前面的文章中已经介绍了Mysql的缓存机制,我们在执行一条更新语句时,并不会马上将数据更新到磁盘上,而是将更新的操作写入Buffer Pool中,当事务完成后会异步地把数据更新到磁盘中。
当内存数据页跟磁盘数据页内容不一致的时候,我们称这个内存页为“脏页”。内存数据写入到磁盘后,内存和磁盘上的数据页的内容就一致了,称为“干净页”。出现了脏页,数据库就需要将新版本的页从 Buffer Pool 中刷新到磁盘。
如果每次一个页面发生变化,就将新的页刷新到磁盘上,无疑开销会非常的大。Mysql引入了 Checkpoint(检查点),其主要解决以下问题:
- 缩短数据库恢复时间,因为 CheckPoint 之前的页已经刷新回磁盘,故数据库只需对 CheckPoint 后的重做日志进行恢复
- 当缓冲池不够用时,利用 LRU 算法淘汰一些数据页时,如果该数据页是脏页,则需要将脏页刷新到磁盘
- 重做日志不可用时(redolog写满了),刷新脏页
当触发Checkpoint时会将脏页刷入磁盘。Checkpoint发生的时间、条件及脏页的选择非常重要。Checkpoint分两种 Sharp Checkpoint 和 Fuzzy Checkpoint
Sharp Checkpoint
当数据库正常关闭的情况下会触发 Sharp Checkpoint,将所有脏页刷新到磁盘。但是在数据库运行时使用这种方式性能会受到一定的影响,因为这种方式会一次性把所有的脏页都刷新进磁盘。
Fuzzy Checkpoint
相比于 Sharp Checkpoint,这种方式可以只刷新一部分脏页,而不需要一次性刷新全部脏页。Fuzzy Checkpoint 的触发通常由以下几种情况:
- redo-log写满了
在 InnoDB 中对重做日志的设计是循环使用的,并不是让其无限增大。当 InnoDB 的 redo log 写满了,会触发 Async/Sync Checkpoint,把一部分 “脏页” 刷到磁盘上(Async Checkpoint会阻塞发现问题的用户查询线程,Sync Checkpoint会阻塞所有的用户查询线程,两种不同的刷盘方式由不同的阈值触发)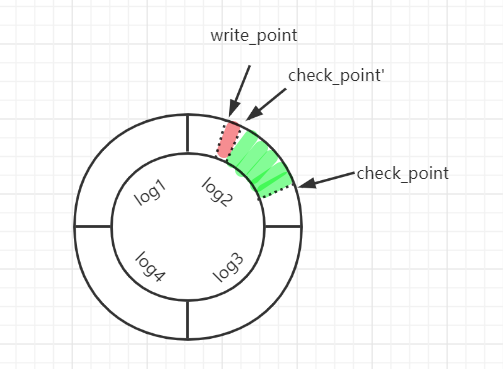
这种情况要尽量少发生,因为刷新过程中数据库会出现阻塞用户的查询请求的情况,所以 redo-log 的大小对数据库性能有这很大的影响。
- 如果redo-log 设置得很大,服务器 crash 后恢复数据需要很长时间
- 如果redo-log 设置得很小,会频繁触发刷盘操作
- Buffer Pool空闲页不够
Innodb引擎通过 LRU 算法来维护 Buffer Pool 中的空闲页数量(保证至少有100个左右的空闲页),当Buffer Pool 中的空闲页不够时,就会将LRU列表中尾端的数据页移除。若有脏数据页,则需要进行刷盘。
- 脏数据页过多
通过 innodb_max_dirty_pages_pct 来控制当Buffer Pool 中脏页到达一定比例,进行刷盘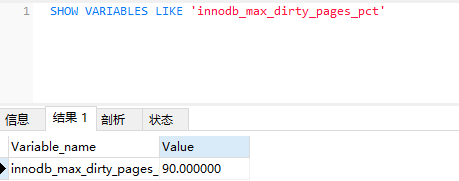
当Buffer Pool中的脏页占据90%时,会进行刷盘
- 后台线程刷盘
Innodb中有一个非常重要的后台线程 Master Thread ,该线程内部会不断地循环,主要负责将各种缓冲池中的数据异步刷新到磁盘中,包括脏页的刷新、redolog Buffer刷盘、合并插入缓冲…….

若有收获,就点个赞吧
0 人点赞
