更新中….
📌 人工智能与深度学习
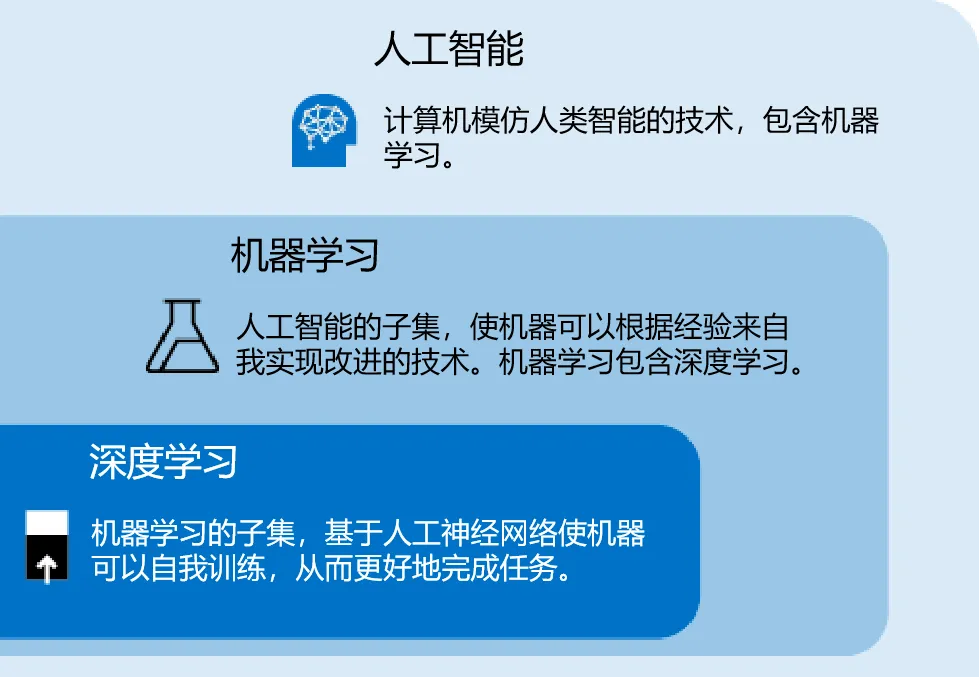
在开始之前,我们要先了解一下,在人工智能领域,什么是“人工神经网络”以及“训练”。
📍 AI 的起源与神经网络的启示
人工智能,一个听起来像是来自科幻小说的词汇,其实已经有着超过半个世纪的历史。自20世纪50年代起,它就在科技的舞台上不断探索,经历了风风雨雨,起起落落。
在AI的早期探索中,有一个流派虽然起初并不被看好,却最终成为了AI的核心——那就是“人工神经网络”。这个流派的灵感来源于我们最复杂、最神奇的器官:人脑。人脑由数十亿神经元组成,它们相互连接,形成了一个庞大而精密的网络。就像一张白纸的婴儿大脑,通过不断的学习和模仿,逐渐展现出惊人的智慧**。**
受此启发,科学家们设计出了人工神经元模型。想象一下,这些模型就像是简化版的大脑神经元,它们通过调整输入信号的权重,经过一系列计算,最终输出结果。每个权重,我们称之为参数,就像是神经元的“学习记忆”。
