scrapy框架
什么是框架? 项目半成品
- 就是一个集成了很多功能并且具有很强通用性的一个项目模板。
- 如何学习框架?
- 专门学习框架封装的各种功能的详细用法。
什么是scrapy?
- 爬虫中封装好的一个明星框架。<br />功能:高性能的持久化存储,异步的数据下载,高性能的数据解析,分布式
scrapy框架的基本使用
环境的安装:
mac or linux
windows
- pip install wheel<br /> - 下载twisted,下载地址为[http://www.lfd.uci.edu/~gohlke/pythonlibs/#twisted](http://www.lfd.uci.edu/~gohlke/pythonlibs/#twisted)<br /> - 安装twisted:pip install Twisted‑17.1.0‑cp36‑cp36m‑win_amd64.whl<br /> - pip install pywin32<br /> - pip install scrapy<br /> 测试:在终端里录入scrapy指令,没有报错即表示安装成功!
使用
-建一个工程:scrapy startproject xxxPro
- cd xxxPro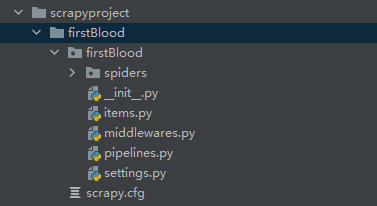
spiders是一个爬虫文件夹
settings是配置文件。
- 在spiders子目录中创建一个爬虫文件(py文件)
- scrapy genspider spiderName www.xxx.com
一个启始url,后续可以在setting中改。
- 执行工程:
- scrapy crawl spiderName(爬虫名称)
开始爬取
ROBOTSTXT_OBEY = True,ROBOTS协议 ```pythonObey robots.txt rules
ROBOTSTXT_OBEY = False
显示指定类型的日志信息
LOG_LEVEL = ‘ERROR’
<a name="KW9iP"></a>
# scrapy数据解析
```python
# author = div.xpath('./div[1]/a[2]/h2/text()')[0].extract()
# author = div.xpath('./div[1]/a[2]/h2/text()').extract_first()
# #列表调用了extract之后,则表示将列表中每一个Selector对象中data对应的字符串提取了出来
# -*- coding: utf-8 -*-
import scrapy
from qiubaiPro.items import QiubaiproItem
class QiubaiSpider(scrapy.Spider):
name = 'qiubai'
# allowed_domains = ['www.xxx.com']
start_urls = ['https://www.qiushibaike.com/text/']
#
# def parse(self, response):
# #解析:作者的名称+段子内容
# div_list = response.xpath('//div[@id="content-left"]/div')
# all_data = [] #存储所有解析到的数据
# for div in div_list:
# #xpath返回的是列表,但是列表元素一定是Selector类型的对象
# #extract可以将Selector对象中data参数存储的字符串提取出来
# # author = div.xpath('./div[1]/a[2]/h2/text()')[0].extract()
# author = div.xpath('./div[1]/a[2]/h2/text()').extract_first()
# #列表调用了extract之后,则表示将列表中每一个Selector对象中data对应的字符串提取了出来
# content = div.xpath('./a[1]/div/span//text()').extract()
# content = ''.join(content)
#
# dic = {
# 'author':author,
# 'content':content
# }
#
# all_data.append(dic)
#
#
# return all_data
def parse(self, response):
#解析:作者的名称+段子内容
div_list = response.xpath('//div[@id="content-left"]/div')
all_data = [] #存储所有解析到的数据
for div in div_list:
#xpath返回的是列表,但是列表元素一定是Selector类型的对象
#extract可以将Selector对象中data参数存储的字符串提取出来
# author = div.xpath('./div[1]/a[2]/h2/text()')[0].extract()
author = div.xpath('./div[1]/a[2]/h2/text() | ./div[1]/span/h2/text()').extract_first()
#列表调用了extract之后,则表示将列表中每一个Selector对象中data对应的字符串提取了出来
content = div.xpath('./a[1]/div/span//text()').extract()
content = ''.join(content)
item = QiubaiproItem()
item['author'] = author
item['content'] = content
yield item#将item提交给了管道
scrapy持久化存储
基于终端指令
