索引是帮助 Mysql 高效获取数据的有序的数据结构(本质就是一个数据结构),能够实现查找的数据结构有很多,最常见的就是 B+Tree。
Innodb 如何存储数据
MySQL 支持多种存储引擎,不同的存储引擎,存储数据的方式也是不同的,我们最常使用的是 InnoDB 存储引擎。在 InnoDB 中数据是按 “数据页” 为单位来读写的,也就是说,当需要读一条记录的时候,并不是将这个记录本身从磁盘读出来,而是以页为单位,将其整体读入内存。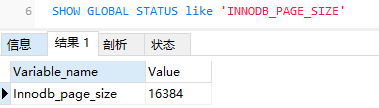
InnoDB 数据页的默认大小是 16KB,意味着数据库每次读写都是以 16KB 为单位,一次最少从磁盘中读取 16K 的内容到内存中,一次最少把内存中 16K 内容刷新到磁盘中。
数据页包括七个部分,结构如下图: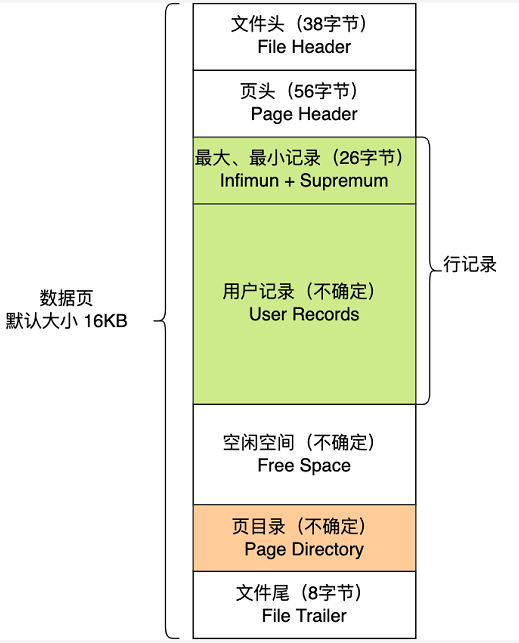
这 7 个部分的作用如下图:
- 文件头:表示页的信息
- 页头:表示页的状态信息
- 最小、最大记录:两个虚拟的伪记录,分别表示页中最大记录和最小记录
- 用户记录:存储行记录内容
- 空闲空间:表示页中还没被使用的空间
- 页目录:存储用户记录的相对位置,对记录起到索引作用
- 文件尾:校验页是否完整
File Header 字段用于记录 Page 的头信息,其中比较重要的是 FIL_PAGE_PREV 和 FIL_PAGE_NEXT 字段,通过这两个字段,我们可以找到该页的上一页和下一页,实际上所有页通过两个字段可以形成一条双向链表。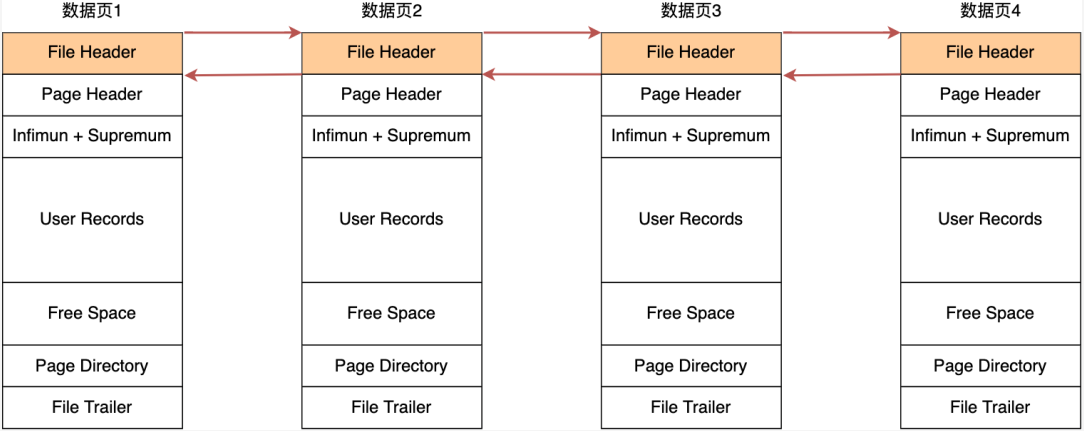
Infimum 和 Supremum 是两个伪行记录,Infimum(下确界)记录比该页中任何主键值都要小的值,Supremum (上确界)记录比该页中任何主键值都要大的值,这个伪记录分别构成了页中记录的边界。数据页的主要作用是存储记录,也就是数据库的数据,所以重点说一下数据页中的用户记录(User Records) 是怎么组织数据的。
数据页中的记录按照主键顺序组成单向链表,单向链表的特点就是插入、删除非常方便,但是检索效率不高,最差的情况下需要遍历链表上的所有节点才能完成检索。因此,数据页中有一个页目录(Page Directory),起到记录的索引作用,就像我们书那样,针对书中内容的每个章节设立了一个目录,想看某个章节的时候,可以查看目录,快速找到对应的章节的页数,而数据页中的页目录就是为了能快速找到记录。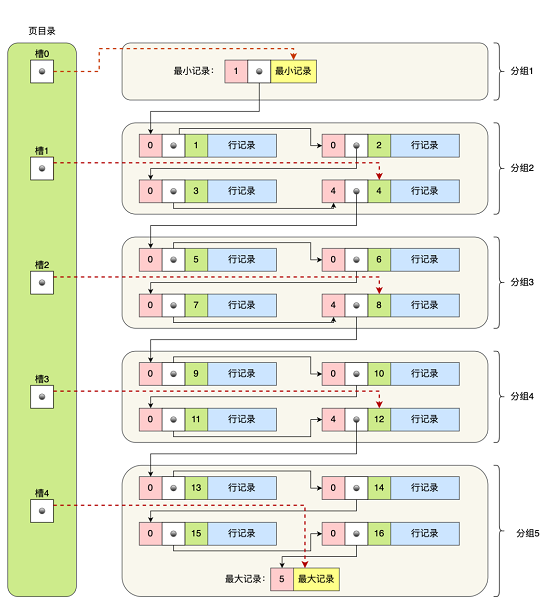