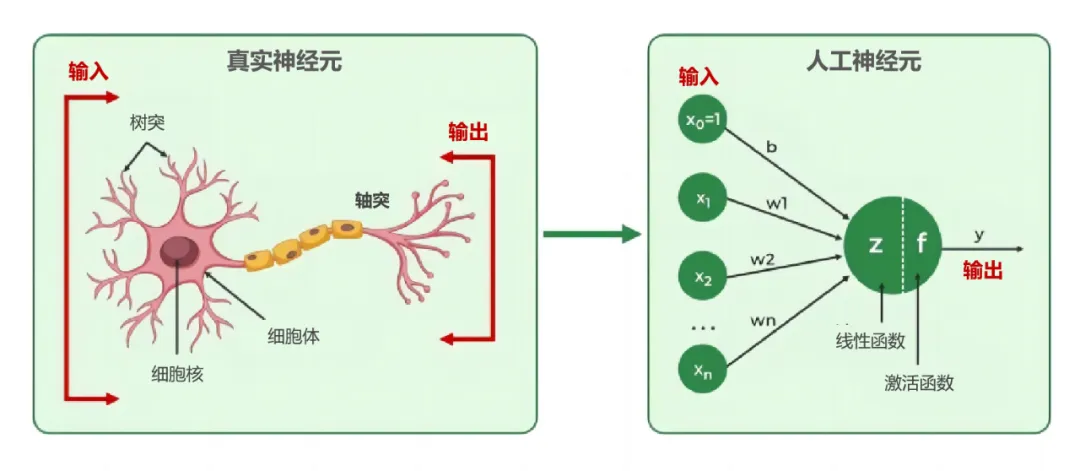
📍 人工神经网络的构建
将这些神经元模型连接起来,就构成了人工神经网络。它们通常由输入层、中间的多个隐藏层以及输出层组成。类似于婴儿的大脑,一开始是空白的,需要大量的数据来“喂食”,通过不断的学习和调整,最终形成解决问题的能力。这个过程,就是我们所说的“深度学习”,它是机器学习的一个重要分支。
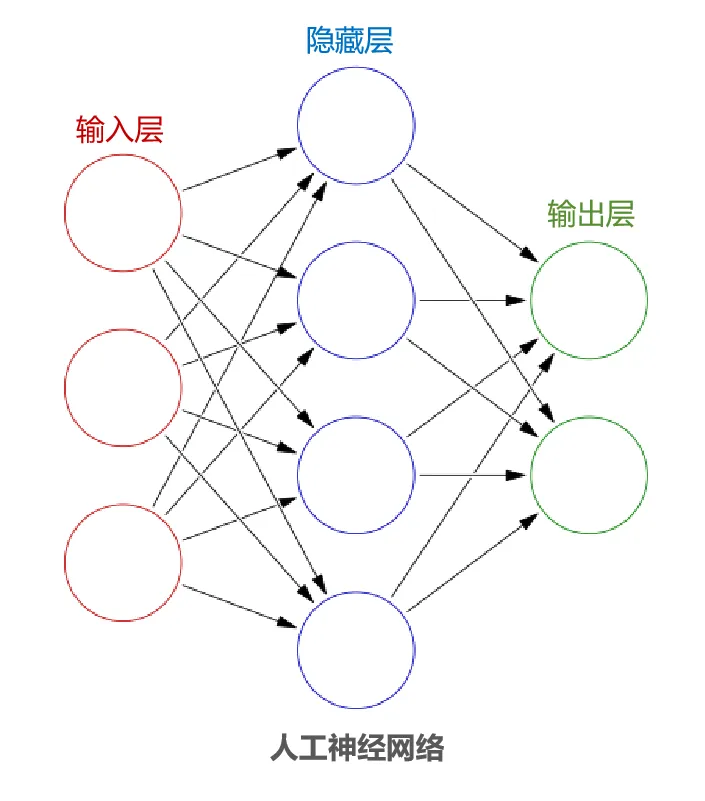
📍 监督学习与AI泛化:如何让机器学会“认猫”
以常见的“监督学习”为例,,如果我们想让 AI 学会识别图片中的猫,就需要给它提供大量已知含有猫的图片,并告诉它猫的特征。AI 会用这些信息来训练自己,找出识别猫的规律。它首先会尝试用当前的参数对一张图片做出判断,然后与正确答案进行比较,根据差异来调整参数权重,这个过程会不断重复,直到 AI 能够准确识别出猫。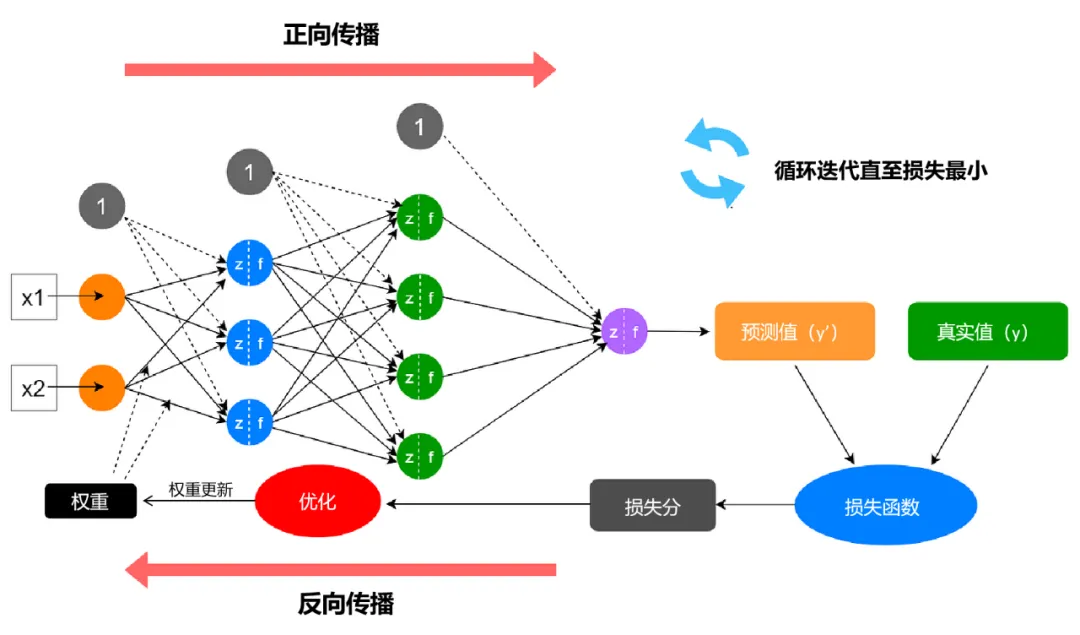 当训练完成后,我们将 AI 放到实际环境中进行测试。如果它能够准确回答未知的问题,那么我们就可以说,训练是成功的,AI展现出了良好的“泛化”能力。
