一、背景
视频下载的套路基本同图片下载一样,甚至更简单。
本文通过代码实现下载电视剧《赘婿》:https://www.okzyw.net/?m=vod-detail-id-71448.html
思路:搜索——>解析——>下载。
1.搜索
- F12检查元素,打开网络选项卡,搜索《赘婿》,可以发现向服务器POST了关键词‘赘婿’
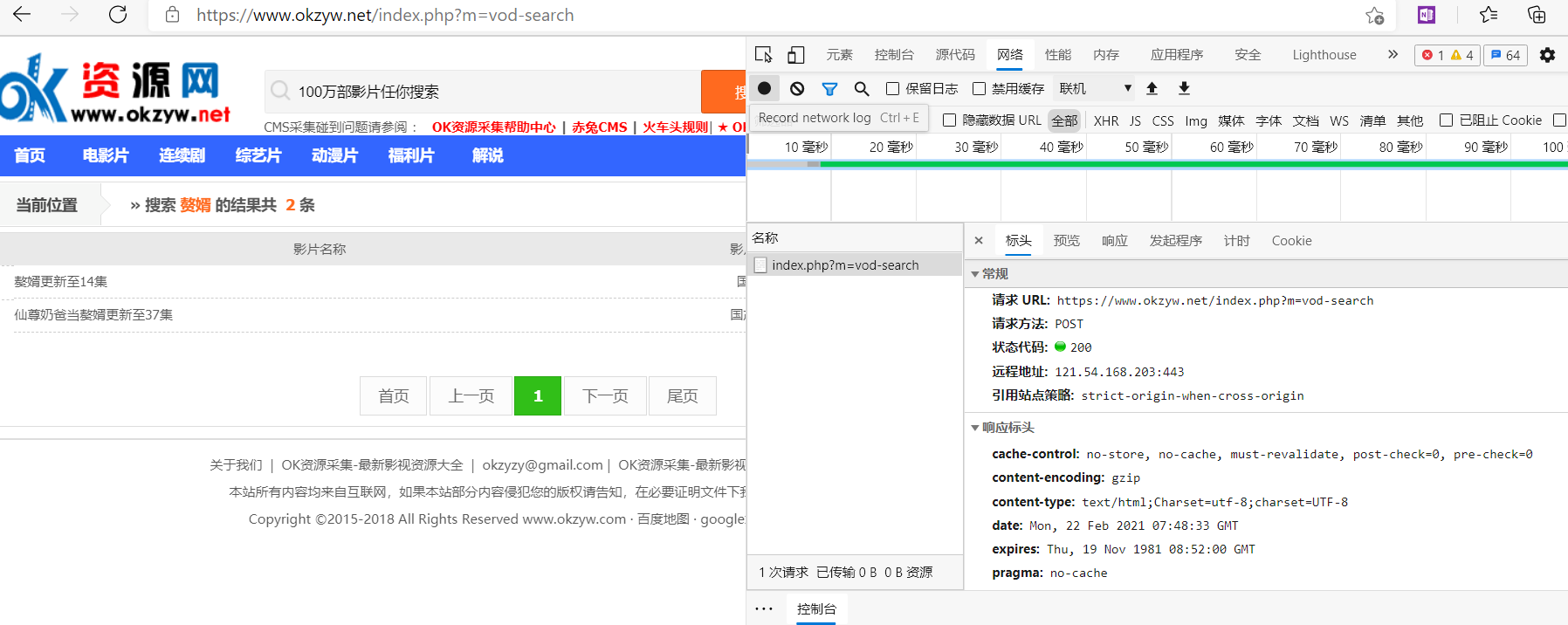
- 继续查看搜索结果,搜索结果保存在html的赘婿更新至14集中

- 编写get_url()获取电视剧的url ```python import requests from bs4 import BeautifulSoup
search_key=’赘婿’ search_url=’https://www.okzyw.net/index.php‘ search_params={ ‘m’:’vod-search’ } search_headers={ ‘user-agent’:’Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.150 Safari/537.36 Edg/88.0.705.68’, ‘referer’:’https://www.okzyw.net/‘, ‘origin’:’https://www.okzyw.net‘ } search_data={ ‘wd’: search_key, ‘submit’: ‘search’ }
req=requests.post(url=searchurl,params=search_params,headers=search_headers,data=search_data) req.encoding=’utf-8’ server=’https://www.okzyw.net‘ search_html=BeautifulSoup(req.text,’lxml’) search_spans=search_html.find_all(‘span’,class=’xing_vb4’)
for span in search_spans:
name=span.a.string
url=server+span.a.get(‘href’)
print(name,’:’,url)