页目录创建的过程如下:
- 将所有的记录划分成几个组,这些记录包括最小记录和最大记录,但不包括标记为“已删除”的记录;
- 每个记录组的最后一条记录就是组内最大的那条记录,并且最后一条记录的头信息中会存储该组一共有多少条记录,作为 n_owned 字段(上图中粉红色字段)
- 页目录用来存储每组最后一条记录的地址偏移量,这些地址偏移量会按照先后顺序存储起来,每组的地址偏移量也被称之为槽(slot),每个槽相当于指针指向了不同组的最后一个记录。
从图可以看到,页目录就是由多个槽组成的,槽相当于分组记录的索引。然后,因为记录是按照主键值从小到大排序的,所以我们通过槽查找记录时,可以使用二分法快速定位要查询的记录在哪个槽(哪个记录分组),定位到槽后,再遍历槽内的所有记录,找到对应的记录,无需从最小记录开始遍历整个页中的记录链表。以上面那张图举个例子,5 个槽的编号分别为 0,1,2,3,4,我想查找主键为 11 的用户记录:
- 先二分得出槽中间位是 (0+4)/2=2 ,2号槽里最大的记录为 8。因为 11 > 8,所以需要从 2 号槽后继续搜索记录;
- 再使用二分搜索出 2 号和 4 槽的中间位是 (2+4)/2= 3,3 号槽里最大的记录为 12。因为 11 < 12,所以主键为 11 的记录在 3 号槽里;
- 再从 2 号槽指向的主键值为 8 记录开始向下搜索 3 次,定位到主键为 11 的记录,取出该条记录的信息即为我们想要查找的内容。
在 InnoDB 中对每个分组中的记录条数都是有规定的,槽内的记录就只有几条:
- 第一个分组中的记录只能有 1 条记录;
- 最后一个分组中的记录条数范围只能在 1-8 条之间;
- 剩下的分组中记录条数范围只能在 4-8 条之间。
B+树索引
上面我们都是在说一个数据页中的记录检索,因为一个数据页中的记录是有限的,且主键值是有序的,所以通过对所有记录进行分组,然后将组号(槽号)存储到页目录,使其起到索引作用,通过二分查找的方法快速检索到记录在哪个分组,来降低检索的时间复杂度。但是,当我们需要存储大量的记录时,就需要多个数据页,这时我们就需要考虑如何建立合适的索引,才能方便定位记录所在的页。
为什么不采用搜索(平衡)二叉树?
