一、思路
首先,记事本json格式的文件,里面的单条数据有$oid, 这个$oid是mongodb数据库特有的索引数据。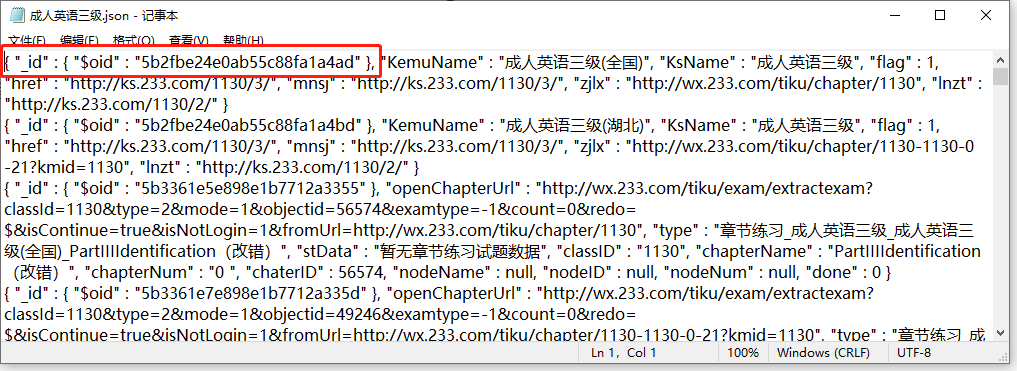
1、我们需要先把json格式数据(这个JSON数据不是JavaScript可以处理)需要导入到mongodb数据库(可以使用mongodb可视化工具compass);
2、将数据导入完毕后,筛选后导出成 JavaScript可以处理的JSON数据,通过node 插入到数据库;
3、使用mssql 插件连接数据库, 之前按照往上文档一直连接不上,因为少了红框的部分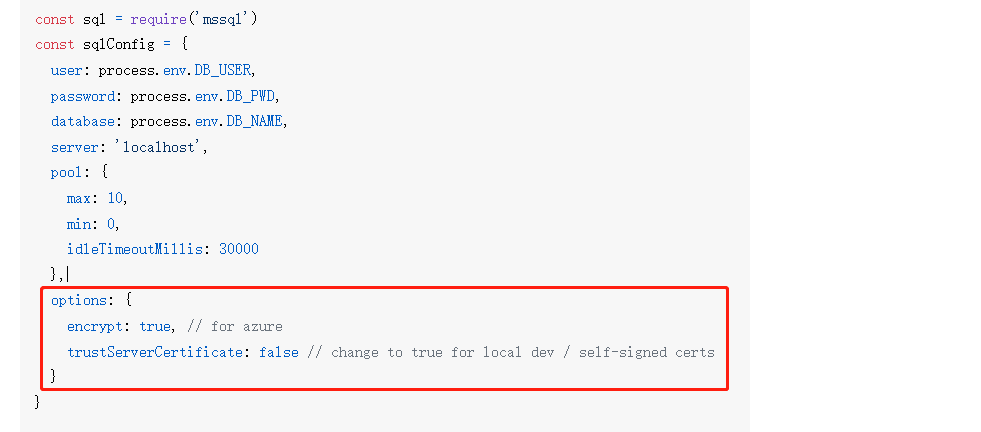
var dbConfig = {user: 'sa',password: 'PPKao2106',server: '192.168.1.220',database: 'lltk',port: 1433,pool: {max: 10,min: 0,idleTimeoutMillis: 30000},options: {encrypt: false, // for azuretrustServerCertificate: false // change to true for local dev / self-signed certs}};
二、碰到的问题
1、 “_id” : { “$oid” : “5b2fbe24e0ab55c88fa1a4ad” }
解答:这个是mongodb数据 导出的数据就是这样的,自带了id,导出的时候可以筛选不用带这个id;
2、node 如何读取Json文件,使用 fs.readFileSync(‘./data/gongwuyuan.json’,’utf8’ ), utf8是告知应该用何种数据格式进行读取。 默认是buffer 数据格式;导出的数据是有效的json字符串,需要使用JSON.parse转换成数组JSON文件进行处理。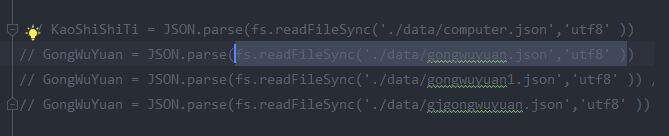
3、node读取较大文件报错如何处理?