<a name="4fAWG"></a>### 2.解析- 解析搜索结果,获取每集的下载链接。url:[https://www.okzyw.net/?m=vod-detail-id-71448.html](https://www.okzyw.net/?m=vod-detail-id-71448.html)- 可以发现有两种下载格式,我们已下载m3u8为例。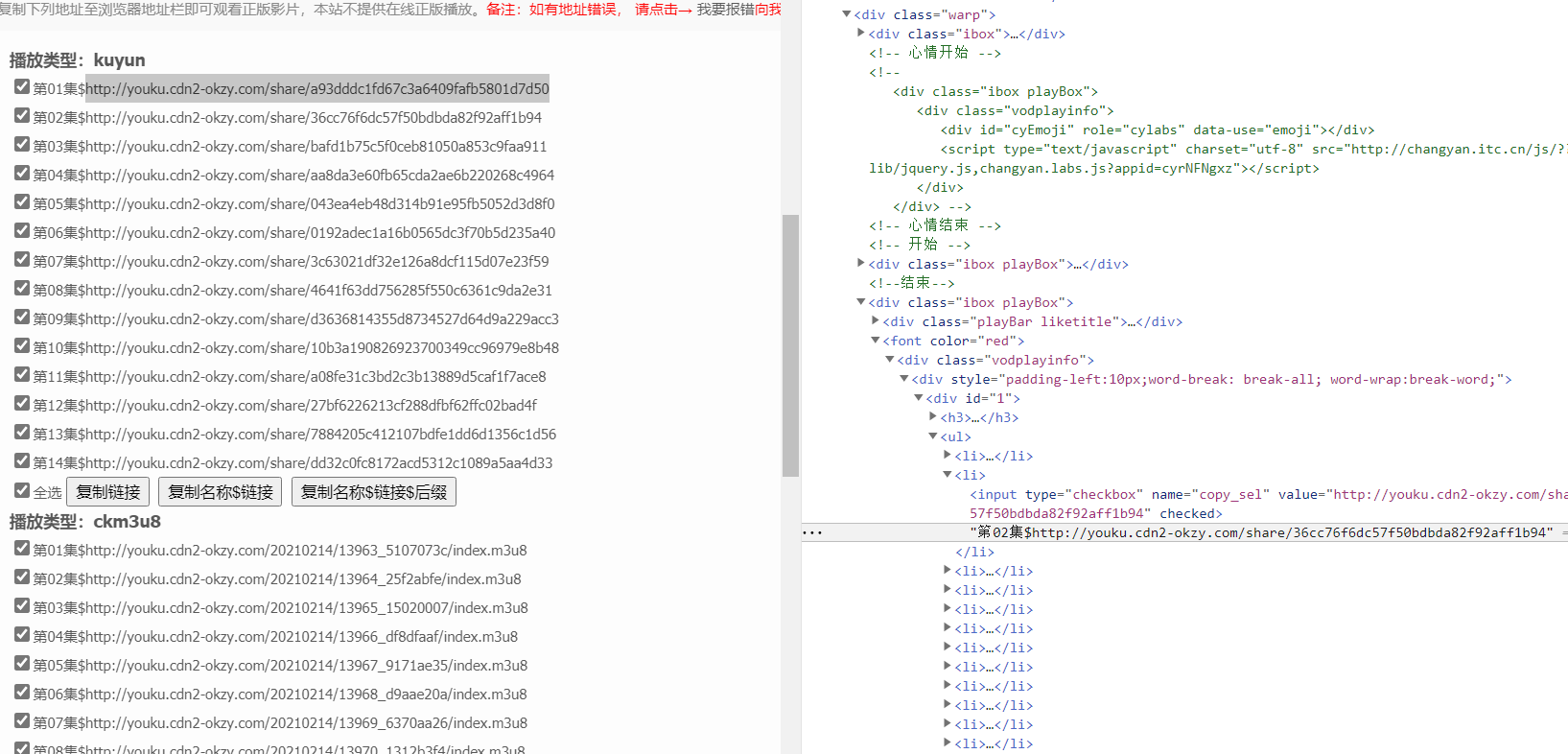- 可以发现,下载链接都存放在<div id="2">的input标签中,下面提取所有下载链接<a name="0af5c359"></a>### 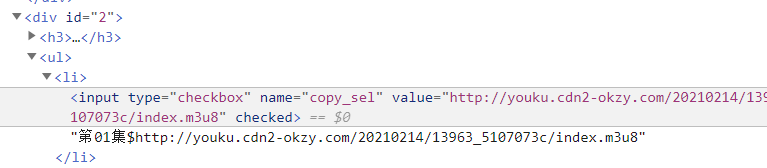- 代码如下:```pythonimport requestsfrom bs4 import BeautifulSoupurl = 'https://www.okzyw.net/?m=vod-detail-id-71448.html'req = requests.get(url)bs = BeautifulSoup(req.text, 'lxml')bs_div = bs.find('div', id="2")bs_inputs = bs_div.find_all('input')num = 1for each in bs_inputs:if 'm3u8' in each.get('value'):url = each.get('value')print(num, ':', url)num += 1
3.下载
打开网络抓包,容易发现视频都是以ts分段视频传输的,python中的ffmpy3,及python中的FFmpeg可以处理,该模块的功能包括视频采集、视频格式转换、视频抓图、给视频加水印等。FFmpeg相关教程url
import requestsfrom bs4 import BeautifulSoupimport osimport ffmpy3from multiprocessing.dummy import Pool as ThreadPoolsearch_key='赘婿'search_url='https://www.okzyw.net/index.php'search_params={'m':'vod-search'}search_headers={'user-agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.150 Safari/537.36 Edg/88.0.705.68','referer':'https://www.okzyw.net/','origin':'https://www.okzyw.net'}search_data={'wd': search_key,'submit': 