urllib模块(旧)
简介
requests模块:python中原生的一款基于网络请求的模块,功能非常强大,简单便捷,效率极高。
作用:模拟浏览器发请求。
使用(request模块的编码流程)
- 指定url
- 发起请求(get/post)
- 获取响应数据
- 持久化存储
安装:pip install request
实战
需求:爬取搜狗首页的页面数据
# 初尝试import requestsif __name__ == "__main__":# step1:指定urlurl = "https://zhihu.sogou.com/"# step2:发起请求# get方法会返回一个响应对象response = requests.get(url=url,)# step3:获取响应数据,响应数据在响应对象里,需要请求成功#text 返回的是字符串形式的响应数据page_text = response.textprint(page_text)# step4:持久化存储with open('./sougou.html', 'w', encoding='utf-8') as fp:fp.write(page_text)
实战巩固
- 需求:爬取搜狗指定词条对应的搜索结果页面(简易网页采集器)
- 需求:破解百度翻译
- 需求:爬取豆瓣电影分类排行榜https://movie.douban.com/中的电影详情数据
- 需求:爬取肯德基餐厅查询http://www.kfc.com.cn/kfccda/index.aspx中指定地点的餐厅数据
- 需求:爬取国家药品监督管理总局中基于中华人民共和国化妆品生产许可证相关数据http://scxk.nmpa.gov.cn:81/xk/
网易采集器
搜狗输入一个关键字,然后对页面进行抓取
UA检测与伪装
UA:User-Agent
import requests# UA:User-Agent(请求载体的身份标识)# UA检测:门户网站的服务器会检测对应请求的载体身份标识,如果检测到的身份标识为某一款浏览器,# 说明该请求为正常请求。若检测为不是,则为不正常请求(爬虫)。服务器端则可能拒绝此次请求。# UA伪装:让爬虫对应的请求载体身份标识伪装成某一款浏览器if __name__ == "__main__":# UA伪装:将对应的User-Agent封装到一个字典中headers = {'User-Agent': 'Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/100.0.4896.60 Mobile Safari/537.36 Edg/100.0.1185.29'}url = 'https://www.sogou.com/web'# 处理url携带的参数:封装到字典中kw = input('enter a word:')param = {'query': kw}# 对指定的url发起的请求对应的url是携带参数的,并且请求过程中处理了参数response = requests.get(url=url, params=param, headers=headers)page_text = response.textfileName = kw + '.html'with open(fileName, 'w', encoding='utf-8') as fp:fp.write(page_text)print(fileName, 'save success!!')
破解百度翻译
对应单词或句子的翻译结果
爬取局部数据
什么是xhr?
什么是AJAX请求?ajax 是一种浏览器通过 js 异步发起请求, 局部更新页面的技术。
xhr,全称为XMLHttpRequest,用于与服务器交互数据,是ajax功能实现所依赖的对象,jquery中的ajax就是对 xhr的封装。
局部刷新,ajax请求,就是对应的单字翻译结果
import requests# 只拿到翻译结果# 页面局部刷新,用ajax请求# post请求(携带了参数)# 响应数据是一组json数据import jsonif __name__ == "__main__":post_url = 'https://fanyi.baidu.com/sug'# post请求参数处理(同get一致)word = input('enter a word:')data = {'kw': word}# 进行UA伪装headers = {'User-Agent': 'Mozilla / 5.0(Windows NT 10.0;Win64;x64;rv: 99.0) Gecko / 20100101Firefox / 99.0'}response = requests.post(url=post_url, data=data, headers=headers)# 响应数据是一组json数据,json返回的是一个对象obj,(如果确认服务器响应数据是json类型的,才可以使用json)# content-type可以看到类型dict_obj = response.json()print(dict_obj)# 持久化存储file_Name = word + '.json'fp = open(file_Name, 'w', encoding='utf-8')json.dump(dict_obj, fp=fp, ensure_ascii=False)
豆瓣电影
爬取排行榜里喜剧,电影的作者等等。
当前页面局部的信息,不用数据解析如何爬取?
是否有ajax请求呢?
