:::color2 👏 Hi~,我是@领航猿1号,也有粉丝叫我『AGI舰长』,欢迎来到 AI 全栈大模型通识课堂。
🎯 向您保证,学完本系列五个单元共78+节(持续更新)课程后,你将成为 AI 领域专家。并提升职场竞争力,涨薪,升职,副业赚钱!
:::
:::color1 🙋 个人介绍 **👉🏻**
:::
:::color5 🙋 AI 工具 **👉🏻**
:::
:::info 🙋 开源版知识库**👉🏻**
:::
:::warning 🙋 AI全栈课堂**👉🏻**
:::
:::success 🎯 我们在做 RAG 解决方案时,第一就是准备数据,数据清理,然后做文档拆分。而在做文档拆分时,需要我们考虑几个问题,比如支持不同文件类型的拆分、拆分技术的选择、文档拆分常见问题的处理等等。本文将针对这部分进行讲解。
:::
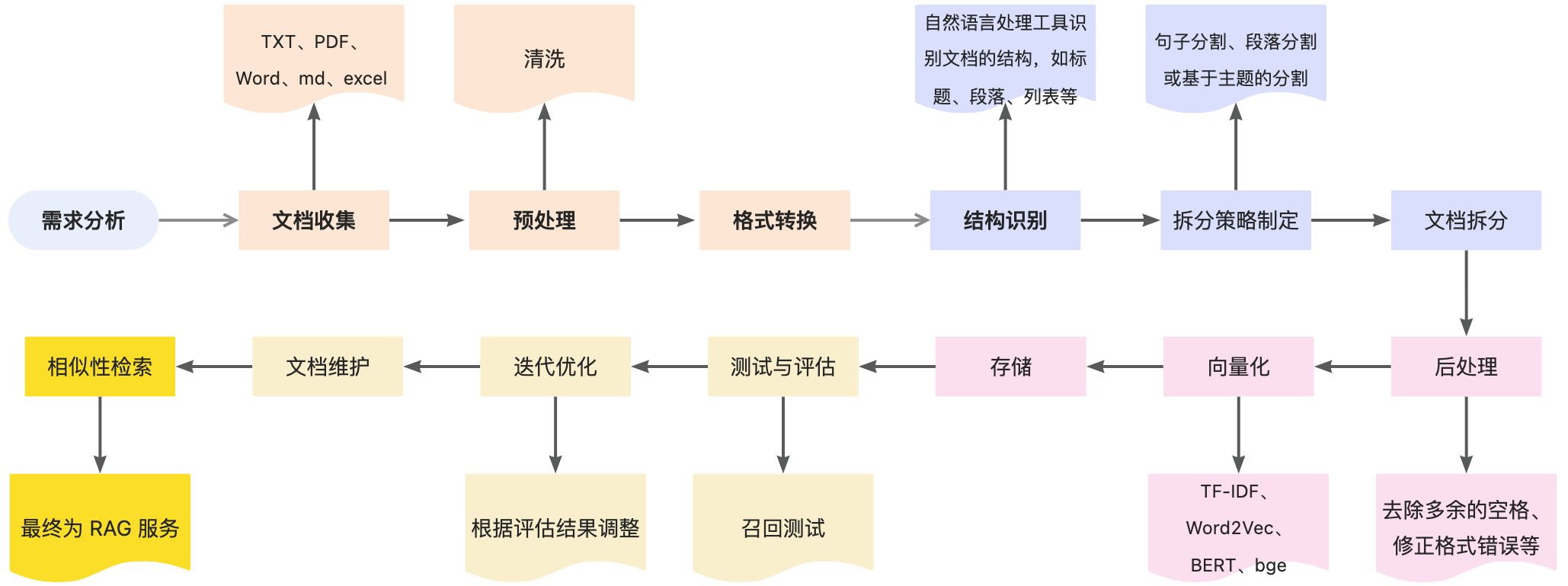
1、为什么要先做文档拆分?
:::info 📌 文档拆分是指将较大的文档分解成更小的、可管理的片段(chunks),便于 RAG 时,可以通过相似性检索的方式召回与用户问题相关的知识片段喂给 LLM 。另外,这样做的其他几个原因如下:
:::
- 提高检索效率:小的文档片段可以更快地被索引和检索。
- 提升检索精度:通过对文档进行拆分,可以更精确地定位到包含用户查询相关信息的文档部分,从而提高检索结果的相关性。
- 减少噪声:较大的文档可能包含不相关或冗余的信息,拆分有助于去除这些噪声。
- 便于向量化:拆分后的文档片段更容易被转换成向量形式,这对于使用基于向量的检索系统(如向量数据库)至关重要。
- 支持复杂查询:拆分后的文档可以支持更复杂的查询操作,如跨文档的信息合并、对比分析等。
2、需要考虑哪些类型文件?
