在日常工作中由于业务需要需要用 JOIN 查询是很常见的,前面文章中已经介绍了 JOIN 查询是如何执行和单表查询成本分析,这篇文章我们就来了解一下连表查询成本到底是如何计算的。
我们先创建两张一模一样的表,后面所以的例子演示都是基于这两张表。
CREATE TABLE `order_exp` (`id` bigint(255) NOT NULL AUTO_INCREMENT COMMENT '订单主键',`order_no` varchar(50) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NOT NULL COMMENT '订单号',`order_note` varchar(100) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NOT NULL COMMENT '订单描述',`insert_time` datetime(0) NOT NULL DEFAULT CURRENT_TIMESTAMP(0) ON UPDATE CURRENT_TIMESTAMP(0) COMMENT '订单插入时间',`expire_duration` bigint(255) NOT NULL COMMENT '订单的过期时长,单位秒',`expire_time` datetime(0) NOT NULL COMMENT '订单过期时间',`order_status` smallint(6) NOT NULL COMMENT '订单的状态,0:未支付;:已支付;-1:已过期,关闭',PRIMARY KEY (`id`) USING BTREE,UNIQUE INDEX `u_idx_day_status`(`insert_time`, `expire_time`, `order_status`) USING BTREE,INDEX `idx_order_no`(`order_no`) USING BTREE,INDEX `idx_expire_time`(`expire_time`) USING BTREE) ENGINE = InnoDB AUTO_INCREMENT = 1 CHARACTER SET = utf8mb4 COLLATE = utf8mb4_general_ci ROW_FORMAT = Dynamic;CREATE TABLE `order_exp2` (`id` bigint(255) NOT NULL AUTO_INCREMENT COMMENT '订单主键',`order_no` varchar(50) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NOT NULL COMMENT '订单号',`order_note` varchar(100) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NOT NULL COMMENT '订单描述',`insert_time` datetime(0) NOT NULL DEFAULT CURRENT_TIMESTAMP(0) ON UPDATE CURRENT_TIMESTAMP(0) COMMENT '订单插入时间',`expire_duration` bigint(255) NOT NULL COMMENT '订单的过期时长,单位秒',`expire_time` datetime(0) NOT NULL COMMENT '订单过期时间',`order_status` smallint(6) NOT NULL COMMENT '订单的状态,0:未支付;:已支付;-1:已过期,关闭',PRIMARY KEY (`id`) USING BTREE,UNIQUE INDEX `u_idx_day_status`(`insert_time`, `expire_time`, `order_status`) USING BTREE,INDEX `idx_order_no`(`order_no`) USING BTREE,INDEX `idx_expire_time`(`expire_time`) USING BTREE) ENGINE = InnoDB AUTO_INCREMENT = 1 CHARACTER SET = utf8mb4 COLLATE = utf8mb4_general_ci ROW_FORMAT = Dynamic;