node 读取大文件会报错,因为fs.readFileSync读取文件是将文件一次性读取到本地内存。而如果读取文件超过400M左右就会报错,因为占用了大量内存,效率低。我们就要用流来读取。流是将数据分割段,一段一段的读取,可以控制速率,效率很高,不会占用大量内存。gulp的task任务,文件压缩,和http中的请求和响应功能的实现都是基于流来实现的
流的用法
1. node中读是将内容读取到内存中,而内存就是Buffer 对象2. 流都是基于原生的fs 操作文件的方法来实现的,通过fs 创建流。所有的Stream 对象都是EventEmitter 的实例。常用的事件有:1. open - 打开文件2. data - 当有数据可读的时候触发3. error - 在读取和写如过程中发生错误时触发。4. close - 关闭文件5. end - 没有更多的数据可读时触发
let fs = require('fs');let rs = fs.createReadStream('./1.text', {highWaterMark:3, // 文件一次读多少个字节,默认 64*1024flags: 'r', // 默认 'r'autoClose: true, // 默认读取完毕后自动关闭start: 0, //读取文件开始位置end: 3, // 流是闭合区间, 包含start 也含 endencoding: 'utf8' //默认null})//监听文件open方法rs.on('open', () => {console.log('文件打开')})// 只要文件没读取完 这个方法会一直触发, 直到读取完毕rs.on('data', (data) => {console.log(data); //})rs.pause() // 暂定读取, 会暂停data事件的触发,将流动模式转为非流动模式rs.resume() // 恢复data 事件,继续读取,变为流动模式rs.on('err', () => {console.log("发生错误")})rs.on('end', () => {console.log("读取完毕")})rs.on("close",()=>{ //最后文件关闭触发console.log("关闭")});
但是 问题又出现了, 流的操作是每次都读取固定的字节数量,会导致每次读取的可能不是完整的字符串,所以就不能连接字符串的操作, 如下图所示;<br /><br />我们可以使用一个叫JSONStream 的插件进行处理,这个插件是基于流的,每次data 返回的是一个对象,正好满足我们的需求,每次返回一个对象,我们就处理一下,插入到数据库!
function ShiTiData() {console.log(KaoShiShiTi.length) //3214 先500开始(采集完了)sql.connect(dbConfig).then(function async() {// for(let i = 0; i < KaoShiShiTi.length; i++ ) {// for(let i = 3000; i < 3215; i++ ) {// const { stData } = GongWuYuan[i];const readable = fs.createReadStream('./data/medicine.json', {encoding: 'utf8',highWaterMark: 10})const parser = JSONStream.parse('.');readable.pipe(parser);parser.on('data', (data) => {const { stData } = data;// console.log(stData, 'stData', stData.length)if(stData && stData.length > 0) {console.log(stData, 'dataaaaaaaaaaaaaaaaaaaaaa', stData.length)for(let stDataIndex = 0; stDataIndex < stData.length; stDataIndex ++) {if(stData[stDataIndex].examCardStatusList && stData[stDataIndex].examCardStatusList.examDtoList && stData[stDataIndex].examCardStatusList.examDtoList.length > 0) {let topicList = stData[stDataIndex].examCardStatusList.examDtoList;for(let topicIndex = 0; topicIndex < topicList.length; topicIndex++) {let { examId, answer, analysis, content, examType, examTypeName, selectNum, optionList, videoAnalysis, videoAnalysisId, videoCoverUrl, md5, tikuId } = topicList[topicIndex];if(optionList && optionList.length > 0) {optionList = handdleOptionList(optionList);}new sql.Request().query(`insert into ShiTi (examId,answer,analysis, content, examType, examTypeName, selectNum, optionList, videoAnalysis, videoAnalysisId, videoCoverUrl, md5, tikuId ) values('${examId}','${answer}','${analysis}', '${content}', '${examType}', '${examTypeName}', '${selectNum}','${optionList}','${videoAnalysis}', '${videoAnalysisId}', '${videoCoverUrl}', '${md5}', '${tikuId}')`,);}}if(stData[stDataIndex].examCardStatusList && !stData[stDataIndex].examCardStatusList.examDtoList && stData[stDataIndex].examCardStatusList.length > 0){let topicList = stData[stDataIndex].examCardStatusList;for(let topicIndex = 0; topicIndex < topicList.length; topicIndex++) {let { examId, answer, analysis, content, examType, examTypeName, selectNum, optionList, videoAnalysis, videoAnalysisId, videoCoverUrl, md5, tikuId } = topicList[topicIndex];console.log(`examId=${examId};answer=${answer}`)if(optionList && optionList.length > 0) {optionList = handdleOptionList(optionList);}new sql.Request().query(`insert into ShiTi (examId,answer,analysis, content, examType, examTypeName, selectNum, optionList, videoAnalysis, videoAnalysisId, videoCoverUrl, md5, tikuId ) values('${examId}','${answer}','${analysis}', '${content}', '${examType}', '${examTypeName}', '${selectNum}','${optionList}','${videoAnalysis}', '${videoAnalysisId}', '${videoCoverUrl}', '${md5}', '${tikuId}')`,);}}}}});}).catch(function (err) {console.log(err);});}

若有收获,就点个赞吧
0 人点赞
