一、单机优化
1.1 向量化
用-O3编译选项可以自动向量化,用-fopt-info-vec-optimized编译选项输出向量化信息,确保编译过程中正常向量化。
1.2 分块与数组封装
本题中矩阵的形状为 ,为了方便储存与运算,将其扩展为
,为了方便储存与运算,将其扩展为 矩阵。如下公式所示,拓展之后的矩阵相乘之后,左上角
矩阵。如下公式所示,拓展之后的矩阵相乘之后,左上角 的部分
的部分 即为所求答案。
即为所求答案。
用下图所示的顺序,将分块好的矩阵存入数组,保证计算矩阵乘法时访问数据的顺序是连续的(原本矩阵是行优先存储的)。
1.3 线程级并行
加入 OpenMP 预处理指令,实现线程级并行。我就是在所有 for 循环前面加了#pragma omp parallel for,感觉用不上更高级的指令。
二、分布式并行
这一块参考了知网上北交大的一篇本科生论文,是苟悦宬同学创作的《使用OpenMP+MPI的矩阵乘法并行实现》。如上图, 和
和 矩阵分成了
矩阵分成了 共16大块,可以把
共16大块,可以把 矩阵四行分别用 MPI 分到四个节点上,分别跟
矩阵四行分别用 MPI 分到四个节点上,分别跟 矩阵计算乘积,然后在集中到根节点上拼出完整的
矩阵计算乘积,然后在集中到根节点上拼出完整的 矩阵。用上四个结点之后计算速度变成原来的4倍不到一点,因为节点间通讯也有一些开销,所以不能刚好达到原来速度的 4 倍。
矩阵。用上四个结点之后计算速度变成原来的4倍不到一点,因为节点间通讯也有一些开销,所以不能刚好达到原来速度的 4 倍。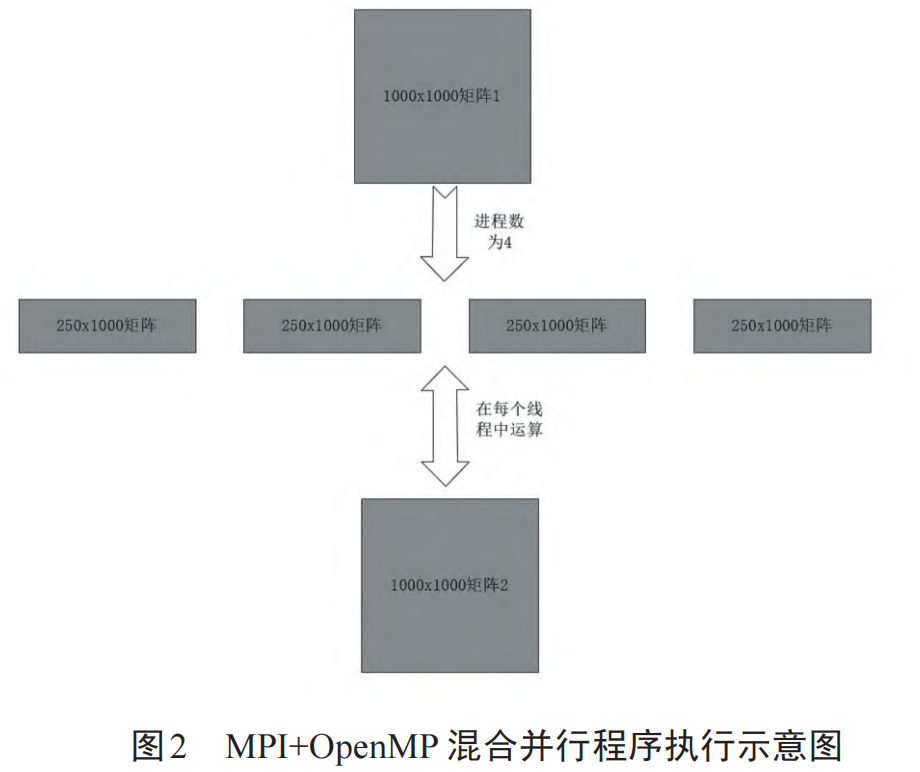
三、运行结果

源代码在附件里,集群上 chenyh-summer 账号里~/ChenYihangGeMM/hw_MPI.cpp也是源代码。

若有收获,就点个赞吧
0 人点赞
