锁
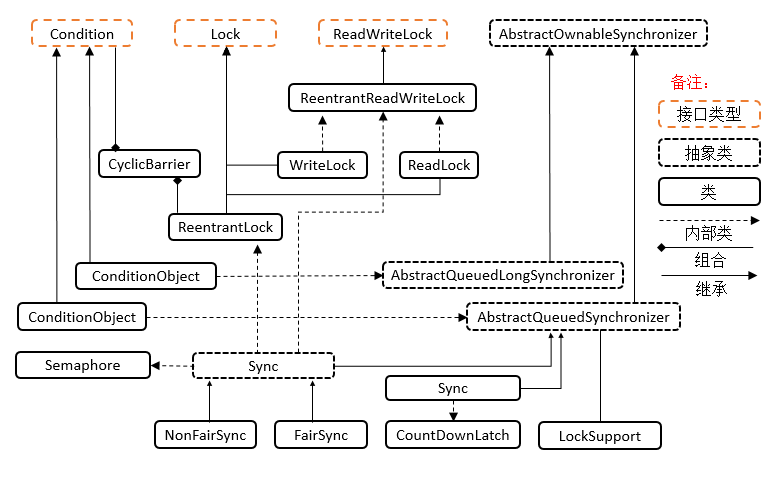
ReentrantLock
ReentrantReadWriteLock
当读操作远远高于写操作时,这时候使用读写锁让读-读可以并发,提高性能。读-写,写-写都是相互互斥的。
提供一个数据容器类内部分别使用读锁保护数据的read()方法,写锁保护数据的write()方法
- 流程与 ReentrantLock 加锁相比没有特殊之处,不同是写锁状态占了 state 的低 16 位,而读锁使用的是 state 的高 16 位
class DataContainer{// 受读写保护的数据private Object data;// 读写锁private ReentrantReadWriteLock rw = new ReentrantReadWriteLock();// 读锁private ReentrantReadWriteLock.ReadLock r = rw.readLock();// 写锁private ReentrantReadWriteLock.WriteLock w = rw.writeLock();public Object read() {System.out.println("获取读锁");r.lock();try {System.out.println("读取");Thread.sleep(1000);} catch (InterruptedException e) {e.printStackTrace();} finally {System.out.println("释放读锁");r.unlock();return data;}}public void write() {System.out.println("获取写锁");w.lock();try {System.out.println("写入");Thread.sleep(1000);} catch (InterruptedException e) {e.printStackTrace();} finally {System.out.println("释放写锁");w.unlock();}}}
- 读锁不支持条件变量
- 重入时升级不支持:即持有读锁的情况下去获取写锁,会导致获取写锁永久等待
- 重入时降级支持:即持有写锁的情况下去获取读锁
StampedLock
该类自 JDK 8 加入,是为了进一步优化读性能,它的特点是在使用读锁、写锁时都必须配合【戳】使用
加解读锁
long stamp = lock.readLock();
lock.unlockRead(stamp);
加解写锁
long stamp = lock.writeLock();
lock.unlockWrite(stamp);
乐观读,StampedLock 支持 tryOptimisticRead() 方法(乐观读),读取完毕后需要做一次 戳校验 如果校验通
过,表示这期间确实没有写操作,数据可以安全使用,如果校验没通过,需要重新获取读锁,保证数据安全。
long stamp = lock.tryOptimisticRead();
// 验戳
if(!lock.validate(stamp)){
// 锁升级
}
提供一个 数据容器类 内部分别使用读锁保护数据的 read() 方法,写锁保护数据的 write() 方法
- StampedLock 不支持条件变量
- StampedLock 不支持可重入
线程协作
Semaphore
Semaphore 通常我们叫它信号量, 可以用来控制同时访问特定资源的线程数量,通过协调各个线程,以保证合理的使用资源。
可以把它简单的理解成我们停车场入口立着的那个显示屏,每有一辆车进入停车场显示屏就会显示剩余车位减1,每有一辆车从停车场出去,显示屏上显示的剩余车辆就会加1,当显示屏上的剩余车位为0时,停车场入口的栏杆就不会再打开,车辆就无法进入停车场了,直到有一辆车从停车场出去为止。
