💡 基本介绍
:::success
- Transformer 是谷歌于 2017 年发布的关于「编码器-解码器」“自注意力学习机制” 论文。由 OpenAI 选择落地,并在 2022 年 11 月份在 GPT3 上爆火。
- 2024 年 2 月 16 日,OpenAI 再次给予此架构,发布了 Sora 世界模拟器(也就是生成式视频模型),引发了全球轰动,央视网也在发文跟进,甚至台长慎海雄也在台内发文,督促跟进并拿出方案。
可见,谷歌,被 OpenAI “偷家” 偷的很惨。
:::
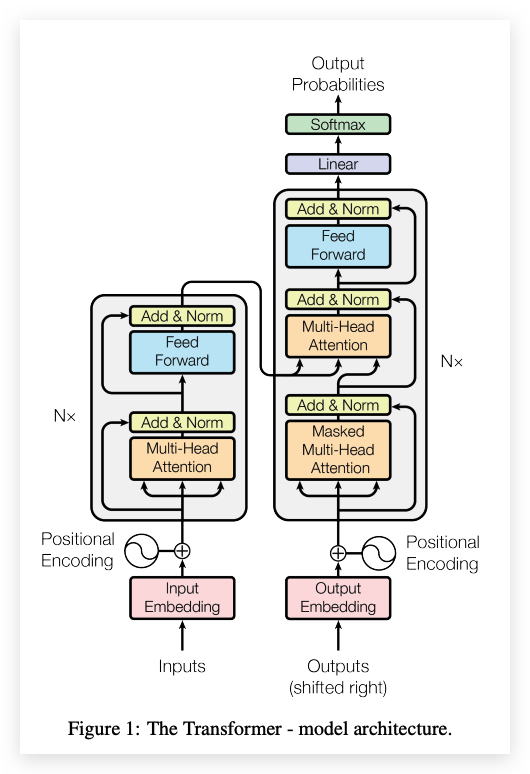
2017年,Google Research推出了Transformer模型。由Vaswani等人发表于谷歌官方论文“Attention Is All You Need ”介绍了Transformer——一种有助于语言理解的新神经网络架构。在Transformer出现之前,机器不太擅长理解长句子的含义,也无法看到相距较远单词之间的关联。Transformer极大地改善了这一点,并成为当今语言理解和生成式人工智能系统的基石。Transformer彻底改变了机器执行翻译、文本摘要、问题回答甚至图像生成和机器人技术的含义。📌 Transformer 架构的基本组成
Transformer 是一种深度学习模型架构,它主要使用了自注意力(Self-Attention)机制来处理序列数据。与传统的RNN(循环神经网络)和CNN(卷积神经网络)不同,Transformer可以并行处理序列中的所有元素,并且能够捕捉序列中的长距离依赖关系。Transformer 将“编码器-解码器”架构与文本处理机制相结合。- 编码器:
- 将原始文本信息转换为内部的向量表示,每个输入的token(如单词或字的部分)被转换为向量。负责处理输入数据。
- 解码器:
- 将这些嵌入与模型之前的输出相结合,并连续预测句子中的每个单词通过填空猜谜游戏,编码器可以了解单词与句子之间的关系,而无需任何人标记词性。解码器在生成输出时,会考虑到所有先前的内部状态和当前步骤的输入。
举个例子:今天天气很(),根据训练的数据,可能会拿“好”来分别计算与“今天天气很”的关系。
- 自注意力机制
- 自注意力机制是Transformer的核心组成部分,它允许模型在处理输入的每个部分时动态地关注(即”注意”)输入的不同部分。它可以计算序列中每个元素与其他元素的关系。这使得模型能够理解文本中的上下文关系,如代词的指代关系等。这种机制使得Transformer能够捕捉长距离的依赖关系,这在传统的RNN架构中是一个挑战。