'search'}req=requests.post(url=search_url,params=search_params,headers=search_headers,data=search_data)req.encoding='utf-8'server='https://www.okzyw.net'search_html=BeautifulSoup(req.text,'lxml')search_spans=search_html.find_all('span',class_='xing_vb4')for span in search_spans:name=span.a.stringtv_url=server+span.a.get('href')print(name)print(tv_url)video_dir=nameif video_dir not in os.listdir(r'D:\ProgramData\Python'):os.mkdir(name)#获取每集电视的下载地址req = requests.get(tv_url)bs = BeautifulSoup(req.text, 'lxml')bs_div = bs.find('div', id="2")bs_inputs = bs_div.find_all('input')num = 1search_res={}for each in bs_inputs:if 'm3u8' in each.get('value'):ep_url = each.get('value')if ep_url not in search_res.keys():search_res[ep_url]=numprint(num, ':', ep_url)num += 1#开始下载def download_video(ep_url):num=search_res[ep_url]name=os.path.join(video_dir,'第{0}集.mp4'.format(num))ffmpy3.FFmpeg(inputs={ep_url: None}, outputs={name:None}).run()# 开10个线程池pool = ThreadPool(10)results = pool.map(download_video, search_res.keys())pool.close()pool.join()

若有收获,就点个赞吧
0 人点赞