通常用于那些资源有明确访问数量限制的场景,常用于限流。
比如:数据库连接池,同时进行连接的线程有数量限制,连接不能超过一定的数量,当连接达到了限制数量后,后面的线程只能排队等前面的线程释放了数据库连接才能获得数据库连接。
public static void main(String[] args) {
// 1. 创建 semaphore 对象
Semaphore semaphore = new Semaphore(3);
// 2. 10个线程同时运行
for (int i = 0; i < 10; i++) {
new Thread(() -> {
// 3. 获取许可
try {
semaphore.acquire();
} catch (InterruptedException e) {
e.printStackTrace();
}
try {
log.debug("running...");
sleep(1);
log.debug("end...");
} finally {
// 4. 释放许可
semaphore.release();
}
}).start();
}
}
CountDownLatch
CountDownLatch允许 count 个线程阻塞在一个地方,直至所有线程的任务都执行完毕。
CountDownLatch是共享锁的一种实现,它默认构造 AQS 的 state 值为 count。当线程使用countDown方法时,其实使用了tryReleaseShared方法以CAS的操作来减少state,直至state为0就代表所有的线程都调用了countDown方法。当调用await方法的时候,如果state不为0,就代表仍然有线程没有调用countDown方法,那么就把已经调用过countDown的线程都放入阻塞队列Park,并自旋CAS判断state == 0,直至最后一个线程调用了countDown,使得state == 0,于是阻塞的线程便判断成功,全部往下执行。
用来进行线程同步协作,等待所有线程完成倒计时。其中构造参数用来初始化等待计数值,await() 用来等待计数归零,countDown() 用来让计数减一
public static void main(String[] args) throws InterruptedException {
CountDownLatch latch = new CountDownLatch(3);
new Thread(() -> {
log.debug("begin...");
sleep(1);
latch.countDown();
log.debug("end...{}", latch.getCount());
}).start();
new Thread(() -> {
log.debug("begin...");
sleep(2);
latch.countDown();
log.debug("end...{}", latch.getCount());
}).start();
new Thread(() -> {
log.debug("begin...");
sleep(3);
latch.countDown();
log.debug("end...{}", latch.getCount());
}).start();
log.debug("waiting...");
latch.await();
log.debug("wait end...");
}
CyclicBarrier
CyclicBarrier 循环栅栏,用来进行线程协作,等待线程满足某个计数。构造时设置『计数个数』,每个线程执行到某个需要“同步”的时刻调用 await() 方法进行等待,当等待的线程数满足『计数个数』时,继续执行。跟CountdownLatch一样,但这个可以重用
