今天我们来聊一聊 “order by” 是怎么执行的。我们先准备一张表:
CREATE TABLE `employees` (`id` int(11) NOT NULL AUTO_INCREMENT,`name` varchar(24) NOT NULL DEFAULT '' COMMENT '姓名',`age` int(11) NOT NULL DEFAULT '0' COMMENT '年龄',`position` varchar(20) NOT NULL DEFAULT '' COMMENT '职位',`hire_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '入职时间',PRIMARY KEY (`id`),KEY `idx_name_age_position` (`name`,`age`,`position`) USING BTREE) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8 COMMENT='员工记录表';
其中给表中的 name、age、position 字段创建一个联合索引,插入一些数据
INSERT INTO employees(name,age,position,hire_time) VALUES('LiLei',22,'manager',NOW());
INSERT INTO employees(name,age,position,hire_time) VALUES('HanMeimei', 23,'dev',NOW());
INSERT INTO employees(name,age,position,hire_time) VALUES('Lucy',23,'dev',NOW());
drop procedure if exists insert_emp;
delimiter;;
create procedure insert_emp()
begin
declare i int;
set i=1;
while(i<=100000)do
insert into employees(name,age,position) values(CONCAT('sda',i),i,'dev');
set i=i+1;
end while;
end;;
delimiter ;
call insert_emp();
单路排序
执行以下语句
EXPLAIN SELECT * FROM employees WHERE name = 'LiLei' ORDER BY position