这个学习的过程就叫做训练。一般来说,需要给 AI 大量含有正确答案的数据,才会得出比较好的训练结果。我们将 AI 放到实际环境中进行测试。如果它能够准确回答未知的问题,那么我们就可以说,训练是成功的,AI 展现出了良好的“泛化”能力。
## 📍 为什么AI训练的计算量很大
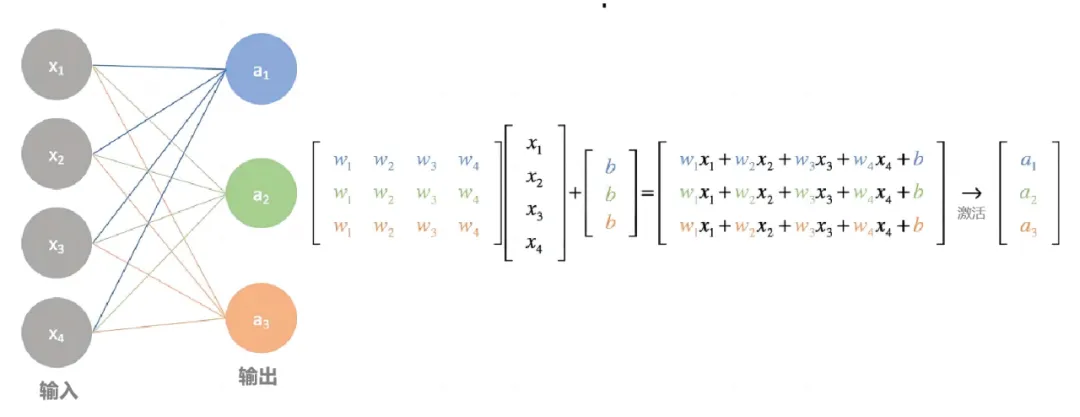
如下图,在神经网络的每一层之间,参数权重的传递本质上是矩阵的乘法和加法。随着神经网络规模的增大,所需的计算量也随之增加。最先进的深度学习神经网络可能包含数百万到数万亿个参数,这就需要大量的训练数据来实现高精度的识别,意味着需要处理海量的输入样本。
由于神经网络的计算本质上是高度并行的,这就引出了一个问题:面对如此庞大的计算量,我们是选择 CPU 还是 GPU 来完成这项任务呢?请看另一篇文章 👉🏻 ⚙️ AI训练为什么需要GPU?
