ArrayList与LinkedList
遍历与迭代器
- List集合的遍历方法
- 普通for循环 ArrayList实现了 RandomAccess 接口,通过下标遍历更快
- 增强for循环(实现Iterable接口的对象可以使用增强for循环)
- foreach方法
- 迭代器 Linked使用迭代器遍历更快,因为迭代器内存储了上一个节点的信息
- stream流
- 如何在遍历时删除集合元素
- 调用迭代器中提供的add、remove等方法(直接调用List集合提供的删除方法会抛出并发修改异常)
- 使用普通for循环遍历集合时可以修改集合元素
使用List集合特有的
Listiterator迭代器进行遍历,调用迭代器中提供的方法public static void main(String[] args) {ArrayList<Integer> list = new ArrayList<>(Arrays.asList(0, 1, 2, 3));for (int i = 0; i < list.size(); i++) {if (i == 1) list.remove(i);}Iterator<Integer> iterator = list.iterator();while (iterator.hasNext()) {Integer next = iterator.next();if (next == 1) iterator.remove();}ListIterator<Integer> listIterator = list.listIterator();while (listIterator.hasNext()) {Integer next = listIterator.next();if (next == 1) listIterator.remove();}System.out.println(list); // [0, 2, 3]}
- ListIterator
- List集合特有的迭代器
- 可以从任意方向遍历集合
ListItr内部类实现了ListIterator接口,在对集合进行操作时,会进行expectedModCount = modCount的操作,所以允许在使用迭代器遍历时对集合进行修改

对比使用普通for循环和ListIterator在进行遍历时修改集合元素
public static void main(String[] args) {ArrayList<Integer> list = new ArrayList<>(Arrays.asList(0, 1, 2, 3));// 默认在末尾添加元素for (int i = 0; i < list.size(); i++) {if (i == 1) list.add(11); // [0, 1, 2, 3, 11]}// 默认在当前元素之后添加新元素ListIterator<Integer> listIterator = list.listIterator();while (listIterator.hasNext()) {Integer next = listIterator.next();if (next == 1) listIterator.add(11); // [0, 1, 11, 2, 3]}}
添加数据
ArrayList进行扩容,以
add(int index, E element)为例//1.添加范围检查 rangeCheckForAdd(index); //2.调用方法检验是否要扩容,且让增量++ (修改modCount) ensureCapacityInternal(size + 1); //3.复制数组 System.arraycopy(elementData, index, elementData, index + 1,size - index); //4.添加元素 elementData[index] = element; //5.更新数组中元素个数 size++;向ArrayList中指定位置添加数据时,index不能超过size,否则会抛出下标越界异常
LinkedList提供了