CyclicBarrier cb = new CyclicBarrier(2); // 个数为2时才会继续执行
for (int i=0;i<3;i++){
new Thread(()->{
System.out.println("线程1开始.."+new Date());
try {
cb.await(); // 当个数不足时,等待
} catch (InterruptedException | BrokenBarrierException e) {
e.printStackTrace();
}
System.out.println("线程1继续向下运行..."+new Date());
}).start();
new Thread(()->{
System.out.println("线程2开始.."+new Date());
try { Thread.sleep(2000); } catch (InterruptedException e) { }
try {
cb.await(); // 2 秒后,线程个数够2,继续运行
} catch (InterruptedException | BrokenBarrierException e) {
e.printStackTrace();
}
System.out.println("线程2继续向下运行..."+new Date());
}).start();
}
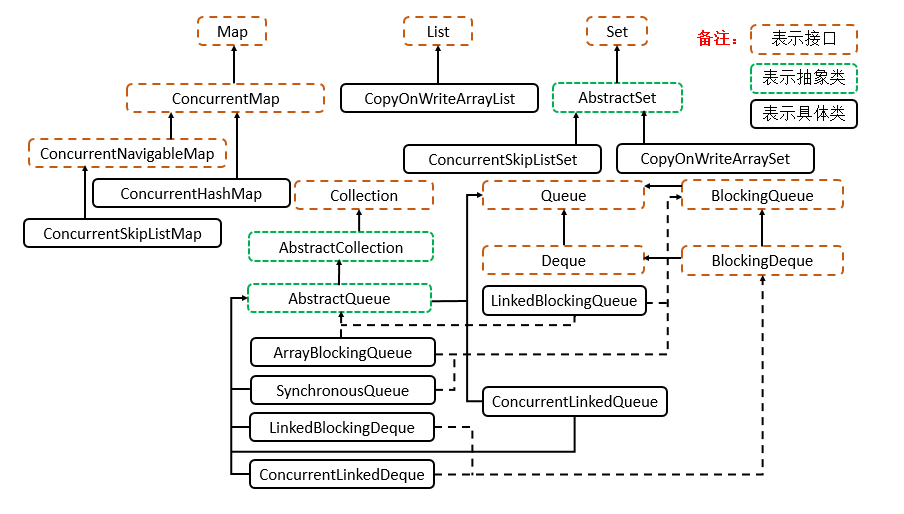
线程安全的集合
ConcurrentHashMap 1.7
初始化容量:ConcurrentHashMap中保存了一个默认长度为16的Segment[],每个Segment元素中保存了一个默认长度为2的HashEntry[],我们添加的元素,是存入对应的Segment中的HashEntry[]中。所以ConcurrentHashMap中默认元素的长度是32个,而不是16个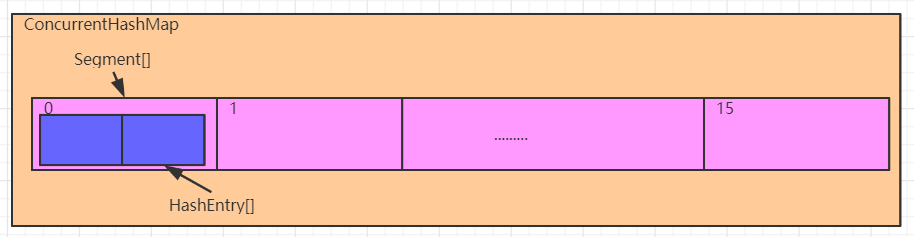
其中,Segment是:
static final class Segment<K,V> extends ReentrantLock implements Serializable {}
HashEntry是单链表的节点:
//ConcurrentHashMap中真正存储数据的对象
static final class HashEntry<K,V> {
final int hash; //通过运算,得到的键的hash值
final K key; // 存入的键
volatile V value; //存入的值
volatile HashEntry<K,V> next; //记录下一个元素,形成单向链表
// ...
}
通过一个hashCode键要计算两个数组的索引,为了避免冲突,当Segment初始长度为16时,取高4位计算Segment[]的索引;低位则用来计算HashEntry索引。
添加元素
计算出存放位置后,调用Segment中的put方法存入元素。使用tryLock尝试锁住Segment:
- 若成功上锁:计算出HashEntry[]的索引,存入元素
- 若无法上锁:通过
while (!tryLock()) {}进入自旋,创建出待添加的HashEntry对象,之后如依旧拿不到锁,继续自旋到次数上限。自旋失败后,直接调用lock()方法,线程进入阻塞直到成功上锁。
- 扩容
在添加成功后会检查数组长度是否达到容量阈值,若达到则进行扩容。从第一个Segment开始,依次对每个Segment下的元素进行迁移。
扩容操作在添加方法中进行,由于此时已经拿到Segment的锁,所以扩容不存在线程安全问题。
扩容过程采用单链表的头插法进行。
- 集合长度获取
采用CAS(比较modCount的值是否变化)和加锁机制依次获取每个Segment中元素的数量,进行累加得到结果