通过上面的了解,InnoDB 中数据是按 “数据页” 为单位来读写的,若一次IO只需要查找的数据量非常少,会大大浪费资源。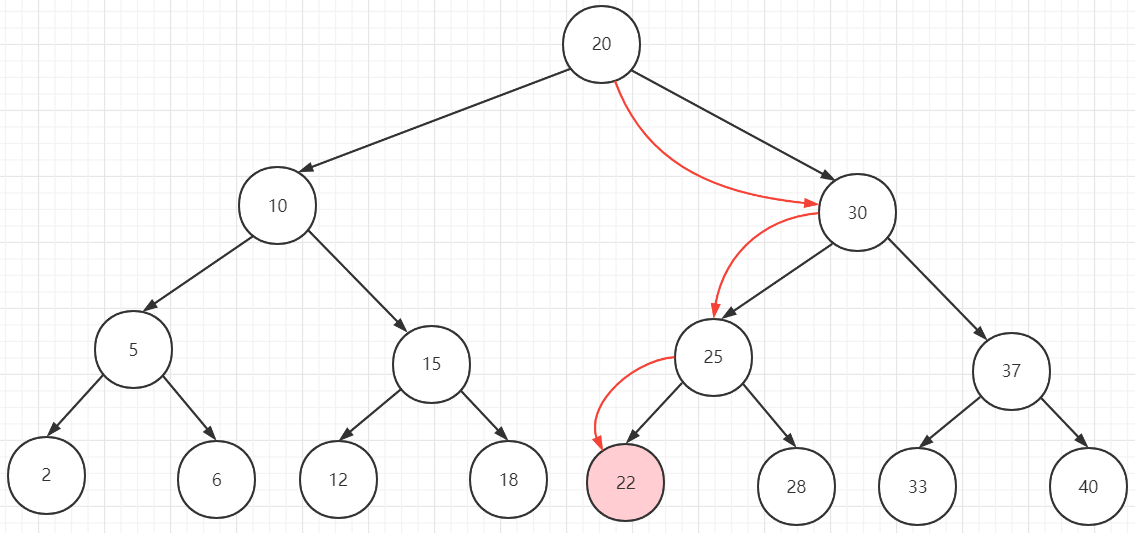
上图所示,当我们需要查找值为 22 的元素,需要经历 3 次 IO。虽然搜索二叉树的查询时间复杂度为 O(logN),但是当数据量越大,树的深度也越大,所需要的查找的次数也越多。Mysql 数据存储在磁盘中,而且在磁盘上是随机分布的(随机IO),一次磁盘IO所需的时间相比于内存IO非常久。
总结:
- 数据量越多,树的深度越大,查找次数多
- 磁盘 IO 查找慢
- 每次查询的数据量少,浪费资源
优化:减少磁盘IO次数,每次磁盘IO查找的数据量尽量要多
B-Tree
两个叉的树就能实现折半查询,理论可以提高一倍性能,那么多个叉是不是能提高更多倍性能?下面以三叉树为例: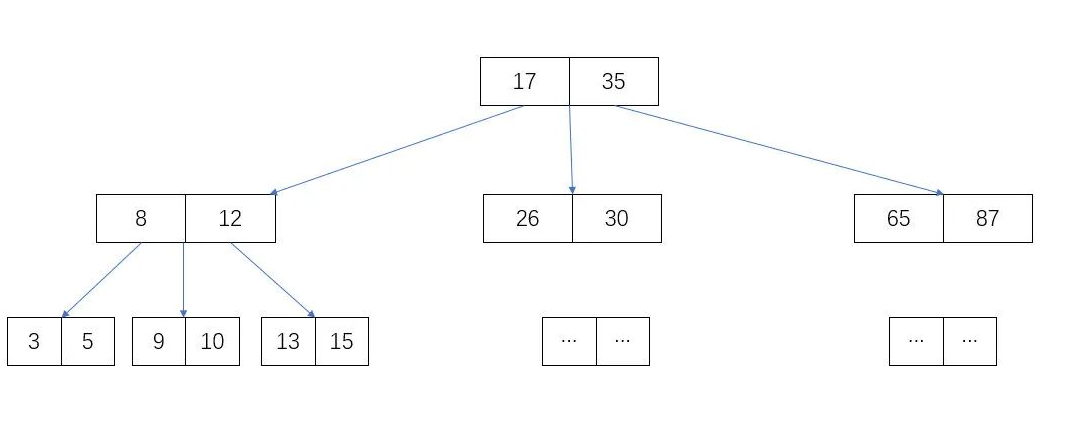
假设,从上图中查找 10 这个数,步骤如下:
- 找到根节点,对比 10 与 17 和 35 的大小,发现 10 < 17 在左子节点,也就是第 2 层节点;
- 从根节点的指针,找到左子节点,对比 10 与 8 和 12 的大小,发现 8 < 10 < 12,数据在当前节点的中间子节点,也就是第 3 层节点;
- 通过上步节点的指针,找到中间子节点(第 3 层节点),对比 10 与 9 和 10 的大小,发现 9 < 10 == 10,因此找到当前节点的第二数即为结果。
多叉树是在二分查找树的基础上,增加单个节点的数据存储数量,同时增加了树的子节点数,一次计算可以把查找范围缩小更多。