- 要求:只可以将parse方法的**返回值**存储到本地的文本文件中,只可存**返回值**<br /> - 注意:持久化存储对应的文本文件的类型只可以为:'json', 'jsonlines', 'jl', 'csv', 'xml', 'marshal', 'pickle<br /> - 指令:scrapy crawl xxx -o filePath<br /> - 好处:简介高效便捷<br /> - 缺点:局限性比较强(数据只可以存储到指定后缀的文本文件中)
基于管道
编码流程
1、数据解析,用xpath
2、首先,在item类中定义相关的属性,
class QiubaiproItem(scrapy.Item):
# define the fields for your item here like:
author = scrapy.Field()
content = scrapy.Field()
# pass
3、将解析的数据封装存储到item类型的对象,(需要手动实例化)
item = QiubaiproItem()
item['author'] = author
item['content'] = content
yield item#将item提交给了管道
4、将item类型的对象提交给管道进行持久化存储的操作,
class QiubaiproPipeline(object):
fp = None
#重写父类的一个方法:该方法只在开始爬虫的时候被调用一次
def open_spider(self,spider):
print('开始爬虫......')
self.fp = open('./qiubai.txt', 'w', encoding='utf-8')
#专门用来处理item类型对象
#该方法可以接收爬虫文件提交过来的item对象
#该方法每接收到一个item就会被调用一次
def process_item(self, item, spider):
author = item['author']
content= item['content']
# with open写进来不好,只打开一次就可
self.fp.write(author+':'+content+'\n')
return item #就会传递给下一个即将被执行的管道类
def close_spider(self,spider):
print('结束爬虫!')
self.fp.close()
开启管道:
# Configure item pipelines
# See https://docs.scrapy.org/en/latest/topics/item-pipeline.html
ITEM_PIPELINES = {
'hesuanPro.pipelines.HesuanproPipeline': 300,
# 300表示优先级,数值越小,优先级越高
}
5、在管道类的process_item中要将其接受到的item对象中存储的数据进行持久化存储操作
6、在配置文件中开启管道
- 好处:
- 通用性强。
面试题
将爬取到的数据一份存储到本地一份存储到数据库,如何实现?
- 管道文件中一个管道类对应的是将数据存储到一种平台
- 爬虫文件提交的item只会给管道文件中第一个被执行的管道类接收
- process_item中的return item表示将item传递给下一个即将被执行的管道类
# -*- coding: utf-8 -*-
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://doc.scrapy.org/en/latest/topics/item-pipeline.html
import pymysql
class QiubaiproPipeline(object):
fp = None
#重写父类的一个方法:该方法只在开始爬虫的时候被调用一次
def open_spider(self,spider):
print('开始爬虫......')
self.fp = open('./qiubai.txt','w',encoding='utf-8')
#专门用来处理item类型对象
#该方法可以接收爬虫文件提交过来的item对象
#该方法没接收到一个item就会被调用一次
def process_item(self, item, spider):
author = item['author']
content= item['content']
self.fp.write(author+':'+content+'\n')
return item #就会传递给下一个即将被执行的管道类
def close_spider(self,spider):
print('结束爬虫!')
self.fp.close()
#管道文件中一个管道类对应将一组数据存储到一个平台或者载体中
class mysqlPileLine(object):
conn = None
cursor = None
def open_spider(self,spider):
self.conn = pymysql.Connect(host='127.0.0.1',port=3306,user='root',password='123456',db='qiubai',charset='utf8')
def process_item(self,item,spider):
self.cursor = self.conn.cursor()
try:
self.cursor.execute('insert into qiubai values("%s","%s")'%(item["author"],item["content"]))
self.conn.commit()
except Exception as e:
print(e)
self.conn.rollback()
return item
def close_spider(self,spider):
self.cursor.close()
self.conn.close()
#爬虫文件提交的item类型的对象最终会提交给哪一个管道类?
