应用系统分层架构,为了加速数据访问,会把最常访问的数据,放在缓存(cache)里,避免每次都去访问数据库。MySQL作为一个存储系统,同样具有缓冲池(buffer pool)机制,以避免每次查询数据都进行磁盘IO。
InnoDB 采取了 “Write Ahead Log” 策略,即当事务提交时,先写重做日志,在修改数据页。当系统发生宕机而导致数据丢失的时候,可以通过重做日志来恢复。
通过命令 SHOW VARIABLES LIKE ‘innodb_buffer_pool_size 查看buffer pool大小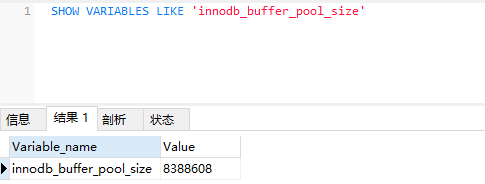
Mysql中三种重要日志文件
重做日志和回滚日志与事务操作息息相关,二进制日志对磁盘数据恢复有关,这三种日志,对理解MySQL中的事务操作有着重要的意义。
undo log(回滚日志)
保存了事务发生之前的数据的一个版本链,可以用于回滚,同时可以提供多版本并发控制下的读(MVCC),也即非锁定读。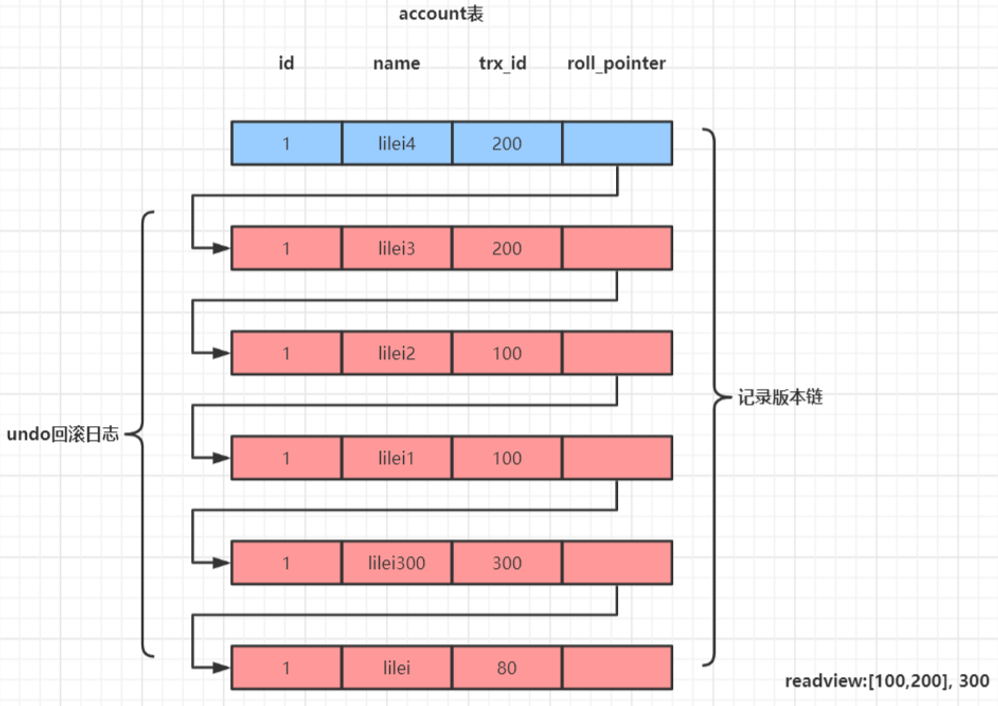
redo log(重做日志)
mysql对数据的增删查改都是基于Buffer Pool进行的,当数据还在Buffer Pool中未来得及写入磁盘,而此时服务器宕机了,重启后可以通过 redo log恢复Buffer Pool中的数据,从而等待下次刷盘。
redo-log是Innodb引擎特有的日志文件,每个Innodb存储引擎至少一个重做日志组,每组至少有两个重做日志文件(为了得到更高的可靠性,可以配置多个镜像日志组),同一个日志组中的日志文件大小一致,比如可以配置为一组 4 个文件,每个文件的大小是 1GB。当一个文件写满了可以写入另外一个文件,如果都写满了则重新切换到第一个文件中继续写入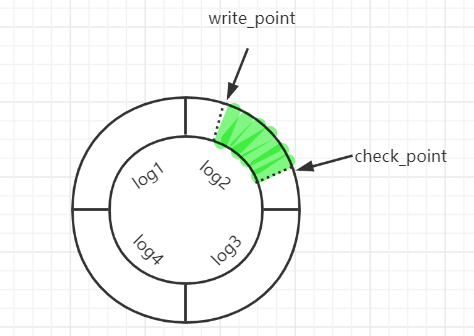
binlog (二进制日志)
用于复制,在主从复制中,从库利用主库上的binlog进行重播,实现主从同步。用于数据库的基于时间点还原被人恶意删除数据库磁盘文件。
随机IO和顺序IO
顺序IO:指读写操作的访问地址连续。在顺序IO访问中,HDD所需的磁道搜索时间显着减少,因为读/写磁头可以以最小的移动访问下一个块。数据备份和日志记录等业务是顺序IO业务。
随机IO:指读写操作时间连续,但访问地址不连续,随机分布在磁盘的地址空间中。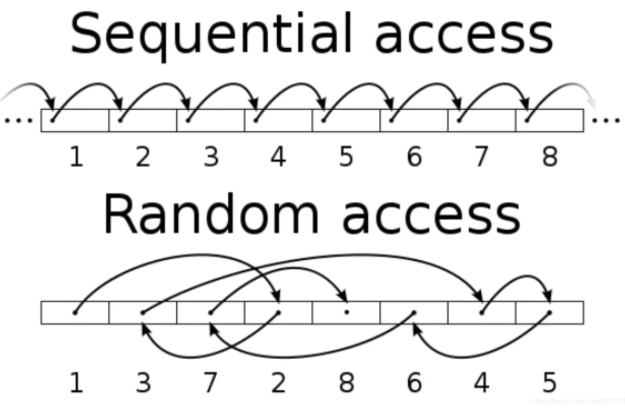
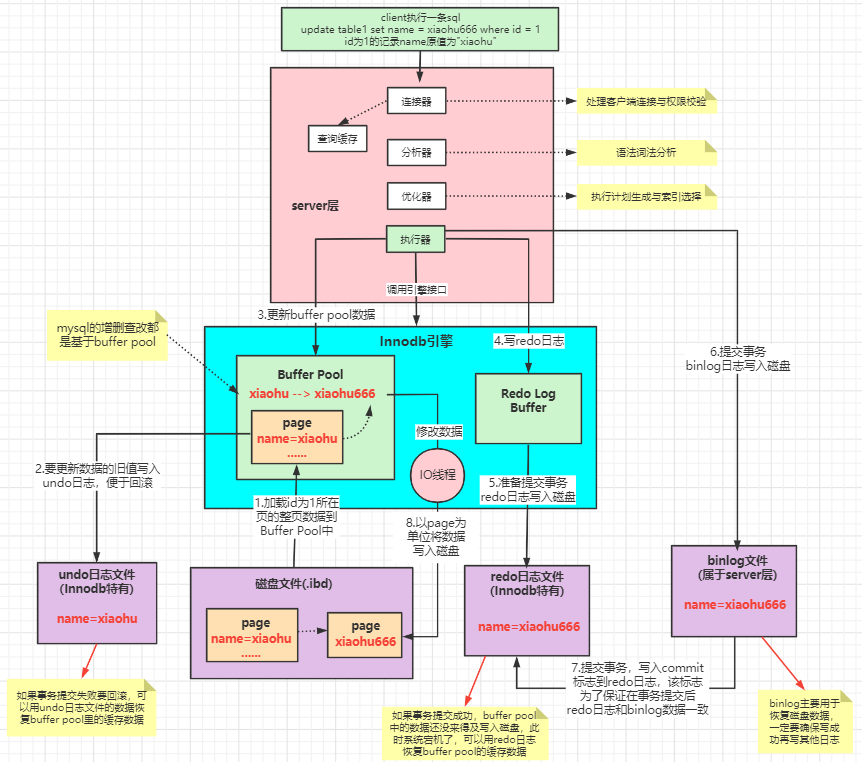
Mysql数据执行过程
如要执行一条更新操作(原来的值为”xiaohu”)
update tabel1 set name = xiaohu666 where id = 1