Extra 这个字段中的 “Using filesort” 表示的就是需要排序,MySQL 会给每个线程分配一块内存用于排序,称为 sort_buffer。该sql语句的执行流程大致如下:
- 从索引 name 找到第一个满足 name = “LiLei” 条件的主键 id
- 根据主键 id 取出整行,取出所有字段的值,存入 sort_buffer 中
- 从索引name找到下一个满足 name = “LiLei” 条件的主键 id
- 重复步骤 2、3 直到不满足 name = “LiLei”
- 对 sort_buffer 中的数据按照字段 position 进行排序
- 返回结果给客户端
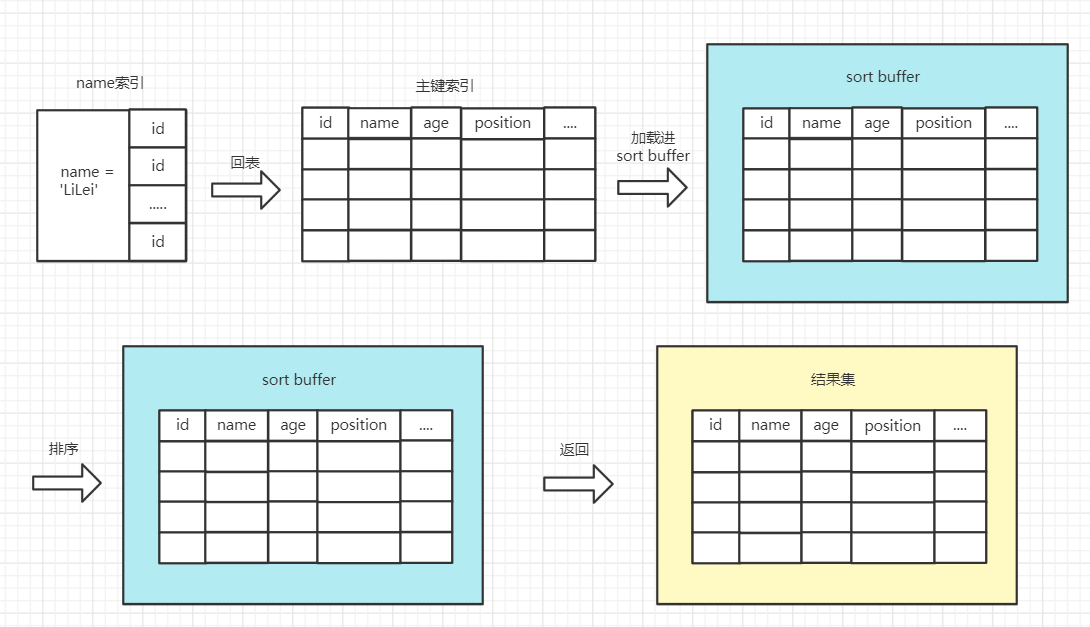
单路排序,也称全字段排序,会把查询到的所有结果都加载进 sort_buffer 中进行排序。sort_buffer_size,就是 MySQL 为排序开辟的内存(sort_buffer)的大小。如果要排序的数据量小于 sort_buffer_size,排序就在内存中完成。但如果排序数据量太大,内存放不下,则不得不利用磁盘临时文件辅助排序。
双路排序
在上面这个算法过程里面,只对原表的数据读了一遍,剩下的操作都是在 sort_buffer 和临时文件中执行的。但这个算法有一个问题,就是如果查询要返回的字段很多的话,那么 sort_buffer 里面要放的字段数太多,这样内存里能够同时放下的行数很少,要分成很多个临时文件,排序的性能会很差。
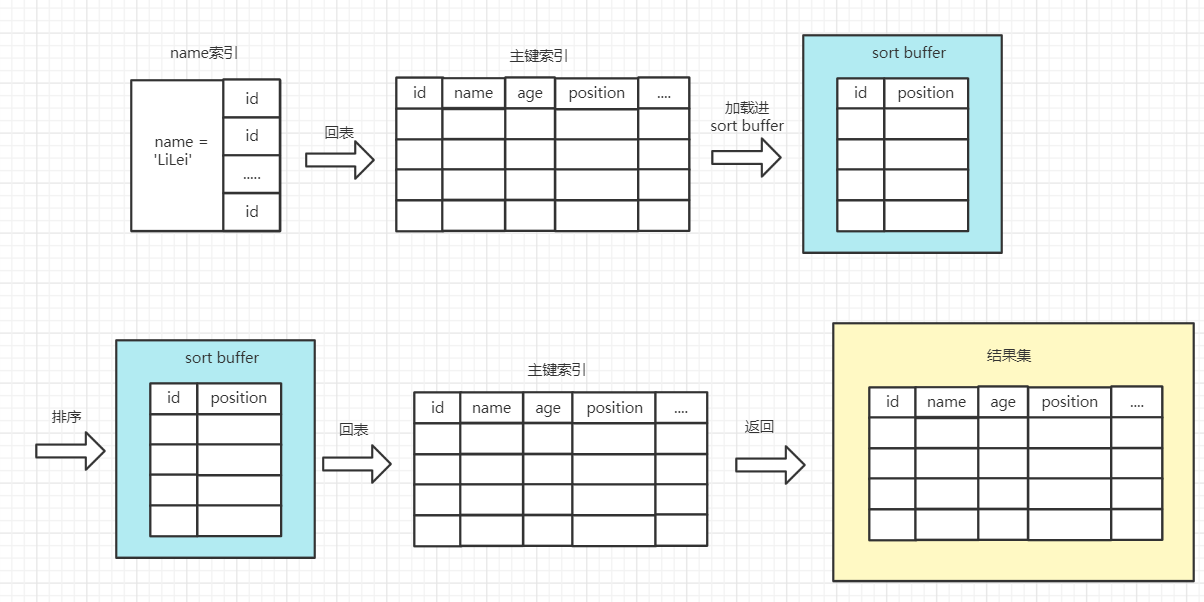
双路排序,会根据相应的条件取出相应的排序字段和可以直接定位行数据的行主键 ID,只会把这两个字段加载进 sort_buffer 中,然后在 sort buffer 中进行排序,排序完后需要再次取回其它需要的字段。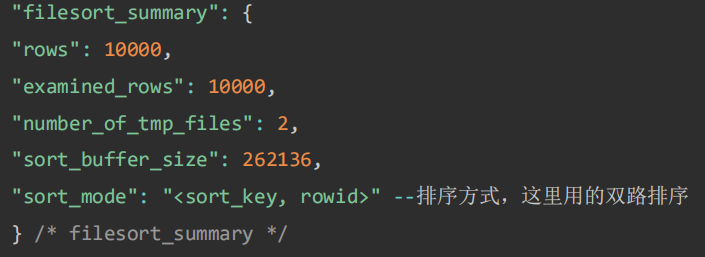
因为放入 sort_buffer 的字段,只有要排序的列(即 position 字段)和主键 id,排序的结果就因为少了 city 和 age 字段的值,不能直接返回了,需要重新返回主键索引树获取返回结果,所以执行流程为:
- 从索引 name 找到第一个满足 name = “LiLei” 的主键id
- 根据主键 id 取出整行,把排序字段 position 和主键 id 这两个字段放到 sort buffer
- 从索引 name 取下一个满足 name = “zhuge” 记录的主键 id
- 重复 3、4 直到不满足 name = “zhuge”
- 对 sort_buffer 中的字段 position 和主键 id 按照字段 position 进行排序
- 遍历排序好的 id 和字段 position,按照 id 的值回到原表中取出所有字段的值返回给客户端
MySQL 通过比较系统变量 max_length_for_sort_data(默认1024字节) 的大小和需要查询的字段总大小来判断使用哪种排序模式。
