
}
}
}
事务消息
消息确认机制只能在事后进行通知,提供了一种补偿机制。
事务消息可以保证消息的发送和处理之间的原子性
通过对信道的设置可以实现Rabbit MQ发送事务消息
channel.txSelect():通知服务器开启事务模式,服务器会返回tx.Select-OKchannel.basicPublish():发送消息,此时消息不会直接进入queue中,而是进入到一个临时队列channel.rxCommit():提交事务,临时队列中存放的所有消息进入queue中channel.txRollback():回滚事务
其中任何一个环节出现问题都会抛出IOException异常,通过捕捉异常可以进行事务回滚
事务消息会产生大量的连接,降低MQ性能
死信队列、延时队列
死信队列
- 正常情况下无法被消费的消息称为死信消息。
以下情况会造成死信:
- 消息被消费方否定确认,并且requeue属性被设置为false
- 消息在队列中存活的时间大于了TTL(最大存活时间)
- 消息队列中消息数量超过上限
- 死信消息将会被Rabbit MQ特殊处理,如果配置了死信队列,那么该消息将会进入死信队列;未配置死信队列,则该消息被直接丢弃。
- 开启死信业务时,需要为死信队列配置一个死信交换机
延时队列
- 基于死信队列可以实现延时队列
- 可以通过为消息设置TTL属性或者将消息加入设置了TTL属性的队列,故意使该消息超时从而加入死信队列
- 消费者只需要消费死信队列中的消息即可

若有收获,就点个赞吧
0 人点赞
