数据解析(用于聚焦爬虫)
爬取页面中指定的页面内容,局部内容解析操作。
对爬下的页面,在处理数据。
原理
使用通用爬虫。大部分内容都存储在标签内;图片是一个img标签,存储的是一个url。
- 解析的局部文本内容都会存在:标签or标签内的属性当中
- 1、进行指定标签的定位
- 2、标签或者标签对应的属性中存储的数据值进行提取(解析)
正则
常用: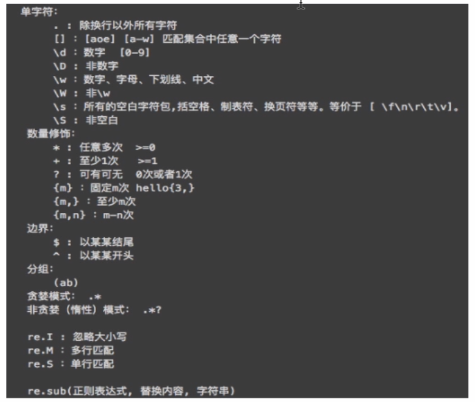
正则练习:
取图片,图片的content是一组二进制数据。
#!/usr/bin/env python# -*- coding:utf-8 -*-import requestsif __name__ == "__main__":# 如何爬取图片数据url = 'https://bkimg.cdn.bcebos.com/pic/77c6a7efce1b9d16fdfa648f598ca38f8c5495eece98'# content返回的是二进制形式的图片数据# text(字符串) content(二进制)json() (对象)img_data = requests.get(url=url).contentwith open('./qiutu.jpg', 'wb') as fp:fp.write(img_data)
正则解析案例
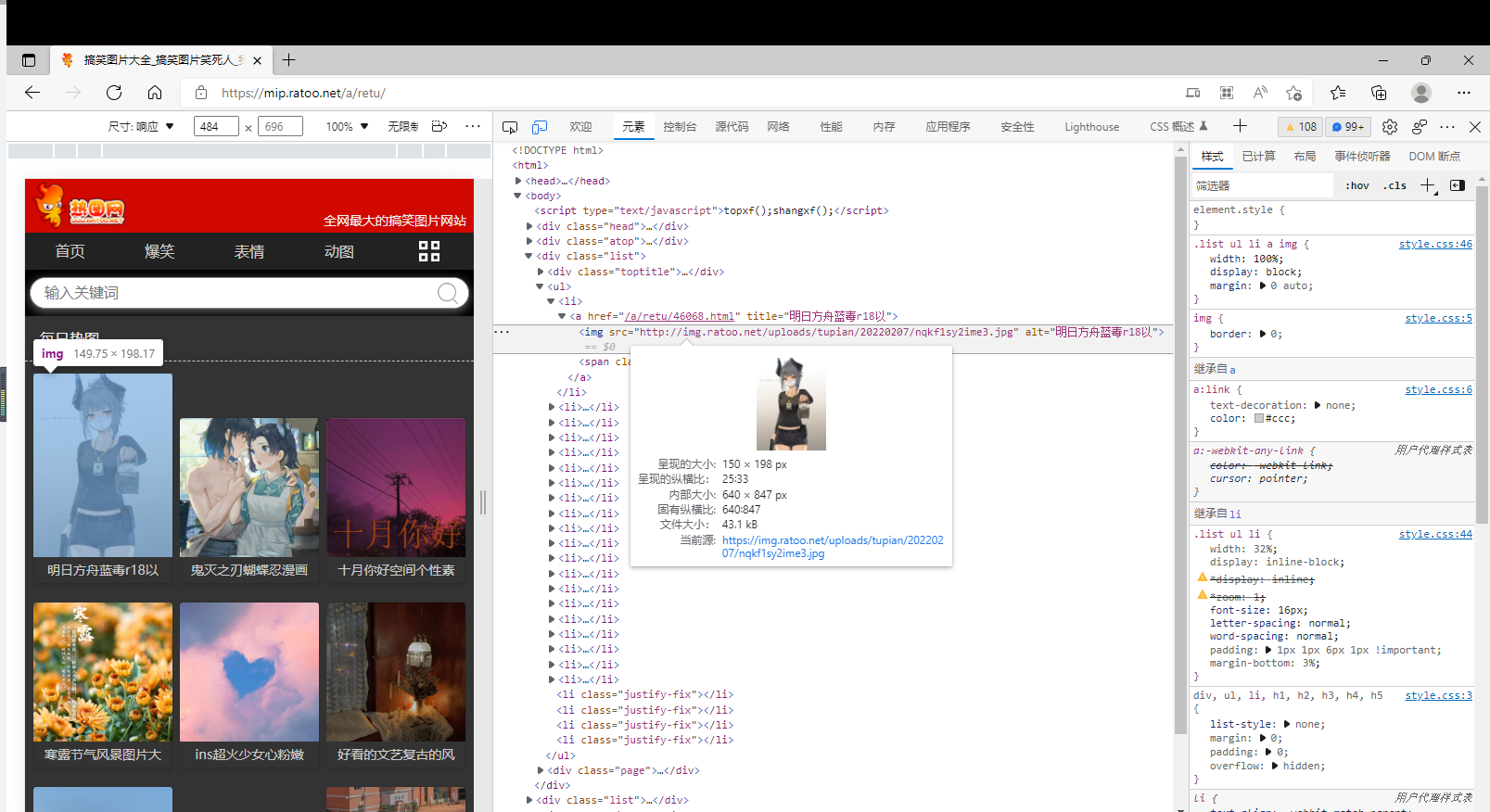
import requestsimport jsonimport reimport osif __name__ == "__main__":# 创建文件夹,保存所有图片if not os.path.exists('./retuLibs'):os.mkdir('./retuLibs')headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:99.0) Gecko/20100101 Firefox/99.0'}# 设置一个通用的url模板url = 'https://mip.ratoo.net/a/retu/list_21_%d.html'# pageNum =2for pageNum in range(1, 3):# 对应页码的urlnew_url = format(url % pageNum)# 使用通用爬虫page_text = requests.get(url=url, headers=headers).text# """# <li><a href="/a/retu/46006.html" title="鬼灭之刃蝴蝶忍漫画"><img src="http://img.ratoo.net/uploads/tupian/20220113/bly3vi3oafm307.jpg" alt="鬼灭之刃蝴蝶忍漫画"><span class="title">鬼灭之刃蝴蝶忍漫画</span></a></li># """ex = '<li><a href="/a/retu/.*?<img src="(.*?)" alt=".*?</span></a></li>'img_src_list = re.findall(ex, page_text, re.M) # re.S单行匹配# print(img_src_list)for src in img_src_list:img_data = requests.get(url=new_url, headers=headers).content# 生成图片名称img_name = src.split('/')[-1]imgPath = './retuLibs/' + img_namewith open(imgPath, 'wb') as fp:fp.write(img_data)print(img_name, 'download success')