addFirst()和addLast()方法,而调用add(int index, Element E)在指定位置插入元素时,则需要遍历链表找到下标位置的元素ArrayList和LinkedList中都可以存储null值
- 如何复制某个ArrayList到另一个ArrayList中去?
- 使用clone()方法
- 使用ArrayList构造方法
使用addAll方法
<br />
ArrayList 与 LinkedList 都有自己的使用场景,如果你不能很好的确定,那么就使用 ArrayList。但如果你能确定你会在集合的首位有大量的插入、删除以及获取操作,那么可以使用 LinkedList,因为它都有相应的方法;addFirst、addLast、 removeFirst、removeLast、getFirst、getLast,这些操作的时间复杂度都是 O(1),非常高效。
LinkedList 的链表结构不一定会比 ArrayList 节省空间,首先它所占用的内存不是连续的,其次他还需要大量的实例化对象创造节点。虽然不一定节省空间,但链表结构也是非常优秀的数据结构,它能在你的程序设计中起着非常优秀的作用,例如可视化的链路追踪图,就是需要链表结构,并需要每个节点自旋一次,用于串联业务。
ArrayList的自动扩容
- 调用无参构造方法时,ArrayList的默认初始容量为0。直到调用add方法时才进行扩容
- 第一次扩容后容量为10
- 以后每次都是原容量的1.5倍
- 调用add方法前会先检查数组容量,如果容量不足,则进行自动扩容
- 自动扩容底层调用
System.arrayCopy()方法进行数组拷贝
HashMap
JDK1.8 之前 HashMap 由 数组+链表 组成的,数组是 HashMap 的主体,链表则是主要为了解决哈希冲突(两个对象调用的hashCode方法计算的哈希码值一致导致计算的数组索引值相同)而存在的(“拉链法”解决冲突)。JDK1.8 以后在解决哈希冲突时有了较大的变化,当链表长度大于阈值(或者红黑树的边界值,默认为 8)并且当前数组的长度大于64时,此时此索引位置上的所有数据改为使用红黑树存储。
哈希方法
字符串类型变量hashCode的计算方法:固定乘以质数31
public int hashCode() { int h = hash; if (h == 0 && value.length > 0) { char val[] = value; for (int i = 0; i < value.length; i++) { // 固定 * 31 h = 31 * h + val[i]; } hash = h; } return h; }ThreadLocalMap中的hashCode计算方法:斐波那契散列法
private static final int HASH_INCREMENT = 0x61c88647; // 该数与黄金分割点有关 private static int nextHashCode() { return nextHashCode.getAndAdd(HASH_INCREMENT); }扰动函数
h = key.hashCode() ^ (h >>> 16)
高16位与低16位进行异或运算,增大哈希值低位数字的随机性,使得后续在计算数组下标时使得元素下标更为分散
- 桶容量为2的n次方的原因
通过取模运算将hash值映射为数组下标,hash%length,计算机中直接求余效率不如位移运算(这点上述已经讲解)。所以源码中做了优化,使用 hash&(length-1),而实际上hash%length等于hash&(length-1)的前提是length是2的n次幂。
若指定的 HashMap 的初始长度不是2的n次方,则会自动寻找比初始值大的,最小的那个 2 进制数值,做为桶的容量。比如传 了 17,应该找到的是 32。
- 另一方面,一般我们可能会想通过 % 求余来确定位置,这样也可以,只不过性能不如 & 运算。而且当n是2的幂次方时:hash & (length - 1) == hash % length