什么是 Condition filtering?
前面在 join 查询如何执行 文章中说过,MySQL 中连接查询在走索引的情况下通常采用的是嵌套循环连接(NLJ)算法,驱动表会被访问一次,被驱动表可能会被访问多次,所以对于两表连接查询来说,它的查询成本由下边两个部分构成:
- 单次查询驱动表的成本
- 多次查询被驱动表的成本 (具体查询的次数取决于驱动表查询结果集中有多少条记录)
对驱动表进行查询后得到的记录条数称之为驱动表的扇出(fanout)。很显然驱动表的扇出值越小,对被驱动表的查询次数也就越少,连接查询的总成本也就越低。当查询优化器想计算整个连接查询所使用的成本时,就需要计算出驱动表的扇出值。下面我们以几个查询例子逐一来说明:
查询一:
SELECT * FROM order_exp AS s1 INNER JOIN order_exp2 AS s2;
假设使用s1表作为驱动表,该查询没有添加任何条件,很显然对驱动表的单表查询只能使用全表扫描的方式执行,驱动表的扇出值也很明确,那就是驱动表中有多少记录,扇出值就是多少。统计数据中 s1表的记录行数是10573,也就是说优化器就直接会把 10573 当作s1表的扇出值。
查询二:
SELECT * FROM order_exp AS s1 INNER JOIN order_exp2 AS s2
WHERE s1.expire_time> '2021-03-22 18:28:28' AND s1.expire_time<= '2021-03-22 18:35:09'
仍然假设s1表是驱动表的话,很显然对驱动表的单表查询可以使用idx_expire_time索引执行查询。此时范围区间 ( ‘2021-03-22 18:28:28’, ‘2021-03-22 18:35:09’) 中有多少条记录,那么扇出值就是多少。
查询三:
SELECT * FROM order_exp AS s1 INNER JOIN order_exp2 AS s2
WHERE s1.order_note > 'xyz'
本查询和查询一类似,只不过对于驱动表s1多了一个 order_note > ‘xyz’ 的搜索条件。查询优化器又不会真正的去执行查询,所以它只能猜这 10573 记录里有多少条记录满足 order_note > ‘xyz’ 条件。
查询四:
SELECT * FROM order_exp AS s1 INNER JOIN order_exp2 AS s2
WHERE s1.expire_time> '2021-03-22 18:28:28'
AND s1.expire_time<= '2021-03-22 18:35:09'
AND s1.order_note > 'xyz'
本查询和查询二类似,只不过对于驱动表s1也多了一个 order_note > ‘xyz’ 的搜索条件。不过因为本查询可以使用 idx_expire_time 索引,所以只需要从符合二级索引范围区间的记录中猜有多少条记录符合 order_note > ‘xyz’ 条件。
查询五:
SELECT * FROM order_exp AS s1 INNER JOIN order_exp2 AS s2
WHERE s1.expire_time> '2021-03-22 18:28:28'
AND s1.expire_time<= '2021-03-22 18:35:09'
AND s1.order_no IN ('DD00_6S', 'DD00_9S', 'DD00_10S')
AND s1.order_note > 'xyz';
本查询和查询四类似,不过在驱动表s1选取idx_expire_time索引执行查询后,优化器需要从符合二级索引范围区间的记录中猜有多少条记录符合下边两个条件:order_no IN (‘DD00_6S’, ‘DD00_9S’, ‘DD00_10S’) ,order_note > ‘xyz
上面说了这么多中情况,其实就是想表达在这两种情况下计算驱动表扇出值时需要靠猜:
- 如果使用的是全表扫描的方式执行的单表查询,那么计算驱动表扇出时需要猜满足搜索条件的记录到底有多少条。
- 如果使用的是索引执行的单表扫描,那么计算驱动表扇出的时候需要猜满足除使用到对应索引的搜索条件外的其他搜索条件的记录有多少条。