ConcurrentHashMap 1.8
构造方法中,都涉及到一个变量sizeCtl,这个变量是一个非常重要的变量,而且具有非常丰富的含义,它的值不同,对应的含义也不一样,这里我们先对这个变量不同的值的含义做一下说明,后续源码分析过程中,进一步解释
sizeCtl为0,代表数组未初始化, 且数组的初始容量为16
sizeCtl为正数,如果数组未初始化,那么其记录的是数组的初始容量,如果数组已经初始化,那么其记录的是数组的扩容阈值
sizeCtl为-1,表示数组正在进行初始化
sizeCtl小于0,并且不是-1,表示数组正在扩容, -(1+n),表示此时有n个线程正在共同完成数组的扩容操作
添加元素put/putVal方法
putVal()方法逻辑:
1、计算key的hash值(与HashMap中一致)
2、CAS操作与synchronized配合进行元素添加
- 如果数组还未初始化,先对数组进行初始化
- 桶位置没有元素,利用cas添加元素
- 桶位置元素的hash值为MOVED,证明正在扩容,那么协助扩容
- 桶位置元素不为空,且当前没有处于扩容操作,synchronized进行元素添加
3、维护集合长度,判断是否扩容(addCount()方法)
CAS操作与synchronized配合进行元素添加:
当前桶位无元素(为null)时,通过CAS添加元素;当前桶位存在元素,则使用synchronzied锁住链表头元素,进行添加
for (Node<K,V>[] tab = table;;) { // 死循环,用于CAS操作
Node<K,V> f; int n, i, fh;
//如果数组还未初始化,先对数组进行初始化
if (tab == null || (n = tab.length) == 0)
tab = initTable(); // 数组初始化方法,见如下讲解
//如果hash计算得到的桶位置没有元素,利用cas将元素添加
else if ((f = tabAt(tab, i = (n - 1) & hash)) == null) {
//cas+自旋(和外侧的for构成自旋循环),保证元素添加安全
if (casTabAt(tab, i, null,
new Node<K,V>(hash, key, value, null)))
break; // no lock when adding to empty bin
}
//如果hash计算得到的桶位置元素的hash值为MOVED,证明正在扩容,那么协助扩容
else if ((fh = f.hash) == MOVED)
tab = helpTransfer(tab, f);
//hash计算的桶位置元素不为空,且当前没有处于扩容操作,进行元素添加
else {
V oldVal = null;
//对当前桶进行加锁,保证线程安全,执行元素添加操作
synchronized (f) {
//双重检验
if (tabAt(tab, i) == f) {
if (fh >= 0) {} //普通链表节点扩容
else if (f instanceof TreeBin) {} //树节点扩容
}
}
}
}
初始化方法
private final Node<K,V>[] initTable() {
Node<K,V>[] tab; int sc;
//cas+自旋,保证线程安全,对数组进行初始化操作
while ((tab = table) == null || tab.length == 0) {
//如果sizeCtl的值(-1)小于0,说明此时正在初始化, 让出cpu
if ((sc = sizeCtl) < 0)
Thread.yield(); // lost initialization race; just spin
//cas修改sizeCtl的值为-1,修改成功,进行数组初始化,失败,继续自旋