M阶BTree的常见性质:
- 每个节点最多有M个子节点,一个节点最多存M-1个数据
- 若根节点不是叶子节点,则至少有2个孩子节点
- 所有叶子节点的深度相同
- 叶子节点的数据从左到右递增
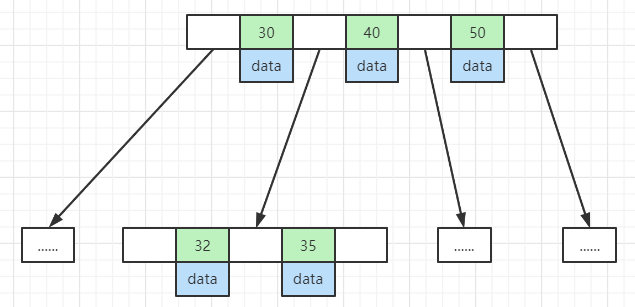
B-Tree 的缺点就是把索引值和数据同时存放在一起,每次为了查找对比计算,需要把数据加载到内存以及 CPU 高速缓存中时,都要把索引数据和无关的业务数据全部查出来。当业务数据的大小可能远远超过了索引数据的大小,本来一次就可以把所有索引数据加载进来,现在却要多次才能加载完。如果所对比的节点不是所查的数据,那么这些加载进内存的业务数据就毫无用处,全部抛弃。
B+Tree
B+Tree 在 B-Tree 的基础上,把所有的数据都存在叶子节点,非叶子节点不存数据(同样是一页空间大小,存放的索引越多,树的高度就越低);且叶子节点包含所有索引字段,因此索引区间左闭右开(或左开右闭),且所有叶子节点组成一个双向链表,如下图: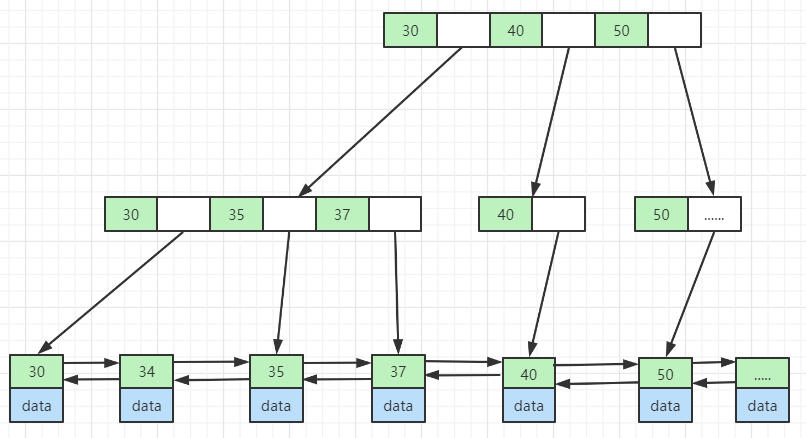
InnoDB 里的 B+ 树中的每个节点都是一个数据页,如果以 bigint 数据类型作为索引字段(占 8Byte),按照指针占 8Byte 来算,一页数据(16KB)可以存 1024 个数据,若B+Tree 的层数为3,则可以存 102410241024 个数据,由此看来,B+Tree 数据结构在能够存储大量数据的同时不会造成树的深度过大。(字符串类型的索引可以通过编码表转换成数字)
联合索引如何构建?