MySQL把这个猜的过程称之为 Condition filtering。当然,这个过程可能会使用到索引,也可能使用到统计数据,整个评估过程非常复杂。在MySQL 5.7 之前的版本中,查询优化器在计算驱动表扇出时,如果是使用全表扫描的话,就直接使用表中记录的数量作为扇出值,如果使用索引的话,就直接使用满足范围条件的索引记录条数作为扇出值。
在MySQL 5.7中,MySQL引入了这个condition filtering的功能,就是还要猜一猜剩余的那些搜索条件能把驱动表中的记录再过滤多少条,其实本质上就是为了让成本估算更精确。我们所说的纯粹瞎猜其实是很不严谨的,MySQL称之为启发式规则。
连表查询成本分析
对于上面分析,我们可以得到连接查询的计算公式:
连接查询总成本 = 单次访问驱动表的成本 + 驱动表扇出数 x 单次访问被驱动表的成本
对于左外连接和右外连接查询来说,它们的驱动表是固定的,所以想要得到最优的查询方案只需要分别为驱动表和被驱动表选择成本最低的访问方法。可是对于内连接来说,驱动表和被驱动表的位置是可以互换的,不同的表作为驱动表最终的查询成本可能不同,也就是需要考虑最优的表连接顺序,然后分别为驱动表和被驱动表选择成本最低的访问方法。
我们以下面查询为例:
SELECT * FROM order_exp AS s1 INNER JOIN order_exp2 AS s2 ON s1.order_no= s2.order_note
WHERE s1.expire_time> '2021-03-22 18:28:28' AND s1.expire_time<= '2021-03-22 18:35:09'
AND s2.expire_time> '2021-03-22 18:35:09' AND s2.expire_time<= '2021-03-22 18:35:59'
该查询可以选择的连接顺序有两种:
- s1连接s2,也就是s1作为驱动表,s2作为被驱动表。
- s2连接s1,也就是s2作为驱动表,s1作为被驱动表。
使用s1作为驱动表
分析对于驱动表的成本最低的执行方案,首先看一下涉及 s1 表单表的搜索条件有哪些:
s1.expire_time> ‘2021-03-22 18:28:28’ AND s1.expire_time<= ‘2021-03-22 18:35:09’
所以这个查询可能使用到idx_expire_time索引,从全表扫描和使用 idx_expire_time 这两个方案中选出成本最低的那个,很显然使用idx_expire_time执行查询的成本更低些。然后分析对于被驱动表的成本最低的执行方案,此时涉及被驱动表 s2 的搜索条件就是:
- s2.order_note = 常数(这是因为对驱动表s1结果集中的每一条记录,都需要进行一次被驱动表s2的访问,此时那些涉及两表的条件现在相当于只涉及被驱动表s2了)
- s2.expire_time> ‘2021-03-22 18:35:09’ AND s2.expire_time<= ‘2021-03-22 18:35:59’
很显然,第一个条件由于 order_note 没有用到索引,所以并没有什么用,此时访问 s2 表时可用的方案也是全表扫描和使用 idx_expire_time 两种,假设使用 idx_expire_time 的成本更小。 所以此时使用s1作为驱动表时的总成本就是(暂时不考虑使用join buffer对成本的影响):
使用 idx_expire_time 访问 s1 的成本 + s1 的扇出 × 使用 idx_expire_time 访问 s2 的成本
使用s2作为驱动表
分析对于驱动表的成本最低的执行方案首先看一下涉及s2表单表的搜索条件有哪些:
s2.expire_time> ‘2021-03-22 18:35:09’ AND s2.expire_time<= ‘2021-03-22 18:35:59’
所以这个查询可能使用到idx_expire_time索引,从全表扫描和使用idx_expire_time这
两个方案中选出成本最低的那个,假设使用 idx_expire_time 执行查询的成本更低些。
然后分析对于被驱动表的成本最低的执行方案,此时涉及被驱动表s1的搜索条件就是:
- s1.order_no = 常数
- s1.expire_time> ‘2021-03-22 18:28:28’ AND s1.expire_time<= ‘2021-03-22 18:35:09’