else if (U.compareAndSwapInt(this, SIZECTL, sc, -1)) {
try {
if ((tab = table) == null || tab.length == 0) {
//sizeCtl为0,取默认长度16,否则去sizeCtl的值
int n = (sc > 0) ? sc : DEFAULT_CAPACITY;
@SuppressWarnings("unchecked")
//基于初始长度,构建数组对象
Node<K,V>[] nt = (Node<K,V>[])new Node<?,?>[n];
table = tab = nt;
//计算扩容阈值,并赋值给sc
sc = n - (n >>> 2);
}
} finally {
//将扩容阈值,赋值给sizeCtl
sizeCtl = sc;
}
break;
}
}
return tab;
}
addCount()方法
① CounterCell数组不为空,优先利用数组中的CounterCell记录数量
② 如果数组为空,尝试对baseCount进行累加,失败后,会执行fullAddCount逻辑
③ 如果是添加元素操作,会继续判断是否需要扩容
通过一个baseCount数组维护集合长度。修改长度时通过CAS获取一个CounterCell-value(根据线程id进行哈希运算,决定获取哪个位置的CounterCell)并修改值。若长时间自旋,则对baseCount数组进行扩容,再进行获取。
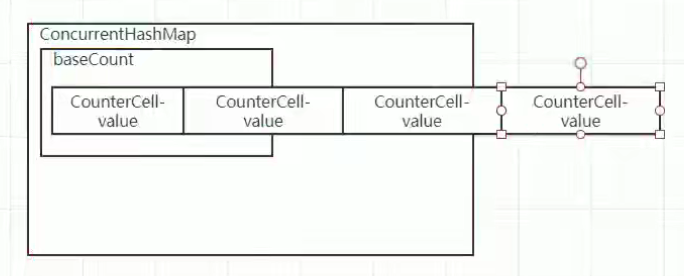
集合长度获取
size方法 —> sumCount方法
public int size() {
long n = sumCount();
return ((n < 0L) ? 0 :
(n > (long)Integer.MAX_VALUE) ? Integer.MAX_VALUE :
(int)n);
}
final long sumCount() {
CounterCell[] as = counterCells; CounterCell a;
//获取baseCount的值
long sum = baseCount;
if (as != null) {
//遍历CounterCell数组,累加每一个CounterCell的value值
for (int i = 0; i < as.length; ++i) {
if ((a = as[i]) != null)
sum += a.value;
}
}
return sum;
}
扩容
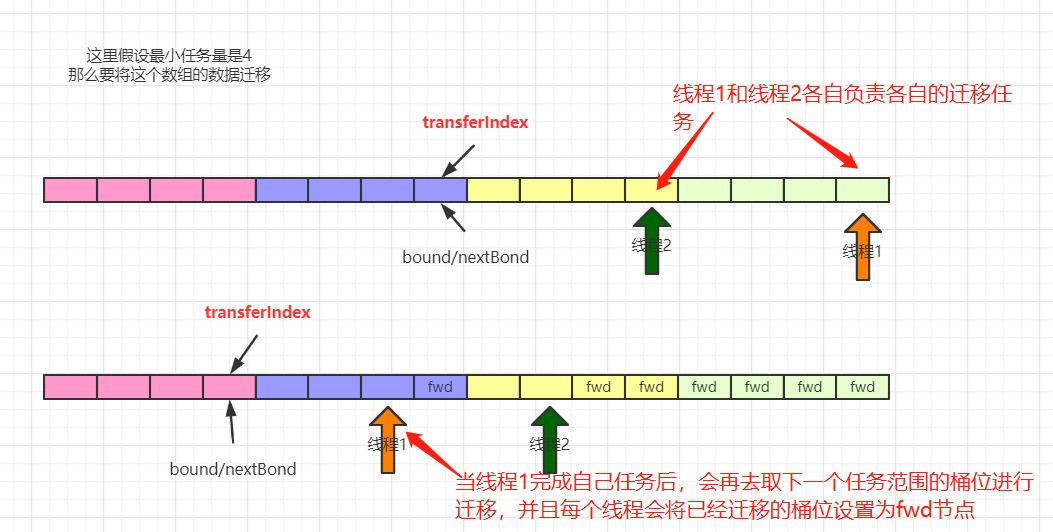
- 触发扩容机制时会给每个线程分配扩容任务,最小的任务量是16个桶的迁移
- 迁移过程从后往前进行,在处理每个桶位时会使用synchronized锁住该桶位
- 当前桶位的数据完成迁移后,使用一个ForwardingNode在原数组上替换该节点
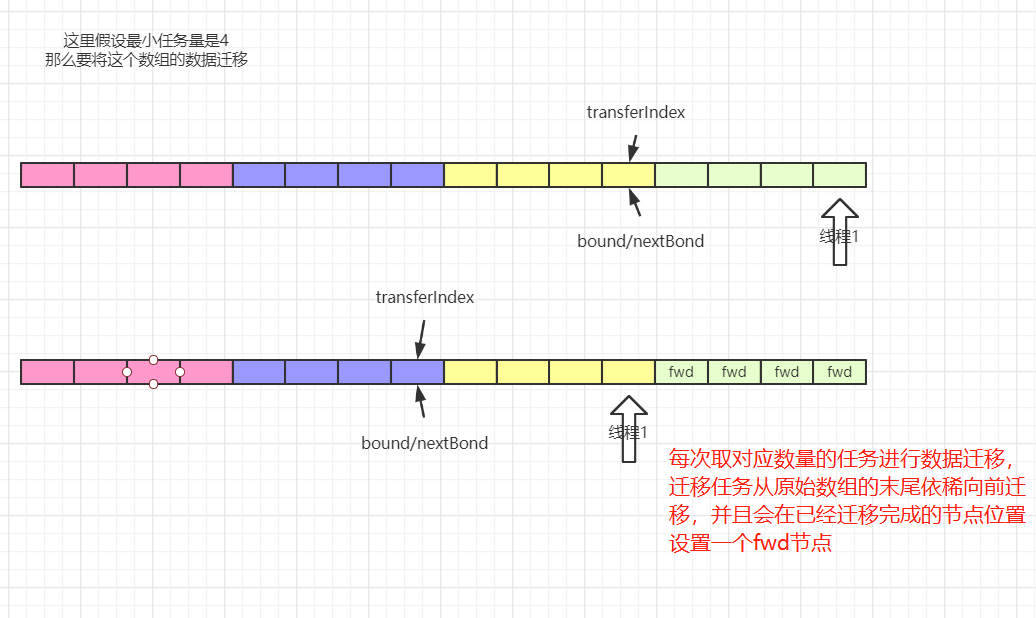
JDK1.8中多线程协助扩容的实现:
多线程协助扩容的操作会在两个地方被触发:
① 当添加元素时,发现添加的元素对用的桶位为fwd节点,就会先去协助扩容,然后再添加元素
② 当添加完元素后,判断当前元素个数达到了扩容阈值,此时发现sizeCtl的值小于0,并且新数组不为空,这个时候,会去协助扩容
1.7 与 1.8 版本比较
其实可以看出JDK1.8版本的ConcurrentHashMap的数据结构已经接近HashMap,相对而言,ConcurrentHashMap只是增加了同步的操作来控制并发,从JDK1.7版本的ReentrantLock+Segment+HashEntry,到JDK1.8版本中synchronized+CAS+HashEntry+红黑树,相对而言,总结如下思考