- 循环神经网络
- LSTM长短期记忆网络和GRNN门控循环神经网络,已经成为了解决序列建模和转换问题最先进的方法。RNN按照输入输出的位置关系对计算进行分解。为了得到当前时序的隐藏层信息h{t}需要输入当前位置信息x{t}和先前层的隐藏层输出h_{t-1}。这种固有的特性阻止了模型在训练过程中的并行化,受限于机器内存的限制,成为了长序列训练的关键受限因素。
:::warning 📌** 生成式 AI:**根据输入预测下一个输出
📌** 编码器和解码器的向量如何变得有效:**就是通过注意力机制,再经过大量的数据训练,使得神经网络里的权重可以把信息压缩成关系靠谱的向量。
📌** 文字信息可以通过上面方法解决,那么图片、影像信息如何预测呢?>>> 看扩散模型章节**
:::
📌 Transformer的实际应用
Transformer架构已被广泛应用于多种语言处理任务,如机器翻译、文本摘要、情感分析等。其优势在于能够高效地处理大规模数据集,并且由于其并行处理能力,训练速度快于传统模型。 Transformer模型通过其独特的注意力机制,为深层语言理解和生成提供了强大的工具。随着技术的进步,我们预见Transformer及其变种将继续在AI领域发挥重要作用,特别是在生成式AI应用中。📌 Transformer 论文原文
其他论文:
- Comprehensive Survey of Model Compression and Speed up for Vision Transformers
Comprehensive Survey of Model Compression and Speed up for Vision Transformers.pdf
📌 Transformer 架构图
:::color2 🌈 LLM 可视化:
:::
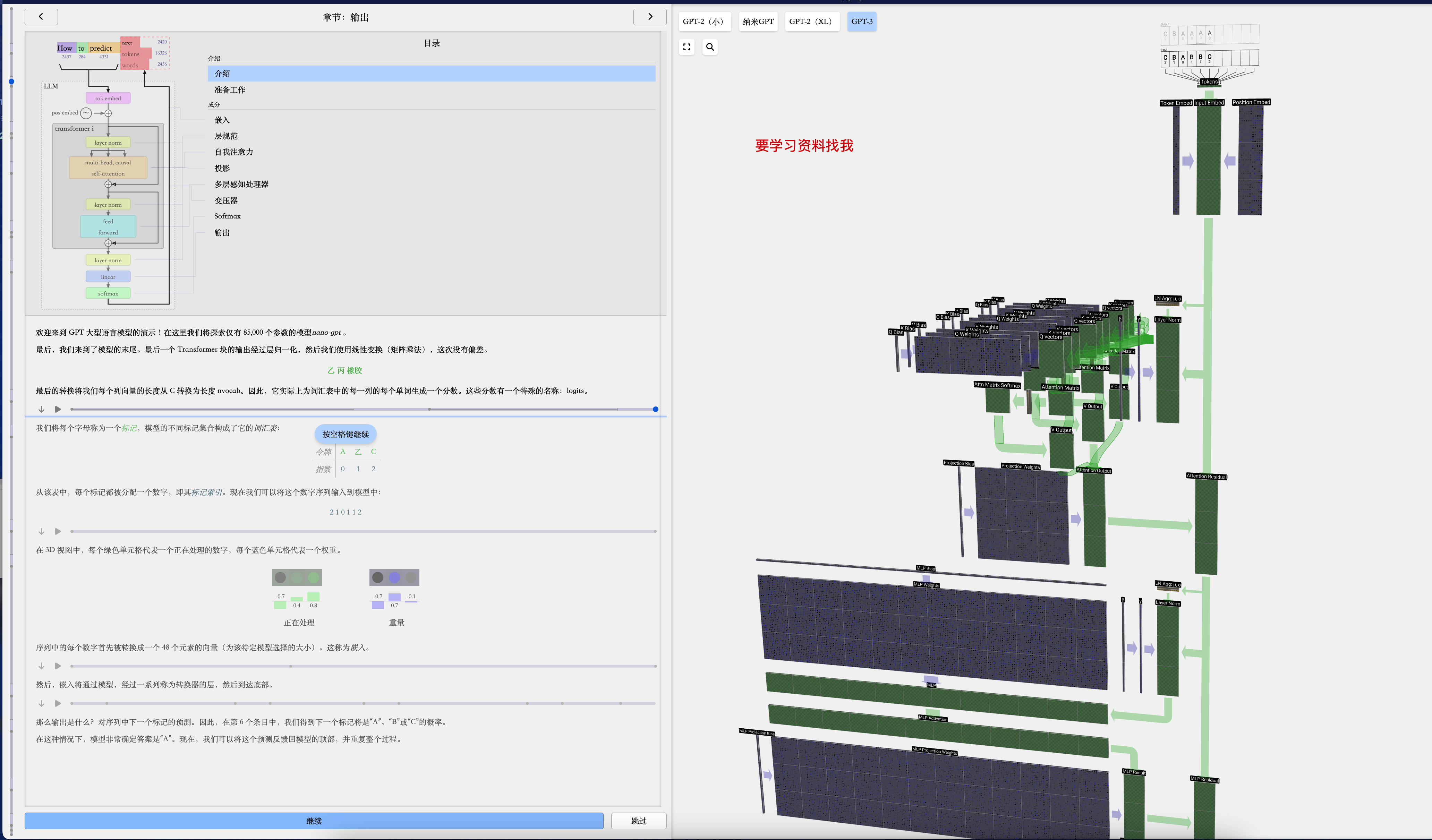
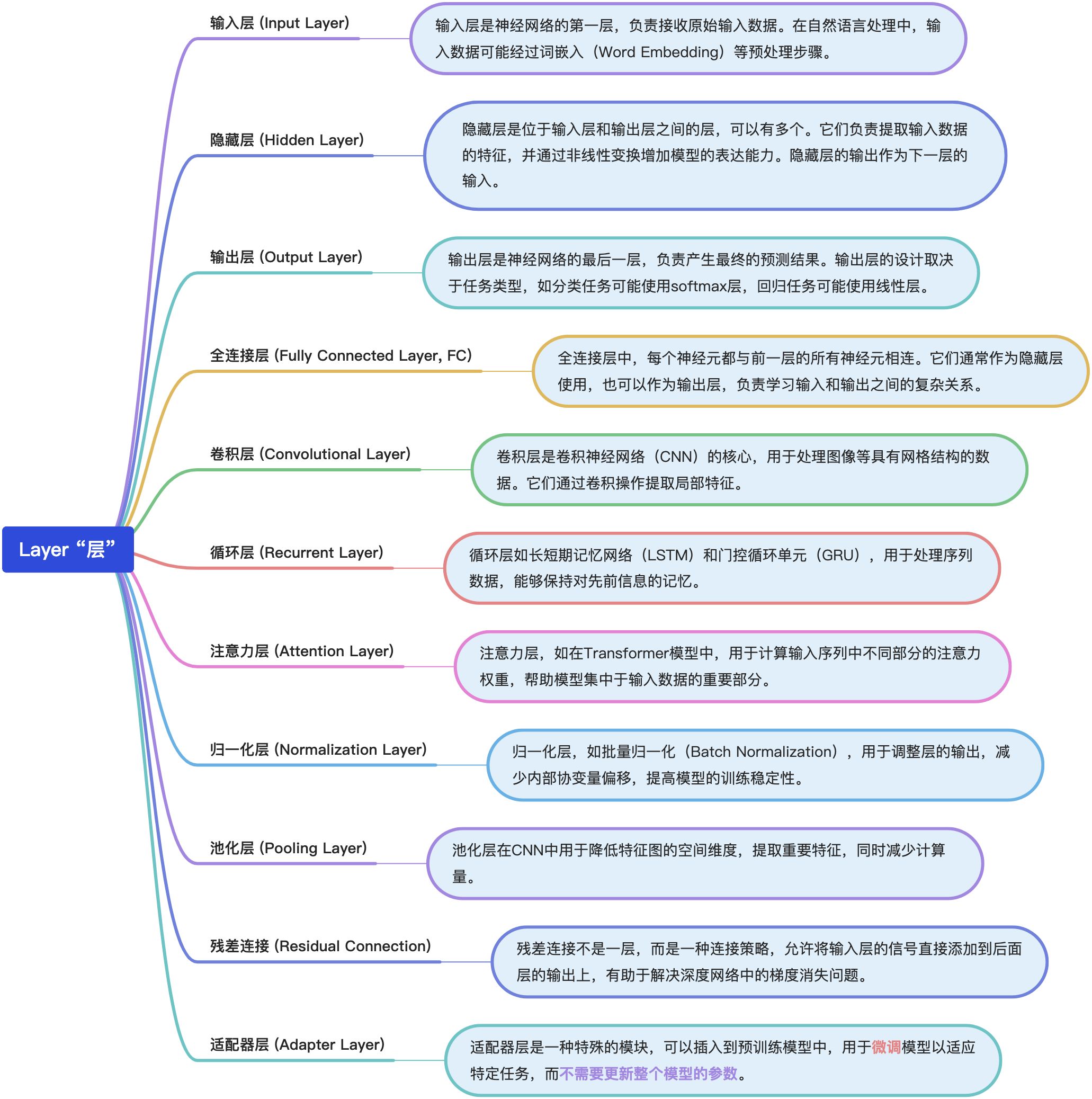
🎯 Layer “层”
在深度学习中,”层”(Layer)是构成神经网络的基本单元,负责对输入数据进行一系列计算和转换。每一层接收来自前一层的输出作为输入,并产生一个输出传递给下一层。在微调大型模型时,通常会保留模型的主要结构不变,只对特定的层(如适配器层)进行训练或更新,以适应新的任务。这种方法可以显著减少计算和存储资源的消耗,同时利用预训练模型的强大能力。下面是对几种常见层类型的详细介绍:
📚 教程 |【清华NLP】大模型公开课
:::color5 网盘课程资料: https://pan.baidu.com/s/1_TkwXRBYM53PzQcpqcuQkw?pwd=best
GitHub:https://github.com/OpenBMB
邮箱:openbmb@gmail.com
🌏 清华 OpenBMB 微信交流群:私信我,拉你进群【微信号:LHYYH0001】 ::: bilibili > 课程原链接:https://www.bilibili.com/video/BV1UG411p7zv > > OpenBMB B站主页:https://space.bilibili.com/493282299 > “Transformers”库和”Transformer”模型是两个不同的概念,但它们都与自然语言处理(NLP)紧密相关。下面我将详细介绍这两者之间的区别。 # 🎯 Transformers 库 与 Transformer 有什么区别? ## Transformers库 :::color4 GitHub:https://github.com/huggingface/transformers ::: “Transformers”是一个由Hugging Face团队开发的开源Python库,它提供了一系列预训练模型和相关工具,用于各种NLP任务。这个库的目标是使先进的NLP技术易于访问和使用,无论用户的经验水平如何。”Transformers”库包括了多种流行的预训练模型,如BERT、GPT-2、RoBERTa、T5等,这些模型在各种NLP任务上都取得了卓越的性能。 使用”Transformers”库,开发者可以轻松地在自己的应用程序中加载预训练模型,并进行微调(fine-tuning)以适应特定的任务。此外,库还提供了丰富的API,用于处理数据、生成文本、分类文本、命名实体识别等多种任务。 ## Transformer模型 “Transformer”是一种深度学习模型,由Vaswani等人在2017年的论文《Attention Is All You Need》中首次提出。这种模型是用于处理序列数据的神经网络架构,特别是在机器翻译任务中表现出色。”Transformer”模型的核心是自注意力(self-attention)机制,它允许模型在处理序列的每个元素时,同时考虑序列中的其他元素,这使得模型能够捕捉到长距离依赖关系。 “Transformer”模型的架构与传统的循环神经网络(RNNs)和长短期记忆网络(LSTMs)不同,它不依赖于递归处理序列数据,而是使用并行计算的方式,这大大提高了训练效率。”Transformer”模型已经在多项NLP任务中取得了突破性的成绩,并且成为了后续许多流行模型的基础,如BERT、GPT等。 ## 总结区别 + 用途: “Transformers”库是一个提供多种预训练模型和工具的软件库,用于简化和加速NLP任务的开发。而”Transformer”模型是一种特定的深度学习架构,用于处理序列数据,尤其是在NLP领域。 + 范围: “Transformers”库包含多种基于”Transformer”架构的模型以及其他类型的模型,而”Transformer”通常指的是最初提出的那个具有自注意力机制的模型。 + 实现: “Transformers”库提供了一个高级接口,使得用户可以方便地加载、使用和微调各种预训练模型。”Transformer”模型则是这些预训练模型之一的底层架构。 简而言之,”Transformers”库是一个工具集,它包含了基于”Transformer”架构的多种模型和其他模型,而”Transformer”是一种特定的深度学习模型,是”Transformers”库中的一个组成部分。 # 其他资料 + Transformer模型详解 - https://mp.weixin.qq.com/s/m0pphf3ZA-ieymkU1iWK5g - https://mp.weixin.qq.com/s/K-DrwXviP2KYJJVE3r3BHw - https://gitcode.csdn.net/66262373a2b05122556583ac.html - https://blog.csdn.net/benzhujie1245com/article/details/117173090?login=from_csdn 正在更新中,敬请期待…学习更多关于 AI 大模型全栈知识👇
:::danger 🌈** AI大模型全栈通识课程**👇
:::
:::color1 🙋 个人介绍 **👉🏻**
:::
:::color5 🙋 AI 工具 **👉🏻**
:::
:::info 🙋 开源版知识库**👉🏻**
:::
:::warning 🙋 AI全栈通识课堂
:::
✅免责声明
素材来源于网络以及个人总结,仅供个人学习交流无商业用途,版本归原创者所有
如有侵权请及时与我联系(微信:AGI舰长-LHYYH0001)删除

若有收获,就点个赞吧
0 人点赞