- 先从磁盘加载原始数据到Buffer Pool中
- 将更新前的旧数据写到undo log中,用于事务回滚
- 将加载到Buffer Pool中的数据更新为新的值
- 执行器往Redo Log Buffer中写入日志
- 事务开始后,随着事务的执行,可以将Redo Log Buffer中的数据逐步写入磁盘redo log 日志文件中
- 事务提交后,一次性将事务中的sql写入到磁盘的bin log日志文件中
- 事务提交后,往redo日志中写入commit标志,保证数据和binlog一致
- 后台线程将Buffer Pool中的数据更新到磁盘上
两阶段提交
由上面分析可知,当事务开始后,可以边执行事务操作边写入redolog,当事务提交后一次性写入binlog,接着为redolog写入一个commit标志,此时事务才算真正提交。
如果不用两阶段提交有什么问题?
- 如果先写 redo log 后写 binlog。假设在 redo log 写完,binlog 还没有写完的时候,MySQL 进程异常重启。由于我们前面说过的,redo log 写完之后,系统即使崩溃,仍然能够把数据恢复回来。但是由于 binlog 没写完服务器 crash,这时候 binlog 里面就没有记录这个语句。因此,之后备份日志的时候,存起来的 binlog 里面就没有这条语句。然后你会发现,如果需要用这个 binlog 来恢复临时库的话,由于这个语句的 binlog 丢失,这个临时库就会少了这一次更新,与原库的值不同。
- 如果先写 binlog 后写 redo log。如果在 binlog 写完之后服务器 crash,由于 redo log 还没写,崩溃恢复以后这个事务无效。但是 binlog 里面已经记录了此次事务的修改,所以,在之后用 binlog 来恢复的时候就多了一个事务出来,与原库的值不同。
可以看到,如果不使用“两阶段提交”,那么数据库的状态就有可能和用它的日志恢复出来的库的状态不一致。
为什么要设计这么一套复杂的机制呢?
因为磁盘随机读写的性能是非常差的(磁盘随机IO),所以直接更新磁盘文件是不能让数据库抗住很高并发的。 Mysql这套机制看起来复杂,但它可以保证每个更新请求都是更新BufferPool(底层通过LRU算法管理缓冲区数据),然后顺序写日志文件,同时还能保证各种异常情况下的数据一致性。 更新内存的性能是极高的,然后顺序写磁盘上的日志文件的性能也是非常高的(磁盘顺序IO),要远高于随机读写磁盘文件。 正是通过这套机制,才能让我们的MySQL数据库在较高配置的机器上每秒可以抗下几干的读写请求。
为什么.ibd文件不能顺序IO而日志文件可以?
日志文件基本上很少出现删除操作,数据非常紧凑,可以直接通过偏移量找到数据。

若有收获,就点个赞吧
0 人点赞