当训练完成后,我们将 AI 放到实际环境中进行测试。如果它能够准确回答未知的问题,那么我们就可以说,训练是成功的,AI展现出了良好的“泛化”能力。
这个学习的过程就叫做训练。一般来说,需要给 AI 大量含有正确答案的数据,才会得出比较好的训练结果。我们将 AI 放到实际环境中进行测试。如果它能够准确回答未知的问题,那么我们就可以说,训练是成功的,AI 展现出了良好的“泛化”能力。
## 📍 为什么AI训练的计算量很大
如下图,在神经网络的每一层之间,参数权重的传递本质上是矩阵的乘法和加法。随着神经网络规模的增大,所需的计算量也随之增加。最先进的深度学习神经网络可能包含数百万到数万亿个参数,这就需要大量的训练数据来实现高精度的识别,意味着需要处理海量的输入样本。
由于神经网络的计算本质上是高度并行的,这就引出了一个问题:面对如此庞大的计算量,我们是选择 CPU 还是 GPU 来完成这项任务呢?请看另一篇文章 👉🏻 ⚙️ AI训练为什么需要GPU?
 # 📌 大模型训练与微调的参数
## 📍 关键参数
在大模型训练和微调过程中,有几个关键参数需要特别关注,以确保模型的性能和效率达到预期目标:
1. 学习率(Learning Rate):学习率是控制模型参数更新幅度的一个重要参数。在微调过程中,通常使用较小的学习率,以避免对预训练模型的原有知识造成太大扰动。选择合适的学习率对于模型能否成功微调至关重要。
2. 训练轮数(Epochs):训练轮数决定了数据集被遍历的次数。更多的训练轮数可能帮助模型更好地学习,但也可能导致过拟合。需要根据模型的表现和训练数据量来调整。
3. 批处理大小(Batch Size):批处理大小影响了每次迭代中处理的数据量。较大的批处理大小可以提高计算效率,但也可能增加显存占用。需要根据硬件资源和模型大小来平衡。
4. 权重衰减(Weight Decay):权重衰减是一种正则化技术,可以帮助防止过拟合。通过在损失函数中添加一个与权重大小成比例的项,鼓励模型学习更小的权重。
5. 梯度裁剪(Gradient Clipping):梯度裁剪用于防止梯度爆炸问题,通过设定一个阈值来限制梯度的最大值。
6. 优化器(Optimizer):选择合适的优化器对模型的训练效果有很大影响。常见的优化器有Adam、SGD等,它们在动量、自适应学习率等方面有所不同。
7. 损失函数(Loss Function):损失函数衡量了模型预测与真实标签之间的差异。在微调过程中,可能需要根据特定任务调整损失函数,以更好地反映模型性能。
8. 评估指标(Evaluation Metrics):选择合适的评估指标来监控模型在验证集上的表现,常见的有准确率、F1分数、BLEU分数等。
9. 早停(Early Stopping):早停是一种防止过拟合的技术,当验证集上的性能不再提升时,提前终止训练过程。
10. 数据增强(Data Augmentation):在数据有限的情况下,可以通过数据增强技术生成更多的训练样本,提高模型的泛化能力。
在微调大模型时,这些参数需要根据具体情况进行调整和优化,以达到最佳的训练效果。同时,也需要考虑硬件资源的限制,如显存大小和计算能力,以确保训练过程的顺利进行。
:::color5
例如Baichuan2 7B/13B、ChatGLM2 6B、LLaMA2 7B/13B等。这些模型可以用于内容创作、信息归纳总结等能力,并且支持单轮对话和多轮对话的形式。ChatGLM模型的微调方法包括全量参数微调、LORA/QLORA、P-Tuning V2等,这些方法在微调过程中对模型原有参数的处理方式不同,各有特点和适用场景。
一般:训练 7B 需要 14G 显存, 13B 需要 24G 显存,但实际操作过程中,内存大小需要大于要求的一倍,才能保证良好的效果。
并且训练过程中的参数比如迭代次数,层数大小等,也都对硬件要求有着重要的影响。
# 📌 大模型训练与微调的参数
## 📍 关键参数
在大模型训练和微调过程中,有几个关键参数需要特别关注,以确保模型的性能和效率达到预期目标:
1. 学习率(Learning Rate):学习率是控制模型参数更新幅度的一个重要参数。在微调过程中,通常使用较小的学习率,以避免对预训练模型的原有知识造成太大扰动。选择合适的学习率对于模型能否成功微调至关重要。
2. 训练轮数(Epochs):训练轮数决定了数据集被遍历的次数。更多的训练轮数可能帮助模型更好地学习,但也可能导致过拟合。需要根据模型的表现和训练数据量来调整。