当滚轮到底部的时候发起了ajax请求
是不是有了ajax请求,加上参数就行了
import requestsimport jsonif __name__ == "__main__":url = 'https://movie.douban.com//j/chart/top_list'headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:99.0) Gecko/20100101 Firefox/99.0'}# https://movie.douban.com/typerank?type_name=%E5%96%9C%E5%89%A7&type=24&interval_id=100:90&action=# 问号后的都是参数params = {'type': '24','interval_id': '100:90','action': '','start': '80', # 从库中第几部开始去取'limit': '20', # 一次取多少个}response = requests.get(url=url, headers=headers, params=params)list_obj = response.json()fp = open('./douban.json', 'w', encoding='utf-8')json.dump(list_obj, fp=fp, ensure_ascii=False)print('success')
作业:肯德基餐厅查询
需求:爬取肯德基餐厅查询http://www.kfc.com.cn/kfccda/index.aspx中指定地点的餐厅数据
点按钮如果网址变了, 那就不是ajax请求。
局部刷新就是ajax请求,只要参数就行。

import requestsimport jsonif __name__ == "__main__":url = 'http://www.kfc.com.cn/kfccda/ashx/GetStoreList.ashx?op=keyword'headers = {'User-Agent': 'Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/100.0.4896.60 Mobile Safari/537.36 Edg/100.0.1185.29'}addre = input('请输入查询地点:')params = {'cname': "",'pid': "",'keyword': addre,'pageIndex': "1",'pageSize': "10",}response = requests.post(url=url, headers=headers, params=params)# Content - Type:text / plain;charset = utf - 8list_obj = response.textwith open('./KFC.text', 'w', encoding='utf-8') as fp:fp.write(list_obj)print('success')
综合练习—药监总局
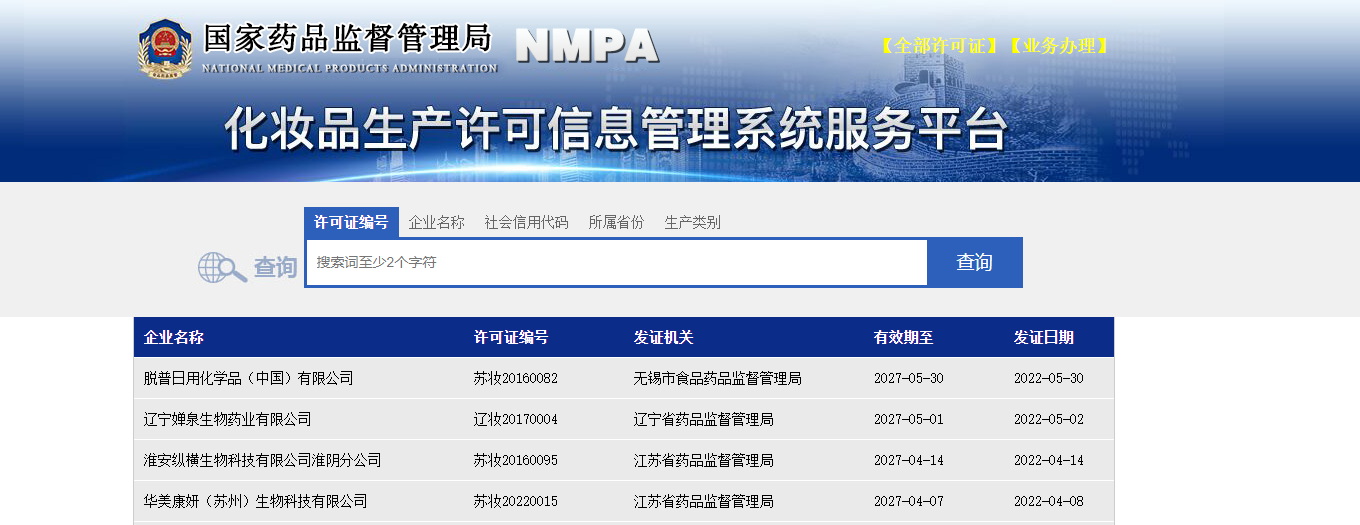
- 需求:爬取国家药品监督管理总局中基于中华人民共和国化妆品生产许可证相关的数据,http://scxk.nmpa.gov.cn:81/xk/
详情页面
将上面这组数据爬取下来。
首先对http://scxk.nmpa.gov.cn:81/xk/这个发起请求,响应数据是否包含企业的数据?