联合索引会把联合的字段(如果是非数字类型则先转换为数字)按顺序拼接,每个字段具体分配多少位按照字段的数据类型来定。这解释了联合索引的最左匹配原则,当断掉了联合索引的第一个字段,在索引树中根本找不到该值,索引失效。同理,当断掉了某个字段后,该字段后面的所有字段都不会走索引。
不同存储引擎的索引
索引可以分成聚集索引和非聚集索引(二级索引),它们区别就在于叶子节点存放的是什么数据。
- 聚集索引的叶子节点存放的是实际数据,所有完整的用户记录都存放在聚集索引的叶子节点;
- 二级索引的叶子节点存放的是主键值,而不是实际数据。
MYISAM
MYISAM中有两种文件,”.MYD“文件用来存储数据,”.MYI“文件用来存放索引信息。MYISAM存储引擎的索引是非聚集索引(索引与数据分开存储)
其索引树的根节点存放的不是数据,而是数据的磁盘地址,即”.MYD”文件中数据的地址,(主键索引的根节点和非主键索引根节点存的都是数据地址)。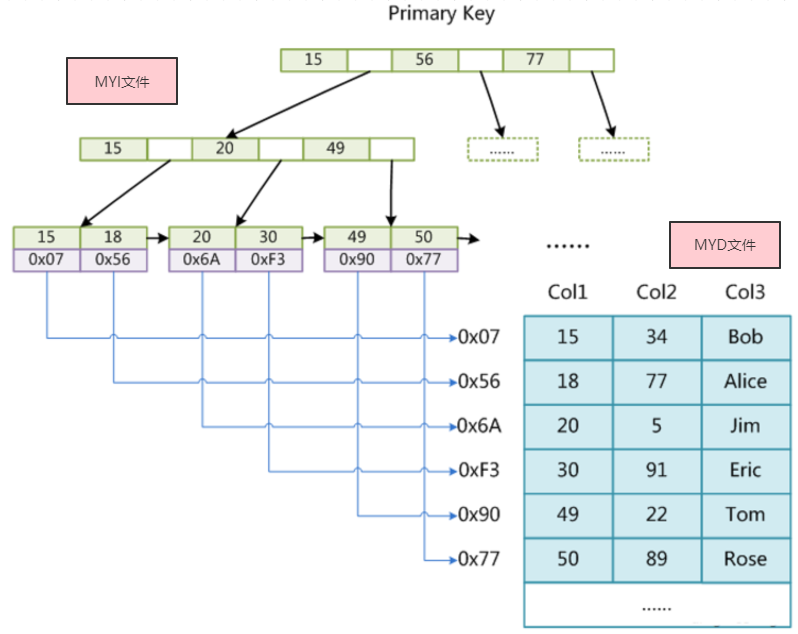
INNODB
INNODB存储引擎用”.ibd”文件来存储主键索引和数据,索引树的根节点存放的是该主键值所对应的数据行(聚集索引)。非主键索引(跟MYISAM的索引一样也是非聚集索引)的根节点存放的是主键的值。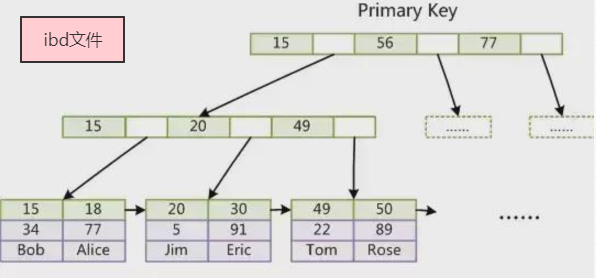
若该表没有主键索引,Innodb会将选择一列数据都不相同的字段来构建索引树;若上述都没有则会自动创建一个隐藏列来构建索引树。INNODB引擎推荐每个表都创建一个主键。
为什么推荐使用一个自增的整形数字作为主键?
- 整形相比于UUID来讲数据量较小,一个数据页可以存放更多的索引。
- B+Tree索引是有序的,当插入非自增的数据时,需要将部分数据往后挪动。更糟糕的情况是,当前所在页的数据已满需要进行分裂时,对B+树平衡操作有较大性能影响(插入的数据是自增的只会不断往后面增加,分裂时基本不用大幅度平衡)

若有收获,就点个赞吧
0 人点赞