3. 批处理大小(Batch Size):批处理大小影响了每次迭代中处理的数据量。较大的批处理大小可以提高计算效率,但也可能增加显存占用。需要根据硬件资源和模型大小来平衡。
4. 权重衰减(Weight Decay):权重衰减是一种正则化技术,可以帮助防止过拟合。通过在损失函数中添加一个与权重大小成比例的项,鼓励模型学习更小的权重。
5. 梯度裁剪(Gradient Clipping):梯度裁剪用于防止梯度爆炸问题,通过设定一个阈值来限制梯度的最大值。
6. 优化器(Optimizer):选择合适的优化器对模型的训练效果有很大影响。常见的优化器有Adam、SGD等,它们在动量、自适应学习率等方面有所不同。
7. 损失函数(Loss Function):损失函数衡量了模型预测与真实标签之间的差异。在微调过程中,可能需要根据特定任务调整损失函数,以更好地反映模型性能。
8. 评估指标(Evaluation Metrics):选择合适的评估指标来监控模型在验证集上的表现,常见的有准确率、F1分数、BLEU分数等。
9. 早停(Early Stopping):早停是一种防止过拟合的技术,当验证集上的性能不再提升时,提前终止训练过程。
10. 数据增强(Data Augmentation):在数据有限的情况下,可以通过数据增强技术生成更多的训练样本,提高模型的泛化能力。
在微调大模型时,这些参数需要根据具体情况进行调整和优化,以达到最佳的训练效果。同时,也需要考虑硬件资源的限制,如显存大小和计算能力,以确保训练过程的顺利进行。
:::color5
例如Baichuan2 7B/13B、ChatGLM2 6B、LLaMA2 7B/13B等。这些模型可以用于内容创作、信息归纳总结等能力,并且支持单轮对话和多轮对话的形式。ChatGLM模型的微调方法包括全量参数微调、LORA/QLORA、P-Tuning V2等,这些方法在微调过程中对模型原有参数的处理方式不同,各有特点和适用场景。
一般:训练 7B 需要 14G 显存, 13B 需要 24G 显存,但实际操作过程中,内存大小需要大于要求的一倍,才能保证良好的效果。
并且训练过程中的参数比如迭代次数,层数大小等,也都对硬件要求有着重要的影响。
:::
📍 超参
:::color5 超参数(Hyperparameters)是机器学习和深度学习模型训练过程中需要设置的参数,它们不是从数据中学得的,而是需要人为设定的。超参数对于模型的性能和最终结果有着重要的影响。与模型参数不同,模型参数(如神经网络中的权重和偏置)是在训练过程中通过学习数据自动调整的。
:::
✅** 超参数的例子包括:**
- 学习率:控制模型参数在每次迭代中更新的幅度。
- 批次大小(Batch Size):每次训练迭代中用于计算梯度和更新参数的样本数量。
- 迭代次数(Epochs):整个训练数据集被遍历和用于训练模型的次数。
- 网络结构:如层数、每层的节点数或神经元数等。
- 正则化参数:如L1、L2正则化项的系数,用于防止过拟合。
- 优化器的选择:如SGD、Adam、RMSprop等。
- 激活函数的选择:如ReLU、Sigmoid、Tanh等。
- dropout率:用于随机丢弃一些神经元输出的比率,以减少过拟合。
✅** 在训练时设定超参数的方法通常包括以下几种:**
- 经验设定:根据经验或文献中的建议来设定超参数的初始值。
- 网格搜索(Grid Search):系统地遍历超参数的所有可能组合,找到最优的参数组合。
- 随机搜索(Random Search):随机选择超参数的值,通常比网格搜索更高效。
- 贝叶斯优化(Bayesian Optimization):基于概率模型来选择最优的超参数,可以更智能地选择参数值。
- 基于模型的方法:使用一个模型来预测不同超参数设置下的性能,从而选择最佳的超参数。
- 遗传算法(Genetic Algorithms):模拟自然选择过程来优化超参数。
超参数的选择对模型的训练和泛化能力至关重要。通常,需要通过多次实验和调整来找到最佳的超参数配置。这个过程可能需要较长的时间和较多的计算资源,但它是构建高效、准确模型的关键步骤。
📌 Q.K.V
📍 概念