bs4(python独有),解析,VS正则
数据解析的原理:
1、标签定位
2、提取标签、标签属性中存储的数据值
bs4数据解析的原理:
1、实例化一个BeautifulSoup对象,并且将页面源码数据加载到该对象中;
2、通过调用BeautifulSoup对象总相关的属性或者方法进行标签定位和数据提取。
环境安装
pip install bs4
pip install lxml(一个解析器)
如何实例化BeautifulSoup对象
对象的实例化:
-1、将本地的html文档中的数据加载到该对象中
fp = open('./test.html', 'r', encoding='utf-8')
# 实例对象
soup = BeautifulSoup(fp, 'lxml') # 用lxml解析器
-2、将互联网上获取的页面源码加载到该对象中
page_text = response.text
soup = BeautifulSoup(page_text, 'lxml') # 用lxml解析器
bs4解析具体使用讲解
提供的用于数据解析的方法和属性:
soup.tagName:返回的是文档中第一次出现的tagName对应的标签
soup.find():
-find(‘tagName’):等同于soup.div
-属性定位:
-soup.find(‘div’, class_/id/attr = ‘song’)
soup.find_all(‘tagName’):返回符合要求的所有标签(列表)。
select
soup.select():
select(‘某种选择器(id, class,标签..选择器) ‘),返回的是一个列表
层级选择器 > 表示一个层级
通过选择器去选择。
>:表示一个层级
空格表示多个层级
soup.select('.tang > ul > li > a'): >表示的是一个层级
soup.select('.tang > ul a'): 空格表示的多个层级
获取标签之间的文本数据
调用定位到的标签的属性、方法。
soup.a.text/string/get_text()
-text/get_text() :可以获取某一个标签中所有的文本内容,即使不是直系的内容
-string:只可以获取该标签下直系的文本内容。
获取标签中的属性值
soup.a.[‘href’]
案例实战
需求:爬取三国演义小说所有的章节标题和章节内容http://www.shicimingju.com/book/sanguoyanyi.html
#!/usr/bin/env python
# -*- coding:utf-8 -*-
import requests
from bs4 import BeautifulSoup
#需求:爬取三国演义小说所有的章节标题和章节内容http://www.shicimingju.com/book/sanguoyanyi.html
if __name__ == "__main__":
#对首页的页面数据进行爬取
headers = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.121 Safari/537.36'
}
url = 'http://www.shicimingju.com/book/sanguoyanyi.html'
page_text = requests.get(url=url,headers=headers).text
#在首页中解析出章节的标题和详情页的url
#1.实例化BeautifulSoup对象,需要将页面源码数据加载到该对象中
soup = BeautifulSoup(page_text,'lxml')
#解析章节标题和详情页的url
li_list = soup.select('.book-mulu > ul > li')