#先执行的管道类
ITEM_PIPELINES = {
'qiubaiPro.pipelines.QiubaiproPipeline': 300,
'qiubaiPro.pipelines.mysqlPileLine': 301,
#300表示的是优先级,数值越小优先级越高
}
基于Spider的全站数据爬取
所谓的全站数据爬取:
就是将网站中某板块下的全部页码对应的页面数据进行爬取
- 需求:爬取校花网中的照片的名称
- 实现方式:
1、将所有页面的url添加到start_urls列表(不推荐),页码很多就没办法
2、自行手动进行请求发送(推荐)
手动请求发送:
- yield scrapy.Request(url,callback):callback专门用做于数据解析
class XiaohuaSpider(scrapy.Spider):
name = 'xiaohua'
# allowed_domains = ['www.xxx.com']
start_urls = ['http://www.521609.com/meinvxiaohua/']
#生成一个通用的url模板(不可变)
url = 'http://www.521609.com/meinvxiaohua/list12%d.html'
page_num = 2
def parse(self, response):
li_list = response.xpath('//*[@id="content"]/div[2]/div[2]/ul/li')
for li in li_list:
img_name = li.xpath('./a[2]/b/text() | ./a[2]/text()').extract_first()
print(img_name)
if self.page_num <= 11:
new_url = format(self.url%self.page_num)
self.page_num += 1
#手动请求发送:callback回调函数是专门用作于数据解析
yield scrapy.Request(url=new_url,callback=self.parse)
#手动请求发送:callback回调函数是专门用作于数据解析
yield scrapy.Request(url=new_url,callback=self.parse)
五大核心组件
引擎(Scrapy)
用来处理整个系统的数据流处理, 触发事务(框架核心)
调度器(Scheduler)
用来接受引擎发过来的请求, 压入队列中, 并在引擎再次请求的时候返回. 可以想像成一个URL(抓取网页的网址或者说是链接)的优先队列, 由它来决定下一个要抓取的网址是什么, 同时去除重复的网址
下载器(Downloader)
用于下载网页内容, 并将网页内容返回给蜘蛛(Scrapy下载器是建立在twisted这个高效的异步模型上的)
爬虫(Spiders)
爬虫是主要干活的, 用于从特定的网页中提取自己需要的信息, 即所谓的实体(Item)。用户也可以从中提取出链接,让Scrapy继续抓取下一个页面
项目管道(Pipeline)
负责处理爬虫从网页中抽取的实体,主要的功能是持久化实体、验证实体的有效性、清除不需要的信息。当页面被爬虫解析后,将被发送到项目管道,并经过几个特定的次序处理数据。
请求传参
- 使用场景:如果爬取解析的数据不在同一张页面中。(深度爬取)<br /> - 需求:爬取boss的岗位名称,岗位描述
图片数据爬取之ImagesPipeline
- 基于scrapy爬取字符串类型的数据和爬取图片类型的数据区别?