在大模型训练中,特别是在涉及到注意力机制(Attention Mechanism)的模型,如 Transformer 架构及其衍生模型中,”Q”、”K”、”V”通常代表查询(Query)、键(Key)和值(Value)这三个组件,它们是注意力机制的核心部分。
- 查询(Query):查询向量是用于与键进行匹配的向量。在注意力机制中,查询向量决定了模型应该关注输入序列中的哪些部分。例如,在自注意力(Self-Attention)中,查询向量可以用来计算输入序列中每个元素对其他元素的影响。
- 键(Key):键向量是用于与查询进行匹配的向量。每个输入元素都会有一个对应的键向量。查询和键之间的匹配程度通常通过计算它们的点积来确定。
- 值(Value):值向量是一旦键和查询匹配后,将要被加权和累加的向量。在注意力机制中,值向量代表了输入序列中的信息,通过加权(权重由查询和键的匹配程度决定)和累加,可以得到加权后的输出表示。
在注意力计算过程中,首先会计算查询和所有键的点积,得到一个注意力分数(Attention Scores),然后通常会通过softmax函数对这些分数进行归一化,使得它们的和为1。这样得到的注意力权重(Attention Weights)会与对应的值向量相乘,最后将所有加权的值向量求和,得到最终的输出向量。
这种机制使得模型能够动态地关注输入序列中的重要部分,并根据上下文信息调整输出表示,这是 Transformer 模型及其变体在自然语言处理任务中取得成功的关键因素之一。
📍 Q.K.V 参数调整策略
在实际训练中,调整查询(Q)、键(K)、值(V)这三个参数通常涉及到注意力机制的超参数调整,以及可能的网络架构改动。以下是一些调整这些参数的例子和方法:
- 缩放因子(Scaling Factor):
在计算查询和键的点积时,通常会有一个缩放因子,以防止点积过大导致softmax函数进入梯度很小的区域,这被称为softmax的梯度消失问题。这个缩放因子通常是键向量维度的倒数平方根。在实际训练中,可以通过调整这个缩放因子来控制注意力的敏感度。
例子:如果发现模型对长距离依赖的学习能力不足,可以尝试增大缩放因子,使得模型更加关注于全局的依赖关系。 - 多头注意力(Multi-Head Attention):
Transformer模型中使用多头注意力来并行地学习不同的注意力模式。这里的“头”(head)数量是一个重要的超参数。增加头的数量可以让模型在不同的表示子空间中学习信息,增强模型的表达能力。
例子:如果模型在处理某些复杂的语言任务时表现不佳,可以尝试增加头的数量,例如从4头增加到8头,以期望模型能够捕捉到更丰富的上下文信息。 - 维度分割(Dimension Splitting):
在多头注意力中,查询、键和值的维度通常会被分割成多个头,每个头拥有较低的维度。分割的方式(如平均分割、分组分割等)会影响模型的学习能力和效率。
例子:如果模型的训练速度较慢或显存占用较高,可以尝试对维度进行不同的分割策略,比如将维度平均分配到每个头上,或者将某些头的维度合并。 - 注意力层的堆叠(Stacking Attention Layers):
通过堆叠多个注意力层,模型可以逐渐学习到更抽象的表示。堆叠的层数是另一个超参数,需要根据任务的复杂性来调整。
例子:对于一个需要深层语义理解的任务,可以增加注意力层的堆叠数量,以便模型能够捕捉到更深层次的依赖关系。 - 激活函数(Activation Function):
在注意力分数通过softmax函数之前或之后,有时会使用非线性激活函数来增加模型的非线性表达能力。
例子:如果模型在某些任务上的性能不佳,可以尝试更换激活函数,如从ReLU更换为GELU,以期望模型能够更好地捕捉到复杂的模式。
在实际训练中,调整这些参数需要根据模型在验证集上的表现来进行。通常需要进行多次实验,通过比较不同配置下的性能来找到最优的参数设置。此外,也需要考虑计算资源和训练时间的限制。
学习更多关于 AI 大模型全栈知识👇
:::danger 🌈** AI大模型全栈通识课程**👇
:::
:::color1 🙋 个人介绍 **👉🏻**
:::
:::color5 🙋 AI 工具 **👉🏻**
:::
:::info 🙋 开源版知识库**👉🏻**
:::
:::warning 🙋 AI全栈通识课堂
:::
✅免责声明
素材来源于网络以及个人总结,仅供个人学习交流无商业用途,版本归原创者所有
如有侵权请及时与我联系(微信:AGI舰长-LHYYH0001)删除

若有收获,就点个赞吧
0 人点赞