这时就很有趣了,s1 表中可用的索引有 idx_order_no 和 idx_expire_time,使用idx_order_no 可以进行 ref 方式的访问,使用 idx_expire_time 可以使用 range 方式的访问那么优化器需要从全表扫描、使用idx_order_no、使用idx_expire_time这几个方案里选出一个成本最低的方案。
这里有个问题,因为idx_expire_time 的范围区间是确定的,怎么计算使用 idx_expire_time的成本我们上边已经说过了,而 s1.order_no 作为连接字段,列与列之间的比较在查询前是无法确定的,怎么衡量使用idx_order_no执行查询的成本呢?
其实很简单,直接使用索引统计数据就好了(就是索引列平均一个值重复多少次)。
show index from order_exp
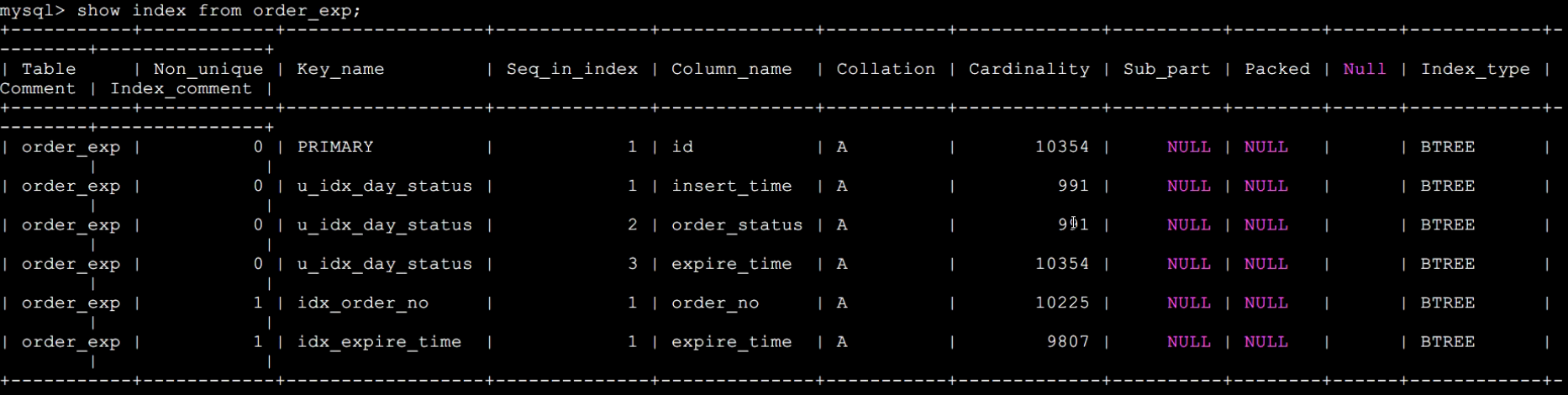
Cardinality 字段代表索引列中不重复值的数量,主键索引该值就为表中记录总数,我们只要使用主键索引的 Cardinality 值除以对应的索引的 Cardinality 值即可得出该索引列平均一个值重复次数。
一般情况下,ref的访问方式要比range成本更低,这里假设使用 idx_order_no进行对 s1 的访问。所以此时使用s2作为驱动表时的总成本就是:
使用idx_expire_time访问s2的成本 + s2的扇出 × 使用idx_order_no访问s1的成本
从上边的计算过程也可以看出来,一般来讲,连接查询成本占大头的其实是 “驱动表扇出数 x 单次访问被驱动表” 的成本,所以我们的优化重点其实是下边这两个部分:
- 尽量减少驱动表的扇出
- 对被驱动表的访问成本尽量低
这一点对于我们实际书写连接查询语句时十分有用,我们需要尽量在被驱动表的连接列 上建立索引,这样就可以使用 ref 访问方法来降低访问被驱动表的成本了。如果可以,被 驱动表的连接列最好是该表的主键或者唯一二级索引列,这样就可以把访问被驱动表的
成本降到更低了。
多表连接查询成本
上面对于两表连接,比如表A和表B连接只有 AB、BA这两种连接顺序。其实相当于2 × 1 = 2种连接顺序。对于三表连接,比如表A、表B、表C进行连接有ABC、ACB、BAC、BCA、CAB、CBA这么6种连接顺序,其实相当于3 × 2 × 1 = 6种连接顺序。对于四表连接的话,则会有4 × 3 × 2 × 1 = 24种连接顺序。对于n表连接的话,则有 n × (n-1) × (n-2) × ··· × 1种连接顺序,就是n的阶乘种连接顺序,也就是n!
有n个表进行连接,MySQL查询优化器要每一种连接顺序的成本都计算一遍么?那就有n! 种连接顺序。其实真的是要都算一遍,不过MySQL用了很多办法减少计算非常多种连接顺序的成本的方法:
- 提前结束某种顺序的成本评估
MySQL 在计算各种链接顺序的成本之前,会维护一个全局的变量,这个变量表示当前最小的连接查询成本。如果在分析某个连接顺序的成本时,该成本已经超过当前最小的连接查询成本,那就压根儿不对该连接顺序继续往下分析了。比方说A、B、C三个表进行连接,已经得到连接顺序ABC是当前的最小连接成本,比方说10.0,在计算连接顺序 BCA 时,发现B和C的连接成本就已经大于10.0时,就不再继续往后分析 BCA 这个连接顺序的成本了。
- optimizer_search_depth
为了防止无穷无尽的分析各种连接顺序的成本,MySQL 提出了 optimizer_search_depth 系统变量。如果连接表的个数小于该值,那么就继续穷举分析每一种连接顺序的成本,否则只对与 optimizer_search_depth 值相同数量的表进行穷举分析。很显然,该值越大,成本分析的越精确,越容易得到好的执行计划,但是消耗的时间也就越长,否则得到不是很好的执行计划,但可以省掉很多分析连接成本的时间。
虽然有了以上两个规则,但是我们平时也要避免多表查询,根据阿里巴巴开发手册中关于索引规约中讲到:
当出现超过三个表的join时,就应该考虑改写SQL语句了,因为从我们上面的多表关联成本分析可以知道,就算是不考虑多表关联时需要查询的巨大记录条数,就算是几个表的关联成本计算也是个很耗费时间的过程。

若有收获,就点个赞吧
0 人点赞