fp = open('./sanguo.txt','w',encoding='utf-8')
for li in li_list:
title = li.a.string
detail_url = 'http://www.shicimingju.com'+li.a['href']
#对详情页发起请求,解析出章节内容
detail_page_text = requests.get(url=detail_url,headers=headers).text
#解析出详情页中相关的章节内容
detail_soup = BeautifulSoup(detail_page_text,'lxml')
div_tag = detail_soup.find('div',class_='chapter_content')
#解析到了章节的内容
content = div_tag.text
fp.write(title+':'+content+'\n')
print(title,'爬取成功!!!')
※xpath 最常用、通用、高效的解析方式
解析原理
1、实例化一个 etree的对象,且需要将被解析的页面源码数据加载到该对象中;
2、调用 etree对象中的 xpath方法结合着 xpath表达式实现标签的定位和内容的捕获。
环境安装:
pip install lxml
实例化etree对象:from lxml import etree
1.将本地的htmL文档中的源码数据加载到etree对象中:
etree.parse(filePath)
2.可以将从互联网上获取的源码数据加载到该对象中:
etree.HTML(‘page_text’)
-xpath(‘xpath表达式’)
xpath表达式:
/:表示的是从根节点开始定位。表示的是一个层级。
//:表示多个层级,相当于bs4的空格。可以表示从任意位置开始定位。
./:表示当前标签
-属性定位://div[@cLass=’song’] tag[@attrName=”attrValue”]
-索引定位:r = tree.xpath(‘//div[@class=”song”]/p[3]’) 索引是从1开始的
取文本
-/text() 获取的标签中直系的文本内容
-//text() 标签中非直系的所有文本内容
取属性
/@attrName
-/@src
58同城
#!/usr/bin/env python
# -*- coding:utf-8 -*-
import requests
from lxml import etree
#需求:爬取58二手房中的房源信息
if __name__ == "__main__":
headers = {
'User-Agent':'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.103 Safari/537.36'
}
#爬取到页面源码数据
url = 'https://bj.58.com/ershoufang/'
page_text = requests.get(url=url,headers=headers).text
#数据解析
tree = etree.HTML(page_text)
#存储的就是li标签对象
li_list = tree.xpath('//ul[@class="house-list-wrap"]/li')
fp = open('58.txt','w',encoding='utf-8')
for li in li_list:
#局部解析
title = li.xpath('./div[2]/h2/a/text()')[0]
print(title)
fp.write(title+'\n')
4k图片解析爬取
需求:解析下载图片数据 http://pic.netbian.com/4kmeinv/
作业

a标签是下载地址,

若有收获,就点个赞吧
0 人点赞