是没有包含相关信息的,并不是由url直接得到。
验证是否由ajax得到。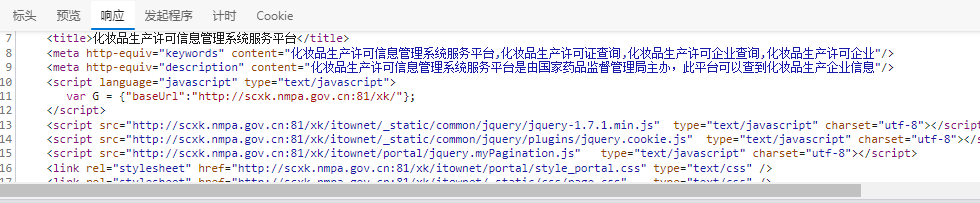 发现响应里没有具体企业的信息。
发现响应里没有具体企业的信息。
存在动态加载数据,直接由url发起得不到。
每一个企业名称对应的是一个超链接,想获得详情页所对应的超链接,
动态加载数据
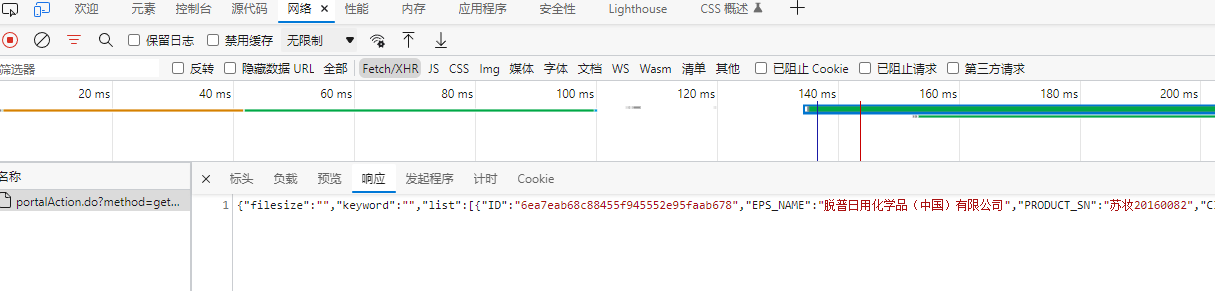
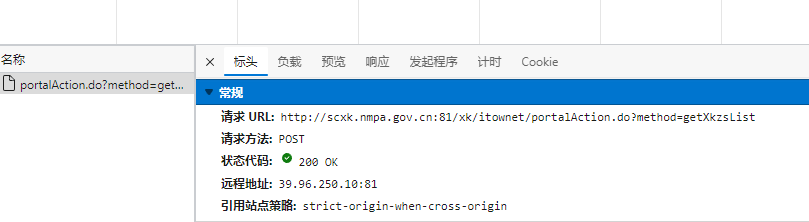
首页数据由ajax动态请求得到。
详情页的url由首页里的数据获得。
http://scxk.nmpa.gov.cn:81/xk/itownet/portal/dzpz.jsp?id=6ea7eab68c88455f945552e95faab678
id由首页数据获得,不同企业的ID不同,由ID可拼接出详情页的URL。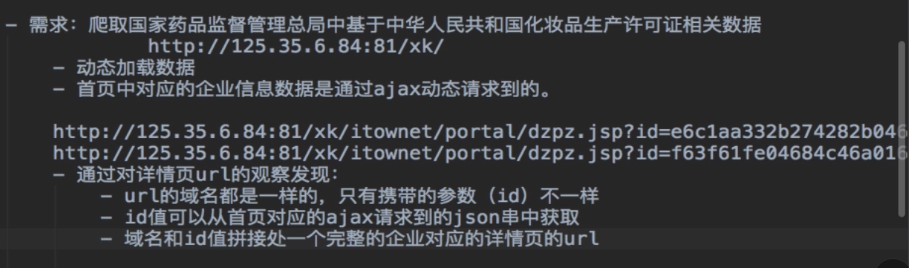
详情页也得验证是不是动态数据。发下详情页数据也是动态加载,不能直接对url发起请求得到数据。
—所有的post请求的url都是一样的,只有参数id值是不同。
—如果我们可以批量获取多家企业的id后,就可以将id和url形成一个完整的详情页对应详情数据的ajax请求的URL
import requestsimport jsonif __name__ == "__main__":headers = {'User-Agent': 'Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/100.0.4896.60 Mobile Safari/537.36 Edg/100.0.1185.29'}id_list = [] # 存储企业的ID# 批量获取不同企业ID值url = 'http://scxk.nmpa.gov.cn:81/xk/itownet/portalAction.do?method=getXkzsList'# 参数的封装for page in range(1, 6):page = str(page)data = {'on': 'true','page': page, # 页码,改动态'pageSize': '15','productName': '','conditionType': '1','applyname': '','applysn': '',}json_ids = requests.post(url=url, headers=headers, data=data).json()for dic in json_ids['list']:id_list.append(dic['ID'])# 获取企业详情数据all_data_list = [] # 存储所以企业详情数据post_url = 'http://scxk.nmpa.gov.cn:81/xk/itownet/portalAction.do?method=getXkzsById'for id in id_list:data = {'id': id}detail_json = requests.post(url=post_url, headers=headers, data=data).json()print(detail_json, '---------------ending----------')all_data_list.append(detail_json)# 持久化存储数据fp = open('./allDate.json', 'w', encoding='utf-8')json.dump(all_data_list, fp=fp, ensure_ascii=False)

若有收获,就点个赞吧
0 人点赞