- 字符串:只需要基于xpath进行解析且提交管道进行持久化存储
- 图片:xpath解析出图片src的属性值。单独的对图片地址发起请求获取图片二进制类型的数据- ImagesPipeline:
- 只需要将img的src的属性值进行解析,提交到管道,管道就会对图片的src进行请求发送获取图片的二进制类型的数据,且还会帮我们进行持久化存储。
- 需求:爬取站长素材中的高清图片
- 使用流程:
- 数据解析(图片的地址)
- 将存储图片地址的item提交到制定的管道类
- 在管道文件中自定制一个基于ImagesPipeLine的一个管道类
- get_media_request
- file_path
- item_completed
- 在配置文件中:
- 指定图片存储的目录:IMAGES_STORE = ‘./imgs_bobo’
- 指定开启的管道:自定制的管道类
- ImagesPipeline:
中间件
- 下载中间件
- 位置:引擎和下载器之间
- 作用:批量拦截到整个工程中所有的请求和响应
- 拦截请求:
- UA伪装:process_request
- 代理IP:process_exception:return request- 拦截响应:<br /> - 篡改响应数据,响应对象<br /> - 需求:爬取网易新闻中的新闻数据(标题和内容)<br /> - 1.通过网易新闻的首页解析出五大板块对应的详情页的url(没有动态加载)<br /> - 2.每一个板块对应的新闻标题都是动态加载出来的(动态加载)<br /> - 3.通过解析出每一条新闻详情页的url获取详情页的页面源码,解析出新闻内容CrawlSpider:类,Spider的一个子类
- 全站数据爬取的方式
- 基于Spider:手动请求
- 基于CrawlSpider
- CrawlSpider的使用:
- 创建一个工程
- cd XXX
- 创建爬虫文件(CrawlSpider):
- scrapy genspider -t crawl xxx www.xxxx.com
- 链接提取器:
- 作用:根据指定的规则(allow)进行指定链接的提取
- 规则解析器:
- 作用:将链接提取器提取到的链接进行指定规则(callback)的解析
#需求:爬取sun网站中的编号,新闻标题,新闻内容,标号
- 分析:爬取的数据没有在同一张页面中。
- 1.可以使用链接提取器提取所有的页码链接
- 2.让链接提取器提取所有的新闻详情页的链接
分布式爬虫
- 概念:我们需要搭建一个分布式的机群,让其对一组资源进行分布联合爬取。
- 作用:提升爬取数据的效率如何实现分布式?
- 安装一个scrapy-redis的组件
- 原生的scarapy是不可以实现分布式爬虫,必须要让scrapy结合着scrapy-redis组件一起实现分布式爬虫。
- 为什么原生的scrapy不可以实现分布式?
- 调度器不可以被分布式机群共享
- 管道不可以被分布式机群共享
- scrapy-redis组件作用:
- 可以给原生的scrapy框架提供可以被共享的管道和调度器
- 实现流程
- 创建一个工程
- 创建一个基于CrawlSpider的爬虫文件
- 修改当前的爬虫文件:
- 导包:from scrapy_redis.spiders import RedisCrawlSpider
- 将start_urls和allowed_domains进行注释
- 添加一个新属性:redis_key = ‘sun’ 可以被共享的调度器队列的名称
- 编写数据解析相关的操作
- 将当前爬虫类的父类修改成RedisCrawlSpider
- 修改配置文件settings
- 指定使用可以被共享的管道:
ITEM_PIPELINES = {
‘scrapy_redis.pipelines.RedisPipeline’: 400
}
- 指定调度器:
# 增加了一个去重容器类的配置, 作用使用Redis的set集合来存储请求的指纹数据, 从而实现请求去重的持久化
DUPEFILTER_CLASS = “scrapy_redis.dupefilter.RFPDupeFilter”
# 使用scrapy-redis组件自己的调度器
SCHEDULER = “scrapy_redis.scheduler.Scheduler”
# 配置调度器是否要持久化, 也就是当爬虫结束了, 要不要清空Redis中请求队列和去重指纹的set。如果是True, 就表示要持久化存储, 就不清空数据, 否则清空数据
SCHEDULER_PERSIST = True
- 指定redis服务器:- redis相关操作配置:<br /> - 配置redis的配置文件:<br /> - linux或者mac:redis.conf<br /> - windows:redis.windows.conf<br /> - 代开配置文件修改:<br /> - 将bind 127.0.0.1进行删除<br /> - 关闭保护模式:protected-mode yes改为no<br /> - 结合着配置文件开启redis服务<br /> - redis-server 配置文件<br /> - 启动客户端:<br /> - redis-cli<br /> - 执行工程:<br /> - scrapy runspider xxx.py<br /> - 向调度器的队列中放入一个起始的url:<br /> - 调度器的队列在redis的客户端中<br /> - lpush xxx www.xxx.com<br /> - 爬取到的数据存储在了redis的proName:items这个数据结构中
参考

若有收获,就点个赞吧
0 人点赞