:::info 📌 在进行文档拆分时,可能需要考虑多种类型的文件,可根据项目情况决定前期支持哪些格式文件,没必要第一版就全都支持,这个很难做到。包括但不限于:
:::
- 文本文件:如 TXT、MD、DOCX 等,它们包含纯文本信息,易于处理
- PDF文件:包含格式化文本和可能的图像内容、多表头表格,需要特定的解析技术
- 富文本文件:如 HTML, XML 等,这些文件除了文本内容外,还包含标记和元数据
- web 联网:通过网页爬虫技术,联网获取数据
- 多媒体文件:如视频和音频的字幕或者转录文本
- 数据集:如 CSV, JSON, Excel 等格式的数据集,其中可能包含文本信息
3、预处理 - 数据清洗
:::info
- 数据清洗是一个迭代的过程,可能需要多次执行和调整清洗规则,以确保数据达到所需的质量。此外,清洗过程中应特别注意不要丢失对分析有用的信息。在整个过程中,保持对数据的敏感性和对清洗操作的影响的理解是非常重要的。清洗后的数据将直接影响到知识库向量化存储的效果和微调模型的性能,因此这一步骤不容忽视。
- 在文档拆分的预处理环节中,数据清洗的目的是去除或纠正数据中的错误和不一致,以提高数据质量并确保后续处理步骤的有效性。以下是一些常见的数据清洗手段和技术:
:::
- 去除无关内容:删除文档中的页眉、页脚、水印、页码等非文本内容。
- 格式化处理:统一文档的格式,包括字体、间距、段落等,以便于统一处理。
- 文本规范化:
- 转换为统一字符集:如将所有字符转换为UTF-8编码。
- 大小写转换:将所有文本转换为小写或大写,以消除大小写差异造成的影响。
- 去除噪声:
- 删除多余的空格和特殊字符:包括前后空格、段落间的多余空格、不可见字符等。
- 去除无意义的符号和数字:如删除文本中的冗余标点符号、无意义的数字序列等。
- 分词处理:
- 使用NLP工具进行分词,将连续的文本拆分成有意义的单词或短语。
- 去除停用词:移除常见的、意义不大的词汇,如“的”、“和”、“是”等。
- 词干提取或词形还原:将单词转换为其基本形式,例如将动词的过去式还原为原形。
- 拼写校正:纠正文档中的拼写错误。
- 实体识别与链接:识别文档中的专有名词(如人名、地名)并进行链接或替换。
- 去除重复内容:
- 删除重复的段落或句子:确保文档中没有重复的信息。
- 合并重复的文档块:如果文档被错误地分割成多个块,需要将它们合并回去。
- 文本对齐:确保文档中的列表、表格等元素格式正确,没有错位。
- 使用正则表达式:编写正则表达式来匹配和替换特定的文本模式,进行复杂的清洗任务。
- 自定义规则:根据具体的业务需求,可能需要编写一些自定义的清洗规则。
- 数据类型转换:
- 确保每列数据的类型正确,例如文本字段不应该包含数字。
- 使用数据类型转换函数或工具来纠正数据类型。
- 数据标准化/归一化:
- 将数据缩放到一个统一的范围,以消除不同量级和单位的影响。
- 常用的方法有最小-最大归一化、Z分数(标准分数)归一化等。
- 数据整合:
- 将来自不同来源的数据合并到一个统一的数据集中。
- 需要确保合并后的数据在结构和内容上保持一致性。
- 数据质量检查:
- 在清洗过程完成后,进行数据质量检查,确保数据满足预期的标准和要求。
- 可以使用数据质量报告或自动化测试来评估数据质量。
- 文档化:
- 记录清洗过程中的所有操作和决策,以便复现或审查。
- 包括数据来源、清洗方法、处理的异常情况等。
- 利用NLP库:使用NLP库(如NLTK、spaCy等)提供的高级文本处理功能。
- 机器学习模型:在一些复杂的情况下,可以使用机器学习模型来识别和清洗数据。
4、文档拆分技术有哪些?