- 由上面可以看出,当我们根据key的hash确定其在数组的位置时,如果n为2的幂次方,可以保证数据的均匀插入,如果n不是2的幂次方,可能数组的一些位置永远不会插入数据,浪费数组的空间,加大hash冲突。
- HashMap的构造方法 ```java // 默认容量16,默认负载因子0.75 public HashMap() {}
// 指定初始容量,默认负载因子0.75(初始容量最小为16) public HashMap(int initialCapacity) {}
// 指定初始容量,指定负载因子 public HashMap(int initialCapacity, float loadFactor) {}
// 包含另一个“Map”的构造函数 public HashMap(Map<? extends K, ? extends V> m){} ```
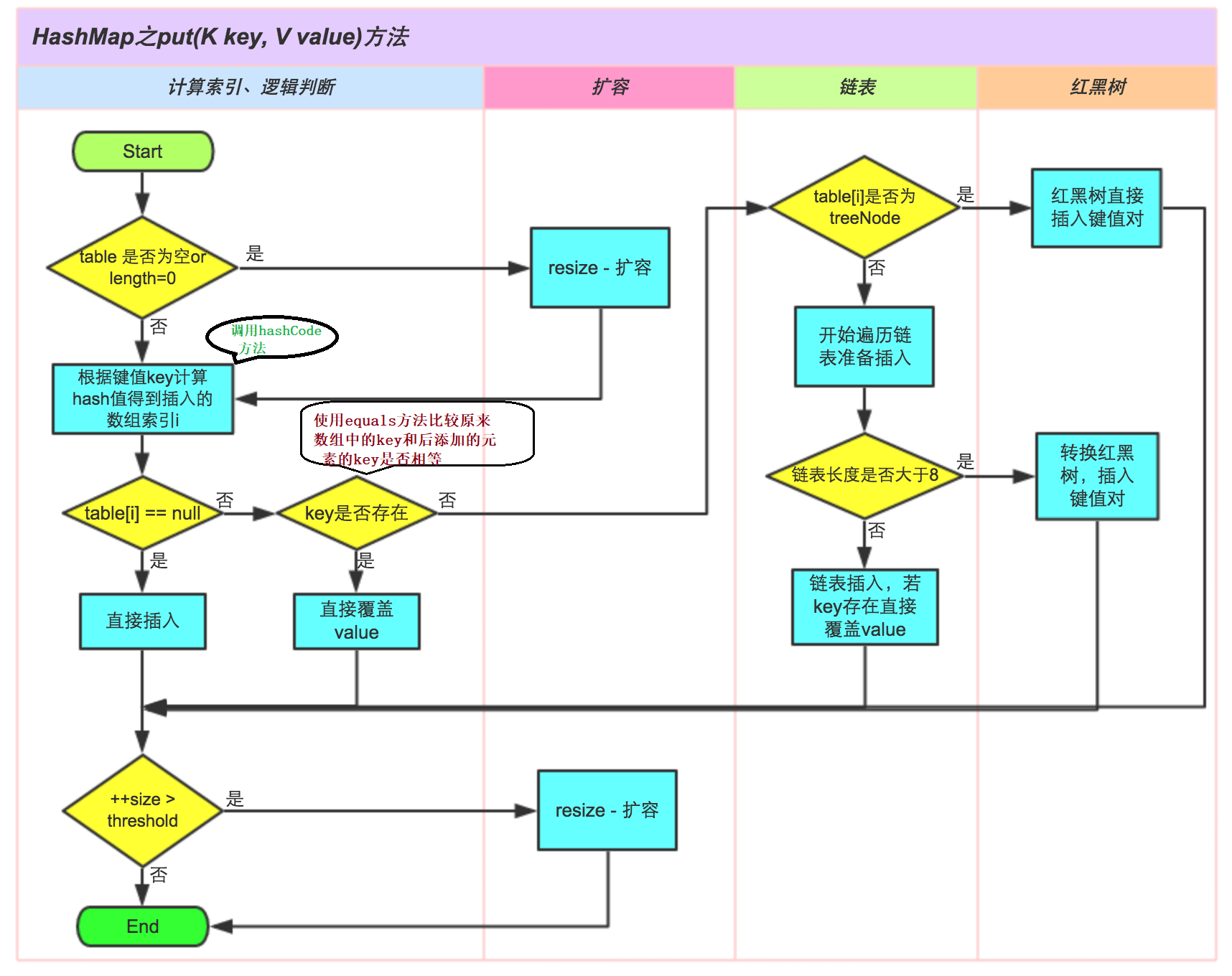
put方法
0)如果数组table没有初始化,则先初始化table数组;
1)先通过hash值计算出key映射到哪个桶;
2)如果桶上没有碰撞冲突,则直接插入;
3)如果出现碰撞冲突了,则需要处理冲突:
a:如果该桶使用红黑树处理冲突,则调用红黑树的方法插入数据;
b:否则采用传统的链式方法插入。如果链的长度达到临界值,则把链转变为红黑树;
4)如果桶中存在重复的键,则为该键替换新值value;
5)如果size大于阈值threshold,则进行扩容;
- 节点添加完成之后判断此时节点个数是否大于TREEIFY_THRESHOLD临界值8,如果大于则将链表转换为红黑树,转换红黑树的方法treeifyBin
1.根据哈希表中元素个数确定是扩容还是树形化
2.如果是树形化遍历桶中的元素,创建相同个数的树形节点,复制内容,建立起联系
3.然后让桶中的第一个元素指向新创建的树根节点,替换桶的链表内容为树形化内容
自动扩容
- 负载因子表示HashMap的疏密程度,计算方法为size/capacity,默认负载因子为0.75
- 当HashMap里面容纳的元素已经达到HashMap数组长度的75%时,表示HashMap太挤了,需要扩容,而扩容这个过程涉及到 rehash、复制数据等操作,非常消耗性能。所以开发中尽量减少扩容的次数,可以通过创建HashMap集合对象时指定初始容量来尽量避免。
table数组的最大容量为2^30
HashMap在进行扩容时,使用的rehash方式非常巧妙,因为每次扩容都是翻倍,与原来计算的 (n-1)&hash的结果相比,只是多了一个bit位,所以节点要么就在原来的位置,要么就被分配到”原位置+旧容量”这个位置。

- 在进行扩容时不需要重新计算hash,只需要看看原来的hash值在高一位的那个bit是1还是0就可以了,是0的话索引没变,是1的话索引变成“原索引+oldCap(原位置+旧容量)”。
遍历HashMap
map.keySet()和map.values()得到key与value的set集合,分别进行遍历- 迭代器遍历
map.entrySet().iterator(),获取的迭代器会取出Map.Entry<>类型的元素 - forEach方法
forEach((key, value) -> {sout(key + value)}) - keySet + get 遍历
并发问题
JDK1.7中HashMap的链表在扩容时采取头插法进行创建,头插法会导致链表的反转,因此有可能导致数据访问线程陷入死循环
JDK1.7 和 JDK1.8 中的HashMap都不支持并发访问,会出现数据错乱情况
红黑树
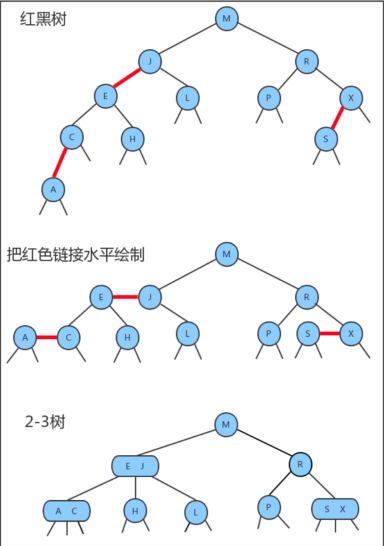
红黑树特点:
- 根节点是黑色
- 节点是红黑或者黑色
- 所有子叶节点都是黑色
- 每个红色节点必须有两个黑色子节点(也同样说明一条链路上不能有链路的红色节点)
- 黑高,从任一节点到齐每个叶子节点,经过的路径都包含相同数目的黑色节点
红黑树的平衡
- 插入的新节点默认都为红色
- 平衡调整包括:左旋、右旋和颜色反转
- 左旋后可能需要进行右旋调整,而右旋后又可能需要进一步进行颜色反转
- 所以在每次插入节点后,树的平衡的调整顺序为:左旋—>右旋—>颜色反转

若有收获,就点个赞吧
0 人点赞