- 如果字段的总长度小于max_length_for_sort_data ,那么使用 单路排序模式;
- 如果字段的总长度大于max_length_for_sort_data ,那么使用 双路排序模式。
两种排序的对比
如果 MySQL 实在是担心排序内存太小,会影响排序效率,才会采用 rowid 排序算法,这样排序过程中一次可以排序更多行,但是需要再回到原表去取数据。
如果 MySQL 认为内存足够大,会优先选择全字段排序,把需要的字段都放到 sort_buffer 中,这样排序后就会直接从内存里面返回查询结果了,不用再回到原表去取数据。
这也就体现了 MySQL 的一个设计思想:如果内存够,就要多利用内存,尽量减少磁盘访问。(注意:如果全部使用sort_buffer内存排序一般情况下效率会高于磁盘文件排序,但不能因为这个就随便增大sort_buffer(默认1M),mysql很多参数设置都是做过优化的,不要轻易调整)
order by 优化策略
联合索引
MySQL支持两种方式的排序filesort和index,Using index是指MySQL扫描索引本身完成排序,index 效率高,filesort效率低。
order by满足两种情况会使用Using index。
- order by语句使用索引最左前列
- 使用where子句与order by子句条件列组合满足索引最左前列
case1
EXPLAIN SELECT * FROM employees WHERE name = 'LiLei' ORDER BY position

从explain的执行结果来看:key_len=74,查询使用了name索引,由于用了position进行排序,跳过了age,出现了Using filesort。
case2
EXPLAIN SELECT * FROM employees WHERE name = 'LiLei' AND position = 'manager' ORDER BY age

利用最左前缀法则:中间字段不能断,因此查询用到了name索引,从key_len=74也能看出,age 索引列用在排序过程中,因为 Extra 字段里没有 using filesort(虽然查询过程没有用到age索引,查出来的结果中 age 的值已经是有序的,所以不用再进行排序)
覆盖索引
覆盖索引是指,索引上的信息足够满足查询请求,不需要再回到主键索引上去取数据。
case3
EXPLAIN SELECT * FROM employees WHERE name > 'l' ORDER BY 'name'

这里没走 name 索引的原因是,Mysql 觉得查询数据量太大,优化器通过判断,直接从主键索引中全表扫描然后进行排序的速度比在二级索引中直接查询的速度还要快(走二级索引还需要回表操作)
case4
EXPLAIN SELECT name,age, position FROM employees WHERE name > 'l' ORDER BY 'name'

通过覆盖索引则可以直接从二级索引上查询得到结果,不用进行回表操作

若有收获,就点个赞吧
0 人点赞