4.1 技术方案
✅** 入门级**
- 基于规则的拆分:根据预定义的规则(如标题、段落、标点符号、token 长度等)来拆分文档。
- 句号分段:好处,分完的段是一个完整句子
- 基于统计的拆分:使用统计方法来确定文档的结构和拆分点,例如,可以通过识别文本中的话题变化来拆分文档。
✅** 高阶**
- 自然语言处理(NLP):利用NLP技术,如句子边界、语义边界检测,来识别文档的逻辑结构。
- 基于文本嵌入的拆分:使用文本嵌入(如BERT等预训练模型生成的向量)来识别文档中内容的相似度,据此进行拆分。
4.2 技术实现
:::info 🎯 可以看一下本单元第三章第 7 节课内容👇
:::
4.3 文档拆分技术
文档拆分是将长文档或大量文本内容分解成更小、更易于管理和处理的单元的过程。这项技术在自然语言处理(NLP)、信息检索、内容管理等领域中非常重要。以下是一些常用的文档拆分技术:
- 分词(Tokenization):
- 分词是将文本拆分成单词或短语的过程,是文本处理的基础步骤。
- 基于规则的分词依赖预定义的词典和规则,适用于结构化文本。
- 基于统计的分词利用语料库统计词语频率和上下文信息,适用于处理新词和歧义词。
- 基于深度学习的分词使用神经网络模型学习词语上下文和语义,适用于复杂文本。
- 句子切分(Sentence Splitting):
- 句子切分是将文本拆分成独立句子的过程,每个句子作为一个单独的单元。
- 可以基于标点符号、语境信息或通过训练的模型来识别句子边界。
- 段落划分(Paragraph Segmentation):
- 段落划分是将文档拆分成独立的段落,每个段落包含相关的内容。
- 通常依赖文档的格式和结构,如换行符或标题,也可以通过内容分析来识别段落边界。
- 结构化文档分块(Structured Document Chunking):
- 对于结构化文档(如Markdown、LaTeX),可以使用专门的分块方法来保留内容的原始结构。
- 通过解析文档的标记语言,可以智能地划分内容,产生语义上连贯的块。
- 自定义文档拆分器(Custom Document Splitter):
- 一些高级工具,如谷歌云的Document AI Workbench,提供了自定义文档拆分器,可以自动拆分和分类文档。
- 文本语义分割(Text Semantic Segmentation):
- 通过模型预测文本分段的边界,考虑上下文信息和潜在的段落断点。
- 分块策略(Chunking Strategies):
- 在构建大型语言模型(LLM)应用时,分块策略用于优化向量数据库返回内容的相关性。
- 可以嵌入短内容和长内容,按语句分块,或递归分块,以及针对特定格式的文档进行结构化分块。
这些技术可以单独使用,也可以组合使用,以适应不同的文档类型和拆分需求。选择合适的文档拆分技术取决于具体的应用场景、文档的结构和内容特点。
5、文档拆分常见问题都有什么?
- 边界识别错误:错误地将一个概念或主题拆分成两个部分,或将两个不同概念合并为一个部分。
- 拆分粒度:确定拆分的粒度是一个挑战
- 拆得太细(chunk 太短):可能会导致上下文信息丢失
- 拆得太粗(chunk 太长):可能会降低检索效率和精度(信息压缩失真)
- chunk 跨主题:内容关系脱节,缺少了主题和知识点之间的关系
- 上下文丢失:
- 拆分后的文档块可能会丢失与其它块的上下文联系,影响检索质量。
- 原文连续内容(含表格、跨页)被截断,单个 chunk 信息表达不完整或含义相反
- 图片问题、表格问题
- 支持检索出来图片文件么?
比如问:xx 系统架构图,会给我返回这张图片么?
问:xx 系统架构图概述?- 表格:多行多列,怎么拆,怎么存,如何做解析
- 权限控制:不同的人看到的文档内容是不同的,怎么控制?
- Excel:有很多 sheet 页以及很多列, 列存在重复数据,比如创建人、更新人、每个文件 excel 都是一样的,这种怎么处理:**CodeInterpreter**
- 干扰信息:如空白、HTML、XML等格式,同等长度下减少有效信息,增加干扰信息
- 格式和结构多样性:不同类型的文档可能有不同的格式和结构,需要不同的处理方法。如 PDF 中的图像或图表)的处理可能需要额外的步骤,如 OCR(光学字符识别)。
- 语义连贯性:确保每个拆分出的文档片段在语义上是连贯的,不会产生误解。
- 性能问题:文档拆分可能会消耗大量的计算资源,特别是在处理大规模数据集时。
- 语言和方言差异:不同语言和方言可能需要不同的拆分策略。

好了,准备工作完毕,下节课我们开始学习 RAG 检索增强技术~
学习更多关于 AI 大模型全栈知识👇
:::danger 🌈** AI大模型全栈通识课程**👇
:::
:::color1 🙋 个人介绍 **👉🏻**
:::
:::color5 🙋 AI 工具 **👉🏻**
:::
:::info 🙋 开源版知识库**👉🏻**
:::
:::warning 🙋 AI全栈通识课堂
:::
✅免责声明
素材来源于网络以及个人总结,仅供个人学习交流无商业用途,版本归原创者所有
如有侵权请及时与我联系(微信:AGI舰长-LHYYH0001)删除

若有收获,就点个赞吧
0 人点赞