- JDK1.8的实现降低锁的粒度,JDK1.7版本锁的粒度是基于Segment的,包含多个HashEntry,而JDK1.8锁的粒度就是HashEntry(首节点)
- JDK1.8版本的数据结构变得更加简单,使得操作也更加清晰流畅,因为已经使用synchronized来进行同步,所以不需要分段锁的概念,也就不需要Segment这种数据结构了,由于粒度的降低,实现的复杂度也增加了
- JDK1.8使用红黑树来优化链表,基于长度很长的链表的遍历是一个很漫长的过程,而红黑树的遍历效率是很快的,代替一定阈值的链表,这样形成一个最佳拍档
- JDK1.8为什么使用内置锁synchronized来代替重入锁ReentrantLock,我觉得有以下几点
1.因为粒度降低了,在相对而言的低粒度加锁方式,synchronized并不比ReentrantLock差,在粗粒度加锁中ReentrantLock可能通过Condition来控制各个低粒度的边界,更加的灵活,而在低粒度中,Condition的优势就没有了
2.JVM的开发团队从来都没有放弃synchronized,而且基于JVM的synchronized优化空间更大,使用内嵌的关键字比使用API更加自然
3.在大量的数据操作下,对于JVM的内存压力,基于API的ReentrantLock会开销更多的内存,虽然不是瓶颈,但是也是一个选择依据
CopyOnWriteArrayList
JDK中提供了 CopyOnWriteArrayList 类,相比于在读写锁的思想又更进一步。为了将读取的性能发挥到极致,CopyOnWriteArrayList 读取是完全不用加锁的,并且更厉害的是:写入也不会阻塞读取操作,只有写入和写入之间需要进行同步等待,读操作的性能得到大幅度提升。
CopyOnWriteArrayList 类的所有可变操作(add,set等等)都是通过创建底层数组的新副本来实现的。当 List 需要被修改的时候,并不直接修改原有数组对象,而是对原有数据进行一次拷贝,将修改的内容写入副本中。写完之后,再将修改完的副本替换成原来的数据,这样就可以保证写操作不会影响读操作了。
从 CopyOnWriteArrayList 的名字可以看出,CopyOnWriteArrayList 是满足 CopyOnWrite 的 ArrayList,所谓 CopyOnWrite 的意思:就是对一块内存进行修改时,不直接在原有内存块中进行写操作,而是将内存拷贝一份,在新的内存中进行写操作,写完之后,再将原来指向的内存指针指到新的内存,原来的内存就可以被回收。
CopyOnWriteArrayList 写入操作add()方法在添加集合的时候加了锁,保证同步,避免多线程写的时候会 copy 出多个副本。
/**
* Appends the specified element to the end of this list.
*
* @param e element to be appended to this list
* @return {@code true} (as specified by {@link Collection#add})
*/
public boolean add(E e) {
final ReentrantLock lock = this.lock;
lock.lock(); // 加锁
try {
Object[] elements = getArray();
int len = elements.length;
Object[] newElements = Arrays.copyOf(elements, len + 1); // 拷贝新数组
newElements[len] = e;
setArray(newElements);
return true;
} finally {
lock.unlock(); // 释放锁
}
}

若有收获,就点个赞吧
0 人点赞
